Lời mở đầu
Chào các bạn, lâu rồi không viết bài trên Viblo nên hôm nay tôi tâm sự chút trải nghiệm của mình khi huấn luyện mô hình trên nhiều máy tính (multi-node training).
Chả là, đồng nghiệp tôi toàn kháo nhau về huấn luyện mô hình trên một máy có nhiều gpu (distributed training on single node) ... ờ thì lúc đầu tôi chẳng thấy hứng thú gì cho lắm, cho đến khi dính phải một cái dự án cần train mô hình cho kịp deadline. Khổ nỗi mô hình này tốn khá nhiều thời gian ~1 tuần mới xong ( đã train multi-gpu trên 1 máy rồi mà còn thế ) => vì vậy tôi nghĩ đến việc thử join gpu trên các máy khác xem như thế nào (multi-node gpus)
Ok mở đầu xong rồi đấy, giờ thì tôi sẽ kể cho các bạn trải nghiệm của mình.
Yêu cầu
Chuẩn bị phần cứng
Dưới đây là thông số của 2 con máy tôi thử nghiệm:
| VM 1 | VM 2 | |
|---|---|---|
| Architecture | x86_64 | x86_64 |
| CPU(s) | 12 | 6 |
| Model name | 12th Gen Intel(R) Core(TM) i5-12400 | Intel(R) Core(TM) i5-8400 CPU @ 2.80GHz |
| CPU MHz | 2500 | 3867 |
| VGA | NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] | NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] |
| LAN speed | 10mb/s | 100mb/s |
Chuẩn bị phần mềm
Tôi sẽ tải các phần mềm dưới đây trên cả 2 máy :
- Nvidia GPU driver: 515.65.01
- NVIDIA Collective Communications Library (NCCL): 2.13.4
https://docs.nvidia.com/deeplearning/nccl/install-guide/index.html
- Docker: 20.10.17
- NVIDIA Container Toolkit (nvidia-docker2): 2.7.0-1
Nếu đã cài nvidia-docker2 thì không cần config nvidia runtime, bạn có thể kiểm tra xem thử docker đã dùng nvidia runtime chưa :
sudo cat /etc/docker/daemon.json
Nếu output như đoạn dưới thì docker trên máy bạn đang dùng nvidia runtime rồi.
{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } }
}
Restart docker để cập nhật thay đổi
sudo systemctl restart docker
Test xem docker container chạy đc cuda chưa :
sudo docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi
Nếu ra đúng hình dưới thì ok
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
- Lựa chọn thư viện hỗ trợ multi-node gpus : Horovod, Deepspeed, Ray, ...
Như các bạn thấy thì có kha khá thư viện mình có thể dùng. Không chỉ thế bạn có thể build luôn từ các backend như Gloo, MPI, NCCL bởi vì các thư viện mình kể trên based trên các backend này, nhưng khổ cái là các backend này viết bằng C và mình lại chỉ biết Python nên xin thôi.
Dưới đây là một bảng so sánh của pytorch về các chức năng của 3 built-in backend trên CPU và GPU mà mình cảm thấy khá hữu dụng :
Tí nữa mình sẽ giải thích các function này có chức năng gì, còn bây giờ quay lại vấn đề chính. Mình chọn dùng horovod làm thư viện hỗ trợ kết nối các gpu với nhau.
Horovod
Tại sao tôi chọn dùng Horovod mà không phải PyTorch hay các thư viện khác âu cũng bởi Horovd dùng song song 2 backend MPI cho CPU và NCCL cho GPU và cái lí do thứ 2 là bởi repo này đạt 12k sao github.
Link repo: https://github.com/horovod/horovod
Tại sao lại là Horovod ?
-
Mục đích chính: Từ 1 script huấn luyện mô hình trên 1 GPU, Horovod sẽ hỗ trợ người dùng huấn luyện trên nhiều GPU.
-
Lợi ích: Khi ở Uber, các dev đã thấy rằng việc sử dụng MPI giúp cho người dùng code ít hơn và dễ đọc hơn giải pháp Distributed TensorFlow. Với 1 script huấn luyện được wrap bởi Horovod, nó có thể chạy trên 1 GPU, nhiều GPU hay nhiều máy mà không thay đổi code của người dùng quá nhiều.
Các bạn chỉ cần chú ý tới màu xanh nhạt thôi bởi cái Horovod (RDMA) đòi hỏi card network đặc biệt mà tôi không có  . Như trên hình với việc tăng số lượng GPU cũng tăng số lượng ảnh được xử lý. Với các công ty vừa và nhỏ việc xây dựng 1 server nhiều GPU khá khó khăn, thường cách 1 thời gian họ mới có tài chính để build thêm máy GPU. Vì vậy giải pháp huấn luyện mô hình trên nhiều máy tính có GPU lại càng cần thiết.
. Như trên hình với việc tăng số lượng GPU cũng tăng số lượng ảnh được xử lý. Với các công ty vừa và nhỏ việc xây dựng 1 server nhiều GPU khá khó khăn, thường cách 1 thời gian họ mới có tài chính để build thêm máy GPU. Vì vậy giải pháp huấn luyện mô hình trên nhiều máy tính có GPU lại càng cần thiết.
Cài đặt
VIệc cài đặt các backend như MPI hay NCCL khá là khoai với nhiều người, bởi tùy hệ điều hành khác nhau có thể phát sinh các lỗi khác nhau và với một người không biết gì về C như tôi mà gặp phải lỗi coredump chắc đầu hàng sớm 
Chính vì vậy cách nhanh nhất để sử dụng Horovod là cài qua Docker. Bạn có thể tìm thấy horovod image qua DockerHub:
https://hub.docker.com/r/horovod/horovod
Dùng câu lệnh để kéo horovod image mới nhất về. (có thể thêm sudo nếu bị permission denied)
docker pull horovod/horovod
Nếu bạn không dùng Docker thì có thể dùng pip để tải về chẳng hạn.
Với CPUs :
pip install horovod
Với GPUs có NCCL :
HOROVOD_GPU_OPERATIONS=NCCL pip install horovod
Sau khi tải xong thì bạn cứ để đấy trước đã để tôi giải thích một chút khái niệm của MPI như tôi thông báo ở trên.
Concepts
Horovod hoạt động như thế nào ?
Horovod huấn luyện mô hình qua nhiều GPUs bằng chiến thuật "data parallelization". Tôi sẽ giải thích đơn giản qua ví dụ sau:
Bạn có 2 GPU và 1 bộ data từ 1 đến 10. Bạn chia bộ data đấy thành 5 phần tương ứng 5 batch
[[1, 2],[3, 4],[5, 6],[7, 8],[9, 10]]
Bạn bỏ batch 1 vào GPU 1 và cùng lúc đó batch 2 cũng gửi tới GPU 2. Mỗi một GPU sử dụng data để tính gradient độc lập. Các kết quả gradient sẽ được đồng bộ hóa giữa các GPU, tính trung bình rồi mới apply vào mô hình.
Cả quá trình được tổng kết thông qua 5 bước:
- Mỗi một worker ( 1 cụm máy tính có 1 máy làm master và nhiều máy làm worker ) lưu trữ 1 bản sao trọng số của mô hình và 1 bản sao của bộ dữ liệu.
- Sau khi nhận được tín hiệu từ master, mỗi worker sẽ dùng các batch khác nhau của bộ dữ liệu và tính gradient trên các batch đó.
- Các workers sử dụng thuật toán ring all-reduce để đồng bộ hóa các gradients của mình bằng cách tính trung bình các gradients này.
- Các worker áp dụng bản gradient đã được cập nhật này vào mô hình trên từng máy.
- Batch tiếp theo được huấn luyện.
Well, nếu tất cả đều thuận lợi thì không nói làm gì còn nếu bởi một nguyên nhân nào đó các trọng số ở các mô hình của các worker khác nhau, các cập nhật trọng số của mô hình không đồng bộ sẽ dẫn đến việc huấn luyện mô hình sẽ cho ra kết quả khác nhau.
Sơ qua về thuật toán Allreduce
May mắn là thuật toán Allreduce xử lý được vấn đề này. Về cơ bản thì các worker sẽ chia sẻ dữ liệu ( trọng số chẳng hạn ) với nhau và áp dụng một phép toán ( cộng, nhân, max, min ). Sau khi áp dụng phép toán này, các mảng trên các tiến trình sẽ quy về một mảng duy nhất và trả về các tiến trình của workers.
Ví dụ:
Trước:
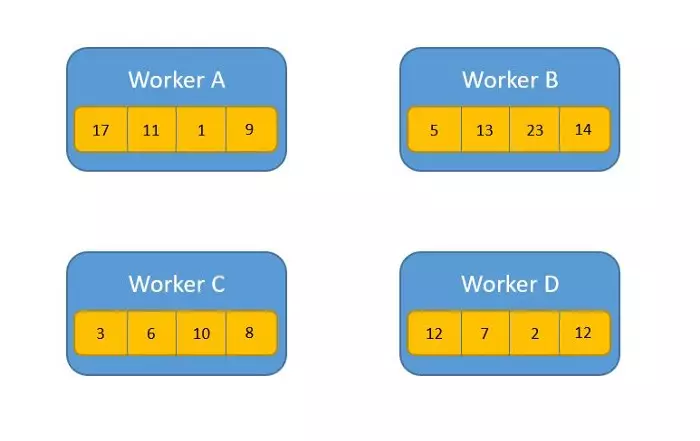
Sau khi áp dụng Allreduce
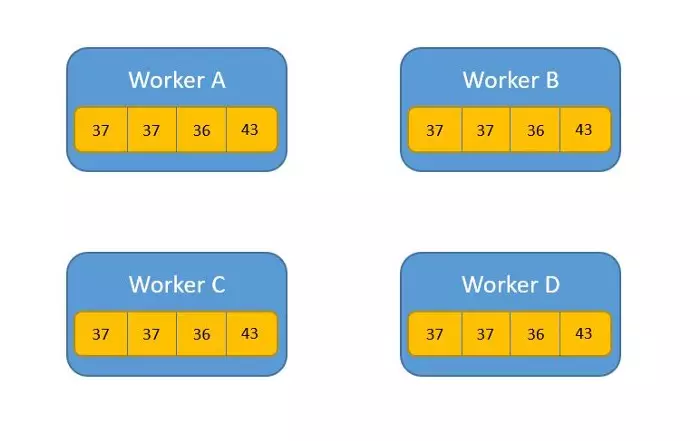
Thuật toán này hoạt động ra sao ?
- Cách 1: Trao đổi từng mảng data ở các workers và áp dụng các phép toán :
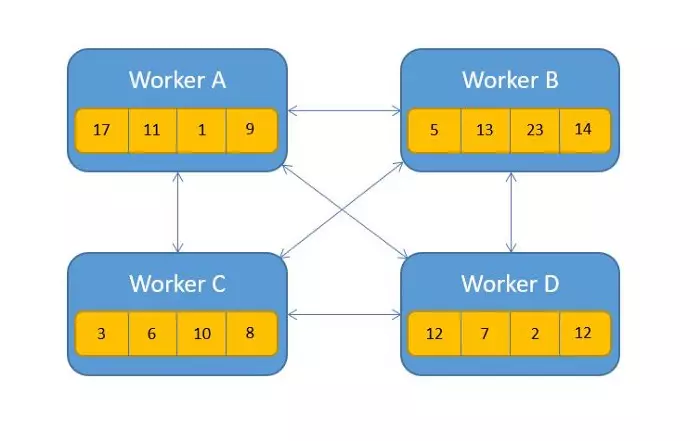
Cách này không lí tưởng cho lắm, bởi các message từ worker này tới worker kia có thể bị lặp, dư thừa dẫn đến bottleneck ở network.
- Cách 2: Lựa chọn một worker làm chính, các worker còn lại gửi dữ liệu tới worker này. Worker này sẽ áp dụng phép toán rồi sau đó phân phối lại kết quả tới các worker kia.
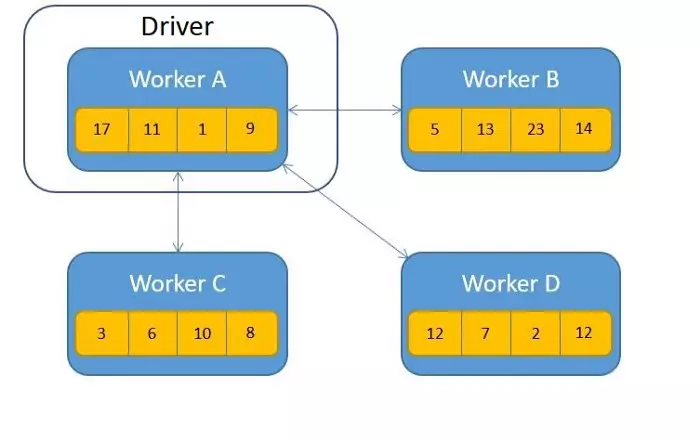
Cách này cũng có vấn đề  , nếu các worker đồng loạt gửi dữ liệu tới worker chính này sẽ dẫn đến hiện tượng nghẽn cổ chai ( bottleneck )
, nếu các worker đồng loạt gửi dữ liệu tới worker chính này sẽ dẫn đến hiện tượng nghẽn cổ chai ( bottleneck )
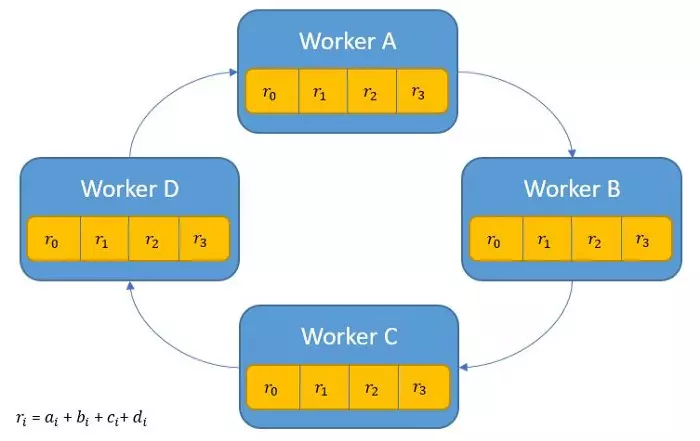
- Cách 3: Ring Allreduce có 2 phase. Phase 1: share-reduce. Phase 2: share-only
Phase 1: mỗi tiến trình p gửi dữ liệu tới tiến trình (p+1) % p ( % là phép tính lấy số dư ). Các mảng dữ liệu có độ dài n chia cho p thành các phần nhỏ hơn ( chunks ). Các chunks này sẽ được đánh index i. Mỗi tiến trình gửi các chunks tới tiến trình tiếp theo => sự trao đổi dữ liệu này tạo thành 1 vòng tròn giữa các tiến trình.
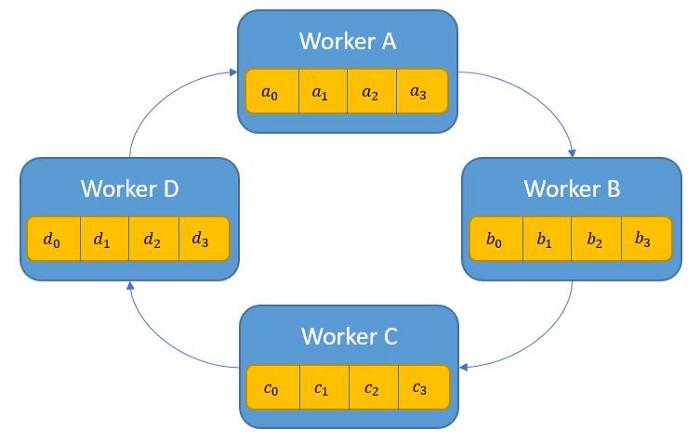
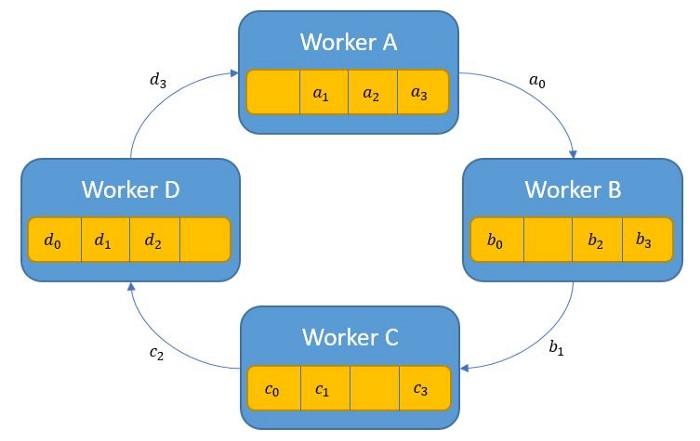
Khi nhận được dữ liệu của tiến trình trước đó thì tiến trình hiện tại sẽ áp dụng phép toán reduce và trả kết quả cho tiến trình tiếp theo. Trong hình này là phép toán cộng:
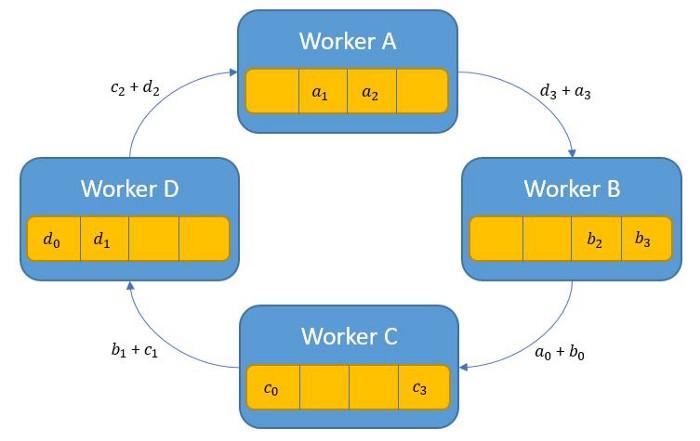
Để áp dụng được phép toán reduce trong này sau đó trả kết quả cho các tiến trình tiếp theo thì phép tính này cần có tính chất liên kết và giao hoán. Phase 1 kết thúc khi mỗi tiến trình giữ kết quả cuối của các chunks sau khi đi qua phép tính tổng.
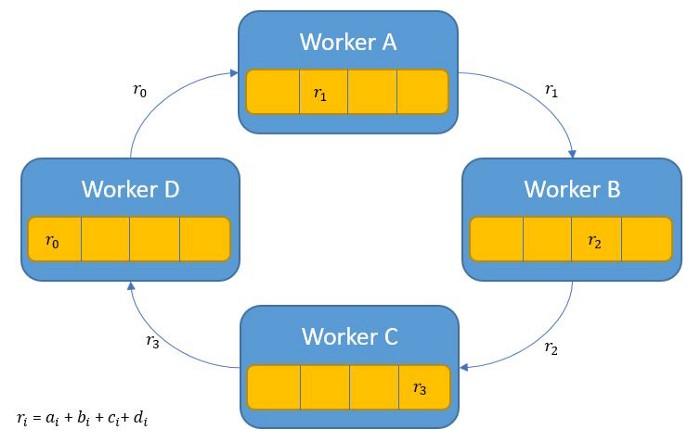
Phase 2 chỉ có chia sẻ kết quả chunks tới các mảng nên dễ hiểu hơn hẳn 
Ngoài thuật toán Allreduce còn một số thuật toán khác sẽ được đề cập ngay bên dưới
Các thuật toán truyền dữ liệu của MPI và NCCL
Quay trở lại vấn đề ban đầu, Horovod hoạt động như nào ? Core của Horovod based trên MPI ( Message Passing Interface ) nên bao hàm các thuật ngữ như: size, rank, local rank, allreduce, allgather, broadcast, and alltoall. Để hiểu đơn giản thì tôi sẽ giải thích qua ví dụ vậy, các bạn có thể đọc qua đây : https://github.com/horovod/horovod/blob/master/docs/concepts.rst . Còn để giải thích chi tiết các thuật toán này thì các bạn đọc qua đây nhé : https://mpitutorial.com/tutorials/mpi-scatter-gather-and-allgather/
Giả dụ tôi có 4 servers, mỗi server có 4 GPU. Nếu tôi chạy qua 1 script huấn luyện thì:
- Size là số tiến trình, do tôi có 4 host - 4 GPUs nên trong trường hợp này là 16
- Rank là unique ID của 16 tiến trình, từ 0 tới 15
- Local rank là unique ID của 4 server, từ 0 tới 3
- Allreduce tôi có giải thích bên trên. Còn đây là hình minh họa của MPI và NCCL :
- Allgather là một thuật toán giúp gom dữ liệu từ các tiến trình
- Broadcast là một thuật toán cho phép một tiến trình chia sẻ dữ liệu tới tất cả các tiến trình khác dựa theo xếp hạng rank.
- Reducescatter là một thuật toán thực hiện gần giống thuật toán reduce ( tính tổng ) , ngoại trừ việc kết quả sẽ được phân tán qua từng rank , mỗi rank sẽ chứa 1 chunk dữ liệu dựa trên rank index.
- Alltoall là một thuật toán trao đổi dữ liệu giữa các tiến trình, hữu dụng khi implement kiến trúc Neural Network trải dài trên nhiều thiết bị.
Sử dụng
Nếu bạn từng dùng qua Torch distributed thì chắc sẽ làm quen rất nhanh với Horovod bởi concept của mấy thư viện này khá giống nhau.
Cách tốt nhất để implement Horovod vào một file training là đọc example của họ, vì vậy tôi sẽ phân tích file training của mnist keras cho bạn đọc dễ hiểu.
import math import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K import horovod.tensorflow.keras as hvd # Horovod: initialize Horovod.
hvd.init() # Horovod: pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
K.set_session(tf.Session(config=config)) batch_size = 128
num_classes = 10 # Horovod: adjust number of epochs based on number of GPUs.
epochs = int(math.ceil(12.0 / hvd.size())) # Input image dimensions
img_rows, img_cols = 28, 28 # The data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data() if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols)
else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples') # Convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax')) # Horovod: adjust learning rate based on number of GPUs.
opt = keras.optimizers.Adadelta(1.0 * hvd.size()) # Horovod: add Horovod Distributed Optimizer.
opt = hvd.DistributedOptimizer(opt, backward_passes_per_step=1) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=opt, metrics=['accuracy']) callbacks = [ # Horovod: broadcast initial variable states from rank 0 to all other processes. # This is necessary to ensure consistent initialization of all workers when # training is started with random weights or restored from a checkpoint. hvd.callbacks.BroadcastGlobalVariablesCallback(0),
] # Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting them.
if hvd.rank() == 0: callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch}.h5')) model.fit(x_train, y_train, batch_size=batch_size, callbacks=callbacks, epochs=epochs, verbose=1 if hvd.rank() == 0 else 0, validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Follow theo từng bước nhé:
- Import Horovod
import horovod.tensorflow.keras as hvd
Init Horovod
hvd.init()
- Gắn GPU vào 1 tiến trình local rank ( local rank là các ID của máy tính ) để tránh việc lạm dụng tài nguyên máy. 1 GPU tương ứng với 1 tiến trình ( process )
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
- Điều chỉnh số epoch dựa trên số lượng GPU
epochs = int(math.ceil(12.0 / hvd.size()))
- Điều chỉnh learning rate tương ứng với số lượng worker. Cũng như vậy, kích thước của batch sẽ được điều chỉnh theo số lượng worker. Tỉ lệ learning rate tăng lên để mô hình học nhanh hơn, bù đắp cho việc thời gian huấn luyện tăng lên do batch size tăng.
opt = keras.optimizers.Adadelta(1.0 * hvd.size())
- Wrap optimizer với Horovod
hvd.DistributedOptimizer. Về cơ bản thì việc tính toán vẫn được thực hiện bởi optimizer ban đầu ( cụ thể trong ví dụ trên là Adadelta ). Horovod có nhiệm vụ tính trung bình gradients của các worker bằng thuật toán allreduce hoặc allgather rồi phân phối kết quả tới các worker để đợi batch tiếp theo.
opt = hvd.DistributedOptimizer(opt, backward_passes_per_step=1)
- Broadcast các biến khởi tạo từ worker rank 0 tới tiến trình trên các worker khác nhằm đảm bảo sự đồng nhất của các worker trong quá trình training với trọng số ngẫu nhiên hoặc khôi phục lại từ checkpoint.
callbacks = [ hvd.callbacks.BroadcastGlobalVariablesCallback(0),
]
- Chỉnh sửa code để lưu checkpoint duy nhất trên worker 0 tránh trường hợp các worker khác làm hỏng checkpoint.
if hvd.rank() == 0: callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch}.h5'))
Ok xong rồi đấy, chỉ đơn giản vậy thôi, tiếp sau đây chúng ta sẽ đến phần chạy Horovod trên Docker.
Running Horovod
Để tránh gặp quá nhiều bug thì tôi khuyến khích dùng container để chạy Horovod. Bạn có thể chọn 1 trong 3 version: CPU, GPU và Ray ( 1 thư viện mã nguồn mở cho phép distributed training và hyperparam tuning ). Ở đây tôi chọn dùng GPU để thử nghiệm
Running Horovod trên 1 máy
Sau khi pull Horovod GPU image về máy, mở terminal lên và dùng nvidia-docker để run container
nvidia-docker run --name main -it horovod/horovod
Còn nếu container có sẵn :
nvidia-docker start main
nvidia-docker exec -it main /bin/bash
Giờ chúng ta sẽ ở bên trong môi trường của container
_@.com:/horovod/examples#
Do máy mình có 1 GPU nên ở đây mình chỉ chạy đúng 1 process
horovodrun -np 1 -H localhost:1 python pytorch/pytorch_mnist.py
Output
Để đo thời gian chạy bạn có thể dùng thêm lệnh time ở đầu câu lệnh horovod
time horovodrun -np 1 -H localhost:1 python pytorch/pytorch_mnist.py
Running Horovod trên nhiều máy
Đầu tiên tôi cần đảm bảo máy 1 của tôi có thể ssh vào máy 2 mà không cần password và ngược lại máy 2 cũng có thể ssh vào máy 1 không cần password. Vì vậy tôi follow theo hướng dẫn này :
http://www.linuxproblem.org/art_9.html
Việc này đảm bảo 2 máy có thể giao tiếp với nhau mà không bị chặn lại bởi lớp bảo mật mật khẩu của ssh.
Ở cả 2 máy, copy các file trong folder ssh vào folder này /mnt/share/ssh . Nếu chưa có folder thì dùng lệnh mkdir để tạo folder. Đảm bảo trong folder ssh của share có 2 file id_rsa và authorized_keys vì 2 file này cho phép bạn ssh passwordless authentication.
Ở máy 1, tôi đặt làm máy chính, dùng nvidia-docker để chạy container với network=host ( không dùng network overlay của docker ) , mount folder /mnt/share/ssh này với folder /root/.ssh trong container
nvidia-docker run --name main -it --network=host -v /mnt/share/ssh:/root/.ssh horovod/horovod
Đừng vội chạy câu lệnh horovodrun, chúng ta cần chạy horovod container ở máy 2 để mở kết nối giữa 2 container. Duy trì kết nối bằng sleep infinity
nvidia-docker run --name worker -it --network=host -v /mnt/share/ssh:/root/.ssh horovod/horovod bash -c "/usr/sbin/sshd -p 12345; sleep infinity"
Giải thích một chút đoạn này /usr/sbin/sshd -p 12345 . Tại sao tôi không dùng port 22 mặc định của ssh, bởi vì đây là kết nối ssh của 2 môi trường container, để đường truyền không bị ảnh hưởng tôi thêm config vào ssh để bọn nó trỏ vào cổng 12345.
Được rồi, sau khi chạy 2 container, chúng ta sẽ thử train pytorch mnist bằng 2 GPU sử dụng câu lệnh horovodrun ( tôi chạy câu lệnh này trong container ở máy 1 )
horovodrun -np 2 -H localhost:1,host1:1 -p 12345 python pytorch/pytorch_mnist.py
Trong command này, host1 là tên của máy 2 mà tôi setup cùng với port 12345 trong folder ssh. Cụ thể là tôi tạo thêm 1 file ssh config bởi vì horovodrun không nhận cách viết _@.com_ADDRESS:number_of_gpus.
Trong /mnt/share/ssh/ tạo thêm 1 file config
Host host1 HostName 10.0.xx.xxx User root Port 12345
Nếu các bạn có nhiều máy hơn thì cũng chạy câu lệnh này để duy trì liên kết giữa các máy
hostN$ nvidia-docker run --name worker -it --network=host -v /mnt/share/ssh:/root/.ssh horovod/horovod bash -c "/usr/sbin/sshd -p 12345; sleep infinity"
Một số thứ cần lưu ý khi train trên nhiều máy
- Việc training nhiều máy này phụ thuộc khá nhiều vào network nên bạn phải xác định khi train : 2 máy phải xài cùng 1 network interface. Dùng câu lệnh
ifconfig -ađể xác định localhost interface name, của tôi làenp3s0. Lần đầu tôi chạy horovod không được cũng là do không xài chung network interface. Vì vậy trong câu lệnh horovodrun bạn thêm argument--network-interface.
horovodrun --network-interfaces "enp3s0" -np 2 -H localhost:1,host1:1 -p 12345 python pytorch/pytorch_mnist.py
- Như tôi nói ở trên, network chiếm phần quan trọng trong việc training nhiều máy. Tốc độ truyền dẫn dữ liệu cần phải nhanh để tránh bottleneck network. Tôi đã gặp trường hợp này, khi mà train 1 máy tôi chỉ tốn 30s còn 2 máy tốn 1p30'. Do tốc độ mạng LAN ở máy 1 của tôi có mỗi 10mb/s
 . Bên Horovod có hẳn một hướng dẫn nếu bạn xài Mellanox NICs tăng 20% hiệu suất.
. Bên Horovod có hẳn một hướng dẫn nếu bạn xài Mellanox NICs tăng 20% hiệu suất.
Train 1 GPU
Train 2 node 2 GPU
Lời kết
Vậy là xong, tôi mong các bạn cảm thấy hữu ích khi đọc bài viết này, tránh mắc các lỗi ngớ ngẩn mà tôi gặp phải .
References
https://github.com/horovod/horovod
https://spell.ml/blog/distributed-model-training-using-horovod-XvqEGRUAACgAa5th
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/operations.html