Mở
Vừa qua cũng thấy nhiều bạn tìm hiểu về chatGPT, các kiến thức chủ đạo như mô hình Tranformer
https://viblo.asia/p/tu-transformer-den-language-model-bai-1-bat-dau-voi-kien-truc-mo-hinh-transformer-38X4EN1gJN2
. Mình dù không hiểu nhiều lắm, nhưng dựa trên các thông tin trên internet, cũng vọc vạch làm một số demo nhỏ cho việc train model GPT-2, ở mức newbie , hy vọng a.e chạy phát cho vui để lấy cảm hứng học được nhiều hơn 
Load the dataframe
import pandas as pd df = pd.read_csv('../data/Restaurant_Reviews.tsv', sep='\t')
df = df.rename(columns={'Review': 'text'})
df Clean text một chút.
import nltk
nltk.download('stopwords')
import re
from nltk.corpus import stopwords def clean_text(text): # Make text lowercase text = text.lower() # Remove text in square brackets text = re.sub('\[.*?\]', '', text) # Remove links text = re.sub('https?://\S+|www\.\S+', '', text) # Remove punctuation text = re.sub('[^a-zA-Z0-9\s]+', '', text) # Remove words containing numbers text = re.sub('\w*\d\w*', '', text) # Remove stop words stop_words = set(stopwords.words('english')) words = text.split() filtered_words = [word for word in words if word not in stop_words] text = ' '.join(filtered_words) # Remove extra whitespace text = re.sub('\s+', ' ', text).strip() return text # Apply the clean_text function to all text in the 'text' column
df['text'] = df['text'].apply(clean_text) # Show the updated dataframe
df.head()
Phần tách thành những token nhỏ hơn
import re contents = df['text'].values.tolist()
def santilize(x): t = x.split(' ') new_list = [item for item in t if item is not None] return new_list
content_tokens = list(map(santilize, contents))
print('content_tokens', content_tokens[0]) Load model pretrained của GPT2
from transformers import AutoTokenizer, AutoModelWithLMHead
modelMaskedLM = AutoModelWithLMHead.from_pretrained('gpt2')
tokenizerVI = AutoTokenizer.from_pretrained('gpt2')
Add thêm vocabulary mới cho model.
def flatten_list(lst): flattened = [] for item in lst: if isinstance(item, list): flattened.extend(flatten_list(item)) else: flattened.append(item) return flattened sentence_tokens = flatten_list(content_tokens)
print('sentence_tokens', set(sentence_tokens[0:30]))
new_tokens = set(sentence_tokens) - set(tokenizerVI.get_vocab().keys())
print('length before add:', len(tokenizerVI.vocab))
tokenizerVI.add_tokens(list(new_tokens))
print('length after add:', len(tokenizerVI.vocab))
modelMaskedLM.resize_token_embeddings(len(tokenizerVI)+1)
Viết file những câu + token sẽ train để review.
# Open the file in write mode
with open("../data/news_output.txt", "w") as file: # Truncate the file to the current position of the file pointer file.truncate() print(content_tokens[:20])
with open("../data/news_output.txt", "w") as file: for t in content_tokens[:2]: file.write(' '.join(t) + "\n") tokenizerVI.add_special_tokens({'pad_token': '[PAD]'})
Encode thành list, seq lấy max=512
max_seq_length = 512
encoded_texts = [tokenizerVI.encode(text, truncation=True, max_length=max_seq_length) for text in contents]
print(encoded_texts[:2])
Train thôi 
from transformers import LineByLineTextDataset, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments # training_data = LineByLineTextDataset(
# tokenizer=tokenizerVI,
# file_path='../data/news_output.txt',
# block_size=1024,
# ) data_collator = DataCollatorForLanguageModeling( tokenizer=tokenizerVI, mlm=False, mlm_probability=0.15
) training_args = TrainingArguments( output_dir="./results-text", overwrite_output_dir=True, num_train_epochs=12, per_device_train_batch_size=16, per_device_eval_batch_size=8, warmup_steps=1000, logging_steps=500,
) trainer = Trainer( model=modelMaskedLM, args=training_args, train_dataset=encoded_texts, data_collator=data_collator
) trainer.train()
trainer.save_model()
Và rồi xem thử model hoạt động thế nào 
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel text = """
write comment about "Loved this", for restaurant
"""
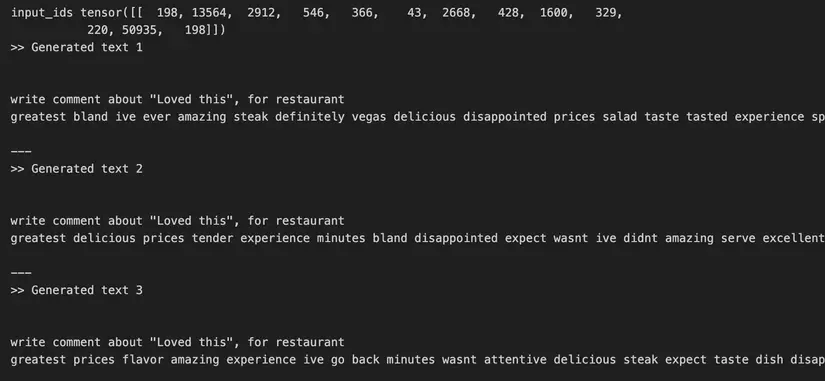
input_ids = tokenizerVI.encode(text, return_tensors='pt')
print('input_ids',input_ids)
max_length = 100 sample_outputs = modelMaskedLM.generate(input_ids,pad_token_id=tokenizerVI.eos_token_id, bos_token_id=tokenizerVI.bos_token_id, eos_token_id=tokenizerVI.eos_token_id, do_sample=True, max_length=max_length, min_length=max_length, top_k=40, num_beams=5, early_stopping=True, no_repeat_ngram_size=2, num_return_sequences=3) for i, sample_output in enumerate(sample_outputs): print(">> Generated text {}\n\n{}".format(i+1, tokenizerVI.decode(sample_output.tolist()))) print('\n---') - Kết quả cùng thầy zui zui, dù không chắc có hiệu quả không