1. Introduction
Xin chào các bạn, dạo gần đây tôi có đi tìm hiểu về các mô hình sequence to sequence kết hợp với cơ chế attention để xử lý dữ liệu dạng chuỗi (sequence). Các dữ liệu dạng chuỗi các bạn có thể gặp như: dữ liệu text, dữ liệu về âm thanh... Các bài toán tiêu biểu xử lý dữ liệu chuỗi có thể kể đến như Machine Translation (dịch chuỗi văn bản từ ngôn ngữ A sang ngôn ngữ B), Text to Speech (chuyển chuỗi văn bản đầu vào thành chuỗi âm thanh tương ứng), NLP (Xử lý ngôn ngữ tự nhiên), ...
Các mô hình học máy, học sâu đang được cải thiện và phát triển liên tục theo thời gian về cả độ chính xác và tốc độ xử lý. Đối với bài toán sequence to sequence cũng vậy. Các mô hình xử lý cho bài toán này từ thuở ban đầu là RNN ( Recurrent Neural Network). Tuy nhiên nếu bạn nào đã tìm hiểu về RNN có thể biết nó có rất nhiều các hạn chế khi phải xử lý các chuỗi đầu vào có kích thước quá dài do không lưu trữ đc thông tin của chuỗi ở khoảng cách xa và sự mất mát đạo hàm khiến mô hình không thể học được. Và cứ có nhược điểm như vậy thì các mô hình sau mới được nghiên cứu ra. Điển hình là LSTM ra đời nhằm khắc phục phần nào vấn đề khi xử lý các chuỗi đầu vào có kích thước dài của RNN. Về sau này với sự ra đời của cơ chế Attention thì các mô hình RNN và LSTM cũng đạt được hiệu quả hơn rõ rệt khi xử lý các chuỗi đầu vào. Tiếp nối sau đó thì mô hình Transformer ra đời như là một sự bứt phá trong các bài toán sequence to sequence, mô hình này vừa tận dụng được sức mạnh của cơ chế attention vừa tận dụng được khả năng tính toán song song của GPU vì mô hình này có thể xử lý song song chuỗi đầu vào thay vì xử lý tuần tự như các mô hình RNN hay LTSM trước đó.
Với tôi, tôi lại thích xử lý các bài toán liên quan đến dữ liệu ảnh hơn, vì thỉnh thoảng có thể đưa một số ảnh của người mình thích hoặc là idol của mình vào model để thử nghiệm cho vui  . Chính vì vậy tôi tự hỏi rằng có sự giao thoa nào giữa 2 bài toán xử lý dữ liệu vào là ảnh và xử lý dữ liệu vào là chuỗi không thì bùm
. Chính vì vậy tôi tự hỏi rằng có sự giao thoa nào giữa 2 bài toán xử lý dữ liệu vào là ảnh và xử lý dữ liệu vào là chuỗi không thì bùm  Vision Transformer là câu trả lời.
Vision Transformer là câu trả lời.
Lấy ý tưởng xử lý ảnh đầu vào như một chuỗi, Vision Transformer là sự kết hợp của 1 phần kiến trúc của Transformer và các khối MLP (Multilayer Perceptron). Mô hình này nhằm giải quyết bài toán phân loại ảnh (Image classification). Bài viết này là những kiến thức được tôi note lại trong quá trình tìm hiểu, mục đích là có nơi lưu lại kiến thức để sau này quên thì có chỗ đọc lại, hoặc có thể chia sẻ được chút ít nội dung cho các bạn đọc.
Thôi không linh tinh luyên thuyên nữa, các bạn cùng tôi tìm hiểu kiến trúc của mô hình này nhé 
2. Vision Transformer
Dưới đây là kiến trúc của mô hình Vision Transformer cho bài toán Image Classification.
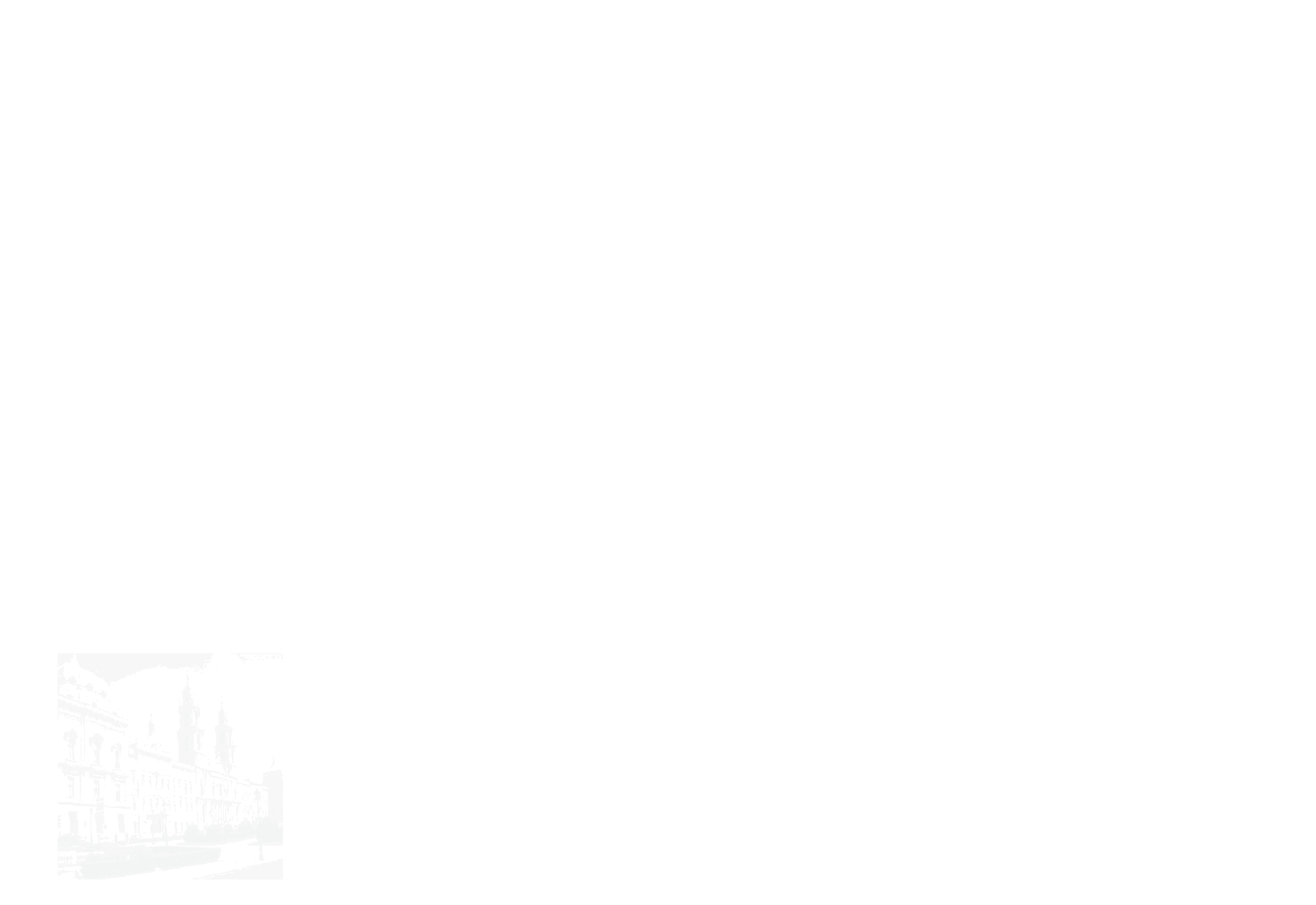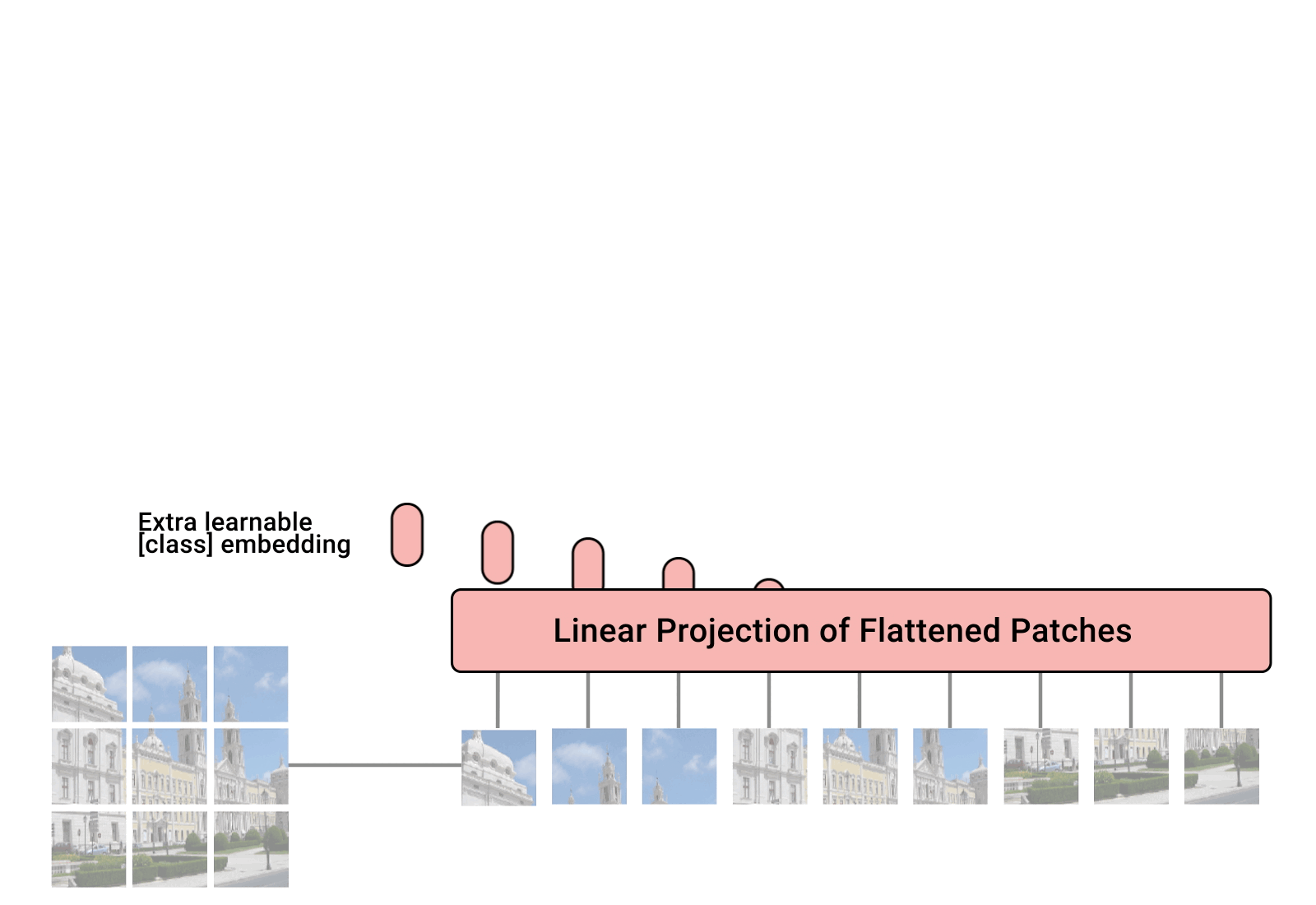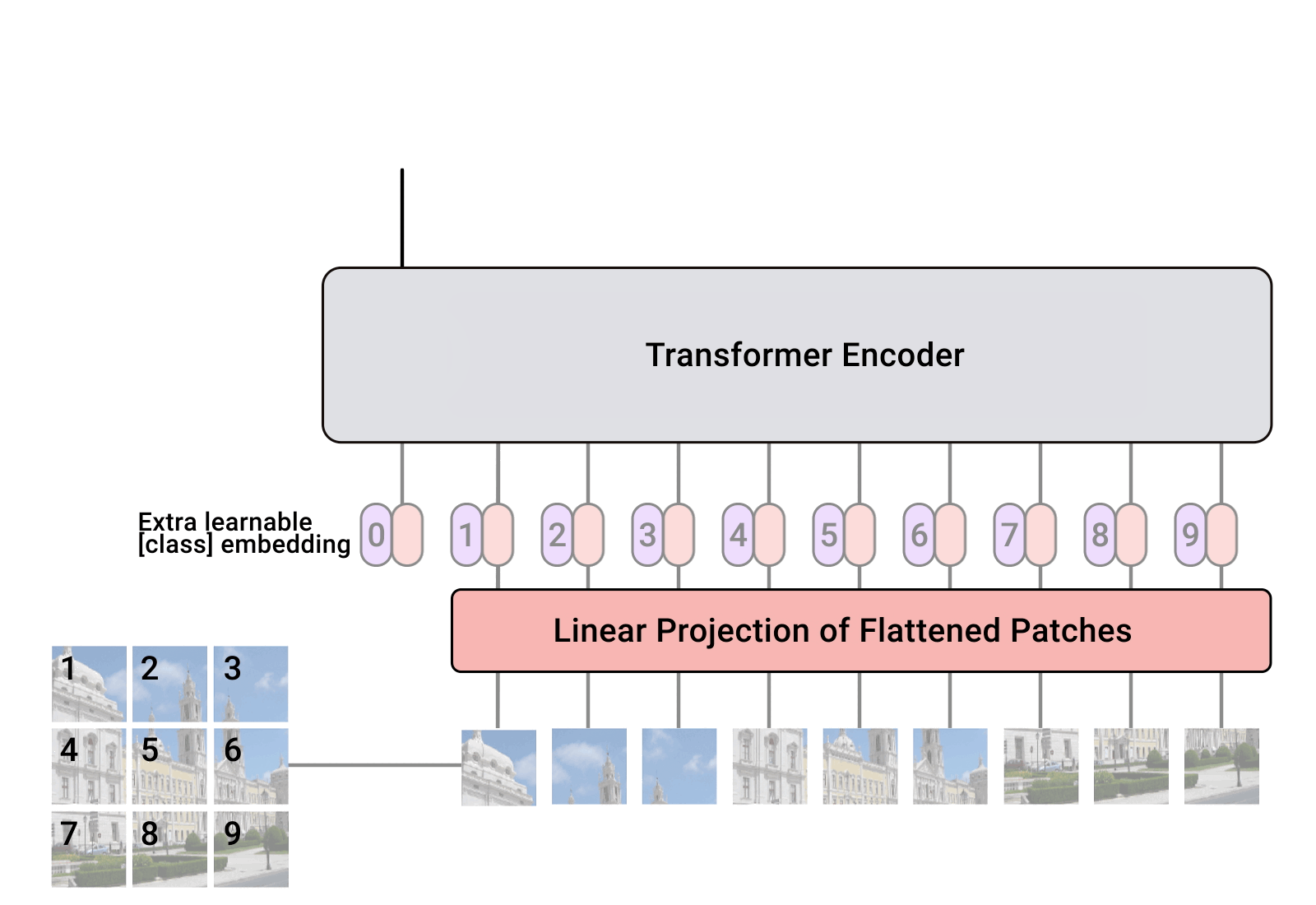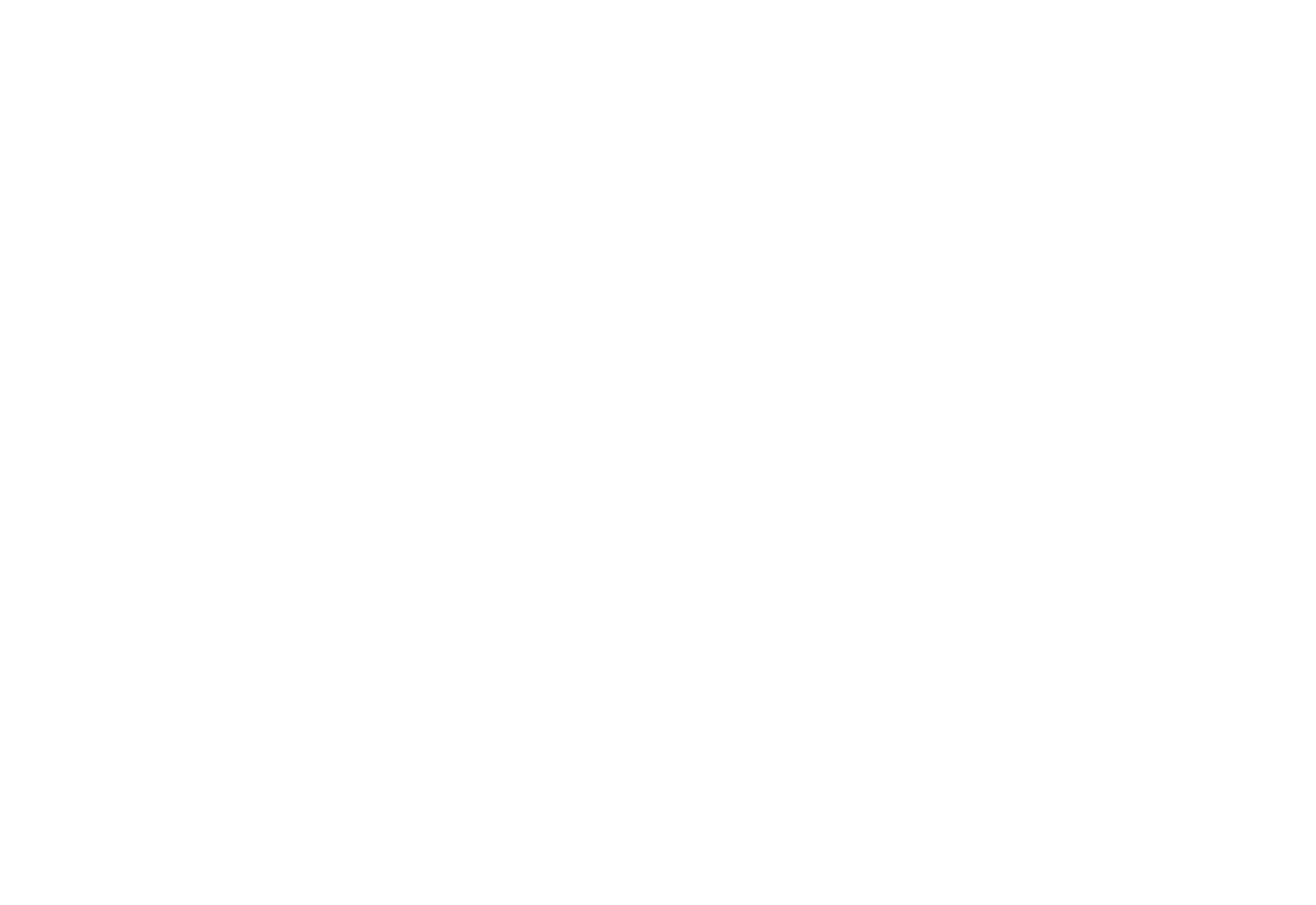
Kiến trúc của mô hình gồm 3 thành phần chính:
- Linear Projection of Flattened Patches
- Transformer encoder.
- Classification head.
Sau đây tôi sẽ đi trình bày về từng thành phần của ViT:
2.1. Linear Projection and Flattend Patches
2.1.1. Patch Embedding
Với các mô hình CNN cho bài toán image classification, ảnh input đầu vào cho mô hình CNN đó là toàn bộ ảnh với kích thước cố định. Tuy nhiên ViT có một cách xử lý khác.
Với mỗi ảnh đầu vào, ViT xử lý bằng cách chia ảnh ra thành các phần có kích thước bằng nhau (patch)

Ví dụ với hình trên, ảnh gốc có kích thước là 48x48, ViT sẽ chia ảnh gốc này ra thành các patch có kích thước 16x16 ( Đây là lý do mà paper có tên An image is worth 16x16 words transformers for image recognition at scale  ). Sau khi chia nhỏ ảnh đầu vào ra ta sẽ có 9 patches tất cả.
). Sau khi chia nhỏ ảnh đầu vào ra ta sẽ có 9 patches tất cả.
Bước tiếp theo, đưa các patches này về dạng vector bằng cách flattend các patches này ra.
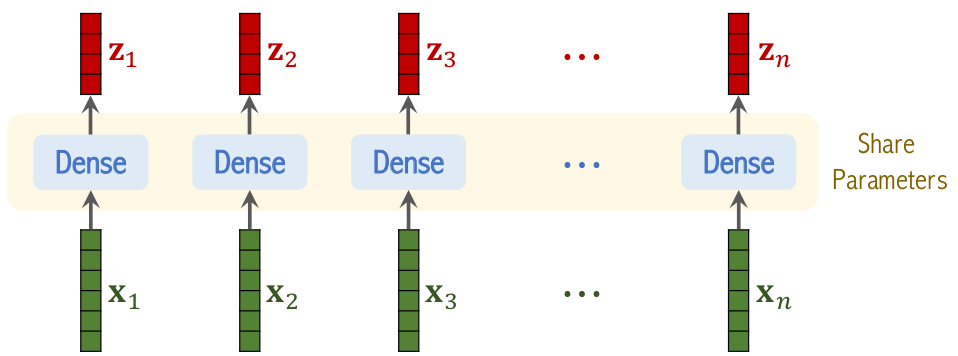 Hình trên mô tả phần Linear Projection.
Thực chất Linear Projection là một lớp Dense với đầu vào là flattend vector của các patches, đầu ra sẽ là embeeding vector tương ứng với từng patch.
Hình trên mô tả phần Linear Projection.
Thực chất Linear Projection là một lớp Dense với đầu vào là flattend vector của các patches, đầu ra sẽ là embeeding vector tương ứng với từng patch.
Trong đó:
- là flattend vector của patch thứ .
- là output tương ứng của khi qua Linear Projection.
- được gọi là ma trận embeeding .
2.1.2. Positional Embeeding
Ý tưởng tương tự với mô hình Transformer gốc. Positional embeeding trong mô hình ViT sẽ chứa thông tin về vị trí của patch trong ảnh (spatial information). Vậy tại sao với dữ liệu là ảnh mà ta vẫn cần spatial information.
Ví dụ như hình dưới đây:

Nếu như ta chỉ Embeeding các patch và đưa vào mô hình Transformer thì với 2 ảnh ở bên trên sẽ hoàn toàn không có sự khác biệt. Do đó ta cần thêm thông tin về vị trí cho mỗi patch.
Sau khi có vector positional embeeding cho mỗi patch ta sẽ cộng các vector này tương ứng với embeeding vector của từng patch đã tính ở trên và thu được các vector embeeding vừa chứa thông tin của vùng ảnh vừa chứa thông tin về vị trí của nó trong ảnh.
2.1.3. Class Embeeding
Phần này tôi đã tìm hiểu trong paper tuy nhiên cũng chưa hiểu rõ cho lắm. Nếu bạn nào hiểu phần này có thể để lại 1 comment giúp tôi nhé! Thanks 
2.2. Transformer Encoder
Trước khi vào tìm hiểu phần này, tôi gợi ý các bạn nên đọc các bài viết sau đây để có cái nhìn cụ thể hơn về cơ chế Attention và mô hình Transformer, đây là những bài viết rất hay của các "tay to" trong team AI của tôi:
- [Machine Learning] Attention, Attention, Attention, ...! - Tác giả Phan Huy Hoàng
- Tản mạn về self Attention - Tác giả Bùi Quang Mạnh
- Transformers - "Người máy biến hình" biến đổi thế giới NLP - Tác giả Nguyễn Việt Anh
Kiến trúc của Transformer Encoder.
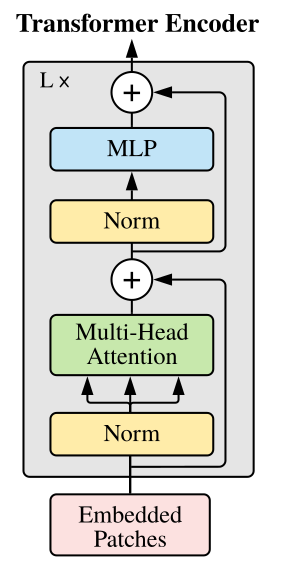
2.2.1. Self Attention layer
Self attention layer là thành phần chính để tạo nên một block trong Transformer Encoder.
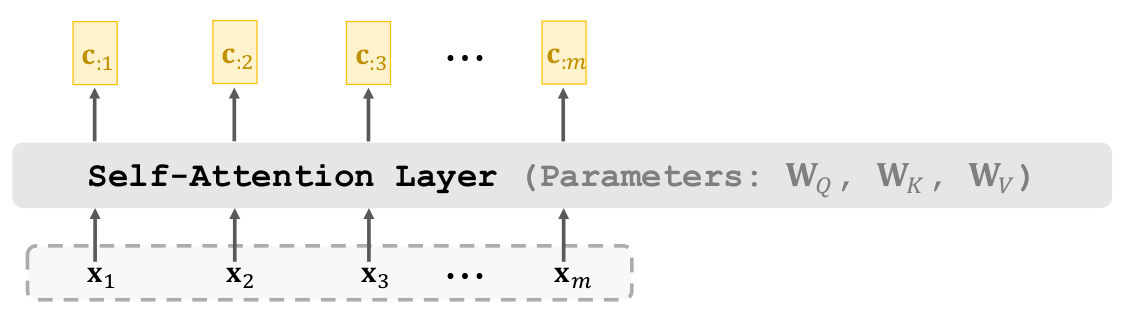
Đầu vào của Self attention layer là một chuỗi
Đầu ra của Self Attention layer là một context vector chứa những thông tin quan trọng nhất của chuỗi đầu vào
Các parameters của layer này bao gồm .
Dưới đây là hình thể hiện cách hoạt động của Self attention layer:
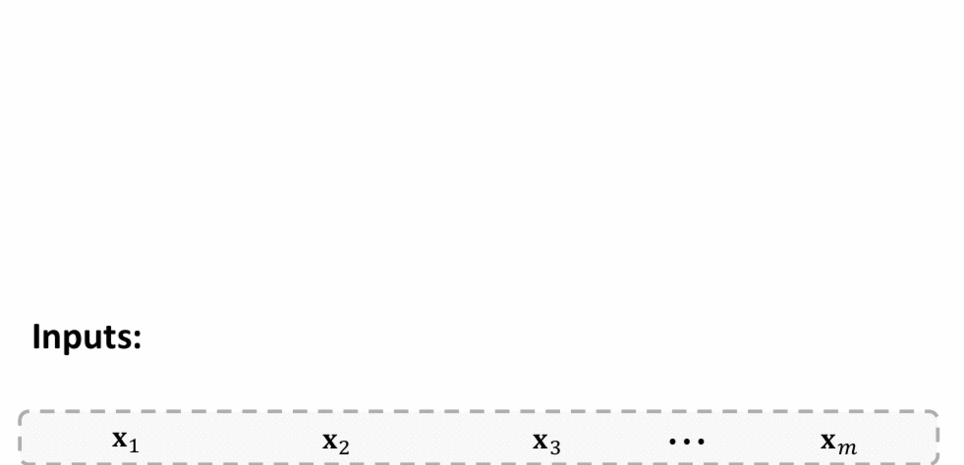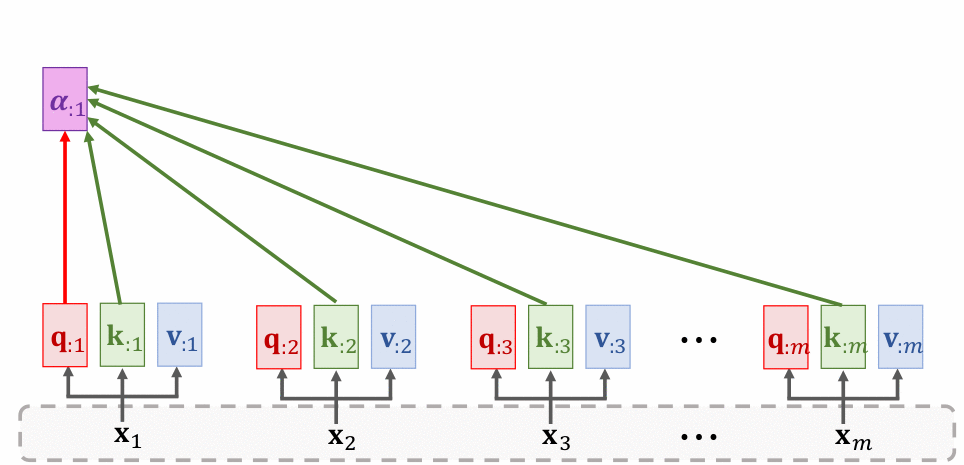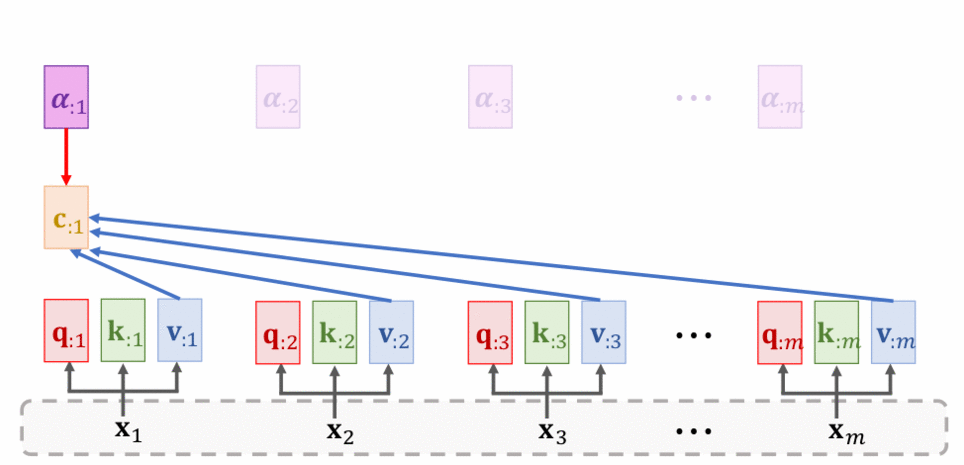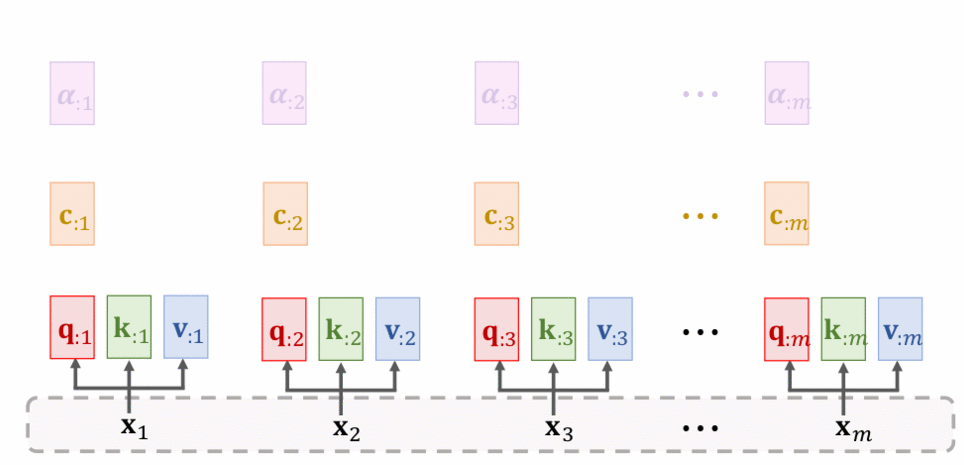 Tôi sẽ đi nói qua về chi tiết từng bước:
Tôi sẽ đi nói qua về chi tiết từng bước:
- Bước 1: Ứng với mỗi của chuỗi đầu vào tính toán các gía trị tương ứng theo công thức , ,
- Bước 2: Tính alignment score tương ứng với theo công thức:
- Bước 3: Tính context vector tương ứng với theo công thức
2.2.2. Multi-head Attention
Bên trên tôi đã trình bày về cấu trúc cũng như cách hoạt động của self attention layer.
Multi-head Attention đơn giản là sự xếp chồng các lớp self attention. Ví dụ 1 lớp Multi-head Attention có lớp self attention. Đầu ra của mỗi lớp self attention có kích thước x thì đầu ra của multi-head attention sẽ là x
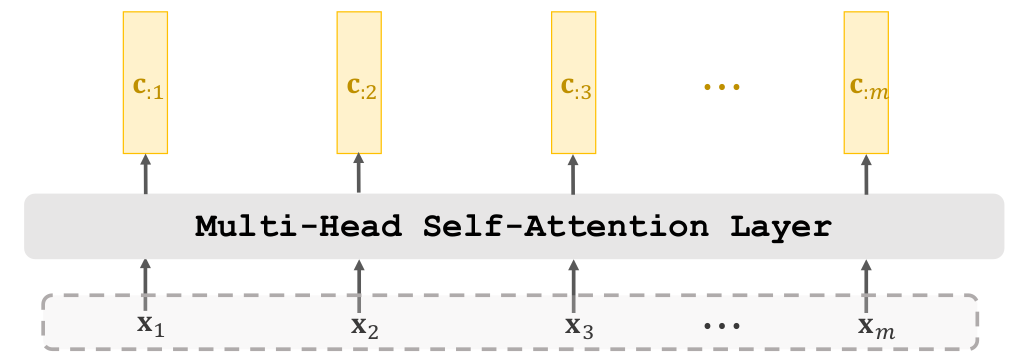
Ngoài thành phần chính là Multi-head Attention thì Transformer Encoder còn được tạo bởi các lớp khác như Add & Norm, Feed Forward, Add & Norm.
2.3. Classification Head
Phần này đơn giản là một khối MLP (Multilayer perceptron) nhận đầu vào là context vector trả về từ Transformer Encoder và đưa ra kết quả cuối cùng là xác suất tương ứng với các class.
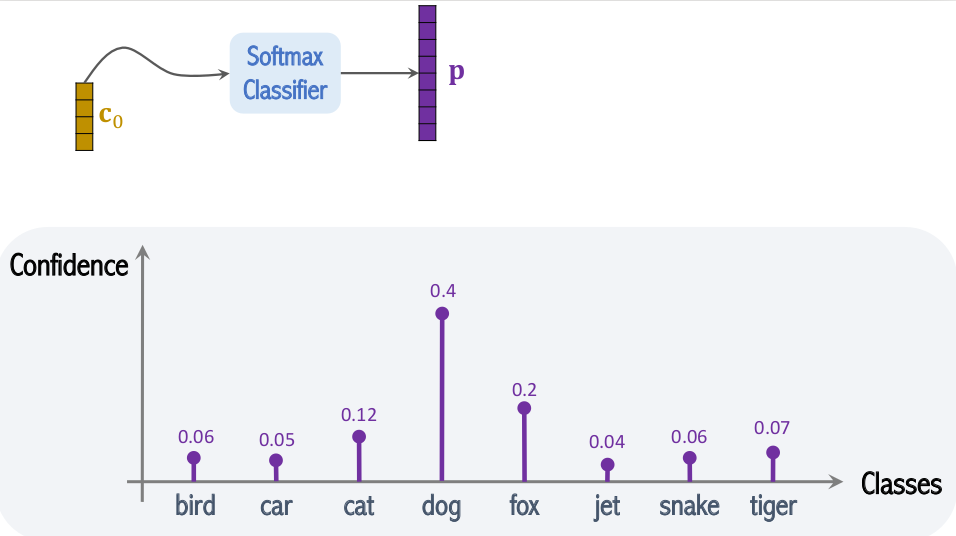
3. Results
3.1. Training strategies
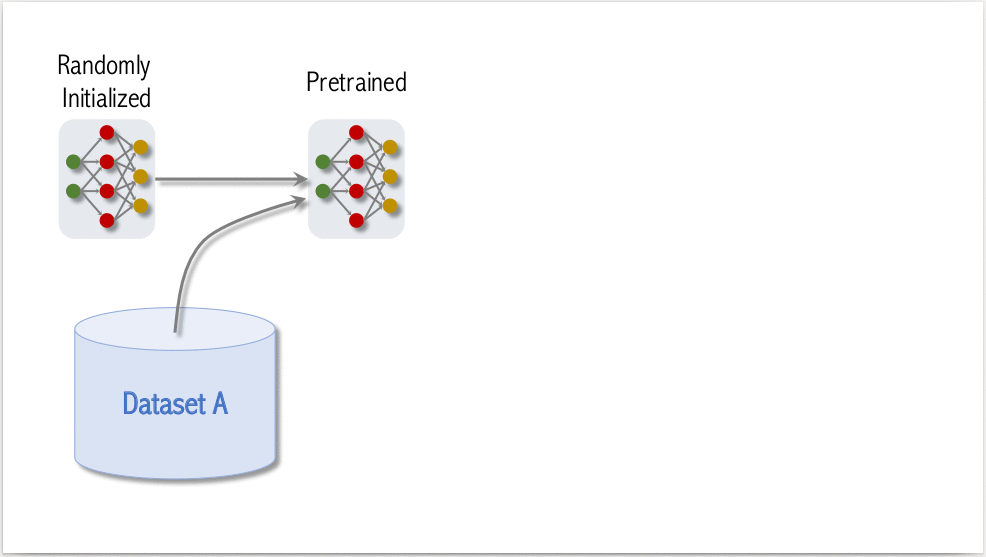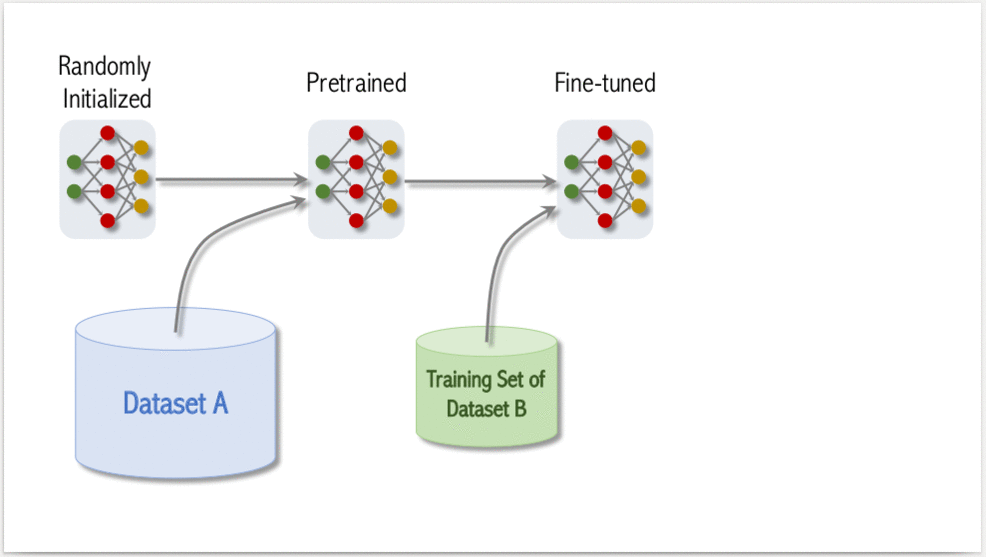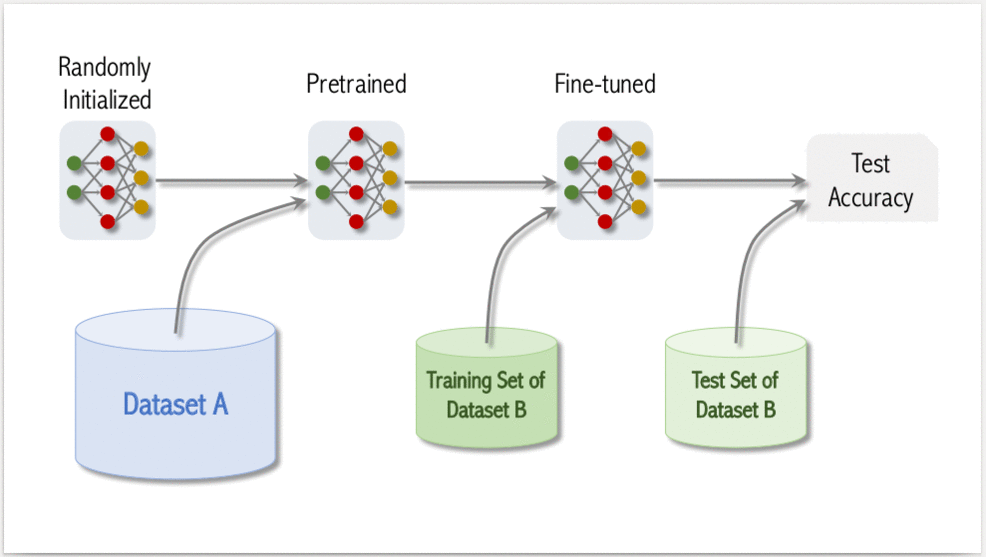 Để đạt được độ chính xác cao, quá trình training ViT gồm có 3 bước:
Để đạt được độ chính xác cao, quá trình training ViT gồm có 3 bước:
- Pre-Training: Khởi tạo model và training trên tập Dataset A, Dataset A thường là một tập dataset với kích thước lớn.
- Fine-tuned: Sử dụng pretrained model ở bước 1, fine tune trên tập dataset B. Dataset B là tập dataset mục tiêu mà ta cần model học tốt trên nó.
- Testing: Sau khi model được fine tune trên tập training của dataset B nó sẽ được đánh giá trên tập Test của dataset B. Các thông số đánh giá ở bước này sẽ thể hiện performance của model.
Được đề cập trong paper. Các tác giả sử dụng 3 tập dữ liệu cho việc huấn luyện mô hình ViT. Chi tiết các tập dữ liệu như ở bảng dưới đây.
| Dataset | Số lượng samples | Số lượng class |
|---|---|---|
| ImageNet (Small) | 1.3 M | 1K |
| ImageNet-21K (Medium) | 14 M | 21K |
| JFT (Big) | 300 M | 18K |
3.2. Classification accuracies
Với chiến lược training như trên thì ViT khi so sánh với ResNet đạt kết quả như sau:
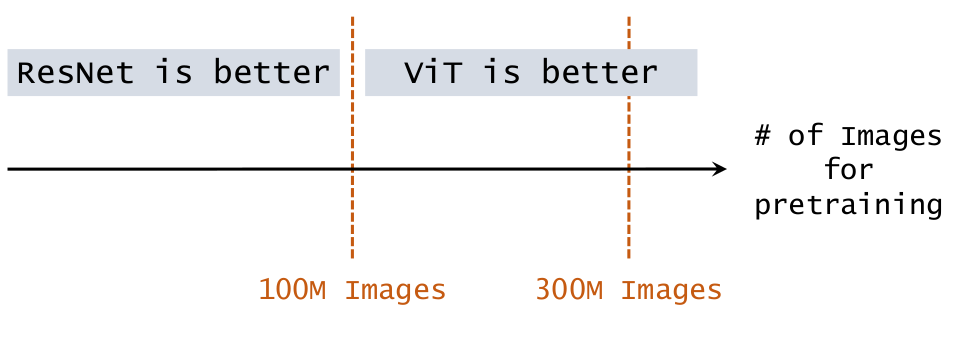
- Pretrained on ImageNet (small), kết quả kém hơn ResNet
- Pretrained on ImageNet - 21K (medium), độ chính xác của ViT đạt xấp xỉ bằng ResNet
- Pretrained on JFT (large), ViT đạt độ chính xác vượt trội hơn so với ResNet
4. Conclusions
Như vậy phía trên tôi đã trình bày qua về kiến trúc cũng như cách hoạt động của Vision Transformer cho bài toán image classification. Bài viết còn nhiều thiếu sót, cũng như còn 1 số phần tôi trình bày theo ý hiểu của mình nên cũng có thể chưa được chính xác hoàn toàn. Rất mong các bạn nào đã đọc bài viết nếu thấy chỗ nào chưa hợp lý có thể để lại cho tôi 1 comment để giúp bài viết hoàn chỉnh hơn. Nếu bạn nào muốn tìm hiểu về code thì có thể tham khảo tại đây.
Và một lần nữa nếu bạn nào có ý định tìm hiểu sâu hơn thì tôi highly recommend xem qua các silde ở đây. Cùng với list video này.
Nếu các bạn thấy bài viết này giúp cho các bạn một chút gì đó cho bạn thìđừng quên cho tôi xin 1 upvote nhé ?. Cảm ơn các bạn ??