Bài này được dịch lại từ bài viết của chị Huyền Chip. Các bạn có thể tìm đọc bài viết gốc bằng Tiếng Anh tại đây.
Một câu hỏi mà tôi đã được hỏi rất nhiều gần đây là các mô hình ngôn ngữ lớn (Large Language Models - LLM) sẽ thay đổi quy trình học máy như thế nào. Sau khi làm việc với một số công ty đang triển khai các ứng dụng LLM và tự mình mày mò nghiên cứu để tự xây dựng vài ứng dụng, tôi nhận ra hai điều:
- Để tạo ra thứ gì đó thú vị với LLM thì khá là dễ dàng, nhưng rất khó để xây dựng một sản phẩm để triển khai trong thực tế với chúng.
- Các hạn chế của LLM được thể hiện rõ do thiếu sự hoàn thiện trong kỹ thuật nhắc lệnh (prompt engineering), một phần do tính chất mơ hồ của ngôn ngữ tự nhiên và một phần do sự non trẻ của lĩnh vực này.
Bài viết này bao gồm 3 phần chính.
- Phần 1 thảo luận về các thách thức chính trong việc triển khai các ứng dụng LLM ra thực tế và các giải pháp mà tôi đã quan sát được.
- Phần 2 thảo luận về làm thế nào để lập trình ứng dụng đa tác vụ phức tạp bằng các lệnh điều khiển luồng (ví dụ như lệnh
if, vòng lặp) và tích hợp các công cụ khác (ví dụ như sử dụng SQL, bash, các API của bên thứ ba). - Phần 3 trình bày một số trường hợp các công ty triển khai ứng dụng dựa trên LLM đầy triển vọng và làm thế nào để xây dựng chúng từ các tác vụ nhỏ hơn.
Đã có rất nhiều bài viết về LLM, vì vậy hãy bỏ qua bất kỳ phần nào mà bạn đã cảm thấy quen thuộc.
Phần 1. Thách thức triển khai kỹ thuật nhắc lệnh trong thực tế
Sự mơ hồ của ngôn ngữ tự nhiên
Trong phần lớn lịch sử phát triển của máy tính, các kỹ sư viết lệnh bằng ngôn ngữ lập trình. Ngôn ngữ lập trình yêu cầu sự chính xác gần như tuyệt đối. Sự mơ hồ trong lập trình gây ra sự khó chịu cho các lập trình viên (hãy thử tưởng tượng đến kiểu dữ liệu động trong Python hoặc JavaScript).
Trong kỹ thuật nhắc lệnh, các lệnh nhắc được viết bằng ngôn ngữ tự nhiên, linh hoạt hơn rất nhiều so với ngôn ngữ lập trình. Điều này có thể mang lại trải nghiệm người dùng tuyệt vời, nhưng có thể dẫn đến trải nghiệm khá tệ cho các lập trình viên hay những người phát triển ứng dụng.
Tính linh hoạt đến từ hai hướng: cách người dùng định nghĩa lệnh nhắc và cách LLM phản hồi lại các lời nhắc này.
Trước tiên, tính linh hoạt trong dòng lệnh nhắc do người dùng định nghĩa có thể dẫn đến các lỗi ẩn. Nếu ai đó vô tình thực hiện một số thay đổi trong mã lệnh, chẳng hạn như thêm một ký tự ngẫu nhiên hoặc xóa một dòng, thì thường sẽ có thông báo lỗi. Tuy nhiên, nếu ai đó vô tình thay đổi lời nhắc, nó vẫn sẽ chạy nhưng cho kết quả đầu ra rất khác.
Mặc dù tính linh hoạt trong các lệnh nhắc do người dùng định nghĩa gây ra sự khó chịu nhất định, sự mơ hồ trong các phản hồi của LLM mới là vấn đề chính. Nó dẫn đến hai vấn đề:
- Định dạng đầu ra mơ hồ: các ứng dụng cho khách hàng cuối dựa trên LLM muốn nhận được đầu ra ở một định dạng nhất định để có thể phân tích cú pháp. Ta có thể xây dựng các lệnh nhắc để định nghĩa rõ ràng về định dạng đầu ra, nhưng không có gì đảm bảo rằng đầu ra của LLM sẽ luôn tuân theo định dạng này.
- Thiếu nhất quán trong trải nghiệm người dùng: khi sử dụng một ứng dụng, họ mong đợi sự nhất quán nhất định. Hãy tưởng tượng một công ty bảo hiểm báo giá mỗi lần một khác mỗi khi bạn kiểm tra trang web của họ. LLM là ngẫu nhiên – không có gì đảm bảo rằng LLM sẽ cung cấp cho bạn cùng một đầu ra khi có cùng một đầu vào.
Bạn có thể buộc LLM đưa ra phản hồi tương tự bằng cách đặt temperature = 0, và nhìn chung thì đây là một phương pháp hay. Mặc dù nó gần như có thể giải quyết vấn đề về tính nhất quán, nhưng nó không giúp tạo dựng niềm tin vào hệ thống. Hãy tưởng tượng một giáo viên chỉ chấm điểm một cách nhất quán nếu giáo viên đó ngồi trong một căn phòng cụ thể. Nếu giáo viên đó ngồi phòng khác, không ai có thể đoán được điểm số của giáo viên đó cho bạn.
Vậy thì làm thế nào để giải quyết vấn đề mơ hồ này
Đây dường như là một vấn đề mà OpenAI đang cố gắng để giảm thiểu. Họ có một tài liệu ghi lại các mẹo về cách tăng độ tin cậy cho mô hình của họ.
Một vài người đã làm việc với LLM trong nhiều năm nói với tôi rằng họ đành chấp nhận sự mơ hồ này và xây dựng quy trình làm việc xung quanh vấn đề này. Đó là một tư duy khác so với việc phát triển các chương trình tất định, nhưng không phải là điều không thể làm quen.
Sự mơ hồ này có thể được giảm thiểu bằng cách áp dụng càng nhiều kỹ thuật nghiêm ngặt trong lệnh nhắc càng tốt. Trong phần còn lại của bài viết này, ta sẽ thảo luận về cách thực hiện kỹ thuật nhắc lệnh sao cho có hệ thống (nếu không muốn gọi là tất định).
Đánh giá lệnh nhắc
Một phương pháp phổ biến trong kỹ thuật nhắc lệnh là cung cấp một vài ví dụ trong lệnh nhắc và hy vọng rằng LLM sẽ khái quát hóa được từ những ví dụ này (học ngắn hạn).
Ví dụ, hãy cùng thử đánh giá độ gây tranh cãi của một đoạn văn bản – đây là một dự án thú vị mà tôi đã thực hiện để tìm ra mối tương quan giữa mức độ phổ biến của một tweet và mức độ gây tranh cãi của nó. Đây là lệnh nhắc (đã được rút gọn với 4 ví dụ ngắn gọn):
Given a text, give it a controversy score from 0 to 10. Examples: 1 + 1 = 2
Controversy score: 0 Starting April 15th, only verified accounts on Twitter will be eligible to be in For You recommendations
Controversy score: 5 Everyone has the right to own and use guns
Controversy score: 9 Immigration should be completely banned to protect our country
Controversy score: 10 The response should follow the format: Controversy score: { score }
Reason: { reason } Here is the text.
Khi thực hiện học ngắn hạn, có hai câu hỏi cần lưu tâm:
- Liệu LLM có hiểu các ví dụ được đưa ra trong lệnh nhắc hay không. Một cách để đánh giá điều này là nhập các ví dụ tương tự và xem liệu mô hình có đưa ra điểm số như mong đợi hay không. Nếu mô hình không hoạt động tốt trên cùng các ví dụ được đưa ra trong lệnh nhắc, thì có thể là do lệnh nhắc không rõ ràng – bạn có thể muốn viết lại lệnh nhắc hoặc chia nhiệm vụ thành các nhiệm vụ nhỏ hơn (và kết hợp chúng lại với nhau, sẽ thảo luận chi tiết trong Phần II của bài viết này).
- Liệu LLM có bị quá khớp (overfit) trên các ví dụ này hay không. Bạn có thể đánh giá mô hình của mình trên các ví dụ khác.
Một trong những mẹo tôi thấy khá hữu ích là yêu cầu mô hình đưa ra các ví dụ mà nó sẽ đưa ra một nhãn nhất định. Ví dụ: tôi có thể yêu cầu mô hình cung cấp cho tôi các ví dụ về văn bản mà nó sẽ cho điểm 4. Sau đó, tôi sẽ nhập các ví dụ này vào LLM để xem liệu nó có thực sự cho ra kết quả 4 hay không.
from llm import OpenAILLM def eval_prompt(examples_file, eval_file): prompt = get_prompt(examples_file) model = OpenAILLM(prompt=prompt, temperature=0) compute_rmse(model, examples_file) compute_rmse(model, eval_file) eval_prompt("fewshot_examples.txt", "eval_examples.txt")
Quản lý phiên bản lệnh nhắc
Những thay đổi nhỏ trong lệnh nhắc có thể dẫn đến những kết quả rất khác biệt. Do đó, việc quản lý phiên bản và theo dõi hiệu suất của từng lệnh nhắc là rất cần thiết. Bạn có thể sử dụng git để tạo phiên bản cho từng lệnh nhắc và hiệu suất của nó, nhưng tôi sẽ không ngạc nhiên nếu có các công cụ như MLflow hoặc Weights & Biases dành riêng cho các thử nghiệm lệnh nhắc.
Tối ưu lệnh nhắc
Đã có nhiều bài báo + bài blog được viết về cách tối ưu hóa lời nhắc. Tôi đồng ý với Lilian Weng trong blog của cô ấy rằng hầu hết các bài báo về kỹ thuật lệnh nhắc đều là những thủ thuật có thể được giải thích trong một vài câu. OpenAI có một tài liệu tuyệt vời giải thích nhiều mẹo kèm theo các ví dụ. Một số mẹo trong tài liệu của OpenAI:
- Nhắc mô hình giải thích (từng bước) cách mà nó suy luận để đưa ra câu trả lời, một kỹ thuật được gọi là Chuỗi suy nghĩ (Chain of Though - COT) (Wei et al., 2022). Đánh đổi: COT có thể tăng độ trễ và chi phí do số lượng tokens đầu ra lớn [xem phần Chi phí và độ trễ]
- Tạo nhiều đầu ra cho cùng một đầu vào. Chọn kết quả cuối cùng được trả về nhiều nhất (còn được gọi là kỹ thuật tự nhất quán (self-consistency technique) (Wang et al., 2023)) hoặc bạn có thể yêu cầu LLM chọn kết quả tốt nhất. Trong API của OpenAI, bạn có thể tạo nhiều phản hồi cho cùng một đầu vào bằng cách thay đổi tham số
n. - Chia một lệnh nhắc lớn thành những lệnh nhắc nhỏ hơn, đơn giản hơn.
Nhiều công cụ hứa hẹn sẽ tự động tối ưu hóa lời nhắc của bạn – chúng khá đắt và thường chỉ áp dụng những thủ thuật này. Một điều thú vị về những công cụ này là chúng không cần lập trình, điều này khiến chúng trở nên hấp dẫn đối với những người không phải là lập trình viên.
Chi phí và độ trễ
Chi phí
Bạn đưa vào lệnh nhắc càng nhiều chi tiết và ví dụ rõ ràng thì hiệu suất mô hình càng tốt (hy vọng là vậy), và chi phí sẽ càng đắt.
API của OpenAI tính phí theo số lượng tokens của cả đầu vào và đầu ra. Tùy thuộc vào tác vụ, một lệnh nhắc đơn giản có thể tốn khoảng 300 - 1000 tokens. Nếu bạn muốn bao gồm nhiều ngữ cảnh hơn, ví dụ như thêm tài liệu cá nhân hoặc thông tin từ Internet vào lệnh nhắc, số lượng tokens có thể tăng tới 10 nghìn chỉ cho lệnh nhắc đó.
Chi phí đối với các lệnh nhắc dài không nằm trong quá trình thử nghiệm mà là trong quá trình triển khai.
Trong quá trình thử nghiệm, kỹ thuật nhắc lệnh là một phương pháp nhanh chóng và rẻ tiền để thiết lập và chạy ứng dụng. Ví dụ: ngay cả khi bạn sử dụng GPT-4 với cấu hình sau, thì chi phí thử nghiệm của bạn vẫn chỉ hơn 300 USD. Chi phí ML truyền thống dành cho thu thập dữ liệu và huấn luyệnmô hình thường cao hơn nhiều và mất nhiều thời gian hơn.
- Lệnh nhắc: 10,000 tokens ($0.06 / 1,000 tokens)
- Đầu ra: 200 tokens ($0.12 / 1,000 tokens)
- Đánh giá lệnh nhắc trên 20 ví dụ.
- Thử nghiệm với 25 phiên bản lệnh nhắc khác nhau.
Chi phí LLMOps trong triển khai.
- Nếu bạn sử dụng GPT-4 với 10,000 tokens đầu vào và 200 tokens đầu ra, chi phí sẽ là $0.624 / dự đoán.
- Nếu bạn sử dụng GPT-3.5-turbo với 4,000 tokens cho cả đầu vào và đầu ra, thì chi phí sẽ là $0.004 / dự đoán hoặc $4 / 1,000 lần dự đoán.
- Ví dụ, vào năm 2021, các mô hình DoorDash ML đã đưa ra 10 tỷ dự đoán mỗi ngày. Nếu mỗi dự đoán có giá $0.004, thì đó sẽ là 40 triệu USD một ngày!
- Để so sánh, chi phí của AWS cá nhân là khoảng $0.0417 / 1,000 dự đoán và chi phí phát hiện gian lận AWS khoảng $7.5 /1,000 dự đoán [cho hơn 100.000 dự đoán mỗi tháng]. Các dịch vụ AWS thường được coi là quá đắt (và kém linh hoạt hơn) đối với bất kỳ công ty nào có quy mô vừa phải.
Độ trễ
Các tokens đầu vào có thể được xử lý song song, nghĩa là độ dài đầu vào không ảnh hưởng nhiều đến độ trễ. Tuy nhiên, độ dài đầu ra ảnh hưởng đáng kể đến độ trễ, điều này có thể do các tokens đầu ra được tạo liên tục.
Ngay cả đối với đầu vào cực ngắn (51 tokens) và đầu ra (1 tokens), độ trễ của gpt-3.5-turbo là khoảng 500 mili giây. Nếu tokens đầu ra tăng lên trên 20 tokens, độ trễ sẽ khoảng hơn 1 giây.
Dưới đây là một thử nghiệm tôi đã chạy, với mỗi thiết lập được chạy 20 lần. Tất cả các lần chạy diễn ra trong vòng 2 phút. Nếu tôi thực hiện lại thử nghiệm, độ trễ sẽ rất khác, nhưng mối quan hệ giữa 3 thiết lập sẽ tương tự nhau.
Đây là một thách thức khác trong việc triển khai các ứng dụng LLM sử dụng API như của OpenAI: API rất không đáng tin cậy và không đảm bảo cụ thể là khi nào các SLA sẽ được cung cấp.
| Số lượng tokens | p50 latency (giây) | p75 latency | p90 latency |
|---|---|---|---|
| Đầu vào: 51 tokens, Đầu ra: 1 token | 0.58 | 0.63 | 0.75 |
| Đầu vào: 232 tokens, Đầu ra: 1 token | 0.53 | 0.58 | 0.64 |
| Đầu vào: 228 tokens, Đầu ra: 26 token | 1.43 | 1.49 | 1.62 |
Không rõ bao nhiêu phần độ trễ là do mô hình, kết nối mạng (mà tôi nghĩ là rất lớn do phương sai cao giữa các lần chạy), hoặc một số chi phí kỹ thuật. Rất có thể độ trễ sẽ giảm đáng kể trong tương lai gần.
Dù nửa giây có vẻ cao trong nhiều trường hợp, nhưng con số này cực kỳ ấn tượng khi xét đến độ lớn của mô hình và quy mô mà API đang được sử dụng. Số lượng tham số cho gpt-3.5-turbo không được công khai nhưng ước tính vào khoảng 150 tỉ. Khi bài này được viết, không có mô hình mã nguồn mở nào lớn như vậy. Mô hình T5 của Google có 11 tỉ tham số và mô hình LLaMA lớn nhất của Facebook có 65 tỉ tham số. Trên Github có một cuộc thảo luận về cấu hình họ cần để chạy các mô hình LLaMA và có vẻ như việc chạy mô hình với 30 tỉ tham số là khá khó. Người thành công nhất có vẻ như là randaller, người đã có thể làm cho mô hình 30 tỉ tham số hoạt động trên 128 GB RAM, và chỉ mất vài giây để tạo một token.
Vấn đề trong phân tích chi phí + độ trễ cho LLM
Thế giới ứng dụng LLM đang phát triển nhanh đến mức bất kỳ phân tích chi phí + độ trễ nào cũng sẽ nhanh chóng lỗi thời.
Matt Ross, quản lý cấp cao về nghiên cứu ứng dụng tại Scribd, chia sẻ với tôi rằng chi phí ước tính cho các trường hợp sử dụng API của anh ấy đã giảm hàng trăm lần trong 6 tháng qua. Độ trễ cũng giảm đáng kể. Tương tự, nhiều nhóm đã nói với tôi rằng họ cảm thấy như họ phải ước tính tính khả thi và quyết định mua (sử dụng API trả phí) so với xây dựng (sử dụng mô hình nguồn mở) mỗi tuần.
Lệnh nhắc vs. Tinh chỉnh vs. Các phương pháp khác
- Lệnh nhắc: với mỗi mẫu dữ liệu, định nghĩa rõ ràng cho mô hình biết nó sẽ phải phản hồi như thế nào.
- Tinh chỉnh (Finetuning): huấn luyện tinh chỉnh mô hình theo cách bạn muốn mô hình phản hồi, để sau đó bạn không phải định nghĩa các luật này trong lệnh nhắc.
Có 3 yếu tố chính khi cân nhắc sử dụng lệnh nhắc hay tinh chỉnh: tính có sẵn của dữ liệu, hiệu năng, và chi phí.
Nếu bạn chỉ có một vài ví dụ, áp dụng lệnh nhắc sẽ giúp bắt đầu triển khai nhanh chóng và dễ dàng. Số lượng ví dụ mà bạn có thể đưa vào lệnh nhắc của mình là có giới hạn do giới hạn độ dài tokens đầu vào.
Còn đối với tinh chỉnh mô hình, số lượng ví dụ bạn cần để tinh chỉnh cho tác vụ của mình phụ thuộc vào tác vụ và mô hình sử dụng. Tuy nhiên, theo kinh nghiệm của tôi, bạn có thể mong đợi sự thay đổi đáng chú ý trong hiệu suất mô hình của mình nếu bạn tinh chỉnh với khoảng 100 ví dụ. Tuy nhiên, kết quả có thể không tốt hơn nhiều so với áp dụng lệnh nhắc.
Trong How Many Data Points is a Prompt Worth? (2021), Scao và Rush nhận thấy rằng một lời nhắc có giá trị xấp xỉ 100 ví dụ (hạn chế: có sự sai lệch cao giữa các tác vụ và các mô hình – xem hình bên dưới). Xu hướng chung là khi bạn tăng số lượng ví dụ, việc tinh chỉnh sẽ mang lại hiệu suất mô hình tốt hơn so với sử dụng lời nhắc. Không có giới hạn về số lượng ví dụ bạn có thể sử dụng để hoàn thiện mô hình.
Việc huấn luyện tinh chỉnh có 2 lợi ích:
- Mô hình của bạn có thể có hiệu suất tốt hơn: có thể sử dụng nhiều ví dụ hơn, và các ví dụ trở thành một phần kiến thức nội tại của mô hình.
- Bạn có thể giảm chi phí dự đoán. Bạn càng đưa nhiều ví dụ vào tinh chỉnh mô hình, bạn càng phải đưa ít ví dụ vào lời nhắc của mình. Giả sử, nếu bạn có thể giảm 1 nghìn tokens trong lời nhắc cho mỗi dự đoán, với 1 triệu dự đoán trên gpt-3.5-turbo, bạn sẽ tiết kiệm được $2000.
Tinh chỉnh lệnh nhắc
Vào năm 2021, Leister et al. giới thiệu một ý tưởng thú vị, nằm giữa nhắc lệnh và tinh chỉnh là tinh chỉnh lệnh nhắc. Bắt đầu với một lệnh nhắc, thay vì thay đổi lệnh nhắc này, bạn thay đổi để tinh chỉnh vector nhúng của lệnh nhắc này. Để thực hiện tinh chỉnh lệnh nhắc, bạn cần có khả năng đưa trực tiếp vector nhúng của lời nhắc vào mô hình LLM và tạo tokens từ vector nhúng này. Hiện tại, điều này chỉ có thể được thực hiện với các LLM nguồn mở chứ không thể với API của OpenAI. Trên T5, tinh chỉnh lệnh nhắc dường như hoạt động tốt hơn nhiều so với kỹ thuật nhắc lệnh và có hiệu năng gần với với tinh chỉnh mô hình (xem hình ảnh bên dưới).
Tinh chỉnh với kỹ thuật tháp chưng cất
Vào 03/2023, một nhóm sinh viên Stanford đã đưa ra một ý tưởng đầy hứa hẹn: tinh chỉnh một mô hình ngôn ngữ mã nguồn mở nhỏ hơn (LLaMA-7B, phiên bản 7 tỷ tham số của LLaMA) trên các ví dụ được tạo bởi một mô hình ngôn ngữ lớn hơn (text-davinci-003 – 175 tỷ tham số). Kỹ thuật huấn luyện một mô hình nhỏ để bắt chước hành vi của một mô hình lớn hơn được gọi là chưng cất (distillation. Mô hình tinh chỉnh hành vi tương tự như text-davinci-003, trong khi nhỏ hơn rất nhiều và rẻ hơn để chạy.
Để tinh chỉnh, họ đã sử dụng 52k hướng dẫn mà họ đã nhập vào text-davinci-003 để thu được kết quả đầu ra, sau đó được sử dụng để tinh chỉnh LLaMa-7B. Chi phí cho text-davinci-003 là dưới $500 để tạo ra. Quá trình đào tạo để hoàn thiện có chi phí dưới $100. Xem Stanford Alpaca: An Instruction-following LLaMA Model (Taori et al., 2023).
Sự hấp dẫn của phương pháp này là không thể chối cãi. Sau 3 tuần, repo GitHub của họ đã có gần 20 nghìn sao!! Để so sánh, repo transformer của HuggingFace mất hơn một năm để đạt được số sao tương tự và repo TensorFlow mất 4 tháng.
Embeddings + Cơ sở dữ liệu vector
Một hướng mà tôi thấy rất hứa hẹn là sử dụng LLM để tạo các vector nhúng (embeddings) và sau đó xây dựng các ứng dụng ML của bạn trên các vector nhúng này, ví dụ: trong tìm kiếm và hệ thống gợi ý. Kể từ 04/2023, chi phí nhúng sử dụng mô hình text-embedding-ada-002 là $0.0004/1,000 tokens. Nếu mỗi mục dữ liệu có trung bình 250 tokens (187 từ), cách tính phí này có nghĩa là $1 cho mỗi 10 nghìn mục dữ liệu hoặc $100 cho 1 triệu mục.
Mặc dù điều này vẫn có giá cao hơn một số mô hình nguồn mở hiện có, nhưng chi phí này vẫn rất phải chăng, do:
- Bạn thường chỉ phải tạo vector nhúng cho mỗi mục dữ liệu một lần.
- Với API của OpenAI, việc tạo vector nhúng cho các truy vấn và mục dữ liệu mới trong thời gian thực là khá dễ dàng.
Để tìm hiểu thêm về cách sử dụng vector nhúng với GPT, hãy đọc SGPT (Niklas Muennighoff, 2022) hoặc bài phân tích về hiệu suất và chi phí nhúng GPT-3 (Nils Reimers, 2022). Một vài số liệu trong bài đăng của Nils đã lỗi thời (lĩnh vực này đang phát triển quá nhanh!!), nhưng phương pháp này rất tuyệt!
Chi phí chính của các mô hình nhúng trong thời gian thực là lưu trữ các vector nhúng này vào cơ sở dữ liệu vector để truy xuất với độ trễ thấp. Tuy nhiên, đây là chi phí phải có bất kể bạn sử dụng phương pháp nhúng nào. Thật thú vị khi thấy rất nhiều cơ sở dữ liệu vector đang phát triển - những cơ sở dữ liệu mới như Pinecone, Qdrant, Weaviate, Chroma cũng như những cơ sở dữ liệu đương nhiệm như Faiss, Redis, Milvus, ScaNN.
Nếu năm 2021 là năm của cơ sở dữ liệu đồ thị, thì năm 2023 là năm của cơ sở dữ liệu vector.
Khả năng tương thích ngược và xuôi
Các mô hình nền tảng có thể hoạt động vượt trội cho nhiều nhiệm vụ mà không cần phải huấn luyện lại nhiều. Tuy nhiên, chúng cần phải được huấn luyện lại hoặc tinh chỉnh theo thời gian khi chúng trở nên lỗi thời. Theo bài viết Kỹ thuật nhắc lệnh của Lilian Weng:
Theo quan sát trên tập dữ liệu SsiteQA với các câu hỏi có thời gian khác nhau, mặc dù LM (thời điểm giới hạn thông tin huấn luyện là năm 2020) có quyền truy cập vào thông tin mới nhất qua Google Tìm kiếm, hiệu suất của nó đối với các câu hỏi sau năm 2020 vẫn kém hơn nhiều so với các câu hỏi trước năm 2020. Điều này cho thấy sự tồn tại của sự không nhất quán hoặc xung đột giữa thông tin ngữ cảnh và kiến thức nội bộ của mô hình.
Trong phần mềm truyền thống, khi phần mềm được cập nhật, lý tưởng nhất là phần mềm đó vẫn hoạt động với mã được viết cho phiên bản cũ hơn. Tuy nhiên, với kỹ thuật nhắc lệnh, nếu bạn muốn sử dụng một mô hình mới hơn, không có cách nào đảm bảo rằng tất cả các lệnh nhắc của bạn vẫn sẽ hoạt động đúng như dự định với mô hình mới, vì vậy, bạn có thể sẽ phải viết lại các lệnh nhắc của mình. Vì vậy, việc có unit-test cho tất cả các lệnh nhắc của bạn là rất quan trọng.
Một lập luận mà tôi thường nghe là việc viết lại lệnh nhắc không phải là vấn đề bởi vì:
- Các mô hình mới hoạt động tốt hơn các mô hình hiện có. Tôi không tin về điều này. Nhìn chung, các mô hình mới có thể tốt hơn, nhưng sẽ có những trường hợp cụ thể mà các mô hình mới lại kém hơn.
- Thử nghiệm với lệnh nhắc rất nhanh và rẻ, như đã thảo luận trong phần Chi phí. Mặc dù tôi đồng ý với lập luận này, nhưng một thách thức lớn mà tôi thấy trong MLOps ngày nay là thiếu kiến thức tập trung cho logic mô hình, logic tính năng, lệnh nhắc, v.v. Một ứng dụng có thể có nhiều lệnh nhắc với logic phức tạp (sẽ được thảo luận trong Phần 2. Khả năng tổng hợp tác vụ). Nếu người viết lệnh nhắc rời dự án, việc hiểu ý định đằng sau lời nhắc ban đầu để cập nhật nó sẽ khá khó khăn. Tương tự như tình huống khi ai đó để lại một truy vấn SQL dài 700 dòng mà không ai dám động đến.
Một thách thức khác là các khuôn mẫu viết lệnh nhắc có thể bị ảnh hưởng lớn khi có sự thay đổi. Ví dụ: nhiều lệnh nhắc mà tôi đã thấy bắt đầu bằng "Hãy hành động như XYZ". Nếu một ngày nào đó OpenAI quyết định ra mắt AI với nội dung: "Tôi là trợ lý AI và tôi không thể hành động như XYZ", thì tất cả những lệnh nhắc này sẽ cần được cập nhật.
Phần 2. Khả năng tổng hợp tác vụ
Ứng dụng bao gồm nhiều tác vụ
Ví dụ về công cụ đánh giá độ gây tranh cãi ở trên bao gồm một nhiệm vụ duy nhất: đưa ra một đầu vào, đưa ra một chỉ số đánh giá sự gây tranh cãi của đầu vào. Tuy nhiên, hầu hết các ứng dụng thực tế thì phức tạp hơn nhiều. Hãy xem xét bài toán "trò chuyện với dữ liệu" khi ta muốn kết nối với cơ sở dữ liệu và truy vấn dữ liệu bằng ngôn ngữ tự nhiên. Hãy tưởng tượng một bảng lưu thông tin giao dịch thẻ tín dụng. Bạn muốn hỏi những câu như: "Có bao nhiêu thương nhân khác nhau ở thành phố Phoenix và tên của họ là gì?" và cơ sở dữ liệu của bạn sẽ trả về: "Có 9 thương nhân khác nhau ở thành phố Phoenix và họ là …”.
Một cách để làm điều này là viết một chương trình thực hiện chuỗi nhiệm vụ sau:
- Tác vụ 1: chuyển đổi đầu vào ngôn ngữ tự nhiên từ người dùng sang truy vấn SQL [LLM]
- Tác vụ 2: thực thi truy vấn SQL trong cơ sở dữ liệu SQL [SQL executor]
- Tác vụ 3: chuyển đổi kết quả SQL thành phản hồi ngôn ngữ tự nhiên để hiển thị cho người dùng [LLM]
Agents, các công cụ, và luồng điều khiển
Tôi đã thực hiện một cuộc khảo sát nhỏ với mọi người trong mạng lưới của mình và dường như vẫn chưa có bất kỳ sự đồng thuận nào về các thuật ngữ.
Từ agents (tác nhân) đang được sử dụng rất nhiều để chỉ một ứng dụng có thể thực thi nhiều tác vụ theo một luồng điều khiển nhất định (xem phần Luồng điều khiển). Một nhiệm vụ có thể áp dụng một hoặc nhiều công cụ. Trong ví dụ trên, trình thực thi SQL là một ví dụ về công cụ.
Ghi chú: một số người trong mạng của tôi phản đối việc sử dụng thuật ngữ tác nhân trong ngữ cảnh này vì nó đã được sử dụng quá mức trong các ngữ cảnh khác (ví dụ: tác nhân để chỉ một chính sách trong học tăng cường).
Công cụ vs. plugin
Ngoài trình thực thi SQL, một số ví dụ khác về các công cụ gồm:
- tìm kiếm (ví dụ: bằng cách sử dụng Google Search API hoặc Bing API)
- trình duyệt web (ví dụ: được cung cấp một URL, tìm nạp nội dung của nó)
- trình thực thi bash
- máy tính
Các công cụ và plugin về cơ bản là giống nhau. Bạn có thể coi plugin là các công cụ được đưa vào kho plugin của OpenAI. Khi viết bài này, các plugin OpenAI chưa được công bố mở, nhưng bất kỳ ai cũng có thể tạo và sử dụng các công cụ.
Luồng điều khiển: tuần tự, song song, rẽ nhánh if, vòng lặp for
Trong ví dụ trên, tuần tự là một ví dụ về luồng điều khiển trong đó một tác vụ được thực hiện liền kề một tác vụ khác. Có các loại luồng điều khiển khác như song song, câu lệnh if, vòng lặp for.
- Tuần tự: thực thi tác vụ B sau khi tác vụ A hoàn thành, có thể là do tác vụ B phụ thuộc vào tác vụ A. Ví dụ: truy vấn SQL chỉ có thể được thực thi sau khi nó được chuyển đổi về câu truy vấn từ đầu vào của người dùng.
- Song song: thực hiện đồng thời các tác vụ A và B.
- Câu lệnh if: thực thi tác vụ A hoặc tác vụ B tùy thuộc vào đầu vào.
- Vòng lặp for: lặp lại việc thực hiện tác vụ A cho đến khi thỏa mãn một điều kiện nào đó. Ví dụ: hãy tưởng tượng bạn sử dụng tác vụ của trình duyệt để lấy nội dung của trang web và tiếp tục sử dụng tác vụ của trình duyệt để lấy nội dung của các liên kết được tìm thấy trong trang web đó cho đến khi tác nhân cảm thấy như có đủ thông tin để trả lời câu hỏi ban đầu.
Lưu ý: mặc dù luồng song song chắc chắn sẽ có thể hữu ích nhưng tôi chưa thấy nhiều ứng dụng sử dụng luồng này.
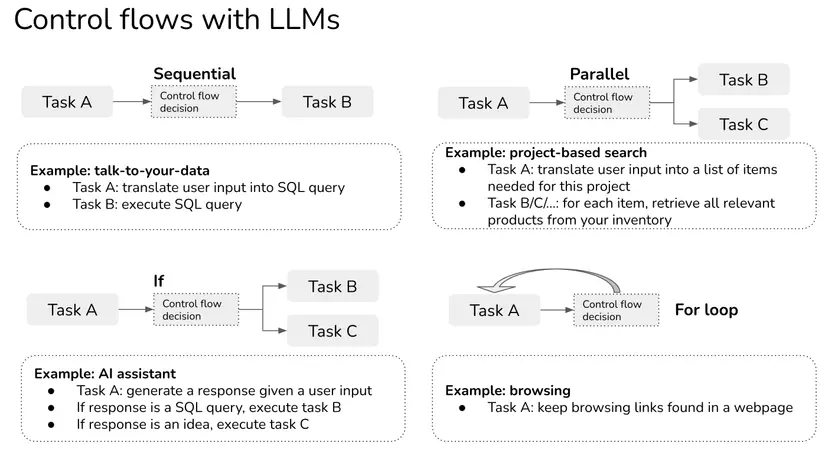
Luồng điều khiển với tác nhân LLM
Trong công nghệ phần mềm truyền thống, điều kiện cho các luồng điều khiển là tất định. Với các ứng dụng LLM (có thể coi là các tác nhân), các điều kiện cũng có thể được xác định bằng lời nhắc.
Ví dụ, nếu bạn muốn tác nhân chọn giữa ba hành động Tìm kiếm, thực thi SQL, hay Trò chuyện, bạn có thể giải thích cách nó nên chọn một trong ba hành động trên như sau.
You have access to three tools: Search, SQL executor, and Chat. Search is useful when users want information about current events or products. SQL executor is useful when users want information that can be queried from a database. Chat is useful when users want general information. Provide your response in the following format: Input: { input }
Thought: { thought }
Action: { action }
Action Input: { action_input }
Observation: { action_output }
Thought: { thought }
Nói cách khác, bạn có thể sử dụng LLM để quyết định điều kiện của luồng điều khiển!
Kiểm thử tác nhân LLM
Để các tác nhân trở nên đáng tin cậy, ta cần có khả năng xây dựng và thử nghiệm từng tác vụ riêng biệt trước khi kết hợp chúng với nhau. Có hai kiểu thất bại chính:
- Một hoặc nhiều nhiệm vụ không thành công. Nguyên nhân tiềm ẩn:
- Luồng điều khiển sai: một hành động không bắt buộc được chọn
- Một hoặc nhiều tác vụ tạo ra kết quả không chính xác.
- Tất cả các nhiệm vụ tạo ra kết quả chính xác nhưng giải pháp tổng thể là không chính xác. Press et al. (2022) gọi đây là “khoảng cách trong khả năng tổng hợp”: tỷ lệ câu hỏi tổng hợp mà mô hình trả lời sai trên tổng số tất cả các câu hỏi tổng hợp mà mô hình trả lời đúng các câu hỏi thành phần.
Giống như công nghệ phần mềm, bạn có thể và nên kiểm thử từng thành phần cũng như luồng điều khiển. Với mỗi thành phần, bạn có thể xác định các cặp (đầu vào, đầu ra dự kiến) làm ví dụ đánh giá, và có thể được sử dụng để đánh giá ứng dụng của bạn mỗi khi bạn cập nhật lệnh nhắc hoặc luồng điều khiển. Bạn cũng có thể thực hiện các bài kiểm thử đầu cuối cho toàn bộ ứng dụng.
Phần 3. Các ví dụ đầy triển vọng
Trên Internet có ngập tràn các bản demo thú vị của các ứng dụng được xây dựng bằng LLM. Dưới đây là một số ứng dụng phổ biến và đấy hứa hẹn mà tôi được thấy. Tôi chắc chắn rằng còn rất nhiều ví dụ khác cần được khám phá.
Để có thêm ý tưởng, hãy xem các dự án từ hai cuộc thi hackathon sau:
- Kết quả mã GPT-4 Hackathon [25/03/2023]
- Langchain / Gen Mo Hackathon [25/02/2023]
Trợ lý AI
Đây là trường hợp ứng dụng phổ biến nhất với người tiêu dùng. Các trợ lý AI được xây dựng cho các nhiệm vụ khác nhau dành cho các nhóm người dùng khác nhau – trợ lý AI để lên lịch, ghi chú, lập trình nhóm, trả lời email, giúp đỡ cha mẹ, đặt chỗ trước, đặt chuyến bay, mua sắm, v.v. – nhưng, tất nhiên, mục tiêu cuối cùng là một trợ lý có thể hỗ trợ bạn trong mọi việc.
Đây cũng là chén thánh mà tất cả các công ty lớn đã và đang hướng tới trong suốt nhiều năm: Google với Google Assistant và Bard, Facebook với M và Blender, OpenAI (và rộng hơn là Microsoft) với ChatGPT. Quora, vốn có nguy cơ bị AI thay thế rất cao, đã phát hành ứng dụng Poe của riêng họ cho phép bạn trò chuyện với nhiều LLM. Tôi khá ngạc nhiên khi thấy Apple và Amazon vẫn chưa tham gia cuộc chơi.
Chatbot
Chatbots tương tự như trợ lý AI khi xét theo phương diện API. Nếu mục tiêu của trợ lý AI là hoàn thành các nhiệm vụ do người dùng đưa ra, thì mục tiêu của chatbot là trở thành người bạn đồng hành nhiều hơn. Ví dụ: bạn có thể có các chatbot nói chuyện như người nổi tiếng, nhân vật trong trò chơi/phim/sách, doanh nhân, tác giả, v.v.
Michelle Huang đã sử dụng các cuốn nhật ký thời thơ ấu của mình như một phần của lệnh nhắc cho GPT-3 để nói chuyện với bản thân khi còn trẻ.
Công ty thú vị nhất trong lĩnh vực chatbot tiêu dùng có lẽ là Character.ai. Đó là một nền tảng để mọi người tạo và chia sẻ chatbot. Các loại chatbot phổ biến nhất trên nền tảng này là nhân vật anime và trò chơi, nhưng bạn cũng có thể nói chuyện với nhà tâm lý học, một đối tác để lập trình cặp, hoặc một đối tác cùng học ngôn ngữ. Bạn có thể nói chuyện, hành động, vẽ tranh, chơi vài trò chơi dựa trên văn bản (như Dungeon AI), và thậm chí kích hoạt giọng nói cho các nhân vật. Tôi đã thử một vài chatbot phổ biến – dường như không có chatbot nào trong số chúng có thể duy trì một cuộc trò chuyện tốt, nhưng chúng ta mới chỉ bắt đầu mà thôi. Mọi thứ có thể trở nên thú vị hơn nếu có một mô hình chia sẻ doanh thu để giúp cho người tạo chatbot có thể được trả tiền.
Lập trình và chơi trò chơi
Đây là một thể loại ứng dụng LLM phổ biến khác, vì các LLM hóa ra cực kỳ giỏi trong việc viết và tìm lỗi trong lập trình. GitHub Copilot là ứng dụng tiên phong (có tiện ích mở rộng VSCode với 5 triệu lượt tải xuống tính đến thời điểm viết bài). Đã có những bản demo khá thú vị về việc sử dụng LLM để viết mã:
- Tạo ứng dụng web từ ngôn ngữ tự nhiên
- Tìm các lỗ hổng bảo mật: Socket AI kiểm tra các gói npm và PyPI trong mã nguồn của bạn để tìm các lỗ hổng bảo mật. Khi một vấn đề tiềm ẩn được phát hiện, họ sử dụng ChatGPT để tóm tắt các phát hiện.
- Chơi trò chơi
- Xây dựng trò chơi: ví dụ, Wyatt Cheng có một video tuyệt vời thuật lại cách anh ấy sử dụng ChatGPT để sao chép Flappy Bird.
- Tạo các nhân vật cho trò chơi.
- Cho phép bạn có những cuộc trò chuyện thực tế hơn với các nhân vật trong trò chơi: hãy xem bản demo tuyệt vời này của Convai!
Giáo dục
Bất cứ khi nào ChatGPT ngừng hoạt động, kênh Discord của OpenAI tràn ngập lời phàn nàn của học sinh về việc không thể hoàn thành bài tập về nhà. Một số phản ứng bằng cách cấm hoàn toàn việc sử dụng ChatGPT trong trường học. Một số có ý tưởng hay hơn nhiều: kết hợp ChatGPT để giúp học sinh học nhanh hơn. Tất cả các công ty EdTech mà tôi biết đều đang tăng tốc tối đa trong việc khám phá ChatGPT.
Một số trường hợp sử dụng:
- Tóm tắt sách
- Tự động tạo các câu hỏi để đảm bảo học sinh hiểu một cuốn sách hoặc một bài giảng. ChatGPT không chỉ có thể tạo câu hỏi mà còn có thể đánh giá xem câu trả lời đầu vào của học sinh có đúng hay không.
- Tôi đã thử và ChatGPT có vẻ khá giỏi trong việc tạo các câu hỏi về Thiết kế Hệ thống Máy học. Tôi sẽ công bố chương trình này sớm thôi!
- Chấm điểm/cho ý kiến về bài luận
- Giải thích cách giải một bài tập toán
- Trở thành một đối thủ tranh luận: ChatGPT thực sự giỏi trong việc đánh giá các khía cạnh khác nhau của cùng một chủ đề tranh luận.
Với sự gia tăng của giáo dục tại nhà, tôi hy vọng sẽ thấy nhiều ứng dụng xây dựng trên ChatGPT để giúp phụ huynh dạy học tại nhà.
Trò chuyện với dữ liệu
Theo quan sát của tôi, đây là ứng dụng doanh nghiệp phổ biến nhất (cho đến nay). Rất nhiều công ty khởi nghiệp đang xây dựng các công cụ để cho phép người dùng doanh nghiệp truy vấn dữ liệu nội bộ và chính sách của họ bằng ngôn ngữ tự nhiên hoặc theo kiểu hỏi đáp. Một số tập trung vào các ngành hẹp như hợp đồng pháp lý, hồ sơ tuyển dụng, dữ liệu tài chính, hoặc hỗ trợ khách hàng. Với tất cả các tài liệu, chính sách, và bộ câu hỏi thường gặp của công ty, bạn có thể xây dựng một chatbot có thể đáp ứng các yêu cầu hỗ trợ khách hàng của bạn.
Phương pháp chính để xây dựng một ứng dụng như vậy thường bao gồm 4 bước:
- Sắp xếp dữ liệu nội bộ của bạn vào cơ sở dữ liệu (cơ sở dữ liệu SQL, cơ sở dữ liệu đồ thị, cơ sở dữ liệu nhúng/vector, hoặc cơ sở dữ liệu văn bản đơn thuẩn)
- Với đầu vào là ngôn ngữ tự nhiên, hãy chuyển đổi nó thành ngôn ngữ truy vấn của cơ sở dữ liệu nội bộ. Ví dụ: nếu đó là cơ sở dữ liệu đồ thị hoặc SQL, quy trình này có thể trả về một truy vấn SQL. Nếu đó là cơ sở dữ liệu nhúng, thì đó có thể là truy vấn truy xuất ANN (hàng xóm gần nhất). Nếu đó chỉ là văn bản thuần túy, quá trình này có thể trích xuất một truy vấn tìm kiếm.
- Thực hiện truy vấn trong cơ sở dữ liệu để lấy kết quả truy vấn.
- Dịch kết quả truy vấn này sang ngôn ngữ tự nhiên.
Mặc dù điều này tạo ra các bản demo thực sự thú vị, nhưng tôi không chắc các ứng dụng này sẽ có thể trụ vững đến mức nào. Tôi có thấy một số công ty khởi nghiệp xây dựng ứng dụng để cho phép người dùng truy vấn trên Google Drive hoặc Notion, và trông có vẻ như đó là một tính năng mà Google Drive hoặc Notion có thể triển khai trong một tuần.
OpenAI có một hướng dẫn khá hay về cách nói chuyện với cơ sở dữ liệu vector của bạn.
LLM có thể thực hiện phân tích dữ liệu được không?
Tôi đã thử nhập một số dữ liệu vào gpt-3.5-turbo và dường như nó có thể phát hiện một thông tin nhất định từ dữ liệu. Tuy nhiên, chức năng này chỉ hoạt động đối với dữ liệu nhỏ để có thể viết vừa trong giới hạn của lệnh nhắc. Hầu hết dữ liệu thực tế đều lớn hơn thế.
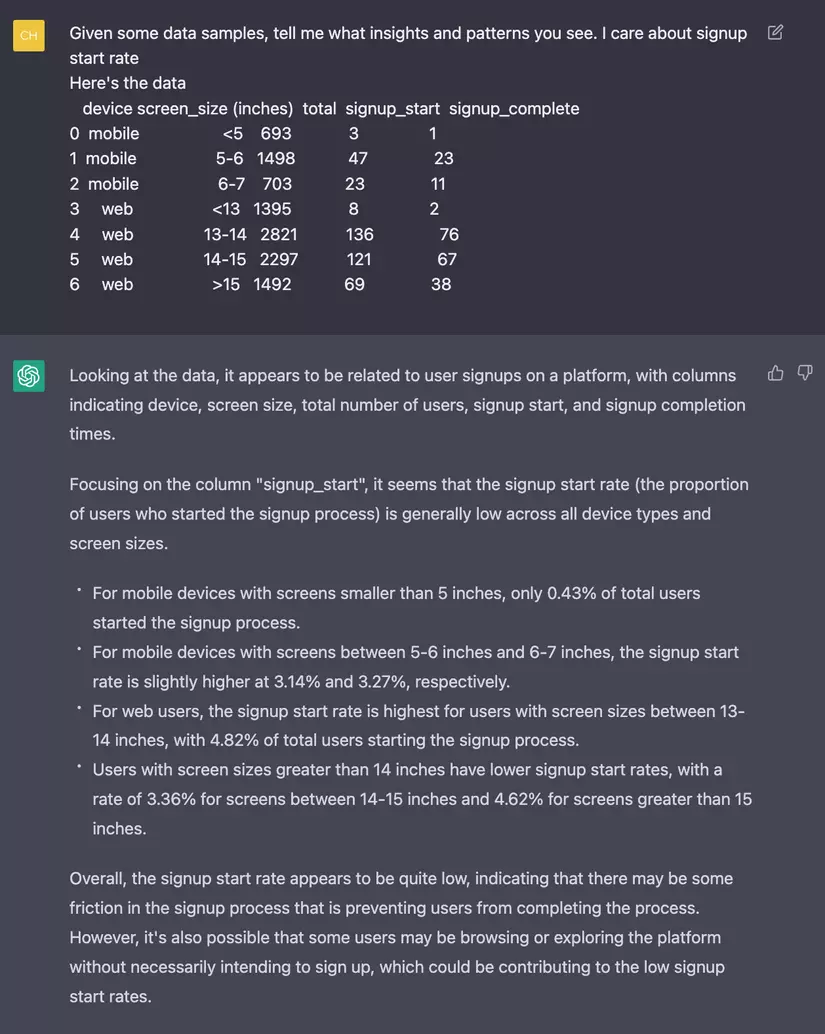
Tìm kiếm và gợi ý
Tìm kiếm và gợi ý luôn là yếu tố cơ bản trong các ứng dụng doanh nghiệp. Nó đang trải qua thời kỳ phục hưng với LLM. Tìm kiếm chủ yếu dựa trên từ khóa: bạn cần một cái lều, bạn tìm kiếm một cái lều. Nhưng nếu bạn chưa biết mình cần gì thì sao? Ví dụ, nếu bạn đi cắm trại trong rừng ở Oregon vào tháng 11, bạn có thể sẽ phải làm một số việc như sau:
- Tìm kiếm để đọc về kinh nghiệm của người khác.
- Đọc các bài đăng trên blog đó và tự trích xuất danh sách đồ đạc cần mua.
- Tìm kiếm từng sản phẩm, trên Google hoặc các trang web khác.
Nếu bạn tìm kiếm “những thứ cần để đi cắm trại ở Oregon vào tháng 11” trực tiếp trên Amazon hoặc bất kỳ trang web thương mại điện tử nào, bạn sẽ nhận được thông tin như sau:
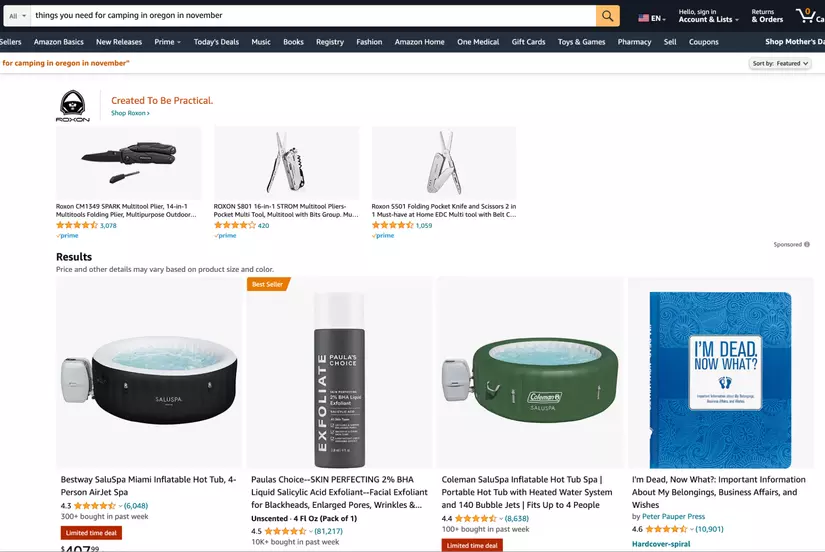
Nhưng điều gì sẽ xảy ra nếu việc tìm kiếm “những thứ cần để đi cắm trại ở Oregon vào tháng 11” trên Amazon thực sự trả về cho bạn một danh sách những thứ bạn cần cho chuyến đi cắm trại của mình?
Nhiện vụ này có thể thành hiện thực với LLM. Ví dụ, ứng dụng có thể được chia thành các bước sau:
- Nhiệm vụ 1: chuyển đổi truy vấn của người dùng thành danh sách tên sản phẩm [LLM]
- Nhiệm vụ 2: đối với mỗi tên sản phẩm trong danh sách, hãy truy xuất các sản phẩm có liên quan từ danh mục sản phẩm trong hệ thống.

Nếu phương pháp này hiệu quả, tôi tự hỏi liệu chúng ta có LLM SEO: các kỹ thuật để các LLM gợi ý sản phẩm cho bạn hay không.
Bán hàng
Cách dễ dàng nhất để sử dụng LLM để bán hàng là viết email bán hàng. Nhưng không ai thực sự muốn có email bán hàng nhiều hơn hoặc tốt hơn. Tuy nhiên, một số công ty trong mạng lưới của tôi đang sử dụng LLM để tổng hợp thông tin về một công ty để xem họ cần làm gì để bán hàng tốt hơn.
SEO
SEO sắp trở nên rất kỳ lạ. Nhiều công ty ngày nay dựa vào việc tạo ra nhiều nội dung với hy vọng được xếp hạng cao trên Google. Tuy nhiên, do các LLM thực sự giỏi trong việc tạo nội dung và tôi đã biết một vài công ty khởi nghiệp có dịch vụ tạo nội dung được tối ưu hóa SEO không giới hạn cho bất kỳ từ khóa cụ thể nào, các công cụ tìm kiếm sẽ tràn ngập nội dung viết bởi AI. SEO thậm chí có thể trở thành trò chơi mèo vờn chuột: các công cụ tìm kiếm đưa ra các thuật toán mới để phát hiện nội dung do AI tạo ra và các công ty trở nên giỏi hơn trong việc qua mặt các thuật toán này. Mọi người cũng có thể ít sử dụng tìm kiếm và tập trung nhiều hơn vào các thương hiệu (ví dụ: chỉ tin tưởng vào nội dung được tạo bởi những người hoặc công ty nhất định).
Và chúng tôi thậm chí còn chưa đề cập đến SEO cho LLM: cách đưa nội dung của bạn vào phản hồi của LLM!!
Kết luận
Chúng ta vẫn đang trong những ngày đầu của các ứng dụng LLM – mọi thứ đang phát triển quá nhanh. Gần đây tôi đã đọc một bản đề xuất sách về LLM và suy nghĩ đầu tiên của tôi là: hầu hết những thứ này sẽ lỗi thời sau một tháng nữa. API đang thay đổi từng ngày. Các ứng dụng mới đang được khám phá. Cơ sở hạ tầng đang được tích cực tối ưu hóa. Phân tích chi phí và độ trễ cần được thực hiện hàng tuần. Các thuật ngữ mới đang được giới thiệu.
Không phải tất cả những thay đổi này sẽ quan trọng. Ví dụ: nhiều bài báo về kỹ thuật lời nhắc khiến tôi nhớ về những ngày đầu học sâu khi có hàng nghìn bài báo mô tả các cách khác nhau để khởi tạo trọng số. Tôi tưởng tượng rằng các mánh khóe để điều chỉnh lời nhắc của bạn như: "Trả lời trung thực", "Tôi muốn bạn hành động như...", viết "câu hỏi: " thay vì "q:" sẽ không thành vấn đề về lâu dài.
Với việc LLM dường như khá giỏi trong việc viết lệnh nhắc cho chính nó – xem Large Language Models Are Human-Level Prompt Engineers (Zhou et al., 2022) – liệu ta có còn cần con người để điều chỉnh lệnh nhắc?
Tuy nhiên, với quá nhiều điều đang xảy ra, thật khó để biết điều gì sẽ quan trọng và điều gì sẽ không.
Gần đây tôi đã hỏi trên LinkedIn về cách mọi người cập nhật thông tin về lĩnh vực này. Các chiến lược bao gồm từ bỏ qua xu hướng này đến thử tất cả các công cụ.
-
Bỏ qua (hầu hết) mọi thứ về xu hướng này
Vicki Boykis (Kỹ sư ML cao cấp @ Duo Security): Tôi làm điều tương tự như với bất kỳ framework mới nào trong lĩnh vực kỹ thuật hoặc dữ liệu: Tôi lướt qua tin tức hàng ngày, bỏ qua hầu hết tin tức và đợi sáu tháng để xem cái gì vẫn trụ vững. Mọi thứ quan trọng sẽ ở lại và sẽ có nhiều bài khảo sát hơn cũng như các phương án triển khai đã được kiểm tra kỹ lưỡng giúp bối cảnh hóa những gì đang xảy ra.
-
Chỉ đọc phần tóm tắt
Shashank Chaurasia (Kỹ sư @ Microsoft): Tôi sử dụng chế độ Creative của BingChat để cung cấp cho tôi các bản tóm tắt nhanh của các bài báo, blog, và tài liệu nghiên cứu mới liên quan đến Gen AI! Tôi thường trò chuyện với các tài liệu nghiên cứu và các kho chứa mã nguồn trên github để hiểu chi tiết.
-
Cố gắng cập nhật các công cụ mới nhất
Chris Alexiuk (Kỹ sư ML sáng lập @ Ox): Tôi chỉ thử và xây dựng với từng công cụ khi chúng ra mắt - theo cách này, khi bước tiếp theo xuất hiện, tôi chỉ nhìn vào vùng quan trọng.
Vậy chiến lược của bạn là gì?
Trường Giang dịch,