Bài viết nằm trong series Performance optimization với PostgreSQL.
Bài trước chúng ta đã biết về các phương pháp giúp tăng performance của SQL query. Bài hôm nay sẽ giới thiệu về một trong các phương pháp đó, indexing thần thánh.
Từ bài này sẽ liên quan nhiều đến practice nên các bạn chuẩn bị env và data trước. Mình sử dụng Docker cho nhanh.
Start PostgreSQL và pgAdmin4:
docker run -d -p 5432:5432 -e POSTGRES_PASSWORD=postgres postgres docker run -d -p 8888:80 -e PGADMIN_DEFAULT_EMAIL=_@.com -e PGADMIN_DEFAULT_PASSWORD=1 dpage/pgadmin4
Tạo mới table:
CREATE TABLE IF NOT EXISTS country
( id bigserial NOT NULL, country_name character varying(255) NOT NULL, created timestamp without time zone NOT NULL, PRIMARY KEY (id)
); CREATE TABLE IF NOT EXISTS engineer
( id bigserial NOT NULL, first_name character varying(255) NOT NULL, last_name character varying(255) NOT NULL, gender smallint NOT NULL, country_id bigint NOT NULL, title character varying(255) NOT NULL, created timestamp without time zone NOT NULL, PRIMARY KEY (id)
);
Insert data 100k records tải ở đây nhé.
1) Explain & Analyze
1.1) Explain
Trước khi optimize query, ta cần hiểu query đó thực hiện nhiệm vụ gì, có thể optimize phần nào, không thể ào ào thêm index hay chia partition và mong nó chạy nhanh hơn được. Xin lưu ý, chúng ta là các kĩ sư chuyên ngành, ở đây chúng ta không làm như thế  . Chúng ta làm việc với các con số, không làm việc với cách.. truyền miệng (nhất là thời đại Covid hiện nay).
. Chúng ta làm việc với các con số, không làm việc với cách.. truyền miệng (nhất là thời đại Covid hiện nay).
Explain & Analyze là công cụ đắc lực để thực hiện việc đó. Nó giúp giải thích các bước thực hiện trong câu query là gì với các thông số về cost, rows, widths... Việc còn lại của các kĩ sư là nhìn vào đó để biết vấn đề đang nằm ở đâu và xử lý ra sao (phần khó nhất ).
Explain keywork giải thích từng bước câu query được thực hiện, bắt đầu với query sau:
EXPLAIN SELECT * FROM ENGINEER;

Với query trên, chỉ 1 step cần thực thi là sequence scan table, rất dễ hiểu. Điều chúng ta quan tâm là các con số đằng sau:
- cost: cái giá phải trả là bao nhiều , hiểu đơn giản là số lượng tính toán cần thiết để hoàn thành, giá trị từ 0 đến 2117. Tức là sao? Con số đầu tiên thể hiện cost cần tiêu tốt để khởi động nhiệm vụ. Sau đó cần 2117 đơn vị tính toán để hoàn thành nhiệm vụ. Lưu ý nó là một thông số đánh giá, không phản ánh thời gian thực tế và nó không có giá trị thời gian đo cụ thể.
- rows: số lượng row mà Postgres nghĩ rằng nó cần scan để thực thi query.
- width: độ rộng trung bình của mỗi row sau khi thực thi query, đơn vị bytes. Nếu chỉ
SELECT GENDERthì giá trị width sẽ nhỏ và giá trị là 2 bytes (smallint).
1.2) Analyze
Trong thực tế, ta chỉ quan tâm đến cost, một con số áng chừng về execution time. Để có con số cụ thể hơn, ta thêm keywork analyze vào sau explain:
EXPLAIN ANALYZE SELECT * FROM ENGINEER;
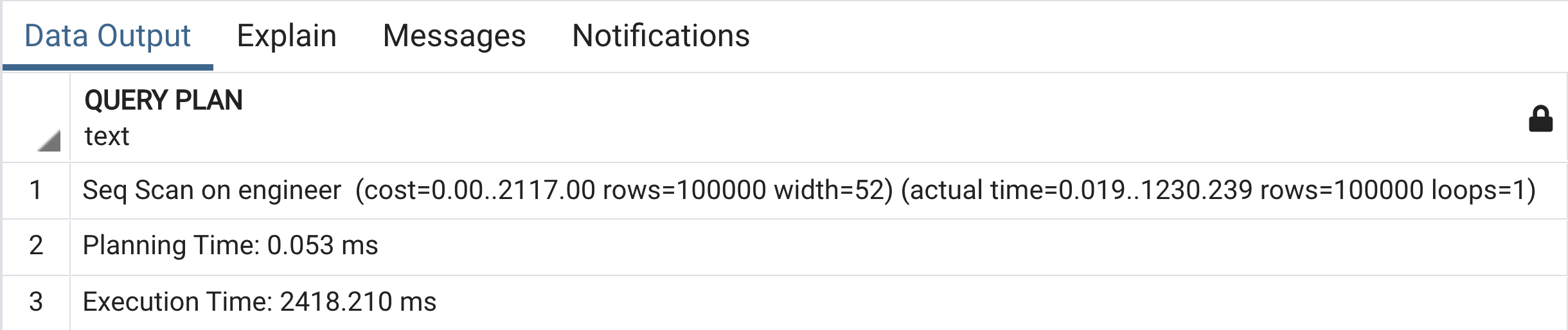
Tiếp tục xuất hiện một vài thông số:
- Với dòng đầu tiên, không có gì thay đổi nhiều ngoại trừ việc có thêm actual time. Giống như cost, con số đầu tiên thể hiện thời gian cần để khởi động, con số thứ hai là thời gian để hoàn thành.
- loops: đơn giản rồi, số lượng vòng lặp.
- planning time: thời gian lên kế hoạch cho query, rất nhanh chỉ 0,053 ms.
- execution time: 2418 ms. Vì sao lại có sự chênh lệch giữa execution time và actual time? Lưu ý rằng actual time là thời gian tính toán cho nhiệm vụ seq scan table. Còn một phần quan trọng nữa là fetch data để hiển thị.
Thử với query có điều kiện WHERE nhé:
EXPLAIN SELECT * FROM ENGINEER WHERE COUNTRY_ID >= 100;
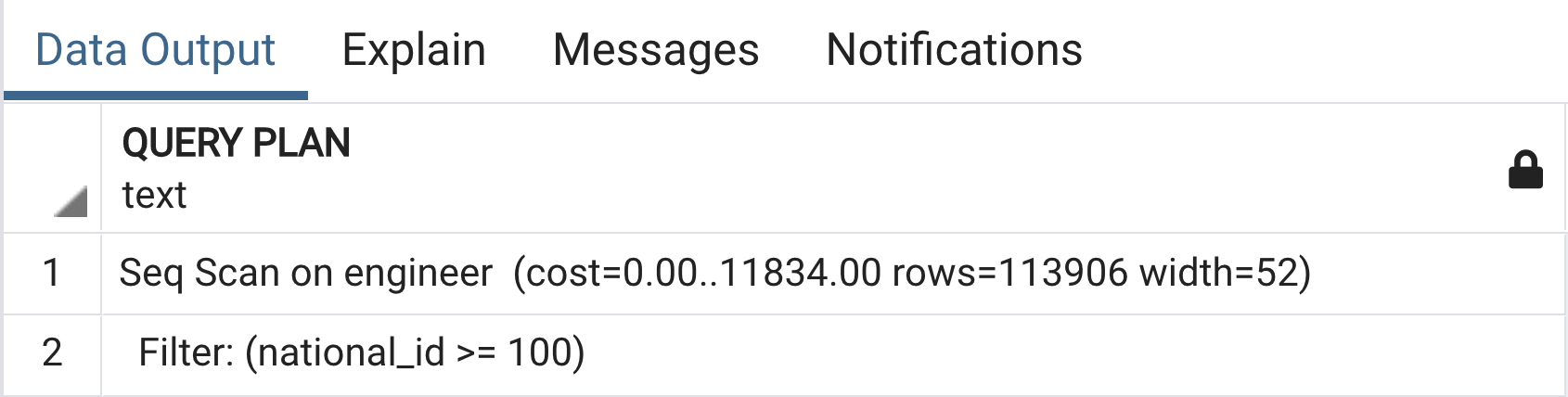
Vẫn là seq scan table, tuy nhiên có thêm bước filter để lọc các row có giá trị national_id >= 100. Không có gì khó hiểu lắm.
Bước phân tích tính toán query đã xong. Ta nhận thấy một vài vấn đề, trong đó có seq scan. Đã có bằng chứng trong tay, xử lý thôi.
2) Indexes
Như đã giới thiệu trong bài trước, để tránh full table scan, ta dùng index .
Thực hành trước đã, câu query trên sử dụng điều kiện với country_id, đánh index cho cột này trước:
CREATE INDEX idx_engineer_country_id ON ENGINEER(country_id);
Sau khi thêm index, chạy lại câu lệnh EXPLAIN ANALYZE SELECT * FROM ENGINEER, kết quả không có gì thay đổi vì chẳng dính dáng gì tới country_id cả. Chạy với điều kiện WHERE sử dụng country_id xem thế nào:
EXPLAIN ANALYZE SELECT * FROM ENGINEER WHERE COUNTRY_ID >= 100;
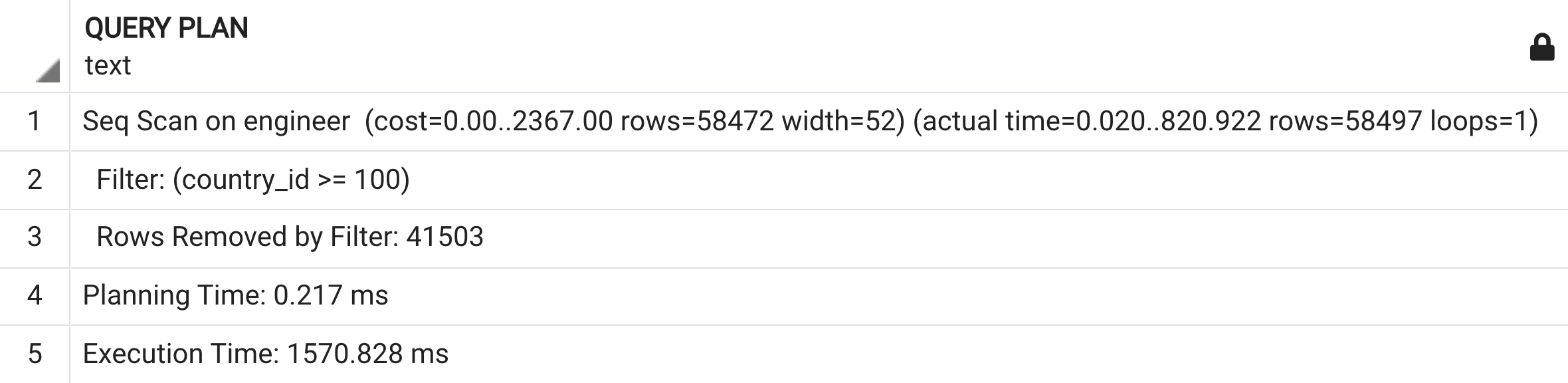
WTF, vẫn seq scan, chẳng có nhẽ các Senior bịp mình  . Thử đổi điều kiện WHERE một chút:
. Thử đổi điều kiện WHERE một chút:
EXPLAIN ANALYZE SELECT * FROM ENGINEER WHERE COUNTRY_ID >= 150;
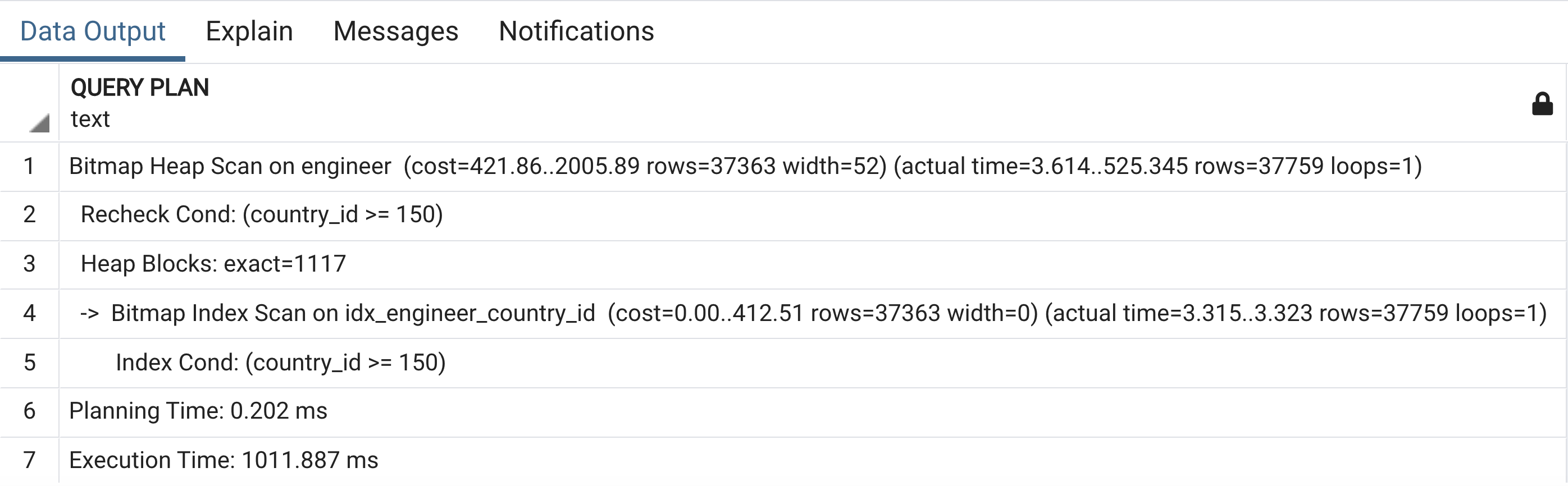
Đã có chút thay đổi điều kiện >= 150, query plan sử dụng bitmap heap scan chính là bitmap index. Execution time giảm ~ 30% từ 1500 xuống 1000 ms. Vì sao có sự khác biệt này?
Với điều kiện >= 100, có rất nhiều records phù hợp. Do đó query execution xác định rằng seq scan trên table chính còn nhanh hơn việc scan index trên table index. Thông minh phết, hóa ra các Senior lương chục ngàn không bịp bợm .
Lưu ý rằng, bài trước ta đã biết việc sử dụng index là việc scan trên 2 table. Tức là scan index table trước, sau đó ánh xạ kết quả sang table chính.
Như vậy với mỗi điều kiện khác nhau DB System sẽ biết cách thực hiện các query nhanh nhất có thể dựa trên những gì chúng ta cung cấp cho nó, cụ thể ở đây là index. Ngoài ra, ta thấy một lesson learn khác là đôi khi index không đem lại tác dụng gì. Đừng index vô tội vạ, không những không tăng tốc độ read mà còn làm chậm tốc độ write.
Cùng tìm hiểu về các loại index phổ biến trong Relational Database:
- B-Tree index.
- Hash index.
- Bitmap index.
Ngoài ra PostgreSQL có một số loại index đặc biệt:
- GIST.
- SP-GIST.
- GIN.
- BRIN.
Viết dài quá dễ quên, mình sẽ đi cụ thể từng loại index và ứng dụng thực tế trong bài viết sau nhé. Tổng kết bài viết rút ra 2 kết luận:
- Sử dụng explain và analyze để phân tích query, tìm bottle neck.
- Sử dụng index để tăng tốc độ truy vấn.. và chỉ hữu ích trong một vài tình huống cụ thể.