Bài viết nằm trong series Apache Kafka từ zero đến one.
Cùng tìm hiểu về cách gửi nhận message trong Kafka và trả lời các câu hỏi phần trước:
- Nếu muốn các message được lưu trên cùng một partition để đảm bảo thứ tự thì làm cách nào?
- Một partition có nhiều replication thì việc read/write message diễn ra trên replication nào hay tất cả các replication?
1) Leader partition concept
Với replication factor, mỗi partition được replicate thành nhiều replication lưu trữ trên các broker khác nhau để đảm bảo high reliable và high durable.
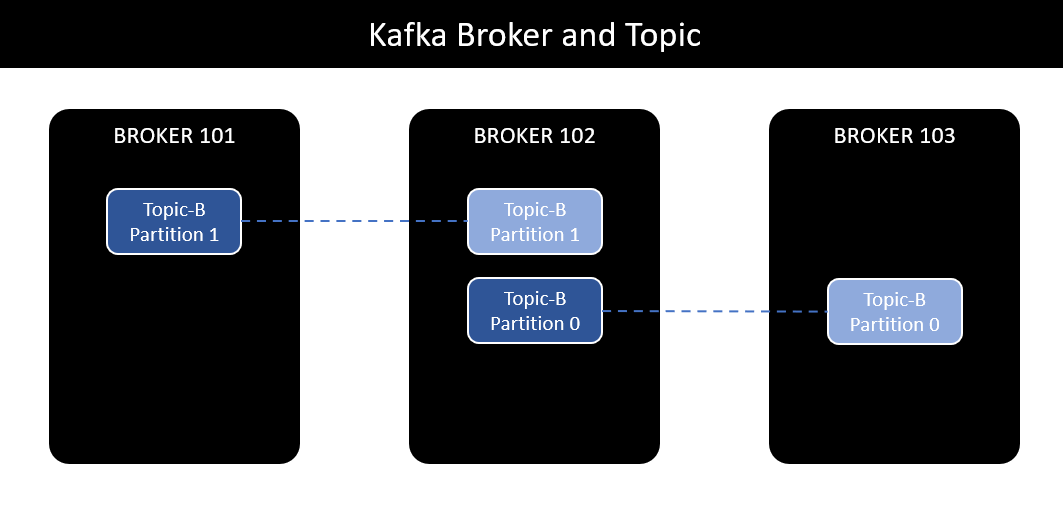
Có thể hình dung các replication của một topic là một dev team. Mỗi khi có thêm feature mới, có 2 cách để team quyết định implement luôn không:
- Thứ nhất, cả team cùng vote: cách này khá fair nhưng mất thời gian. Mỗi khi có feature mới lại họp hành biểu quyết - Peer-to-Peer.
- Thứ hai, bầu ra leader quyết định thay cho cả team: cách này phụ thuộc vào leader nhưng không mất thời gian họp hành. Ông leader nghỉ việc thì bầu ông khác lên thay - Leader - Follower
Để đảm bảo yếu tố performance và tránh rắc rối khi đồng bộ message giữa các replication, Kafka lựa chọn implement theo hướng Leader - Follower, chỉ định một và chỉ một replication bất kì làm leader.
Không chỉ riêng Kafka mà khá nhiều các hệ thống khác đều áp dụng mô hình Leader - Follower.
Như vậy, tất cả các thao tác read/write message của partition đều thông qua replication leader:
- Tại một thời điểm, mỗi partition có duy nhất một replication leader.
- Chỉ có thể read/write message từ replication leader.
- Các replication còn lại được gọi là ISR, đồng bộ message từ replication leader.
- Do vậy, mỗi partition có duy nhất một replication leader và một hoặc nhiều ISR - in-sync replica.
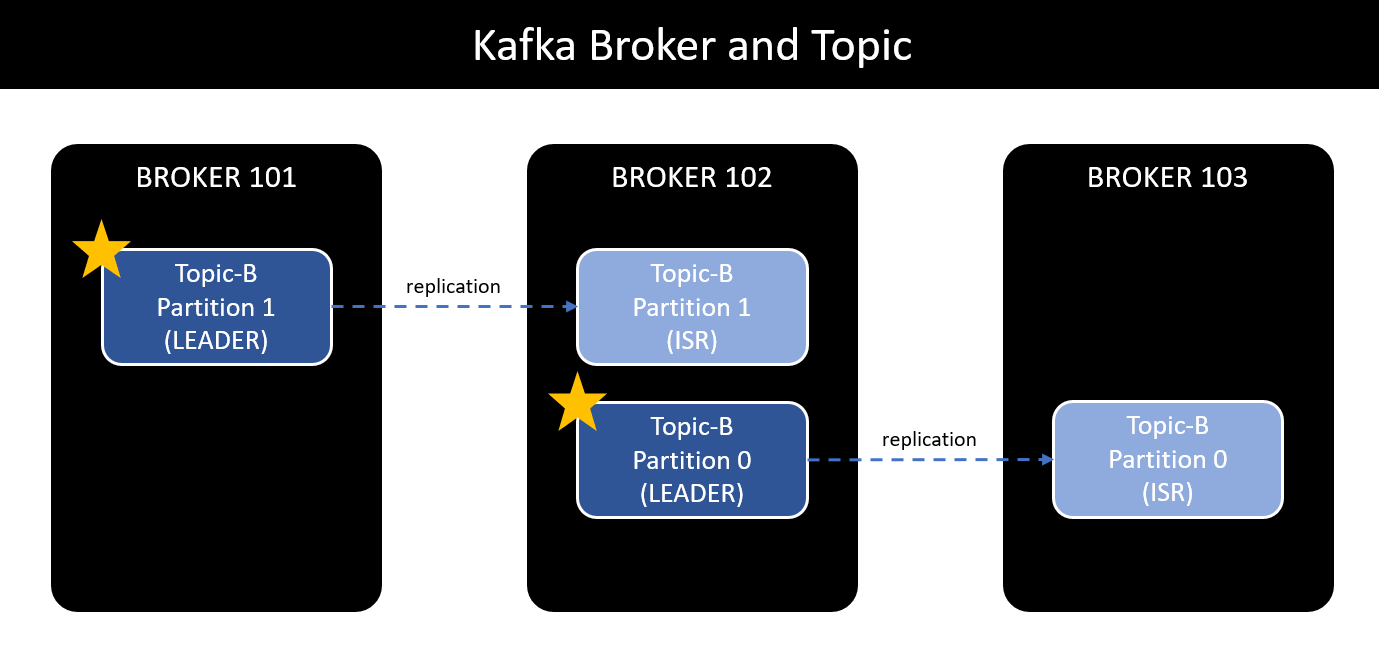
Trong trường hợp Broker 101 gặp sự cố, replication leader của partition 1 không còn hoạt động. Lúc này, một trong các ISR còn lại sẽ trở thành Leader và partition trở lại hoạt động bình thường.
Một câu hỏi khác được đặt ra - Ai là người quyết định replication nào trở thành Leader hay ISR?
Đó là nhiệm vụ của ZooKeeper. Nó làm thế nào, sử dụng thuật toán gì, đón chờ phần sau nhé.
2) Producer
2.1) Producer
Producer là người gửi message đến Message broker. Cụ thể với Kafka, producer write data vào partition của topic.
Producer tự động biết nên write vào broker nào và partition nào. Trong trường hợp đang write data mà broker gặp sự cố, producer sẽ có cơ chế tự động retry cho đến khi thành công.

Nghe không ổn lắm, nếu producer tự assign các message vào partition thì làm cách nào đầu nhận có thể lấy đúng message?
Trong trường hợp gửi message đến topic mà không chỉ định partition, producer sẽ gửi message đến broker theo cơ chế round-robin.
Message đầu tiên đi vào broker 101, message thứ hai đi vào broker 102, message tiếp theo đi vào broker 103... cứ như vậy, các message được write balance giữa các broker.
Tiếp tục đến bài toán khác, làm thế nào producer biết message đã được write thành công ở partition? Chẳng cách nào khác ngoài cơ chế ack - acknowledgment.
Producer có thể lựa chọn nhận ack từ Kafka để chắc chắn rằng message được gửi thành công:
- acks=0: giống fire-and-forget, gửi message mà không chờ phản hồi. Do vậy có thể dẫn đến tình huống mất message.
- acks=1: default setting. Lần này chắc chắn hơn, producer chờ cho tới khi nhận được phản hồi từ replication leader. Tuy nhiên chưa ngăn chặn hoàn toàn việc mất message. Replication leader write message thành công, báo lại cho producer, tuy nhiên broker có thể gặp sự cố với disk, không thể khôi phục data.
- acks=all: lần này thì quá chắc chắn, đảm bảo không mất message. Producer sẽ nhận được phản hồi khi tất cả replication leader và IRS write data thành công.
Dễ dàng nhận thấy cái giá phải trả cho việc đảm bảo không mất message là performance.
2.2) Message key
Làm thế nào để điều hướng message đến chính xác partition mình mong muốn để đảm bảo message ordering?
- Câu trả lời là.. có thể đảm bảo message ordering, nhưng để điều hướng đến chính xác partition mong muốn thì hơi khó - Kafka sẽ xử lý việc này cho chúng ta.
Nếu muốn các message liên quan với nhau được gửi vào cùng partition và order theo thứ tự, cần define key cho mỗi message.
- Key có thể là bất kì loại dữ liệu nào: string, number...
- Nếu key = null, message được gửi đến broker/partition theo cơ chế round-robin.
- Nếu key != null, tất cả các message có cùng key sẽ đi vào cùng broker/partition.
Có thể coi key là tấm thẻ bài phân luồng của message. Nếu bạn không có thẻ bài, tôi sẽ điều hướng bạn đến bất kì đâu. Ngược lại, tôi sẽ kiểm tra và tìm đúng luồng cho bạn.
Quay lại ví dụ Grab bài trước, không cần quan tâm thứ tự gửi giữa nhiều tài xế, chỉ cần đảm bảo message của từng tài xế đúng thứ tự. Vậy, có thể sử dụng driver_id làm message key.
- Toàn bộ message của driver_007 có thể đi vào partition 0 hoặc partition 1.
- Toàn bộ message của driver_009 có thể đi vào partition 1 hoặc partition 0.
Không cần quá quan tâm message thực sự đi vào partition nào. Chỉ cần biết cùng message key sẽ vào cùng partition.
Kafka sử dụng các thuật toán hashing và rounting để điều phối message có cùng key đến cùng partition. Chúng ta hoàn toàn có khả năng điều phối message đến chính xác partition mong muốn bằng cách đọc code Kafka, tuy nhiên nó chẳng giúp giải quyết vấn đề gì.
Chốt, với producer có 3 thứ cần quan tâm và ghi nhớ:
- Ackowledgement.
- Round-robin.
- Message key.
3) Consumer
3.1) Consumer
Có gửi thì có nhận, và consumer là đầu nhận message.
- Consumer đọc message từ topic, xác định bằng topic name.
- Đồng thời, consumer biết nên đọc message từ broker nào. Trong trường hợp chưa read xong mà broker gặp sự cố, consumer cũng có cơ chế tự phục hồi.
- Việc đọc message trong một partition diễn ra tuần tự để đảm bảo message ordering. Có nghĩa là consumer không thể đọc message offset=3 khi chưa đọc message offset=2.
- Một consumer cũng có thể đọc message từ một hoặc nhiều hoặc tất cả partition trong một topic.
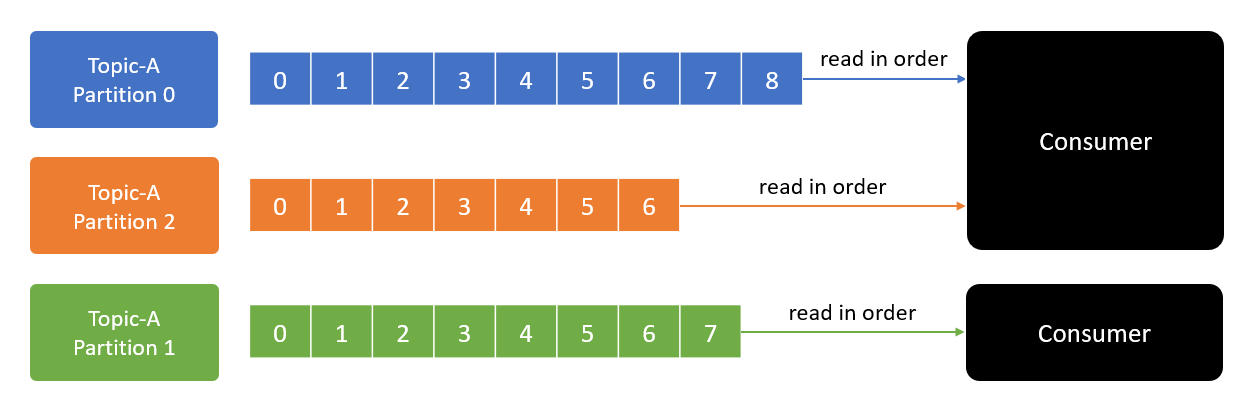
Quan trọng nên cần nhắc đi nhắc lại:
- Message ordering chỉ đảm bảo trong một partition. Việc đọc ghi message giữa nhiều partition không đảm bảo thứ tự.
- Message offset=5 ở partition 0 có thể được đọc trước message offset=2 ở partition 1.
3.2) Consumer group
Đã có consumer lại mọc thêm consumer group. Vậy consumer group là gì và giải quyết vấn đề gì?
Quay lại phần trước, consumer là nơi đọc message từ topic. Có nghĩa là một consumer có thể đọc toàn bộ message của tất cả partition thuộc cùng topic.
Nếu số lượng producer tăng lên và đồng thời gửi message đến tất cả partition trong khi chỉ có duy nhất một consumer thì khả năng xử lý sẽ rất chậm, có thể dẫn tới bottle-neck. Giải pháp là tăng số lượng consumer, các consumer có thể xử lý đồng thời message từ nhiều partition. Và tất cả các consumer sẽ thuộc cùng một nhóm được gọi là consumer group.
Như vậy, consumer group read toàn bộ data của các partition và chia vào các consumer bên trong để xử lý.
Mỗi consumer thuộc consumer group sẽ đọc toàn bộ data của một hoặc nhiều partition để đảm bảo message ordering. Không tồn tại nhiều consumer cùng đọc message từ một partition.
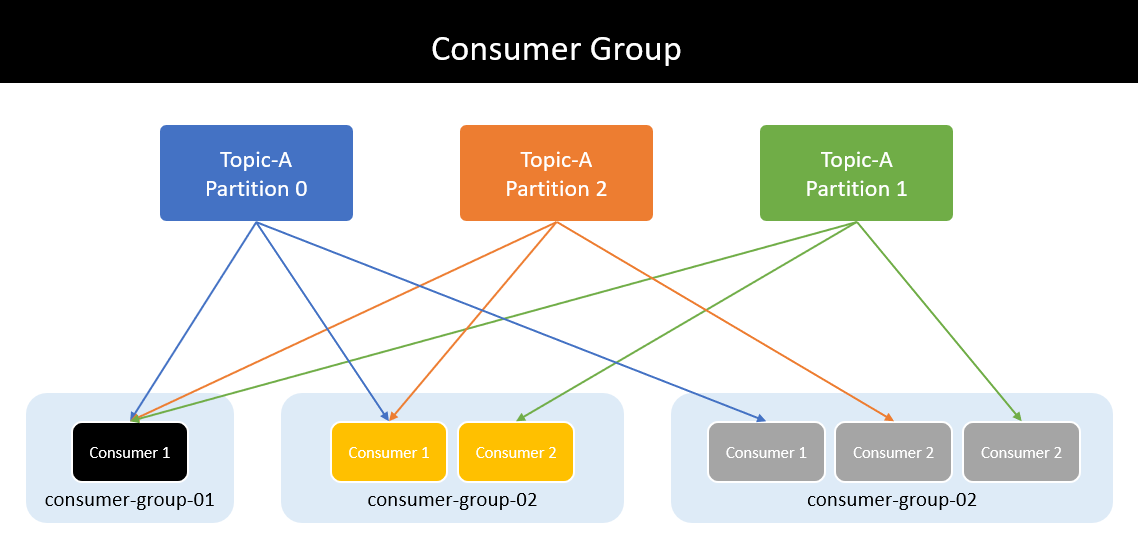
Một consumer có thể nhận message từ nhiều partition. Nhưng một partition không thể gửi message cho nhiều consumer trong cùng consumer group.
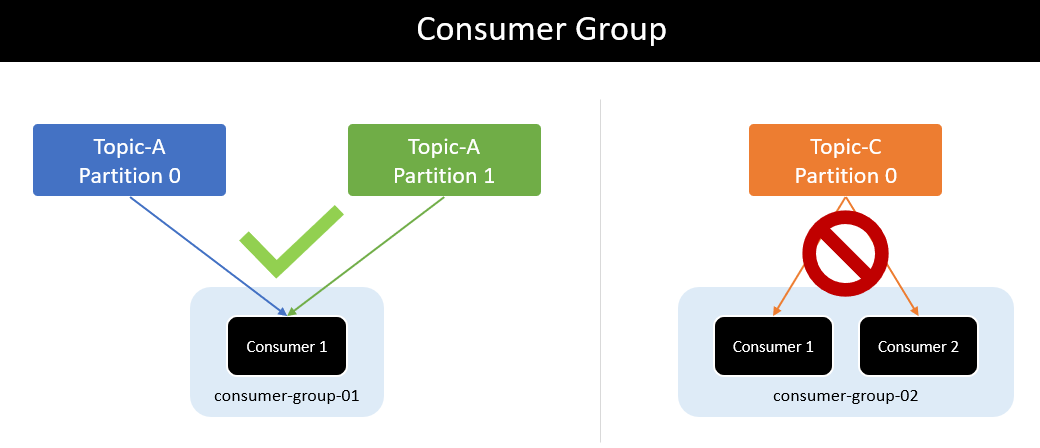
Nếu số lượng consumer trong consumer group lớn hơn số lượng partition thì những consumer dư thừa có trạng thái inactive - không nhận bất kì message nào từ topic.
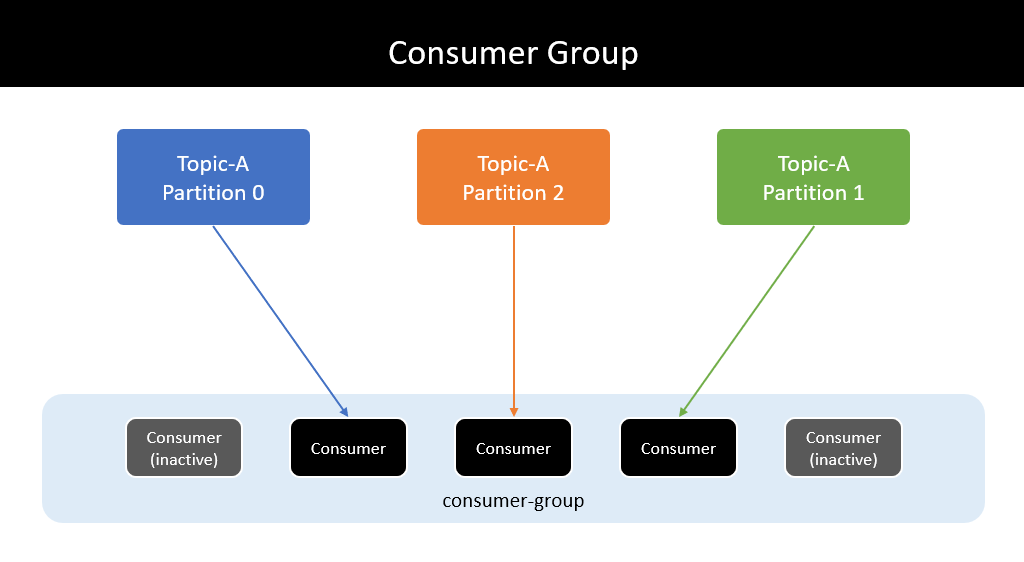
Có vẻ vô nghĩa nhưng một vài trường hợp số lượng consumer trong group sẽ lớn hơn số lượng partition.
Trong trường hợp một active consumer gặp vấn đề và không thể tiếp tục hoạt động, một trong những inactive consumer còn lại được đẩy lên thay thế và tiếp tục công việc ngay lập tức.
Nếu không có inactive consumer nào, message sẽ được route tới một active consumer bất kì khác.
Quá trình re-assign này được gọi là partition rebalance.
Chia thành càng nhiều partition và càng nhiều consumer thì số lượng message được xử lý đồng thời càng nhiều, phần nào cải thiện performance của hệ thống.
- Từ 1 partition/1 consumer thành 5 partition/5 consumer khả năng sẽ đem lại performance tốt.
- Nhưng lên 1000 partition/1000 consumer thì chưa chắc.
4) Queue và Topic trong Apache Kafka
Như vậy chúng ta đã đi qua các thành phần quan trọng của Kafka, từ việc lưu trữ message với offset, partition, replication, topic, broker cho đến gửi nhận message với producer và consumer.
Phần cuối cùng trong bài sẽ nói về cách implement queue và topic với Kafka:
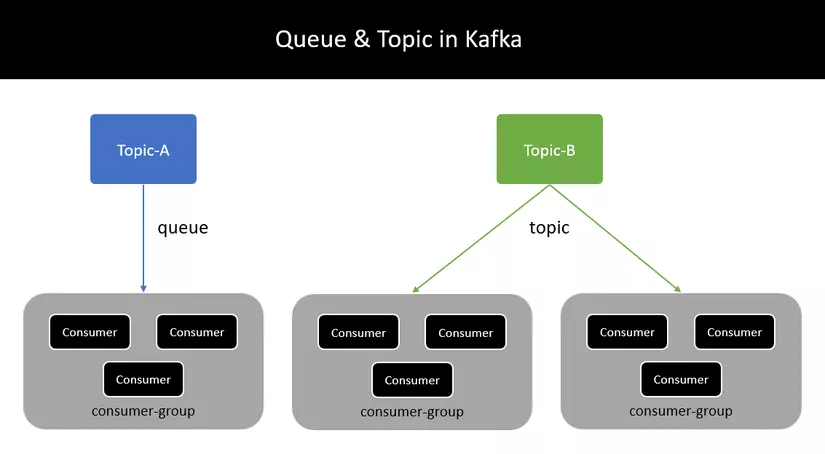
- Point-to-point messaging - Queue.
- Broadcast messaging - Topic.
Thực ra nó đã lồ lộ ở phần consumer group, chỉ là chúng ta có nhận ra hay không.
- Nếu một topic có duy nhất một consumer group, nó là point-to-point messaging - queue.
- Ngược lại nếu muốn implement hệ thống broadcast messaging - topic, hãy tạo ra nhiều consumer group subcribe trên cùng một topic.
Reference
Reference in series https://viblo.asia/s/apache-kafka-tu-zero-den-one-aGK7jPbA5j2
© Dat Bui