Bài viết nằm trong series Performance optimization với PostgreSQL.
Tiếp tục bài trước, cùng đi tìm hiểu về 2 loại partition còn lại là:
- Partition by list
- Partition by hash
Let's begin.
1) Partition by list
Với list partitioning, việc phân chia ra các partition dựa trên key được định nghĩa dưới dạng list of value. Ví dụ với table ENGINEER, các engineer có title Backend Engineer, Frontend Engineer, Fullstack Engineer nhóm vào thành một partition; BA và QA một partition; còn lại là default partition. Triển thôi:
DROP TABLE ENGINEER CASCADE; CREATE TABLE ENGINEER
( id bigserial NOT NULL, first_name character varying(255) NOT NULL, last_name character varying(255) NOT NULL, gender smallint NOT NULL, country_id bigint NOT NULL, title character varying(255) NOT NULL, started_date date, created timestamp without time zone NOT NULL
) PARTITION BY LIST(title); CREATE TABLE ENGINEER_ENGINEER PARTITION OF ENGINEER FOR VALUES IN ('Backend Engineer', 'Frontend Engineer', 'Fullstack Engineer'); CREATE TABLE ENGINEER_BA_QA PARTITION OF ENGINEER FOR VALUES IN ('BA', 'QA'); CREATE TABLE ENGINEER_DEFAULT PARTITION OF ENGINEER DEFAULT;
Về mục đích cũng không khác gì partition by range ngoài việc chia nhỏ ra thành nhiều partition. Tuy nhiên, trường hợp áp dụng sẽ có khác nhau đôi chút:
- List partition phân chia table dựa trên danh sách các giá trị cho trước, không theo khoảng giá trị như range partition. Do đó, nó phù hợp phân chia dữ liệu theo những giá trị cụ thể, giống bài toán phân chia nam, nữ ở phần trước.
2) Partition by hash
Lại là hash, nhưng lần này là hash partition. Idea không có gì phức tạp, các bước thực hiện như sau:
- Thực hiện hash partition key ra hash value.
- Modulus để tìm partition cho record. Ví dụ record có partition key hash value = 5, tổng số lượng partition là 3 (0, 1, 2), lấy 5 % 3 = 2. Vậy record đó nằm ở partition thứ ba.
DROP TABLE ENGINEER CASCADE; CREATE TABLE ENGINEER
( id bigserial NOT NULL, first_name character varying(255) NOT NULL, last_name character varying(255) NOT NULL, gender smallint NOT NULL, country_id bigint NOT NULL, title character varying(255) NOT NULL, started_date date, created timestamp without time zone NOT NULL
) PARTITION BY HASH(country_id); CREATE TABLE ENGINEER_P1 PARTITION OF ENGINEER FOR VALUES WITH (MODULUS 3, REMAINDER 0); CREATE TABLE ENGINEER_P2 PARTITION OF ENGINEER FOR VALUES WITH (MODULUS 3, REMAINDER 1); CREATE TABLE ENGINEER_P3 PARTITION OF ENGINEER FOR VALUES WITH (MODULUS 3, REMAINDER 2);
Như vậy với hash partition, không dễ để đoán được một record nằm ở partition nào. Cho dù bạn có biết thuật toán hash, cũng cần thêm một vài step để biết được đáp án. Vậy nên, hash partition phù hợp với:
- Các dữ liệu không nhất thiết phải thuộc cùng một group để nhóm vào một partition.
- Không cần thực hiện các lệnh đặc biệt với một nhóm data nào đó, ví dụ như drop.
- Với hash partition, chỉ cần đạt được mục đích cố gắng chia thành nhiều partition cân bằng nhau là được. Như vậy đủ để tăng performance cho query.
Insert lại data và query thử nhé:
EXPLAIN SELECT * FROM ENGINEER WHERE COUNTRY_ID = 1;
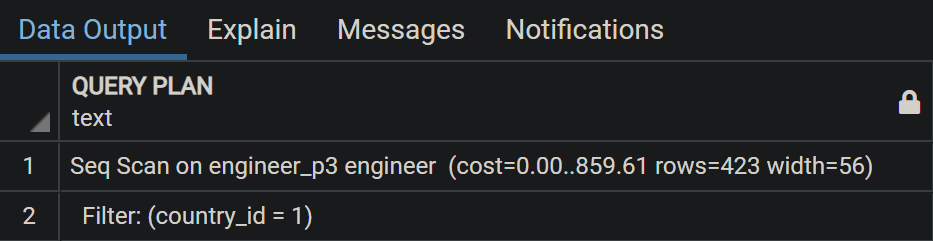
Query plan sẽ tự biết record nằm ở partition table nào và thực hiện sequence scan trên table đó luôn. Nếu query plan và PostgreSQL thông minh đến vậy thì tại sao không partition toàn bộ các table để tăng query performance? Có bí ẩn gì đằng sau mà ta chưa biết không?
Trước khi đi tìm câu trả lời, tổng kết lại những lợi ích mà partition đem lại nhé:
- Biến một logical table thành nhiều physical table, giảm không gian tìm kiếm, tăng performance cho query trong trường hợp tận dụng được điều kiện WHERE với partition key.
- Xóa bỏ các data cũ một cách dễ dàng, nhanh chóng so với cách truyền thống. Ví dụ cần xóa tất cả các record có giới tính nam, nếu chia partition theo giới tính từ đầu. Chỉ cần TRUNCATE/DROP partition đó là ok. Không cần seq scan để DELETE record với WHERE condition.
Ngoài ra, nó cũng có một vài hạn chế cơ bản cần quan tâm:
- Unique constraint, PK constraint không thể thực hiện trên table chính mà phải thực hiện ở partition table.
- Các partition table không thể có column nào khác mà không khai báo ở parent table. Nói cách khác, nó kế thừa toàn bộ column và data type của parent table.
- Một vài vấn đề liên quan đến trigger. Ví dụ BEFORE ROW trigger ON INSERT. Nó thực hiện trigger function/procedure... trước khi row được insert vào table.
3) Partition pruning
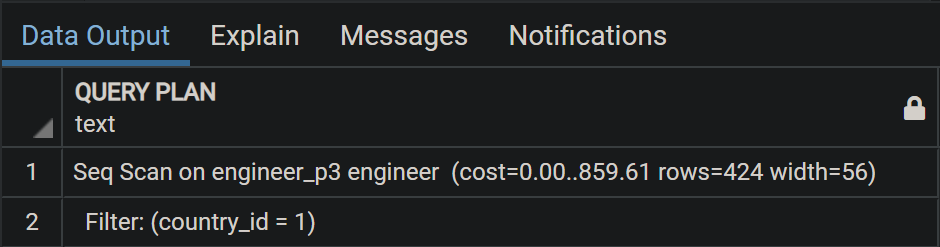
Quay lại phần trước, sử dụng data đã tạo với hash partition, explain 2 query sau đều ra computation cost như nhau:
EXPLAIN SELECT * FROM ENGINEER WHERE country_id = 1;
EXPLAIN SELECT * FROM ENGINEER_P3 WHERE country_id = 1;
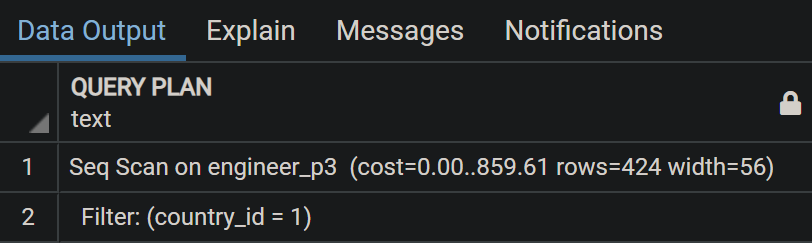
PostgreSQL query plan tự động chuyển sang partition ENGINEER_3 để thực hiện scan vì nó biết record có country_id = 1 nằm ở đó. Mấu chốt chính là partition pruning, nó là thứ bí ẩn đằng sau giúp tối ưu plan nhằm tăng performance cho các query có điều kiện dựa trên partition table cụ thể. Mặc định, partition pruning ở chế độ ON, bây giờ OFF nó đi và thực hiện lại query nhé:
SET enable_partition_pruning = off; EXPLAIN SELECT * FROM ENGINEER WHERE country_id = 1;
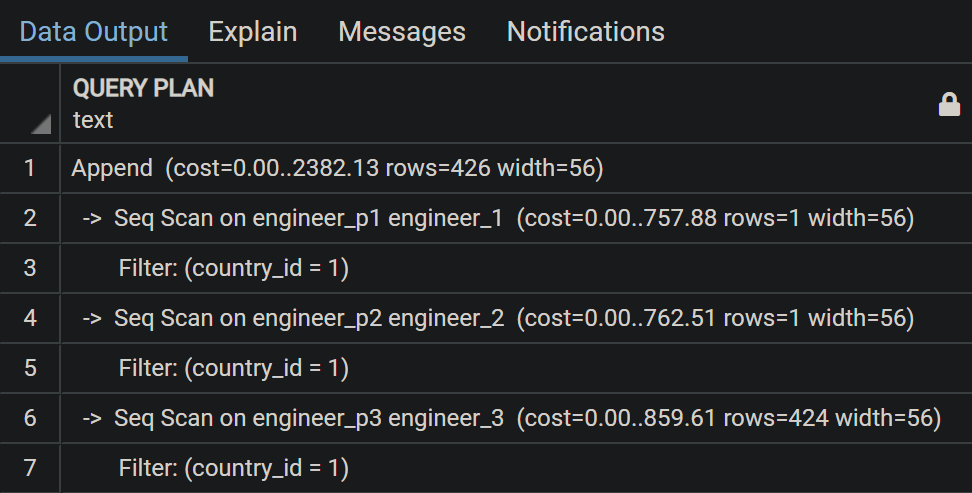
Vỡ alo, giờ thì seq scan từng partition để tìm ra record phù hợp  .
.
Partition pruning chỉ phát huy sức mạnh khi điều kiện WHERE phù hợp với partition key.
4) Multi-level partition
Mình có nhận được câu hỏi khá hay ở bài trước:
- Tại một thời điểm nào đó, toàn bộ 95% query chỉ rơi vào một partition table thì sao, chúng ta xử lý thế nào?
Trước khi trả lời câu hỏi cần phân tích lại về mục đích của partitioning.
- Phân chia table lớn thành nhiều partition table, từ đó giảm không gian tìm kiếm để tăng query performance. Time complexity giảm từ 0(n) xuống 0(k) với k < n. Đó cũng là lý do vì sao với các table nhỏ, partition không phát huy được nhiều sức mạnh.
Ví dụ trong 10s có 1000 queries đều rơi vào một partition, quá tốt rồi, nếu query plan xác định được partition ngay từ đầu và thực hiện partition pruning, chẳng phải mục đích ban đầu đã đạt được rồi hay sao. Nên việc 95% query vào một hay nhiều partition không phải là một vấn đề ta cần quan tâm. Thậm chí nếu không partition ở đây, không gian tìm kiếm tăng lên và làm giảm query performance.
Vấn đề sẽ thực sự xảy ra khi query plan/query execution không thể partition pruning dẫn đến việc phải scan toàn bộ các partition. Việc scan có thể được thực hiện seq hoặc parallel giữa các partition tuy nhiên nó phụ thuộc vào điều kiện tìm kiếm. Tuy nhiên, computation cost lúc này sẽ gần bằng việc không partition thậm chí tốn hơn vì có rất nhiều behind the scenes mà ta không nắm được hết. Lúc này tội lỗi không nằm ở partition nữa mà là cách design của chúng ta có vấn đề .
Đấy cũng là lý do vì sao không phải table nào cũng đi partition để hưởng chút lợi ích từ việc đó. Giống như việc mang dao mổ trâu đi giết gà vậy, trói gà không chặt, chém mạnh quá trượt vào tay chân thì còn chết nữa .
Ta thấy được lợi ích chính của partition là thu hẹp không gian tìm kiếm, vậy nếu có thể tiếp tục thu hẹp partition của 95% query kia chẳng phải tốt hơn sao? Quẩy thôi, lúc này ta cần multi-level partition. Nghe có vẻ nguy hiểm nhưng lại chẳng có gì, nhìn vào hình minh họa sau cũng dễ dàng hiểu được.
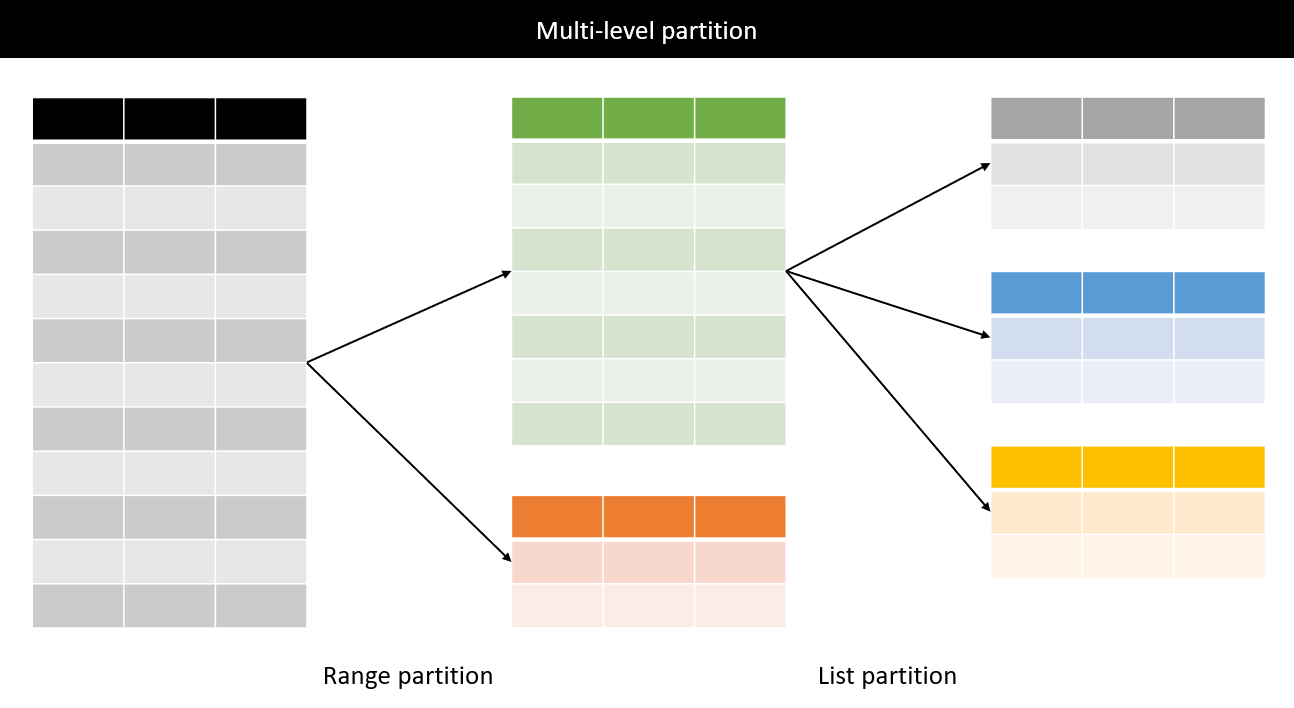
Quanh đi quẩn lại vẫn dựa trên Tree data structure . Nếu phân tích được và bắt thóp 95% query đó dựa trên condition gì, ta hoàn toàn có thể partition tiếp partition table thành những partition nhỏ hơn để phục vụ bài toán . Tuy nhiên, nó cũng có những drawback mình đã nói ở trên. Hãy cân nhắc thật kĩ trước khi quyết định.
DROP TABLE ENGINEER;
CREATE TABLE ENGINEER
( id bigserial NOT NULL, first_name character varying(255) NOT NULL, last_name character varying(255) NOT NULL, gender smallint NOT NULL, country_id bigint NOT NULL, title character varying(255) NOT NULL, started_date date, created timestamp without time zone NOT NULL
) PARTITION BY RANGE(started_date); CREATE TABLE ENGINEER_Q1_2020 PARTITION OF ENGINEER FOR VALUES FROM ('2020-01-01') TO ('2020-04-01') PARTITION BY LIST(title); CREATE TABLE ENGINEER_DF PARTITION OF ENGINEER DEFAULT; CREATE TABLE ENGINEER_Q1_2020_SE PARTITION OF ENGINEER_Q1_2020 FOR VALUES IN ('Backend Engineer', 'Frontend Engineer', 'Fullstack Engineer');
CREATE TABLE ENGINEER_Q1_2020_BA PARTITION OF ENGINEER_Q1_2020 FOR VALUES IN ('BA', 'QA');
CREATE TABLE ENGINEER_Q1_2020_DF PARTITION OF ENGINEER_Q1_2020 DEFAULT;
Insert data và query xem thế nào:
EXPLAIN SELECT * FROM ENGINEER WHERE started_date = '2020-02-02';
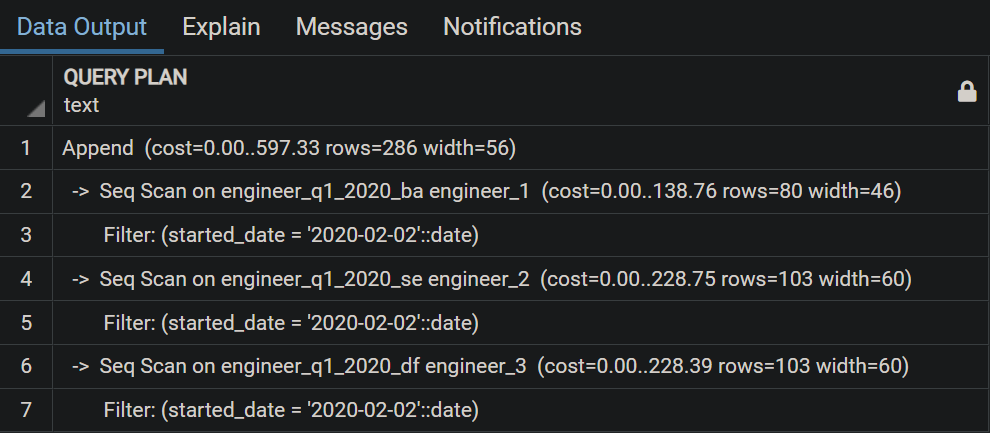
Khá dễ hiểu, started_date nằm trong partition ENGINEER_Q1 nên query plan thực hiện seq scan trên toàn bộ partition con của nó.
Thay đổi query, thêm điều kiện tìm kiếm title:
EXPLAIN SELECT * FROM ENGINEER WHERE started_date = '2020-02-02' AND title = 'BA';
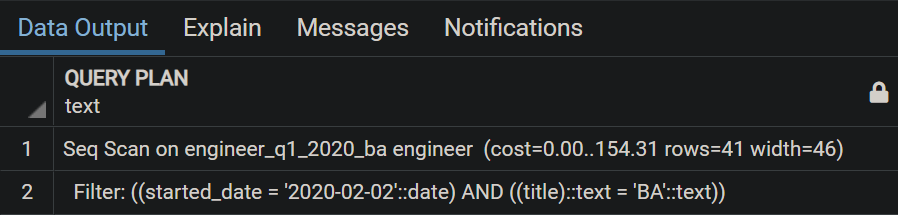
Ngon rồi, nhờ partition pruning nên query plan chỉ thực hiện scan trên partition ENGINEER_Q1_BA.
Bạn có thể thêm ANALYZE để xem thêm thông số về query execution nhé. Với các table ít record, độ chênh lệch về execution time không đáng kể. Tuy nhiên với table lớn cỡ vài hoặc vài chục GB, tác dụng là rõ ràng luôn (với query có where condition phù hợp).
Reference
Reference in series https://viblo.asia/s/performance-optimization-voi-postgresql-OVlYq8oal8W
After credit
Một cách khác khá giống với Horizontal partitioning là Sharding, chung một mục tiêu duy nhất: giảm size của table để tăng query performance. Tuy nhiên chúng có sự khác nhau đôi chút. Partitioning là việc chia tách các table theo chiều ngang nhưng nằm trên cùng một physical database/physical machine. Sharding cũng chia tách table theo chiều ngang nhưng các table nằm trên nhiều physical database/physical machine khác nhau, và thường sharding sử dụng PK làm partition key.
Mục đích của sharding là giảm tải cho hệ thống bằng cách phân tải query ra nhiều database trên nhiều server dẫn tới tăng query performance, tuy nhiên sẽ gặp vấn đề hot partition, chính là câu hỏi 95% query ở trên. Khi ấy, toàn bộ các query sẽ tập trung vào một server duy nhất dẫn đến việc không đạt được mục đích ban đầu.
Đón chờ series tiếp theo để tìm hiểu kĩ hơn về sharding và database system nhé. Bài sau sẽ bàn luận về Materialized view.
© Dat Bui