Bài viết nằm trong series Performance optimization với PostgreSQL.
Chúng ta đã nghe nhiều về ACID là 4 tính chất tạo nên thương hiệu của relational databse. Mình trước đây khá mù mờ gọi là hiểu sơ sơ để phỏng vấn.. và tất nhiên chẳng thể nào qua mặt được các Senior tài ba.
Bài viết này sẽ tập trung vào tính isolation - transaction isolation.
Chỉ với câu hỏi dưới đây, ta sẽ biết mình thật sự hiểu về transaction isolation thế nào.
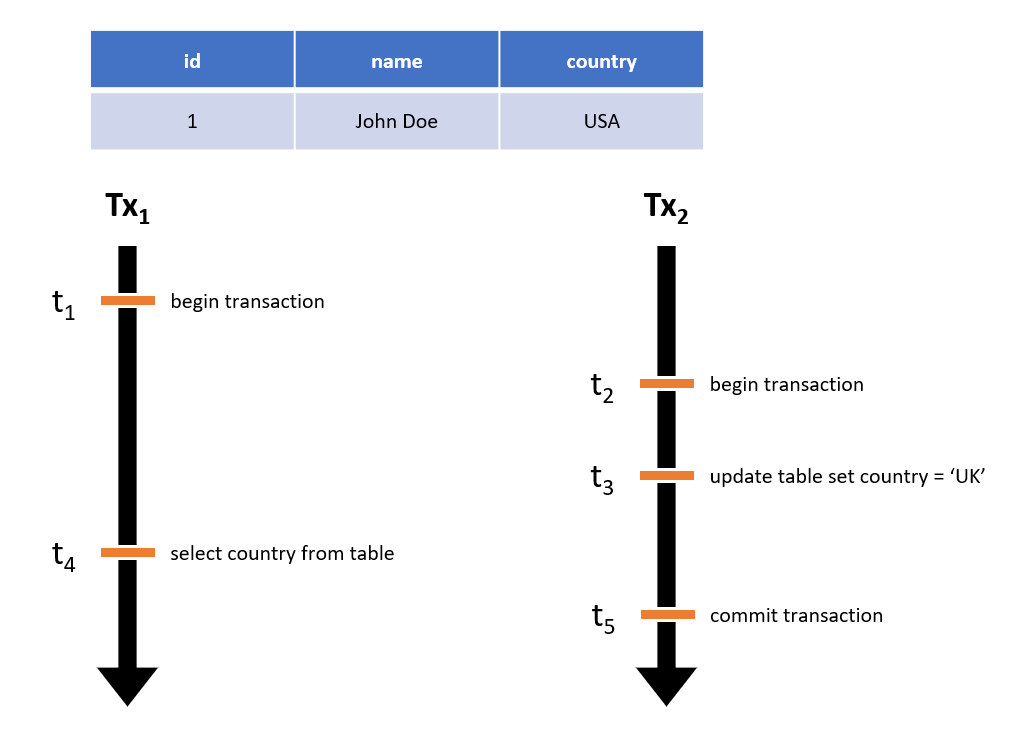
Thời điểm T4, Tx1 đọc giá trị country là gì?
- USA
- UK
Cả 2 đáp án đều có thể xảy ra. Transaction isolation level sẽ quyết định cụ thể giá trị của country sẽ là gì. Cùng đi tìm hiểu kĩ hơn trong bài viết này nhé. Let's begin.
Transaction isolation
Có thể hiểu transaction isolation là mức độ cô lập dữ liệu của transaction này so với transaction khác.
Đến thời điểm hiện tại, theo tài liệu chính thống về Standard SQL Transaction isolation levels có tất cả 4 loại bao gồm:
- Read uncommitted.
- Read committed.
- Repeatable read.
- Serializable.
Một số tài liệu có thêm Sapshot, bàn luận về nó sau. Tạm thời chúng ta hiểu đa số các database sẽ support 4 level như trên. Cùng đi tìm hiểu kĩ hơn thông qua các practice nhé.
1) Read uncommitted
Có thể coi mỗi transaction là một hàng phòng thủ, nơi bên trong đó thực hiện hàng loạt các thao tác với database. Hàng phòng thủ này có những ngoại lệ nhất định, mức độ bảo vệ tăng dần từ thấp đến cao, là các isolation level. Level đầu tiên với mức phòng phủ lỏng lẻo nhất là read uncommitted.
Read uncommitted - đọc lên là hiểu ngay ý nghĩa có nó. Nó nói đến việc các transaction có thể đọc những data mới nhất, không quan tâm đến việc data đó được commit hay chưa.
Như vậy với câu hỏi đầu bài, nếu set transaction isolation level là read uncommitted, Tx1 sẽ đọc giá trị của country là UK tại thời điểm T4.
Sau đó, Tx1 tiếp tục thực hiện một loạt các hành động sau đó với giá trị vừa đọc được và commit. Mọi chuyện vẫn ổn nếu Tx2 không rollback sự thay đổi vừa rồi.
Hãy coi transaction Tx1 và Tx2 là 2 khu vực quân sự đối lập nhau. Các cụ đã dạy Biết người biết ta trăm trận trăm thắng, áp dụng câu nói đó Tx1 cử người đi do thám tình hình và phát hiện kẻ địch Tx2 thực hiện tấn công theo phương án A.
Tx1 nghĩ rằng mình đã đi trước một bước, lập tức triển khai kế hoạch phòng thủ để tạo bất ngờ.
Thế nhưng Tx2 bất ngờ hủy kèo, chuyển sang phương án B. Tx1 không kịp trở tay thay quần áo, bị đánh banh xác.
Hơi đen, sau trận thua này Tx1 đã biết thêm bài học Dương Đông kích Tây.
Tương tự với các transaction, nếu Tx1 đọc và xử lý các data chưa được commit từ Tx2, khả năng cao Tx1 sẽ hẹo giống như trận chiến trên. Dẫn đến hậu quả không thể lường trước cho hệ thống.
Việc đọc data uncommitted như vậy được gọi là dirty read hoặc uncommitted read (UR). Ta đã thấy được hậu quả của dirty read, vậy ưu điểm của nó là gì và áp dụng trong trường hợp nào:
- Performance của dirty read rất tốt vì không có lock. Cộng với nhược điểm của nó nên sẽ phù hợp hơn với các bài toán dạng thống kê, chấp nhận việc sai số liệu.
- Ngoài ra với những business flow chỉ cho phép single user/single thread/single transaction thực hiện thao tác trên database, sử dụng UR sẽ đem lại hiệu quả tốt.
Với PostgreSQL, chúng ta không thể thực hiện uncommitted read. Nguyên dân do cơ chế Multi-version concurrency control mình đã giới thiệu ở bài trước. Mỗi transaction giữ một tuple riêng cho record để giảm thiểu vấn đề locking khi thực hiện concurrent read/write.
Với các database khác như MySQL, chúng ta có thể thực hiện các transaction với read uncommitted level. Có thể thử nghiệm để kiểm chứng nhé.
2) Read committed
An toàn hơn UR là CR - committed read, là level mặc định của transaction isoliation cho hầu hết tất cả database.
Transaction sẽ không thấy data/không thể update data đang được modify ở transaction khác mà chưa commit.
Đến giờ thực hành, mở 2 session và bắt đầu thôi. Vẫn sử dụng table từ bài trước, clear và tạo các test records:
TRUNCATE TABLE country; INSERT INTO country(id, country_name, created) VALUES(1, 'Afghanistan', CURRENT_TIMESTAMP);
INSERT INTO country(id, country_name, created) VALUES(2, 'Albania', CURRENT_TIMESTAMP);
INSERT INTO country(id, country_name, created) VALUES(3, 'American Samoa', CURRENT_TIMESTAMP);
INSERT INTO country(id, country_name, created) VALUES(4, 'Andorra', CURRENT_TIMESTAMP);
INSERT INTO country(id, country_name, created) VALUES(5, 'Argentina', CURRENT_TIMESTAMP); COMMIT;
Transaction thứ nhất (Tx1) thực hiện:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; UPDATE FROM country SET country_name = 'United Kingdom' WHERE id = 1; SELECT * FROM country WHERE id = 1;
Transaction thứ hai (Tx2):
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; SELECT * FROM country WHERE id = 1;
Kết quả của 2 transaction sẽ khác nhau, Tx2 vẫn nhận giá trị country = Afghanistan.
Sau khi Tx1 thực hiện commit, query lại data ở Tx2 sẽ nhận giá trị country = United Kingdom.
Có vẻ CR khá an toàn khi chỉ đọc data mới nhất đã được commit, tránh tình huống thực hiện business với dirty record.
Tuy nhiên nó dẫn đến vấn đề khác về sự nhất quán dữ liệu. Thử một ví dụ mới, thực hiện read data ở Tx1:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; SELECT * FROM country WHERE id = 1;
| id | country_name | created |
|---|---|---|
| 1 | United Kingdom | yyyy-mm-dd HH:MM:ss.ssssss |
Thực hiện update data ở Tx2 nhưng chưa commit:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; UPDATE country SET country_name = 'Russia' WHERE id = 1;
Quay về Tx1 thực hiện lại câu SELECT, data không thay đổi. Chuẩn rồi, không có dirty read nữa. Tiến hành commit Tx2 và SELECT lại ở Tx1, kết quả đã thay đổi:
| id | country_name | created |
|---|---|---|
| 1 | Russia | yyyy-mm-dd HH:MM:ss.ssssss |
Vấn đề xảy ra là mặc dùng cùng transaction Tx1 nhưng mỗi thời điểm khác nhau lại đọc ra giá trị khác nhau của record id = 1. Dữ liệu lúc này không nhất quán, nếu thực hiện business logic quan trọng nào đó phụ thuộc vào kết quả này có thể dẫn tới hệ quả khó lường.
Nó được gọi là non-repeatable read, đọc được các giá trị khác nhau trong thời điểm khác nhau của cùng một dữ liệu thuộc cùng một transaction.
Một tình huống khác khi select data với điều kiện bất kì trả về 5 bản ghi. Nhưng lúc sau thực hiện query lại ra 6 bản ghi.
Thực hành để hiểu rõ hơn. Với Tx1:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; SELECT * FROM country;
Với Tx2:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED; INSERT INTO country(id, country_name, created) VALUES(6, 'Brazil', CURRENT_TIMESTAMP); COMMIT;
Thực hiện select lại ở Tx1, lúc này đã có 6 bản ghi. Tx1 không biết sự tồn tại của Tx2 vì các transaction độc lập với nhau. Rõ ràng không làm gì mà tự nhiên tòi ra thêm records nữa.
Record đó được gọi là phantom row - bản ghi ma quái
. Cách read data dạng này được gọi là phatom read.
Như vậy committed read có thể ngăn chặn dirty read nhưng không thể ngăn chặn non-repeatable read và phantom read.
3) Repeatable read
Nghe phát hiểu luôn, để xử lý non-repeatable read thì sử dụng repeatable read  . Tức là trong cùng một transaction, đảm bảo dữ liệu chắc chắc là thống nhất trong tất cả các lần query, không quan tâm đến việc các transaction khác đã commit sự thay đổi hay chưa.
. Tức là trong cùng một transaction, đảm bảo dữ liệu chắc chắc là thống nhất trong tất cả các lần query, không quan tâm đến việc các transaction khác đã commit sự thay đổi hay chưa.
Ở Tx1, thực hiện read data:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; SELECT * FROM country WHERE id = 1;
| id | country_name | created |
|---|---|---|
| 1 | Russia | yyyy-mm-dd HH:MM:ss.ssssss |
Tx2 thực hiện thay đổi data và commit:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; UPDATE country SET country_name = 'Germany' WHERE id = 1; COMMIT;
Thực hiện select lại ở Tx1, kết quả không đổi mặc dù data đã được thay đổi và commit ở Tx2:
SELECT * FROM country WHERE id = 1;
| id | country_name | created |
|---|---|---|
| 1 | Russia | yyyy-mm-dd HH:MM:ss.ssssss |
Vậy repeatable read có ngăn chặn phantom read hay không?
Theo sách giáo khoa thì không, giống như tên gọi của nó, repeatable read chỉ ngăn chặn non-repeatable read. Còn phantom read sẽ để dành cho level tiếp theo là seriablizable xử lý, mức level an toàn nhất.
Với PostgreSQL, repeatable read đủ để xử lý phantom read.
Repeatable read đảm bảo chắc chắn rằng mỗi transaction sẽ nhìn thấy data hoàn toàn ổn định, không có dirty row hay phantom row.
Nó sử dụng kĩ thuật snapshot isolation mà chúng ta hay nghe khá nhiều. Hiểu đơn giản rằng nó là một bản copy của data tại thời điểm bắt đầu transaction. Mọi sự thay đổi trên transaction khác dù được commit nhưng không ảnh hưởng đến snapshot này.
Tuy nhiên, một vấn đề khác sẽ thể xảy ra nếu 2 transaction cùng thực hiện modify data.
Tx1 thực hiện update record có id = 1:
UPDATE country SET country_name = 'Poland' WHERE id = 1;
Kết quả trả về lỗi ngay lập tức:
ERROR: could not serialize access due to concurrent update
SQL state: 40001
Toàn bộ transaction bị hủy bỏ và bạn chỉ có thể rollback and retry, thực hiện lại các business logic đã làm trước đó. Vấn đề này chỉ xảy ra với các updating transaction đồng thời, read-only transaction không bị ảnh hưởng.
4) Serializable
Cuối cùng là level an toàn nhất của transaction isolation. Level này sẽ thực hiện tuần tự nối tiếp cho tất cả các transaction, gần như chẳng có gì có thể diễn ra đồng thời.
Với PostgreSQL, repeatable read đã đảm bảo việc không có phantom row nên về cơ bản seriablizable hoạt động khá giống repeatable read.
Chỉ khác biệt ở chỗ serializable sẽ giám sát các điều kiện khiến cho các transaction có khả năng thực thi đồng thời và ngăn chặn nó để đảm bảo tính tuần tự.
Việc giám sát này không liên quan gì đến locking hay performance, tuy nhiên nó có thể gây tăng overhead và xảy ra những bất thường về việc tuần tự hóa dẫn đến lỗi serialization failure.
Thực hành để hiểu rõ hơn nhé. Init data trước:
TRUNCATE TABLE engineer; INSERT INTO engineer(gender, country_id) VALUES(1, 10);
INSERT INTO engineer(gender, country_id) VALUES(1, 20);
INSERT INTO engineer(gender, country_id) VALUES(2, 100);
INSERT INTO engineer(gender, country_id) VALUES(2, 200); COMMIT;
Begin tracsaction với Tx1:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Sau đó là Tx2:
BEGIN TRANSACTION;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Quay lại Tx1, thực hiện tính tổng country_id với gender = 1 và insert một record mới có gender = 2:
SELECT SUM(country_id) FROM engineer WHERE gender = 1; INSERT INTO engineer(gender, country_id) VALUES(2, 300);
Sang Tx2, tính tổng country_id với gender = 1 và insert record có gender = 1:
SELECT SUM(country_id) FROM engineer WHERE gender = 2; INSERT INTO engineer(gender, country_id) VALUES(1, 30);
Thực hiện commit ở Tx2 trước, sau đó commit ở Tx1 sẽ có lỗi:
ERROR: could not serialize access due to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
HINT: The transaction might succeed if retried.
SQL state: 40001
Trong tình huống trên, chỉ có một transaction được commit, transaction còn lại bị rollback.
Tx1 được thực thi trước Tx2. Do đó expect sum của gender = 2 phải là 600 thay vì 300. Tuy nhiên kết quả trả về là 300 kéo theo các business logic sau đó có thể đã được thực thi. Vì vậy serializable ngăn không cho phép điều đó xảy ra.
Lý do là vì serializable cần đảm bảo tính tuần tự của các operation trong transaction để tránh serialization anomaly.
Có thể thực hiện lại ví dụ trên với repeatable read level. Chúng ta sẽ thấy cả 2 transaction đều commit thành công.
5) Tổng kết
PostgreSQL isolation transaction level sẽ có đôi chút khác biệt so với tiêu chuẩn chung của SQL isolation transaction level nhưng về cơ bản đều đáp ứng đúng, thậm chí có phần chặt chẽ hơn.
SQL isolation levels:
| Level | Dirty read | Non repeatable read | Phantom read |
|---|---|---|---|
| Read uncommitted |  |
|
|
| Read committed |  |
|
|
| Repeatable read | |
|
|
| Serializable | |
|
|
PostgreSQL isolation levels:
| Level | Dirty read | Non repeatable read | Phantom read | Serialization Anomaly |
|---|---|---|---|---|
| Read uncommitted | |
|
|
|
| Read committed | |
|
|
|
| Repeatable read | |
|
|
|
| Serializable | |
|
|
|
Level càng cao mức độ cô lập càng lớn, thực hiện business càng an toàn nhưng kéo theo đó là performance giảm.
Reference
Reference in series https://viblo.asia/s/performance-optimization-voi-postgresql-OVlYq8oal8W
After credit
Đã tròn 3 tháng kể từ ngày mình bắt đầu viết blog với tổng cộng 48 posts và hơn 170 followers. Tuy số lượng chưa nhiều nhưng nó khiến mình cảm thấy những điều chia sẻ phần nào có ích.
Cảm ơn mọi người đã luôn ủng hộ và đồng hành trong khoảng thời gian qua.
Nếu thấy bài viết hay và có giá trị, hãy upvote và follow như một tri ân dành cho mình nhé  .
.
Thanks.
© Dat Bui