Apache Spark là một framework dùng trong xử lý dữ liệu lớn. Nền tảng này trở nên phổ biến rộng rãi do dễ sử dụng và tốc độ xử lý dữ liệu được cải thiện hơn Hadoop. Apache Spark có thể phân phối khối lượng công việc trên một nhóm máy tính trong một cụm để xử lý hiệu quả hơn các tập hợp dữ liệu lớn. Công cụ mã nguồn mở này hỗ trợ nhiều ngôn ngữ lập trìnhnhư là : Java, Scala, Python và R. Trong bài viết này mình sẽ chia sẻ cách để cài đặt và cấu hình Apache Spark trên Ubuntu
Cài đặt các gói cần thiết cho Spark
Trước khi muốn cài đặt Apache Spark thì trên máy tính của bạn phải cài đặt trước các môi trường : Java, Scala, Git. Nếu chưa có, mở terminal của bạn nên và cài đặt tất cả qua câu lệnh sau :
sudo apt install default-jdk scala git -y
Để kiểm tra xem môi trường Java và Scala đã được cài đặt trong máy của bạn chưa thì sử dụng câu lệnh :
java -version; javac -version; scala -version; git --version
Tải xuống và thiết lập Spark cho Ubuntu
Để tải xuống Apache Spark cho Ubuntu, bạn truy cập vào website https://spark.apache.org/downloads.html, sau đó chọn tải về phiên bản phù hợp cho máy tính của bạn.
Copy file nén đó tới bất kì đâu mà bạn muốn đặt Spark, thường các phần mềm được gắn thêm vào sẽ đặt trong thư mục /opt của Ubuntu, tuy nhiên mình thấy đặt ở đâu cũng được miễn là bạn thấy thuận tiện cho bản thân. Giải nén thư mục bằng lệnh sau :
tar xvzf <ten_file_nen_spark>.tgz
Cấu hình môi trường Spark
Trong thư mục Home, mở hiện các thư mục ẩn lên sau đó tìm tới file .profile, thêm vào cuối file dòng sau :
export SPARK_HOME=<duong_dan_toi_thu_muc_ban_vua_dat_spark>
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3
Ví dụ mình cấu hình file .profile của mình như sau ( à quên, vậy là máy bạn cũng phải có python3 nữa nha) :
SPARK_HOME=/media/trannguyenhan01092000/LEARN/spark-3.0.1-bin-hadoop2.7
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
PYSPARK_PYTHON=/usr/bin/python3
Khởi động Spark Standalone
Di chuyển terminal của bạn tới thư mục Sbin trong thư mục Spark của bạn bằng lệnh cd. Chạy lệnh sau để khởi chạy Spark :
./start-master.sh
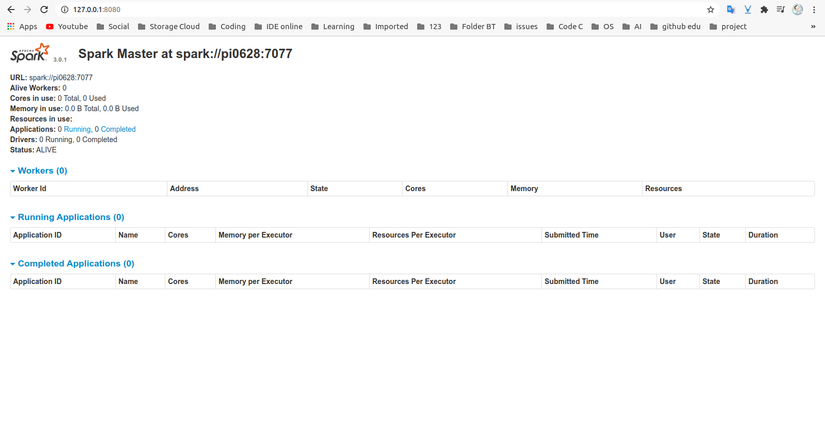
Để xem giao diện người dùng Spark Web, hãy mở trình duyệt web và nhập địa chỉ IP localhost trên cổng 8080 :
http://127.0.0.1:8080/
(Hãy nhớ tắt tất cả các ứng dụng khác có dùng chung cổng với Spark để tránh việc xung đột xảy ra)
Đây là giao diện sau khi khởi chạy thành công ( chờ 1 lúc tầm 10s nha) :
Tham khảo : https://www.tailieubkhn.com/, https://phoenixnap.com/