RLHF là gì?
Reinforcement Learning from Human Feedback (RLHF) là một phương pháp mới, tiên tiến trong lĩnh vực Trí tuệ nhân tạo (AI) được nổi lên với sự thành công vượt bậc của ChatGPT. Tận dụng hướng dẫn của con người (human preferences) để huấn luyện (training) và cải thiện chất lượng của các mô hình ngôn ngữ (Language models) và được các công ty công nghệ lớn ứng dụng mạnh mẽ trong các mô hình ngôn ngữ lớn (Large language models).
Về cốt lõi, RLHF là một mô hình học máy (machine learning) kết hợp với các yếu tố học tăng cường (reinforcement learning) và học có giám sát (supervised learning) để cho phép các hệ thống AI học (learning) và đưa ra quyết định (make decisions) theo cách phù hợp với con người hơn.
Tầm quan trọng của RLHF nằm ở khả năng giải quyết một số thách thức cơ bản trong AI, chẳng hạn như nhu cầu về các mô hình có thể hiểu và tôn trọng các giá trị cũng như sở thích của con người. Không giống như các phương pháp học tăng cường truyền thống, trong đó các mô hình học từ các phần thưởng (rewards) được tạo ra thông qua tương tác với môi trường (enviroment), RLHF đưa ra sử dụng những phản hồi của con người (human feedback) như một nguồn hướng dẫn có giá trị cho mô hình. Những feedback này này có thể giúp các hệ thống AI điều hướng các không gian ra quyết định phức tạp, phù hợp với kỳ vọng của con người và đưa ra những lựa chọn sáng suốt và có đạo đức hơn. RLHF có thể thấy trong nhiều ứng dụng trong nhiều lĩnh vực, từ hệ thống gợi ý (recommend systems), trong xử lý ngôn ngữ tự nhiên (Nature language processing) cho tới trong ro-bot (robotics) và xe tự hành (autonomous vehicles). Bằng cách kết hợp feedback của con người vào quá trình huấn luyện, RLHF có khả năng cải thiện hiệu suất của mô hình, nâng cao trải nghiệm người dùng, và đóng góp vào sự phát triển các công nghệ AI có trách nhiệm, đạo đức.
Tại sao RLHF quan trọng?
Reinforcement Learning from Human Feedback nổi lên như một khái niệm có tầm quan trọng và có sức ảnh hưởng lớn trong lĩnh vực trí tuệ nhân tạo (AI).
1. Human-centered AI: Một trong những nguồn cảm hứng chính của RLHF là tạo ra các hệ thống AI lấy con người làm trung tâm hơn (Human-centered). Các mô hình AI truyền thống thường thiếu khả năng hiểu, quan tâm tới những giá trị hay sở thích, kỳ vọng, mong muốn của con người. RLHF tìm cách thu hẹp khoảng cách này bằng cách kết hợp phản hồi và hướng dẫn của con người vào quá trình đào tạo. Cách tiếp cận này đảm bảo rằng các hệ thống AI phù hợp với giá trị của con người, giúp chúng an toàn hơn, hữu ích hơn trong các ứng dụng thực tế.
2. Giải quyết những vướng mắc trong việc xây dựng Reward: Trong học tăng cường thông thường, việc xác định các hàm tính điểm thưởng (reward functions) mà thể hiện được chính xác hành vi của các tác nhân AI (agents) có thể là một trong những thách thức lớn. RLHF đưa ra một cách tiếp cận khác bằng cách cho phép người dùng cung cấp phản hồi (feedback) về hành động của agent. Feedback do con người cung cấp có thể đóng vai trò là cách trực quan và dễ thích ứng hơn trong việc hướng dẫn AI học (learning), đặc biệt là trong các nhiệm vụ phức tạp và nhiều sắc thái khác nhau.
3. Phát triển AI có đạo đức: Đảm bảo các hệ thống AI hoạt động có đạo đức và không tham gia vào các hành vi độc hại hoặc thiên vị là một mối quan tâm ngày càng tăng trong thực tế khi phát triển các ứng dụng AI lớn. RLHF đưa ra 1 cách thức để cân nhắc về vấn đề đó vào quá trình đào tạo AI. Bằng cách cho con người tham gia phản hồi, RLHF có thể giúp phát hiện, và giảm thiểu những thành kiến, thúc đẩy sự công bằng và giảm các hành vi AI không mong muốn.
4. Tăng trải nghiệm của người dùng: RLHF dẫn đến các hệ thống AI cung cấp trải nghiệm người dùng được cá nhân hóa và thỏa mãn hơn. Bằng cách học hỏi từ những kỳ vọng, sở thích và phản hồi của con người, các hệ thống AI này có thể thích ứng với nhu cầu và sở thích của từng người dùng, nâng cao sự hài lòng và mức độ tương tác của người dùng.
5. Ứng dụng trên nhiều lĩnh vực khác nhau: RLHF có thể ứng dụng trên nhiều lĩnh vực (domains) khác nhau, bao gồm trong xử lý ngôn ngữ tự nhiên (NLP), robot, xe tự hành (autonomous vehicles), chăm sóc sức khỏe, ... Tính linh hoạt của nó khiến nó trở thành công cụ có giá trị để cải thiện khả năng AI trong nhiều ứng dụng.
6. Triển khai AI an toàn và đáng tin cậy: Khi các hệ thống AI ngày càng trở nên phổ biến được tích hợp vào xã hội, việc đảm bảo an toàn và độ tin cậy là điều rất quan trọng. RLHF góp phần phát triển các mô hình AI an toàn hơn, và ít sảy ra các hành vi không lường trước được hay không mong muốn. Nó cho phép các mô hình học từ phản hồi của con người trong thực tế, giảm nguy cơ gây ra những vấn đề thảm họa.
7. Liên tục được nghiên cứu và cải tiến: RLHF là một lĩnh vực đang có xu hướng phát triển nhanh chóng với những nghiên cứu và phát triển liên tục. Tầm quan trọng của nó nằm ở tiềm năng vượt qua ranh giới của những gì AI có thể đạt được, khiến nó trở nên dễ thích ứng, có trách nhiệm hơn và phù hợp hơn với các kỳ vọng của con người.
RLHF hoạt động như thế nào?
Reinforcement Learning from Human Feedback (RLHF) là một quá trình gồm nhiều giai đoạn (multi-stage) tận dụng khả năng dẫn dắt của con người để đào tạo các mô hình AI một cách hiệu quả.
Một số bước cốt lõi như sau:
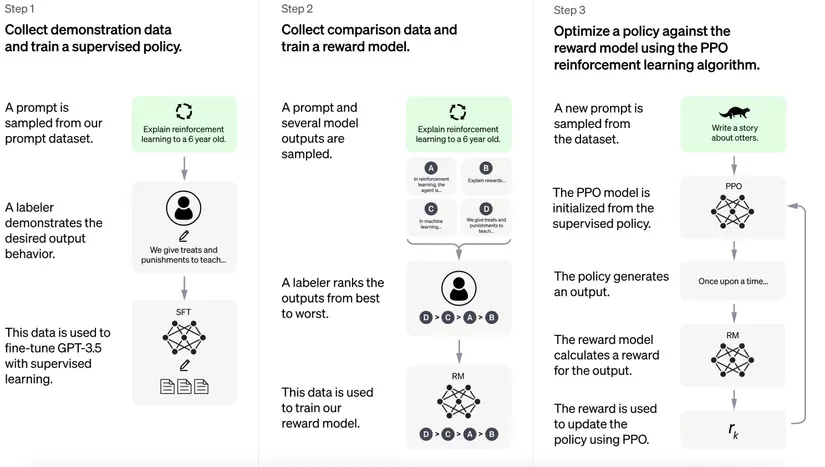
1. Pretraining Language Models
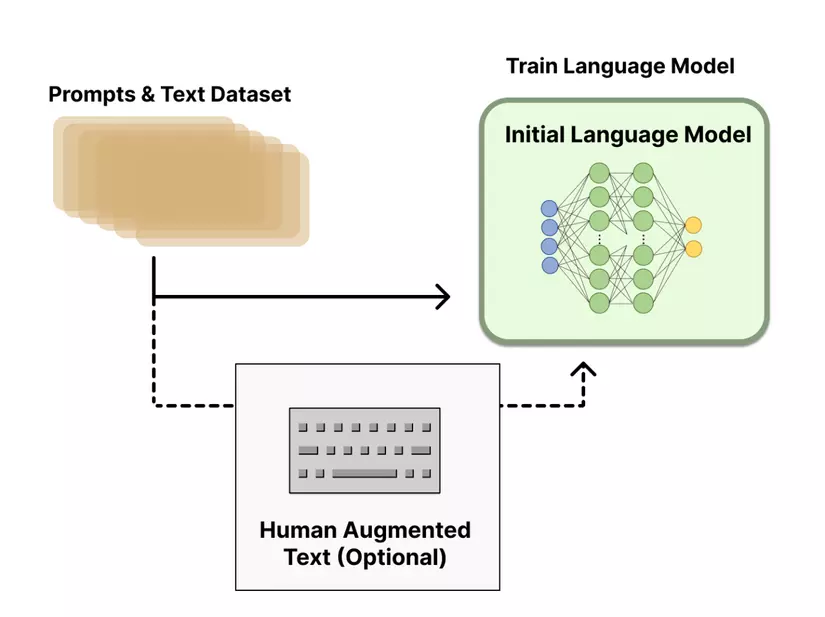
- Bắt đầu với một mô hình ngôn ngữ đã được đào tạo trước, gọi là pre-trained language model bằng các phương pháp huấn luyện mô hình thông thường. Các phương pháp huấn luyện này có thể tìm hiểu sâu từ cách tạo ra các mô hình ngôn ngữ như BERT, Roberta, T5, GPT, ... Mô hình khởi tạo này đóng vai trò là điểm bắt đầu cho RLHF.
- Việc lựa chọn mô hình ngôn ngữ khởi tạo này có thể khác nhau, từ các mô hình nhỏ hơn đến các mô hình có tham số lớn, hay các mô hình hiện đại hiện nay với hàng tỷ tham số, hay từ các kiến trúc khác nhau của mô hình ngôn ngữ.
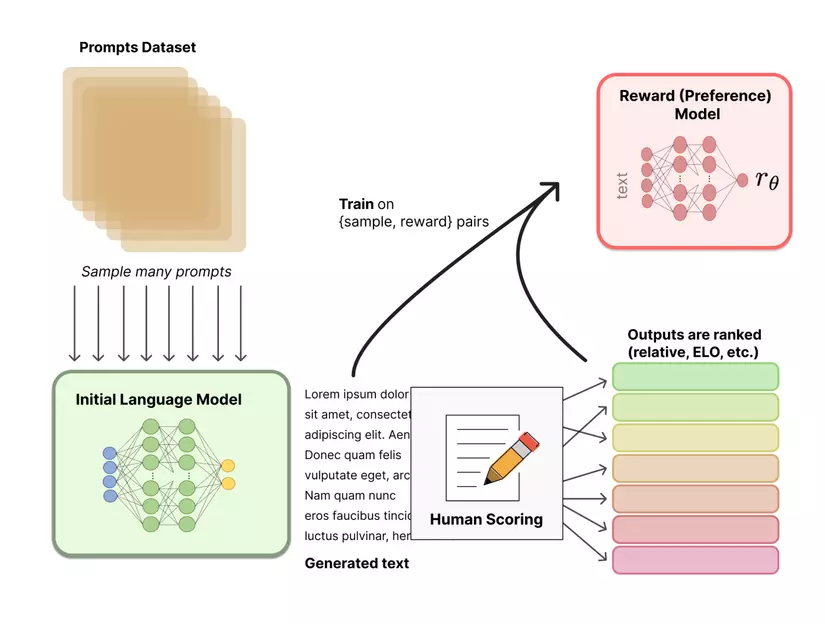
2. Thu thập dữ liệu và huấn luyện Reward model
- Trong RLHF, dữ liệu được tạo để huấn luyện reward model, mô hình này đóng vai trò quan trọng trong việc dẫn dắt hành vi của mô hình AI.
- Một cách tiếp cận để thu thập dữ liệu là thông qua sự tương tác của con người. Người dùng hoặc chuyên gia cung cấp phản hồi (feedback) và đánh giá về hành động của tác nhân AI.
- Ví dụ như trong các nhiệm vụ ngôn ngữ, người dùng có thể xếp hạng các phản hồi khác nhau do AI tạo ra, cho biết phản hồi nào được ưu thích/ tốt hơn.
- Ngoài ra, dữ liệu có thể được thu thập từ các nguồn khác, cung cấp mô hình học được các tác vụ cho các bài toán supervised như phân loại, trích xuất thông tin, ...
- Dữ liệu được thu thập này được sử dụng để đào tạo reward mode , dự đoán mức độ "tốt" hoặc "độ thích hợp" của một hành động AI nhất định dựa trên feedback của con người.
3. Fine-Tuning the Language Model
- Mô hình ngôn ngữ được đào tạo trước (pre-trained language model) được tinh chỉnh (fine-tuning) bằng cách sử dụng các kỹ thuật học tăng cường.
- Trong quá trình tinh chỉnh, mô hình reward model dẫn dắt hành động của mô hình AI. Mô hình tìm cách tối đa hóa reward tích lũy theo dự đoán của reward model.
- Tác nhân AI (agent) thực hiện các hành động trong một môi trường và reward model cung cấp phản hồi về chất lượng của các hành động đó.
- Sau đó, tác nhân sẽ điều chỉnh hành vi của mình để tối ưu hóa các hành động mang lại reward cao hơn, học hỏi một cách hiệu quả từ feedback của con người.
- Fine-tuning thường bao gồm việc chạy nhiều vòng lặp, trong đó tác nhân AI sẽ tinh chỉnh hành vi của nó theo thời gian.
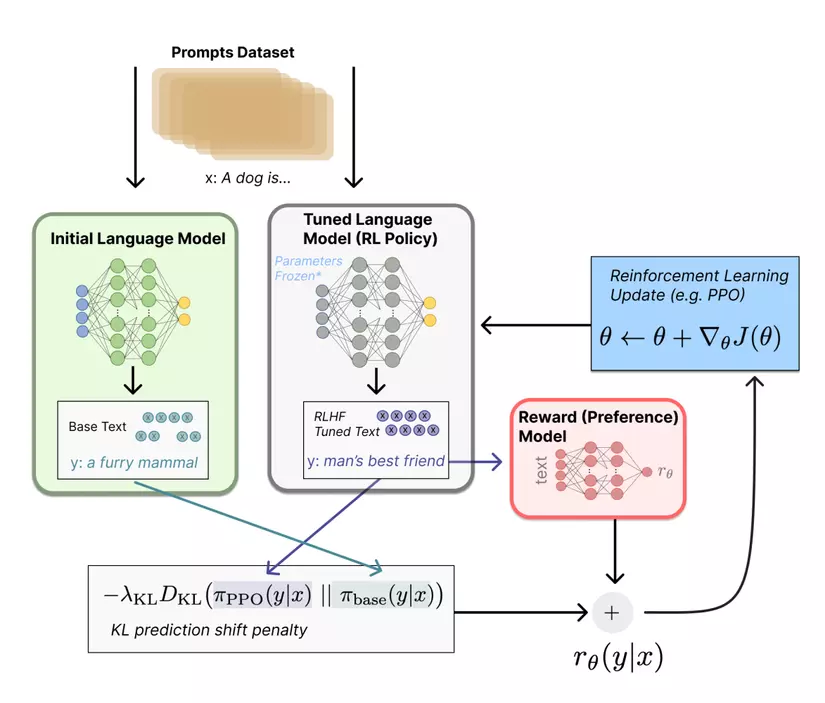
RLHF kết hợp các pre-trained language models với phản hồi (feedback) do con người cung cấp để fine-tuning các mô hình AI một cách hiệu quả. Nó thu hẹp khoảng cách giữa AI và mong muốn của con người, cho phép các hệ thống AI phù hợp và hữu ích hơn. Quá trình học (learning) từ feedback của con người là một quá trình lặp đi lặp lại, thúc đẩy những cải tiến về khả năng của mô hình AI.
Proximal Policy Optimization (PPO) là gì?
Proximal Policy Optimization (PPO) là một thuật toán học tăng cường được sử dụng để đào tạo các mô hình ngôn ngữ lớn và các mô hình học máy khác. Nó được thiết kế để tối ưu hàm policy (trong trường hợp này chính là mô hình ngôn ngữ) nhằm tối đa hóa reward được tích lũy dự kiến của nó trong một môi trường cụ thể. PPO được biết đến là thuật toán với tính ổn định và hiệu quả trong việc huấn luyện các mô hình phức tạp.
Cách PPO hoạt động với mô hình ngôn ngữ:
1. Hàm Policy và Value: PPO gồm 2 thành phần là hàm Policy (thường sử dụng một mạng neuron) và hàm Value. Hàm Policy xác định các hành động hoặc quyết định của mô hình (model) dựa trên dữ liệu vào, trong khi hàm Value ước tính phần thưởng tích lũy dự kiến (expected cumulative reward) khi tuân theo 1 policy cụ thể.
2. Policy Iteration: PPO tuân theo các tiếp cận Policy iteration. Tức là, nó sẽ bắt đầu với khởi tạo 1 policy và lặp đi lặp lại việc tinh chỉnh nhiều lần để cải thiện hiệu suất. Trong mỗi vòng lặp, mô hình thu thập dữ liệu bằng cách tương tác với môi trường. Đối với các mô hình ngôn ngữ, sự tương tác này có thể liên quan đến việc sinh ra text từ prompt đầu vào.
3. Hàm Objective: PPO nằm mục đích tối ưu hóa Policy bằng cách tối đa hóa (maximizing) một hàm Objective. Hàm này kết hợp 2 thuật ngữ chính: surrogate objective và regularization. Surrogage objective đo lường Policy mới hoạt động tốt như thế nào so với Policy cũ bằng cách sử dụng dữ liệu thu thập được trong quá trình lặp hiện tại. Regularization làm hạn chế việc thay đổi quá lớn trong Policy.
4. Clipping: Một trong những tính năng đáng chú ý của PPO là sử dụng tính năng cắt bớt (clipping) để đảm bảo rằng các cập nhật Policy không quá mạnh mẽ, quá lớn. Việc cắt giới hạn cập nhật policy ở một giới hạn nhất định, ngăn chặn những thay đổi lớn của policy có thể dẫn đến mất ổn định trong quá trình đào tạo.
5. Multiple Epochs: PPO thường tiến hành nhiều giai đoạn tối ưu hóa trong mỗi lần lặp. Trong mỗi epoch, nó sử dụng dữ liệu được thu thập để cập nhật policy. Quá trình này lặp lại cho đến khi tìm được policy thỏa mãn.
6. Policy Evaluation: Hàm Value đóng vai trò quan trọng trong việc đánh giá policy. Nó ước tính lợi ích kỳ vọng của việc tuân theo policy hiện tại. Ước tính này giúp đánh giá chất lượng của policy và dẫn dắt việc sàng lọc nó.
7. Độ ổn định và hiệu quả lấy mẫu PPO được ưa chuộng vì tính ổn định và hiệu quả lấy mẫu. Nó có xu hướng cung cấp các bản cập nhật policy mượt mà hơn so với một số thuật toán học tăng cường khác, khiến nó phù hợp với các mô hình ngôn ngữ đào tạo trong đó chất lượng sinh text là rất quan trọng.
PPO có thể được sử dụng cho các nhiệm vụ như sinh văn bản (text generation), hệ thống hội thoại (dialogue systems) và hiểu ngôn ngữ tự nhiên (natural language understanding). Nó giúp tối ưu hóa phản hồi của mô hình và điều chỉnh hành vi của mô hình dựa trên các tín hiệu học tăng cường, giúp mô hình hoạt động hiệu quả hơn trong nhiều ứng dụng liên quan đến ngôn ngữ.
Nhìn chung, PPO là một kỹ thuật học tăng cường có thể được áp dụng để đào tạo các mô hình ngôn ngữ nhằm sinh ra văn bản mạch lạc và phù hợp với ngữ cảnh, làm cho nó có giá trị trong các nhiệm vụ hiểu và xử lý ngôn ngữ tự nhiên.
Direct Preference Optimization (DPO) là gì?
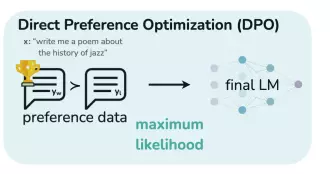
Direct Preference Optimization (DPO) là một phương pháp tiếp cận mới gần đây để tinh chỉnh các mô hình ngôn ngữ lớn (LLM) để phù hợp với mong muốn của con người (Human preferences). Không giống như các phương pháp trước đó liên quan đến học tăng cường phức tạp từ RLHF, DPO đơn giản hóa quy trình hơn. Nó hoạt động bằng cách tạo một tập dữ liệu gồm các cặp sở thích của con người, mỗi cặp chứa một prompt và hai khả năng - một ưu thích (prefered) và một không được ưa thích (dispreferred). Sau đó, LLM được tinh chỉnh để tối đa hóa khả năng sinh ra các đoạn văn bản mà con người ưa thích và giảm thiểu khả năng tạo ra các trường hợp con người không ưa thích.
DPO cung cấp một số lợi thế so với RLHF:
- Tính đơn giản: DPO dễ triển khai và đào tạo hơn, khiến nó dễ tiếp cận hơn.
- Sự ổn định: Ít bị mắc kẹt trong tối ưu cục bộ, đảm bảo quá trình đào tạo đáng tin cậy hơn.
- Efficiency: DPO yêu cầu ít tài nguyên và dữ liệu tính toán hơn so với RLHF, khiến nó nhẹ về mặt tính toán.
- Hiệu quả: Kết quả thử nghiệm cho thấy DPO có thể vượt trội hơn RLHF trong các nhiệm vụ như kiểm soát cảm xúc, tóm tắt và tạo hội thoại.
Các điểm nổi bật chính của DPO bao gồm thuật toán một giai đoạn (one-stage), khả năng thay đổi hyperparameter, hiệu quả và hiệu quả trên các tác vụ xử lý ngôn ngữ tự nhiên khác nhau. Nếu bạn muốn tinh chỉnh LLM để đáp ứng các mong muốn cụ thể của con người, thì DPO sẽ đưa ra một giải pháp thay thế đơn giản và hiệu quả hơn cho RLHF.
DPO vs RLHF
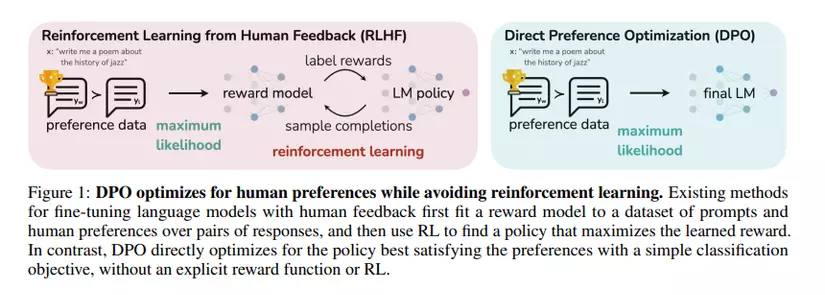
Direct Preference Optimization (DPO) và Reinforcement Learning from Human Feedback (RLHF) là hai phương pháp riêng biệt để tinh chỉnh các mô hình ngôn ngữ lớn (LLM) cho phù hợp với mong muốn của con người.
Methodology
-
DPO: là thuật toán một giai đoạn duy nhất (one-stage) trực tiếp tối ưu LLM để sinh ra response ưu thích của con người. Nó hình thành vấn đề như một nhiệm vụ phân loại bằng cách sử dụng tập dữ liệu gồm các cặp ưu thích (preferences) của con người, trong đó mỗi cặp bao gồm một prompt và hai lần khả năng có thể xảy ra (một ưu tiên, một không được ưu tiên). DPO tối đa hóa xác suất sinh ra các khả năng ưu tiên và giảm thiểu xác suất sinh ra các khả năng không được ưa thích. Nó không cần đến quá trình lặp trong huấn luyện.
-
RLHF: RLHF là một quá trình gồm hai giai đoạn (multi-stage). Đầu tiên, nó tạo ra 1 mô hình reward model để phản ánh mong muốn của con người. Sau đó, nó tinh chỉnh LLM bằng cách sử dụng phương pháp học tăng cường để tối đa hóa reward được ước tính này trong khi vẫn duy trì sự liên kết với mô hình ban đầu. RLHF bao gồm nhiều vòng lặp huấn luyện và có thể tính toán phức tạp.
Complexity
-
DPO: DPO dễ triển khai và huấn luyện hơn so với RLHF. Nó không yêu cầu tạo một mô hình reward model riêng biệt, lấy mẫu từ LLM trong quá trình tinh chỉnh hoặc điều chỉnh hyperparameter.
-
RLHF: RLHF phức tạp hơn và có thể đòi hỏi tính toán cao do quá trình gồm 2 giai đoạn: fitting reward model và fine-tuning.
Stability
-
DPO: DPO ổn định và mạnh mẽ hơn trước những thay đổi hyperparameters. Nó ít có khả năng bị mắc kẹt trong tối ưu cục bộ trong quá trình huấn luyện.
-
RLHF: RLHF có thể nhạy cảm với các lựa chọn hyperparameters và có thể yêu cầu điều chỉnh cẩn thận để tránh mất tính ổn định.
Efficiency (Hiệu suất)
-
DPO: DPO hiệu quả hơn về mặt tính toán và yêu cầu dữ liệu so với RLHF. Nó có thể đạt được kết quả tương tự hoặc tốt hơn với ít nguồn lực hơn.
-
RLHF: RLHF có thể yêu cầu nhiều tài nguyên tính toán hơn và lượng dữ liệu lớn hơn để đạt được kết quả tương tự.
Effectiveness (Hiệu quả)
-
DPO: DPO đã được chứng minh là có hiệu quả trong nhiều nhiệm vụ khác nhau, bao gồm phân tích cảm xúc (sentiment), tóm tắt (summarization) và sinh hộ thoại (dialogue generation). Nó đã vượt trội hơn RLHF trong một số nghiên cứu.
-
RLHF: RLHF cũng có hiệu quả trong việc điều chỉnh LLM phù hợp với mong muốn của con người nhưng có thể yêu cầu thử nghiệm và điều chỉnh sâu rộng hơn.
Tóm lại, DPO cung cấp một giải pháp thay thế đơn giản hơn, ổn định hơn và hiệu quả hơn về mặt tính toán cho RLHF để tinh chỉnh LLM cho phù hợp với mong muốn của con người. Cả hai phương pháp đều có điểm mạnh và có thể được lựa chọn dựa trên yêu cầu cụ thể của dự án và nguồn lực sẵn có.