Giới thiệu chung
Một vấn đề khi sử dụng các model Deep Learning là không phải lúc nào ta cũng có đủ lượng dữ liệu để train. Khi làm việc với các tác vụ Computer Vision, bạn thỉnh thoảng (hoặc thường xuyên  ) gặp vấn đề đó là chỉ có 1-2 mẫu trên một class. Đây là một vấn đề ảnh hưởng rất nhiều tới độ chính xác của model. Với một đứa trẻ, chỉ cần chỉ cho chúng 1 hình ảnh con mèo thì các lần sau đứa bé đều nhận diện ra con mèo một cách dễ dàng. Vậy thì liệu máy móc có thể làm được điều đó hay không? Bài toán học từ ít mẫu dữ liệu này được gọi là Few-shot Learning.
) gặp vấn đề đó là chỉ có 1-2 mẫu trên một class. Đây là một vấn đề ảnh hưởng rất nhiều tới độ chính xác của model. Với một đứa trẻ, chỉ cần chỉ cho chúng 1 hình ảnh con mèo thì các lần sau đứa bé đều nhận diện ra con mèo một cách dễ dàng. Vậy thì liệu máy móc có thể làm được điều đó hay không? Bài toán học từ ít mẫu dữ liệu này được gọi là Few-shot Learning.
Trong những năm gần đây, Few-shot Learning được nhiều sự chú ý từ cộng đồng nghiên cứu, nhiều giải pháp được đề xuất cho bài toán này. Giải pháp phổ biến nhất được sử dụng là Meta-learning. Trong bài viết này chúng ta sẽ tìm hiểu một số kiến thức tổng quát về Few-shot Learning trong Image Classification.
Few-Shot Image Classification task
Đầu tiên, ta cần định nghĩa N-way K-shot image classification task. Cho thông tin ban đầu:
- Support set gồm N nhãn và với mỗi nhãn thì K ảnh được gán nhãn
- Query set gôm Q ảnh truy vấn
Nhiệm vụ là phân loại các ảnh truy vấn vào một trong N nhãn dựa vào N x K ảnh trong Support set. Khi K nhỏ (K < 10), ta có bài toán few-shot image classification (hoặc one-shot trong trường hợp K = 1)
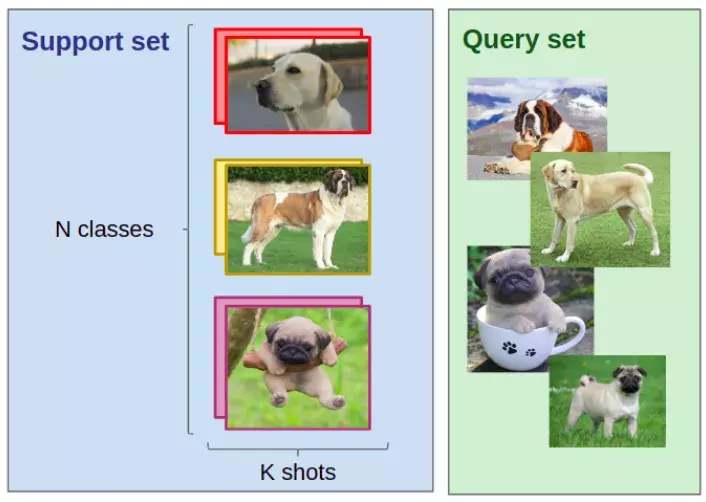
Ví dụ về 1 few-shot classification task: Cho K = 2 và N = 3 trong support set, ta muốn gán nhãn cho Q = 4 chú chó vào 1 trong 3 nhãn Labrador, Saint-Bernard hoặc Pug. Đối với con người, kể cả khi chưa bao giờ nhìn thấy loại chó Pug, Saint-Bernard hoặc Labrador thì việc chọn chúng vào nhãn nào dựa vào một support set cho trước là việc khá dễ dàng. Tuy nhiên để AI có thể giải quyết được, ta sẽ phải cần Meta-learning.
Mô hình Meta-Learning
Nếu ta muốn giải quyết một task , thuật toán meta-learning được train trên các training task . "Kinh nghiệm" mà thuật toán thu được từ những nỗ lực của nó trong việc giải quyết các training task được sử dụng để giải quyết nhiệm vụ cuối cùng .
Ví dụ, ta xét task được mô tả trong hình trước đó. Task yêu cầu gán nhãn cho ảnh với class giống chó là Labrador, Saint-Bernard hoặc Pug dựa vào thông tin từ ảnh đã được gán nhãn trước đó. Một training task (gần tương tự ) có thể là gán nhãn cho ảnh với class giống chó là Boxer, Labradoodle hoặc Rottweiler sử dụng thông tin từ ảnh đã được gán nhãn trước đó. Quá trình Meta-training là sự nối tiếp của các task với các giống chó khác nhau. Cuối cùng ta đánh giá model trên .
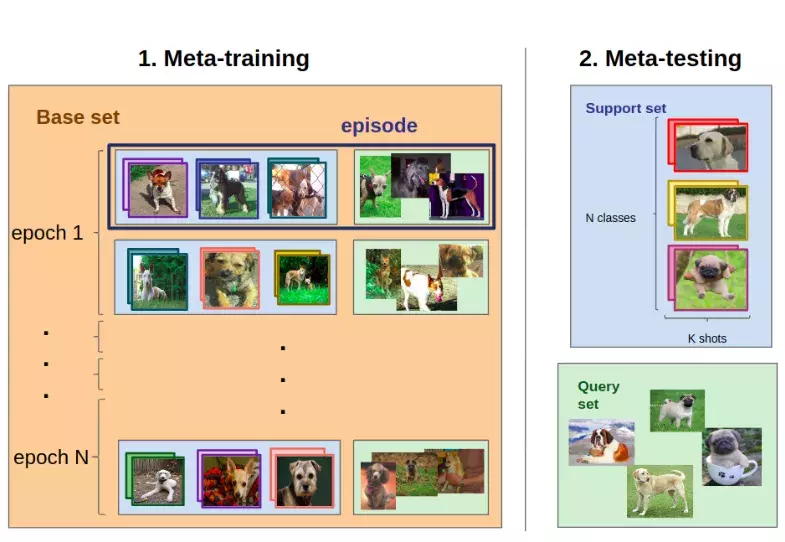
Ta đánh giá meta-learning model trên 3 giống chó Labradors, Saint-Bernards, và Pugs. Tuy nhiên, ta lại train trên các giống chó khác 3 giống chó trên.
Vậy thì cụ thể ta sẽ thực hiện điều này như nào Giả sử ta muốn giải task . Đầu tiên ta cần meta-training dataset gồm nhiều ảnh chó với các giống khác nhau. Ta có thể sử dụng Stanford Dogs Dataset gồm 20.000 ảnh chó được trích xuất từ ImageNet. Ta gọi đó là dataset . Chú ý rằng không cần các giống chó Labrador, Saint-Bernard hoặc Pug.
Từ ta chia thành các episodes. Mỗi episode tương ứng với N-way K-shot classification task . Sau khi model giải quyết được tất cả các episode (tức là model gán nhãn cho tất cả ảnh trong query set), tham số của model được cập nhật.
Bằng cách này, mô hình tìm hiểu giữa các task để giải quyết chính xác một nhiệm vụ mới. Với thuật toán thông thường sẽ học cách mapping ảnh → nhãn, thuật toán meta-learning sẽ học cách mapping support-set → c (.) Trong đó c là một mapping từ query → nhãn.
Thuật toán Meta-Learning
Trong phần này ta sẽ cùng tìm hiểu meta-learning model giải quyết few-shot classification task như nào.
Metric Learning
Ý tưởng cơ bản của metric learning là hàm học khoảng cách giữa các điểm dữ liệu (ví dụ như ảnh). Điều này được chứng minh là rất hữu ích cho việc giải quyết few-shot classification task. Thay vì phải fine-tune trên support set (một vài ảnh được gán nhãn), thuật toán metric learning phân loại ảnh truy vấn bằng cách so sánh chúng với ảnh được gán nhãn.
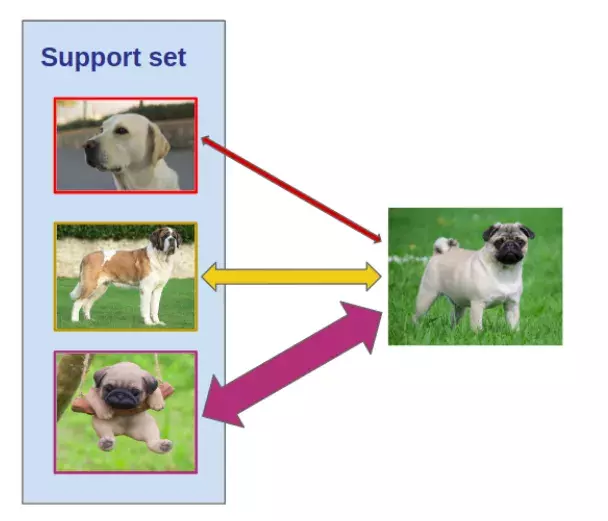
Ảnh truy vấn (bên phải) được so sánh với mỗi ảnh trong support set. Nhãn của ảnh truy vấn phụ thuộc vào việc ảnh nào là có khoảng cách gần nhất.
Tất nhiên, bạn không thể so sánh hình ảnh theo từng pixel, vì vậy ta cần so sánh hình ảnh trong một feature space. Để rõ ràng hơn, ta sẽ xem cách metric learning algorithm giải quyết few-shot classification task:
- Ta trích xuất embedding của tất cả ảnh trong support set và query set (sử dụng CNN). Bây giờ mỗi ảnh mà ta xét trong few-shot classification task được biểu diễn bởi một 1-dim vector.
- Mỗi truy vấn được classify phụ thuộc vào khoảng cách của ảnh truy vấn tới các ảnh trong support set. Có nhiều cách thiết kế cho hàm tính khoảng cách và chiến lược classification. Ta có thể sử dụng khoảng cách Euclidean và k-Nearest Neighbors.
- Trong quá trình meta-training, ở cuối 1 episode, tham số của CNN được cập nhật bằng cách backpropagating dựa trên kết quả loss từ việc phân loại sai trên query set (thường sử dụng cross-entropy loss).
Hai lý do tại sao một số thuật toán metric learning được xuất bản hàng năm để giải quyết few-shot image classification là:
- Thuật toán hoạt động khá tốt
- Có nhiều cách để trích xuất các feature và cũng có nhiều cách để so sánh các feature này. Hãy thử tìm hiểu một vài cách xem nhé
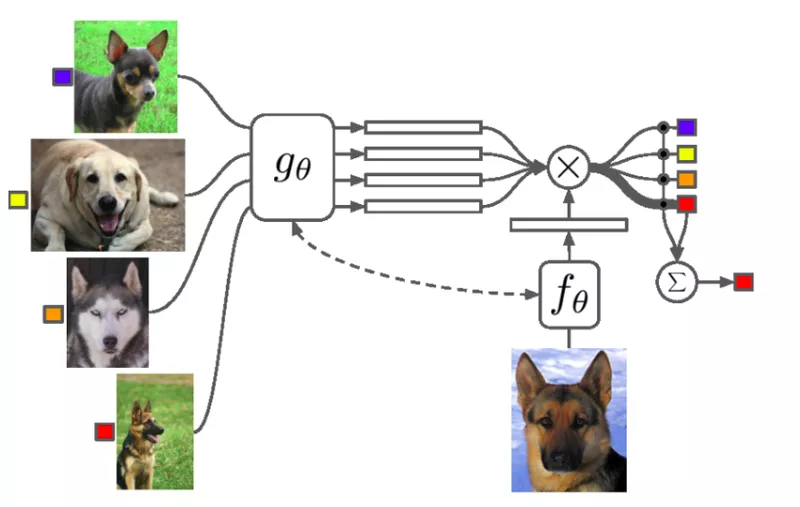
Thuật toán Matching Networks sử dụng 2 Feature extractor khác nhau cho support set và query set. Embedding của query set được so sánh với mọi ảnh trong support set sử dụng cosine similarity. Sau đó chúng được phân loại với 1 hàm softmax.
Matching Networks là thuật toán metric learning đầu tiên sử dụng meta-learning. Trong phương pháp này, ta không trích xuất feature theo một cách giống nhau cho 2 tập support set và query set. Oriol Vinyals và cộng sự có một ý tưởng là sử dụng mạng LSTM để làm cho các ảnh tương tác với nhau trong quá trình trích xuất feature. Họ gọi đó là Full Context Embedding, bởi vì ta cho phép mạng neural tìm cách embedding thích hợp nhất để biết không chỉ ảnh embed mà còn tất cả các hình ảnh khác trong support set. Điều này làm cho mô hình hoạt động tốt hơn so với khi tất cả hình ảnh được truyền qua CNN đơn giản, nhưng nó cũng cần nhiều thời gian hơn và GPU mạnh hơn.
Trong một số nghiên cứu gần đây, ta không so sánh ảnh query với tất cả ảnh trong support set. Thay vào đó, một phương pháp được đề xuất là Prototypical Networks. Trong thuật toán Metric learning này, sau khi feature được trích xuất từ ảnh, ta tính prototype cho mỗi class bằng cách sử dụng trung bình embedding của mọi ảnh trong class. Thật ra có nhiều cách để tính embedding này nhưng function cần đảm bảo khả vi cho backpropagation. Khi prototype được tính, các query được phần loại sử dụng Euclidean distance cho prototype (hình dưới).
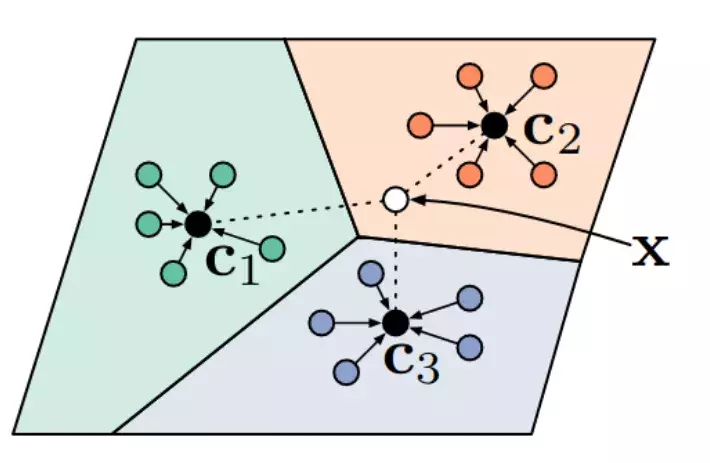
Trong Prototypical Network, ta gán nhãn của query X là nhãn của prototype gần nhất.
Mặc dù đơn giản, Prototypical Networks vẫn đạt kết quả SOTA Có rất nhiều kiến trúc metric-learning phức tạp được phát triển, ví dụ như Learning to Compare: Relation Network for Few-Shot Learning (thay vì khoảng cách Euclidean).
Model-Agnostic Meta-Learning
Trong phần này ta sẽ tìm hiểu một thuật toán meta-learning cơ bản và kinh điển là Model-Agnostic Meta-Learning (MAML). Ý tưởng chính của thuật toán này là train một mạng neural với các tham số có thể thích ứng được nhanh chóng với ít mẫu trong bài toán classification. Hình dưới là mô phỏng cách MAML hoạt động trên 1 episode (là few-shot classification task được lấy mẫu từ ). Giả sử ta có một mạng neural được tham số hóa với 𝚯
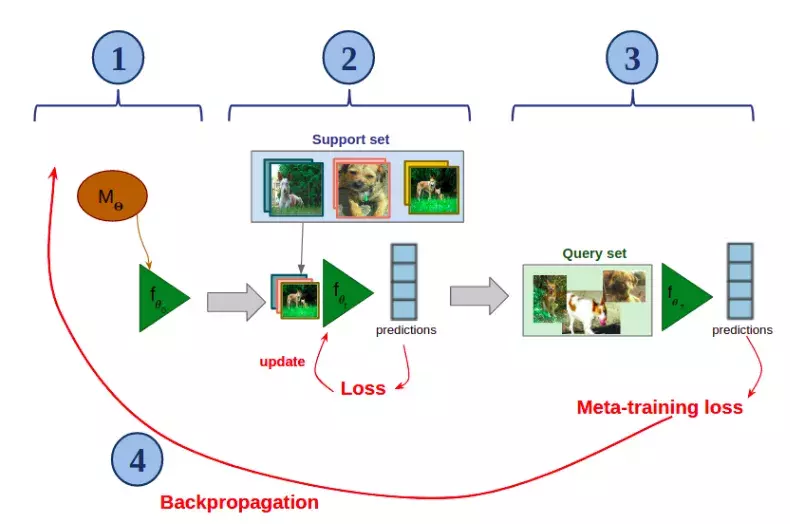
Các bước thực hiện như sau:
- Tạo một bản sao của (tên là f) và khới tạo với tham số 𝚯 (trên hình 𝚯)
- Fine-tune f trên support set (chỉ với ít lần gradient descents)
- Sử dụng f đã fine-tune trên query set
- Backpropagate loss từ classification error qua toàn bộ quá trình và update 𝚯
Sau đó, trong episode tiếp theo, ta tạo một bản sau đã được cập nhật của model và tiếp tục quá trình trên cho few-shot classification task mới. Cứ như vậy cho đến khi hoàn tất
Trong quá trình meta-training, MAML học khởi tạo tham số với mục tiêu cho phép model thích ứng nhanh chóng và hiệu quả với một few-shot task với class mới, chưa được quan sát trước đó.
Công bằng mà nói thì MAML hiện tại không work tốt như các thuật toán metric-learning. Nó khá khó để train bởi vì quá trình train gồm 2 giai đoạn, vì vậy việc tìm hyper-parameter là rất phức tạp. Hơn nữa, meta-backpropagation mang ý nghĩa tính toán "gradient cho gradient", do đó ta phải sử dụng xấp xỉ để có thể train trên GPU tiêu chuẩn. Nhưng lý do làm cho MAML thú vị là Model Agnostic. Nghĩa là nó có thể áp dụng cho bất kì mạng neural nào và bất kì task nào
Implementation
Trong phần này, ta sẽ implement Prototypical Networks. Đây là phương pháp được sử dụng rộng rãi bởi nhiều few-shot learning researchers, lý do là:
- Nó hoạt động tốt
- Dễ cài đặt
Chuẩn bị nguyên liệu
Đầu tiên, ta import một số thư viện cần thiết
!pip install easyfsl import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import Omniglot
from torchvision.models import resnet18
from tqdm import tqdm from easyfsl.data_tools import TaskSampler
from easyfsl.utils import plot_images, sliding_average
Tiếp theo, ta cần một bộ dataset. Trong bài viết này ta sử dụng Omniglot, đây là bộ dữ liệu phổ biến cho benchmark few-shot classification. Bộ dữ liệu bao gồm 1623 ký tự từ 50 bảng chữ cái khác nhau. Mỗi ký tự được viết bởi 20 người khác nhau.
Với torchvision, bạn có thể dễ dàng tải và sử dụng như sau:
image_size = 28 train_set = Omniglot( root="./data", background=True, transform=transforms.Compose( [ transforms.Grayscale(num_output_channels=3), transforms.RandomResizedCrop(image_size), transforms.RandomHorizontalFlip(), transforms.ToTensor(), ] ), download=True,
)
test_set = Omniglot( root="./data", background=False, transform=transforms.Compose( [ transforms.Grayscale(num_output_channels=3), transforms.Resize([ int(image_size * 1.15), int(image_size * 1.15) ]), transforms.CenterCrop(image_size), transforms.ToTensor(), ] ), download=True,
)
Có 2 điều cần chú ý:
- Trong Omniglot,
background = Truechọn tập train vàbackground = Falsechọn tập test - Ảnh trong Omniglot chỉ có 1 kênh, nhưng model của chúng ta muốn 3 kênh màu ảnh, do vậy ta cần biến đổi Grayscale
Code thoai
Đầu tiên, ta định nghĩa class Prototypical Network, ở đây cần chú ý 2 điều sau:
- Khởi tạo PrototypicalNetworks với 1 backbone. Đây chính là feature extractor. Tại đây, ta sử dụng ResNet18 pretrained trên ImageNet, với phần head được thay bằng Flatten layer. Sau đó, output của backbone này là một feature vector 512 chiều
- Đầu vào của foward method là support_images, support_labels và query_images
class PrototypicalNetworks(nn.Module): def __init__(self, backbone: nn.Module): super(PrototypicalNetworks, self).__init__() self.backbone = backbone def forward( self, support_images: torch.Tensor, support_labels: torch.Tensor, query_images: torch.Tensor, ) -> torch.Tensor: """ Predict query labels using labeled support images. """ # Extract the features of support and query images z_support = self.backbone.forward(support_images) z_query = self.backbone.forward(query_images) # Infer the number of classes from the labels of the support set n_way = len(torch.unique(support_labels)) # Prototype i is the mean of all support features vector with label i z_proto = torch.cat( [ z_support[torch.nonzero(support_labels == label)].mean(0) for label in range(n_way) ] ) # Compute the euclidean distance from queries to prototypes dists = torch.cdist(z_query, z_proto) scores = -dists return scores convolutional_network = resnet18(pretrained=True)
convolutional_network.fc = nn.Flatten() model = PrototypicalNetworks(convolutional_network).cuda()
Đánh giá Few-Shot Learning model
Loading few-shot classification tasks với PyTorch
Ta sẽ tạo một dataloader để đưa few-shot classification task vào model. Nhưng một Pytorch dataloader thông thường sẽ đưa vào batch các ảnh và mà không xét nhãn của ảnh cũng như support hay query. Do đó, ta cần 2 chức năng sau:
- Số lượng ảnh được phân phối đồng đều trong các class
- Các ảnh này được chia thành support set và query set
Với chức năng đầu tiên, ta sẽ viết một custom sampler. Đầu tiên, hàm sẽ lấy n_way class từ dataset, sau đó tiếp tục lấy n_shot + n_query ảnh từ mỗi class. Vậy ta có n_way * (n_shot + n_query) ảnh cho mỗi class. Với chức năng thứ hai, ta có custom collate function để thay thể built-in PyTorch collate_fn.
N_WAY = 5 # Number of classes in a task
N_SHOT = 5 # Number of images per class in the support set
N_QUERY = 10 # Number of images per class in the query set
N_EVALUATION_TASKS = 100 test_set.labels = [ instance[1] for instance in test_set._flat_character_images
] test_sampler = TaskSampler( test_set, n_way=N_WAY, n_shot=N_SHOT, n_query=N_QUERY, n_tasks=N_EVALUATION_TASKS,
) test_loader = DataLoader( test_set, batch_sampler=test_sampler, num_workers=12, pin_memory=True, collate_fn=test_sampler.episodic_collate_fn,
)
Đánh giá model
Ta đã tạo một dataloader với 5-way 5-shot task (đây là config phổ biến trong few-shot). Giờ ta thử xem các ảnh trong dataset.
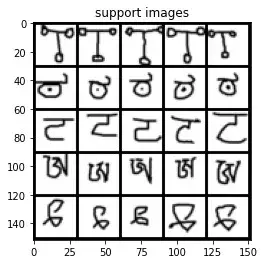
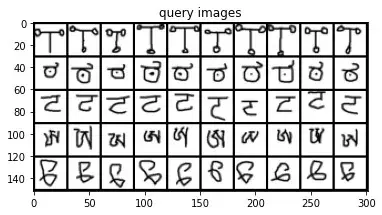
model.eval()
example_scores = model( example_support_images.cuda(), example_support_labels.cuda(), example_query_images.cuda(),
).detach() _, example_predicted_labels = torch.max(example_scores.data, 1) print("Ground Truth / Predicted")
for i in range(len(example_query_labels)): print( f"{test_set._characters[example_class_ids[example_query_labels[i]]]} / {test_set._characters[example_class_ids[example_predicted_labels[i]]]}" )
Kết quả đầu ra cũng không tệ: hãy nhớ rằng mô hình đã được đào tạo trên các hình ảnh rất khác nhau và chỉ có 5 ví dụ cho mỗi lớp
Ground Truth / Predicted
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Angelic/character18 / Atlantean/character11
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Angelic/character18 / Angelic/character18
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Kannada/character23 / Tibetan/character40
Kannada/character23 / Kannada/character23
Kannada/character23 / Kannada/character23
Gurmukhi/character16 / Gurmukhi/character16
Gurmukhi/character16 / Tibetan/character40
Gurmukhi/character16 / Gurmukhi/character16
Gurmukhi/character16 / Atlantean/character11
Gurmukhi/character16 / Tibetan/character40
Gurmukhi/character16 / Gurmukhi/character16
Gurmukhi/character16 / Atlantean/character11
Gurmukhi/character16 / Gurmukhi/character16
Gurmukhi/character16 / Gurmukhi/character16
Gurmukhi/character16 / Gurmukhi/character16
Tibetan/character40 / Tibetan/character40
Tibetan/character40 / Tibetan/character40
Tibetan/character40 / Tibetan/character40
Tibetan/character40 / Kannada/character23
Tibetan/character40 / Atlantean/character11
Tibetan/character40 / Tibetan/character40
Tibetan/character40 / Atlantean/character11
Tibetan/character40 / Tibetan/character40
Tibetan/character40 / Tibetan/character40
Tibetan/character40 / Tibetan/character40
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Atlantean/character11 / Atlantean/character11
Đánh giá trên tập test
def evaluate_on_one_task( support_images: torch.Tensor, support_labels: torch.Tensor, query_images: torch.Tensor, query_labels: torch.Tensor,
) -> [int, int]: """ Returns the number of correct predictions of query labels, and the total number of predictions. """ return ( torch.max( model( support_images.cuda(), support_labels.cuda(), query_images.cuda(), ) .detach() .data, 1, )[1] == query_labels.cuda() ).sum().item(), len(query_labels) def evaluate(data_loader: DataLoader): # We'll count everything and compute the ratio at the end total_predictions = 0 correct_predictions = 0 # eval mode affects the behaviour of some layers (such as batch normalization or dropout) # no_grad() tells torch not to keep in memory the whole computational graph (it's more lightweight this way) model.eval() with torch.no_grad(): for episode_index, ( support_images, support_labels, query_images, query_labels, class_ids, ) in tqdm(enumerate(data_loader), total=len(data_loader)): correct, total = evaluate_on_one_task( support_images, support_labels, query_images, query_labels ) total_predictions += total correct_predictions += correct print( f"Model tested on {len(data_loader)} tasks. Accuracy: {(100 * correct_predictions/total_predictions):.2f}%" ) evaluate(test_loader)
100%|██████████| 100/100 [00:06<00:00, 16.41it/s]
Model tested on 100 tasks. Accuracy: 86.32%
Kết quả là 86.32% cũng khá ổn áp đáy chứ nhỉ
Training meta-learning algorithm
Trong phần này không có valid set để cho ngắn gọn, nhưng đây không phải là good practice. Vì vậy, khi code bạn vẫn nên thêm tập val vào để đánh giá nhé
Chuẩn bị dữ liệu
N_TRAINING_EPISODES = 40000
N_VALIDATION_TASKS = 100 train_set.labels = [ instance[1] for instance in train_set._flat_character_images
] train_sampler = TaskSampler( train_set, n_way=N_WAY, n_shot=N_SHOT, n_query=N_QUERY, n_tasks=N_TRAINING_EPISODES,
)
train_loader = DataLoader( train_set, batch_sampler=train_sampler, num_workers=12, pin_memory=True, collate_fn=train_sampler.episodic_collate_fn,
)
Episodic training
Tại đây ta định nghĩa loss và optimizer và fit method. Method này lấy classification task là input (support set và query set). Hàm thực hiện dự đoán nhãn của query set dựa trên thông tin của support set, sau đó so sánh với nhãn dự đoán với ground truth của query label và tính được giá trị loss. Sau đó, ta sử dụng giá trị loss này để cập nhật tham số cho mô hình. Đây được gọi là meta-training loop.
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) def fit( support_images: torch.Tensor, support_labels: torch.Tensor, query_images: torch.Tensor, query_labels: torch.Tensor,
) -> float: optimizer.zero_grad() classification_scores = model( support_images.cuda(), support_labels.cuda(), query_images.cuda() ) loss = criterion(classification_scores, query_labels.cuda()) loss.backward() optimizer.step() return loss.item()
Đánh giá sự cải thiện
Ta thực hiện đánh giá xem sau khi áp dụng meta-learning thì kết quả có gì cải thiện không
evaluate(test_loader)
100%|██████████| 100/100 [00:06<00:00, 16.08it/s]
Model tested on 100 tasks. Accuracy: 98.38%
Accuracy lên 13%, cũng được đó chứ nhỉ
Kết luận
Vậy là trong bài viết này chúng ta đã tìm hiểu:
- Ý tưởng cơ bản về few-shot learning và các thuật toán liên quan
- Cài đặt và đánh giá mô hình chỉ với vài dòng code
- Cách sử dụng meta-learning để train thuật toán few-shot
Tham khảo
[1] https://proceedings.neurips.cc/paper/2016/hash/90e1357833654983612fb05e3ec9148c-Abstract.html
[2] https://www.sicara.fr/blog-technique/2019-07-30-image-classification-few-shot-meta-learning