Trong thời điểm nhà nước đang thúc đẩy mạnh mẽ quá trình chuyển đổi số như hiện nay, Document Understanding nói chung cũng như Table Extraction nói riêng đang trở thành một trong những lĩnh vực được quan tâm phát triển và chú trọng hàng đầu. Vậy Table Extraction là gì? Document Understanding là cái chi? Hãy đọc tiếp các phần bên dưới để biết thêm thông tin chi tiết!
Nói cao siêu vậy thôi, trong bài viết này, mình sẽ cùng các bạn điểm qua 1 vài điểm đáng chú ý trong 2 lĩnh vực này (thực chất là tập con - tập cha của nhau thôi) để các bạn có thể nắm được tổng quan. Sau đó, chúng ta sẽ đi sâu vào phần code trâu bò, mà cụ thể là code cho table extraction với opencv đã được mình nêu ở tiêu đề bài viết (phần được mong đợi nhất).
Oke, hãy bắt đầu tìm hiểu nội dung bằng một cái Upvote nào 
1. Table Extraction
Trước khi đi vào chủ đề chính của bài viết: Table Extraction, mình muốn trình bày sơ qua 1 chút về một bài toán bao quát hơn: Document Understanding để chúng ta có một cái nhìn toàn diện và rõ ràng hơn về mảng nghiên cứu này.
1.1 Document Understanding
Một cách dễ hiểu, Document Understanding hướng đến việc trích xuất và thu thập dữ liệu từ các tài liệu khác nhau và đảm bảo xử lý tài liệu từ đầu đến cuối.
Để thực hiện điều đó, các giải pháp cần đảm bảo hoạt động với nhiều loại tài liệu khác nhau (từ có cấu trúc đến phi cấu trúc), nhận dạng các đối tượng khác nhau như bảng biểu, chữ viết tay, chữ ký hoặc checkbox cũng như có thể xử lý các định dạng tệp khác nhau (docx, pdf, image, ...).
Như gif minh họa dưới đây (source: NanoNet), một cách chung nhất, các giải pháp cho Document Understanding bao gồm 2 thành phần không thể thiếu: Robotic Process Automation (RPA) và Artificial Intelligence (AI)

Robotic Process Automation (RPA) đề cập đến những công nghệ giúp tự động hóa các tác vụ quản trị thông qua các bot phần mềm và phần cứng. Các bot này tận dụng các giao diện người dùng để nắm bắt dữ liệu và thao tác các ứng dụng như con người vẫn làm, mà không cần đến sự can thiệp trực tiếp của con người. Trong đó, Optical Character Recognition (OCR) là một trong những tính năng quan trọng được tập trung phát triển trong RPA.
Dưới đây là workflow của những công nghệ RPA nói chung. Các bạn có thể đọc 1 bài phân tích chi tiết hơn về RPA cũng như Document Understanding tại blog của NanoNet: A Comprehensive Guide to OCR with RPA and Document Understanding

1.2 Tổng quan Table Extraction
-
Định nghĩa
Table Extraction (TE) is the task of detecting and decomposing table information in a document.
Table Extraction là 1 task con của Document Understanding, mà trong đó, tập trung chính vào nhiệm vụ tự động phát hiện, phân tích và bóc tách các thông tin trong các bảng biểu (nếu có) của tài liệu. Trong bài viết này, mình quan tâm đến các tài liệu scan, hay cụ thể hơn là tài liệu dạng ảnh.

-
Một số thử thách
Như chúng ta đã biết, trong một tài liệu bất kì, bảng biểu (nếu có) luôn bao gồm những thông tin quan trọng về các thông số, số liệu, thống kê, ... được trình bày một cách quy củ và có cấu trúc. Trước khi đi sâu vào việc phân tích tính ứng dụng của trích xuất bảng biểu, chúng ta sẽ điểm qua một số thách thức cần chú ý trong tác vụ này
-
Cấu trúc
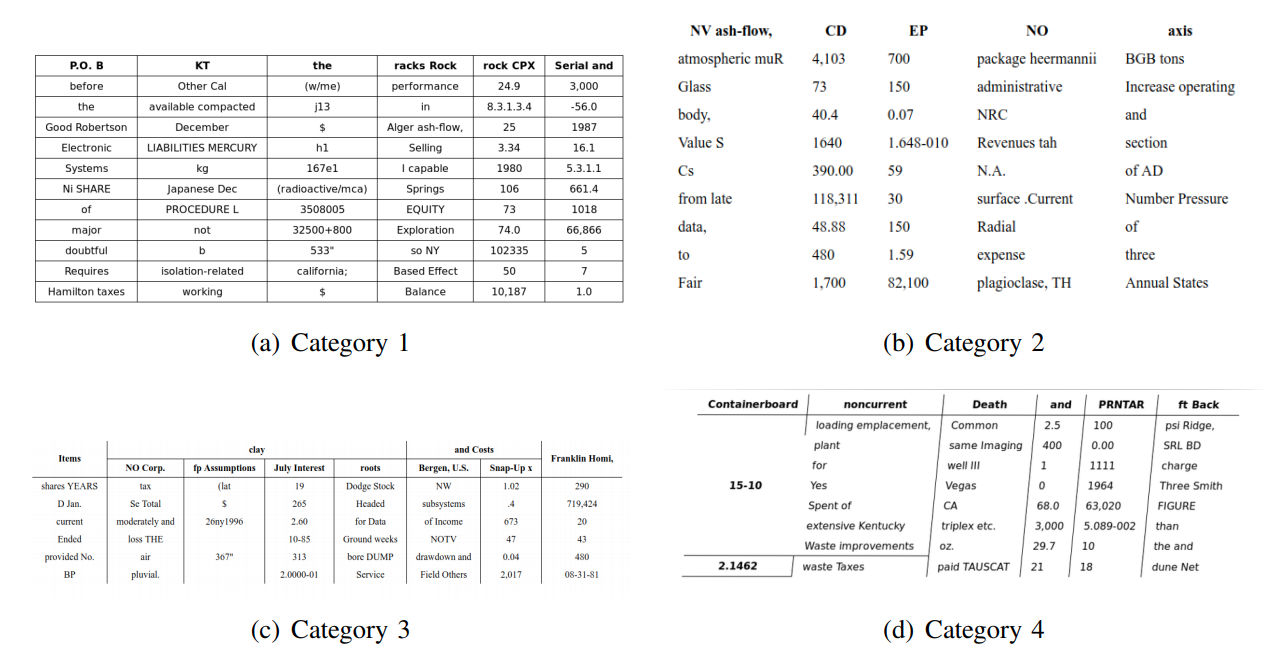
Đầu tiên, hãy nói về tính đa dạng về các thể hiện khác nhau ở bảng biểu. Trong hình trên, mình có chỉ ra 4 dạng chính có thể tồn tại của bảng trong các tài liệu khác nhau.
Dạng 1 là dạng đơn giản và thường gặp nhất, có đầy đủ các đường phân cách hàng cột, không tồn tại các trường hợp merge hàng hoặc merge cột.
Dạng 2 là một dạng khó hơn chút. Mặc dù vẫn không tồn tại trường hợp merging, nhưng các đường phân cách đã bị bỏ đi, thay vào đó là sử dụng các border khác nhau.
Dạng 3 có thể tạm coi như trường hợp khó xử lí nhất, khi mà tồn tại việc merge nhiều hàng cũng như merge nhiều cột, gây ra những nhập nhằng trong việc phân tích và bóc tách.
Dạng 4 cũng gây ra những khó khăn mới trong xử lí khi mà bảng không thẳng hoàn toàn mà đã được transform đi.
-
Chất lượng ảnh
Đây có thể nói là vấn đề chung của tất cả các tác vụ xử lí ảnh thông thường rồi. Đối với các tài liệu, văn bản scan, tùy thuộc vào chất lượng của máy in, máy scan, các hình ảnh thu được có thể tốt hoặc xấu với đa dạng chất lượng.
Trong trường hợp xấu nhất, chúng ta có thể đối mặt với việc xử lí các hình ảnh mờ, độ tương phản thấp, các bảng biểu bị mất nét hoặc tệ hơn thế nữa ...
-
Background
Thông thường, với một tài liệu chứa bảng biểu bất kì, background phổ biến nhất mà chúng ta có thể thấy là chữ đen - nền trắng. Điều này khá thuận lợi cho các tác vụ xử lí ảnh. Tuy nhiên, vẫn tồn tại khả năng tài liệu chứa các background khác nhau, hoặc các watermark được đánh dấu trên tài liệu.
-
Fonts, Format
Đây là một số khó khăn trong việc trích xuất, sau khi đã xác định được vị trí của các cells trong bảng.
Phông chữ thường có nhiều kiểu dáng, màu sắc và độ cao khác nhau. Một số họ phông chữ, đặc biệt là những họ phông chữ thuộc dạng chữ thảo hoặc viết tay, gây ra những khó khăn trong quá trình trích xuất. Do đó, ưu tiên sử dụng phông chữ tốt và định dạng phù hợp sẽ giúp thuật toán xác định thông tin chính xác hơn.
-
-
Ứng dụng
- Mục đích cá nhân (Personal use cases)
- Chuyển đổi văn bản scan (Scanning Documents to Phone)
- Documents to HTML
- Sử dụng trong công nghiệp (Industrial use cases)
- Quản lí chất lượng (Quality Control)
- Theo dõi tài nguyên (Track Of Assets)
- Sử dụng trong thương mại (Business use cases)
- Tự động trích xuất hóa đơn (Invoice Automation)
- Tự động trích xuất biểu mẫu (Form Automation)
- Mục đích cá nhân (Personal use cases)
-
Các hướng tiếp cận chính
- Xử lí ảnh truyền thống (OpenCV) : Dựa trên các đặc trưng về cạnh dọc và cạnh ngang của bảng biểu để tiến hành tính toán, tìm ra các contour chứa các cell của bảng
- Image Segmentation : Sử dụng 1 mạng Encoder-Decoder tương tự như với các tác vụ segmentation thông thường, trích xuất ra mask tương ứng với vị trí của bảng, của hàng cột. Tiêu biểu của hướng xử lí này, có thể kể đến TableNet (TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images)
- Image Detection : Coi bài toán detect table như một vấn đề object detection thông thường. Cụ thể là sử dụng các detector khá phổ biến hiện nay như Faster RCNN, Mask RCNN, ... để phát hiện vị trí của bảng trong tài liệu. (Ví dụ: DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images)
- Graph Neural Network : Dựa vào tính cấu trúc giữa các cell trong bảng, GNN đang là 1 hướng nghiên cứu hứa hẹn và đạt những kết quả cao trong bài toán này: Rethinking Table Recognition using Graph Neural Networks. Để có thể làm quen với những kiến thức mới mẻ về Graph Neural Network này, các bạn có thể ghé qua và nghiên cứu một bài viết có tâm từ tác giả Phan Huy Hoàng tại : [Deep Learning] Graph Neural Network - A literature review and applications
- Others: Ngoài ra, còn rất nhiều các ý tưởng và các cách tiếp cận khác như GAN (Extracting Tables from Documents using Conditional Generative Adversarial Networks and Genetic Algorithms), ... Chi tiết hơn về phần này, các bạn có thể ghé qua blog của NanoNet tại bài viết Table Detection, Information Extraction and Structuring using Deep Learning
2. Table Detection with opencv
2.1 Phạm vi và vấn đề cần giải quyết
-
Phạm vi
Trong phần này, mình sẽ tập trung vào 1 dạng bảng biểu. Cụ thể hơn, là các bảng biểu cần có đường phân cách. Đúng vậy, vì sử dụng opencv, các đặc trưng cạnh là những yếu tố quan trọng nhất quyết định tính chính xác của thuật toán. Do đó, dù bảng có là dạng, merge hàng, merge cột thậm chí là merge cell, miễn đảm bảo có đường phân cách rõ ràng là đủ
-
Hướng giải quyết
Mô tả đơn giản, chúng ta sẽ cố gắng xác định phương trình đường thẳng của các cạnh ngang và cạnh dọc, sau đó, tính toán tọa độ giao điểm của các đường thẳng này để tìm ra tọa độ 4 góc của bảng và cells.
Sau khi xác định được các cell, công việc tiếp theo liên quan đến các bài toán text detection và text recognize với các kí tự trong từng cell.
Để phần trình bày được rõ ràng hơn, mình sẽ lấy một ví dụ mẫu và trình bày lần lượt các bước của thuật toán áp dụng trên ví dụ này. Oke, phần nội dung chính giờ mới thực sự bắt đầu.
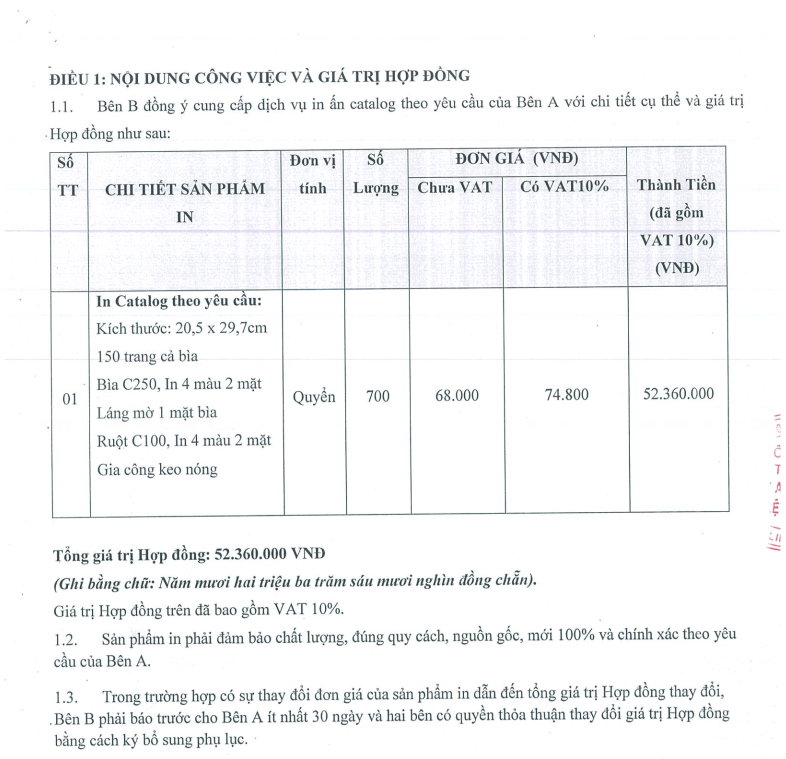
2.2 Tiếp cận dưới góc nhìn của opencv
-
Preprocess
Trước tiên, hãy bắt đầu với những thao tác đầu tiên: Tiền xử lí. Như mình đã trình bày các vấn đề về chất lượng ảnh trước đó, các ảnh đầu vào thường mờ và có độ tương phản thấp. Vì vậy, bước đầu tiên, hãy tăng độ tương phản và làm rõ nét ảnh.
def preprocess(img, factor: int): gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = Image.fromarray(img) enhancer = ImageEnhance.Sharpness(img).enhance(factor) if gray.std() < 30: enhancer = ImageEnhance.Contrast(enhancer).enhance(factor) return np.array(enhancer)
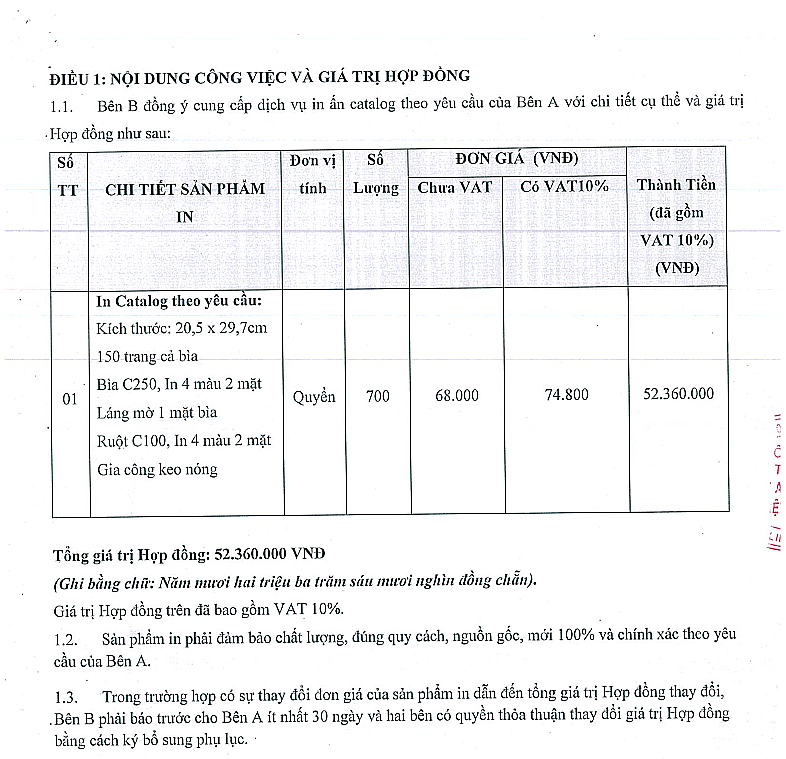
Tiếp đó, đưa ảnh về dạng nhị phân để chuẩn bị cho các bước tiếp theo. Hãy nhớ: ảnh nhị phân (binary image) - không phải ảnh xám (gray image)
gray = cv2.cvtColor(table_image, cv2.COLOR_BGR2GRAY)
thresh, img_bin = cv2.threshold( gray, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
img_bin = 255-img_bin

-
Horizontal lines detection
Tiếp theo, xác định các cạnh hàng ngang bằng một hàm đơn giản cv2.getStructuringElement. Bằng việc erode và dilate các đoạn thẳng này, chúng ta có được những đường cạnh hợp lí hơn.
kernel_len = gray.shape[1]//120
hor_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_len, 1))
image_horizontal = cv2.erode(img_bin, hor_kernel, iterations=3)
horizontal_lines = cv2.dilate(image_horizontal, hor_kernel, iterations=3) h_lines = cv2.HoughLinesP( horizontal_lines, 1, np.pi/180, 30, maxLineGap=250)
Sau khi có những đoạn thẳng chắp vá tạo nên những cạnh hàng ngang, tiến hành nhóm những cạnh này lại thành các cạnh chính, chúng ta sẽ thu được những đường thẳng cạnh cần thiết
def group_h_lines(h_lines, thin_thresh): new_h_lines = [] while len(h_lines) > 0: thresh = sorted(h_lines, key=lambda x: x[0][1])[0][0] lines = [line for line in h_lines if thresh[1] - thin_thresh <= line[0][1] <= thresh[1] + thin_thresh] h_lines = [line for line in h_lines if thresh[1] - thin_thresh > line[0][1] or line[0][1] > thresh[1] + thin_thresh] x = [] for line in lines: x.append(line[0][0]) x.append(line[0][2]) x_min, x_max = min(x) - int(5*thin_thresh), max(x) + int(5*thin_thresh) new_h_lines.append([x_min, thresh[1], x_max, thresh[1]]) return new_h_lines new_horizontal_lines = group_h_lines(h_lines, kernel_len)
-
Vertical lines detection
Tiếp đến là những thao tác tương tự đối với các cạnh hàng dọc. Khác biệt duy nhất ở đây chỉ là kernel được sử dụng ban đầu.
kernel_len = gray.shape[1]//120
ver_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, kernel_len))
image_vertical = cv2.erode(img_bin, ver_kernel, iterations=3)
vertical_lines = cv2.dilate(image_vertical, ver_kernel, iterations=3) v_lines = cv2.HoughLinesP(vertical_lines, 1, np.pi/180, 30, maxLineGap=250)
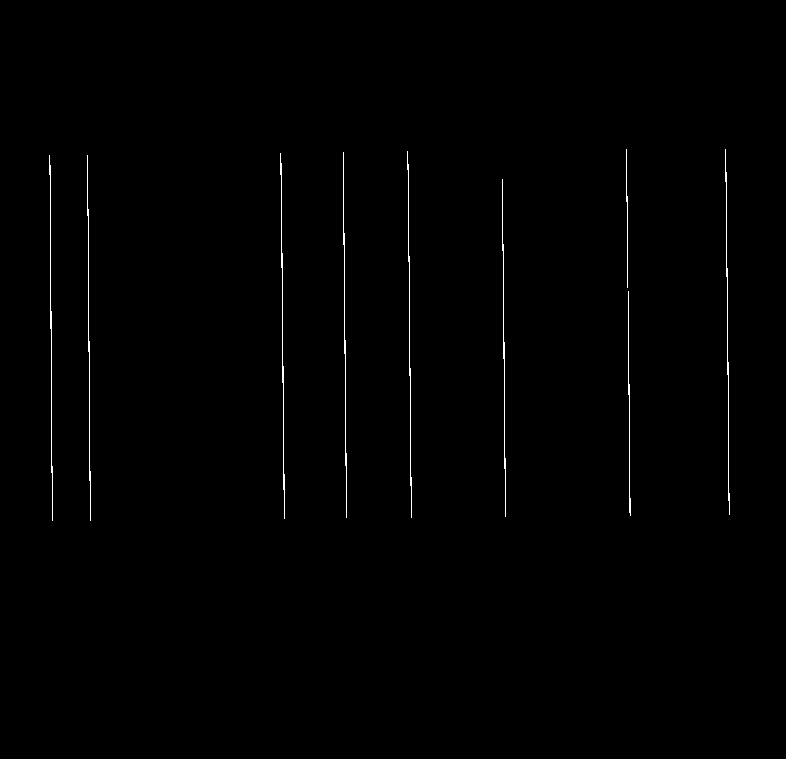
def group_v_lines(v_lines, thin_thresh): new_v_lines = [] while len(v_lines) > 0: thresh = sorted(v_lines, key=lambda x: x[0][0])[0][0] lines = [line for line in v_lines if thresh[0] - thin_thresh <= line[0][0] <= thresh[0] + thin_thresh] v_lines = [line for line in v_lines if thresh[0] - thin_thresh > line[0][0] or line[0][0] > thresh[0] + thin_thresh] y = [] for line in lines: y.append(line[0][1]) y.append(line[0][3]) y_min, y_max = min(y) - int(4*thin_thresh), max(y) + int(4*thin_thresh) new_v_lines.append([thresh[0], y_min, thresh[0], y_max]) return new_v_lines new_vertical_lines = group_v_lines(v_lines, kernel_len)
-
Get intersect point of lines
Oke, sau khi đã có được các hình ảnh và cạnh dọc và cạnh ngang, một hướng tư duy thông thường là sử dụng hàm findContour của opencv để tự động detect cell. Tuy nhiên, mình đã thử và nhận thấy phương pháp này không thực sự đem lại hiểu quả, đặc biệt khi- Ảnh mờ
- Nét cạnh của bảng đứt đoạn hoặc không rõ
- Không bắt được hoàn toàn 100% các cells
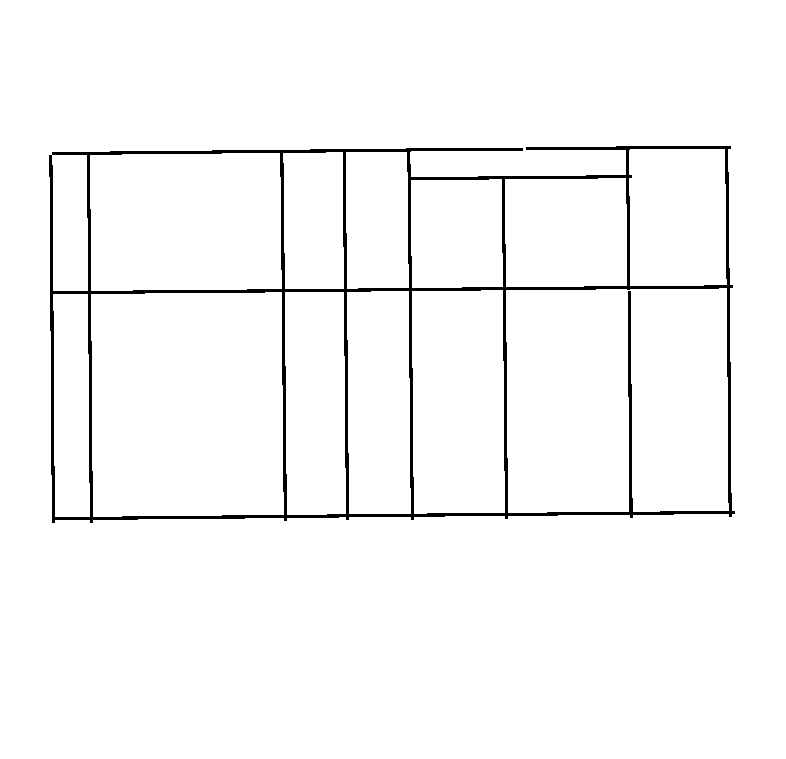
Thay vì sử dụng Contour, trong bài viết này, mình đề xuất một phương án đơn giản, và khả thi hơn bao giờ hết.
Trước tiên, hãy bàn về tính đơn giản, tại sao mình lại bảo nó đơn giản? Thì ở đây, ý tưởng của mình base trên các bài toán giải hệ phương trình 2 ẩn cấp tiểu học. Mà cụ thể hơn là tiến hành xác định giao điểm của những cạnh dọc và cạnh ngang này để đưa ra vị trí (cụ thể là tọa độ 4 góc) của bảng và các cells.
Tiếp theo, tại sao phương án này khả thi ? Bằng việc quan tâm các giá trị đầu cuối nhắm tìm phương trình đường thẳng, phương pháp này có thể tự động fill đầy những chỗ cạnh bị đứt đoạn hoặc quá mờ. Ngoài ra, các cells cũng có thể đảm bảo 99.99% sẽ được bắt đầy đủ, không bỏ sót và được tự động sắp xếp thứ tự từ trên xuống dưới, từ trái qua phải.
def seg_intersect(line1: list, line2: list): a1, a2 = line1 b1, b2 = line2 da = a2-a1 db = b2-b1 dp = a1-b1 def perp(a): b = np.empty_like(a) b[0] = -a[1] b[1] = a[0] return b dap = perp(da) denom = np.dot(dap, db) num = np.dot(dap, dp) return (num / denom.astype(float))*db + b1
-
Results
points = []
for hline in new_horizontal_lines: x1A, y1A, x2A, y2A = hline for vline in new_vertical_lines: x1B, y1B, x2B, y2B = vline line1 = [np.array([x1A, y1A]), np.array([x2A, y2A])] line2 = [np.array([x1B, y1B]), np.array([x2B, y2B])] x, y = seg_intersect(line1, line2) if x1A <= x <= x2A and y1B <= y <= y2B: points.append([int(x), int(y)])
Sau khi đã tính được tất cả các giao điểm của các đường thẳng, chúng ta có 1 list các tọa độ của giao điểm này. Vấn đề tiếp theo là làm sao xác định được 4 điểm nào sẽ tạo thành 1 cell. Ở đây, mình tạm sử dụng 1 logic khá đơn giản : Loang
Cụ thể hơn, với mỗi giao điểm trong list giao điểm, ở đây mình giả định là
- Đầu tiên, mình tiến hành tìm kiếm giao điểm bên phải gần nó nhất và giao điểm bên dưới gần nó nhất . Thao tác này có thể dễ dàng thực hiện do các giao điểm này sẽ cùng tung độ (bên phải) hoặc hoành độ (bên dưới) với giao điểm đang xét, công việc sẽ chỉ là sắp xếp sau đó.
- Tiếp theo, kiếm tra có tồn tại giao điểm của cạnh đi qua giao điểm bên trái và cạnh đi qua giao điểm bên phải hay không? Hiểu đơn giản là kiểm tra có nằm trong list giao điểm hay không.
- Nếu tồn tại, vậy ta xác định được 4 góc của cell, ngược lại, ta bỏ qua và xét giao điểm tiếp theo.
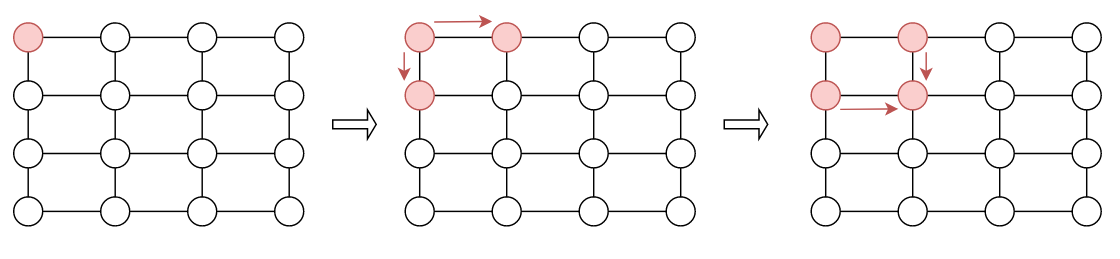 Thuật toán khá đơn giản nhỉ ? Và đừng quên, giả định khiến thuật toán này hoạt động được là bảng cần thẳng
Thuật toán khá đơn giản nhỉ ? Và đừng quên, giả định khiến thuật toán này hoạt động được là bảng cần thẳng
def get_bottom_right(right_points, bottom_points, points): for right in right_points: for bottom in bottom_points: if [right[0], bottom[1]] in points: return right[0], bottom[1] return None, None cells = []
for point in points: left, top = point right_points = sorted( [p for p in points if p[0] > left and p[1] == top], key=lambda x: x[0]) bottom_points = sorted( [p for p in points if p[1] > top and p[0] == left], key=lambda x: x[1]) right, bottom = get_bottom_right( right_points, bottom_points, points) if right and bottom: cv2.rectangle(table_image, (left, top), (right, bottom), (0, 0, 255), 2) cells.append([left, top, right, bottom])
3. What's Up
3.1 Text Detection + Text Recognition
-
CRAFT
Sau khi đã có được vị trí cụ thể của bảng, của các cells, chúng ta sử dụng CRAFT để detect các kí tự trong lần lượt từng cell. Về lí thuyết mạng CRAFT, mình sẽ không đi sâu, ở đây mình lựa chọn do tính đơn giản cũng như pretrained được cũng cấp sẵn của nó (lười mà hehe). Đương nhiên, để đảm bảo tính hợp lí, chúng ta cũng cần hậu xử lí sau CRAFT mà cụ thể ở đây là nhóm các text box trên cùng một hàng thành một.
Phần này mình sẽ lược code đi 1 chút do code để inference CRAFT quá dài. Các bạn có thể tìm đển repo chính của CRAFT để thử nghiệm thêm: https://github.com/clovaai/CRAFT-pytorch
import torch
from craft_structure.detection import detect, get_detector device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
craft = get_detector("models/craft_mlt_25k.pth", device) final_horizontal_list = []
for cell in cells: cell_x_min, cell_y_min, cell_x_max, cell_y_max = cell cell_image = table_image[cell_y_min:cell_y_max, cell_x_min:cell_x_max] horizontal_list, free_list = detect(craft, cell_image, device=device) for box in horizontal_list: x_min = cell_x_min + box[0] x_max = cell_x_min + box[1] y_min = cell_y_min + box[2] y_max = cell_y_min + box[3] cv2.rectangle(table_image, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2) final_horizontal_list.append([x_min, x_max, y_min, y_max])

-
VietOCR
Sau text detection, tác vụ không thể thiếu là text recognize. Ở đây, với tài liệu Tiếng Việt, VietOCR là sự lựa chọn ưu tiên hàng đầu, đương nhiên, sự ưu tiên này cũng đến từ pretrained được cung cấp của VietOCR.
Với lí do tương tự như bên CRAFT, phần này mình sẽ lược code đi 1 chút do code để inference VietOCR quá dài. Các bạn có thể tìm đển repo chính của VietOCR để thử nghiệm thêm: https://github.com/pbcquoc/vietocr (ở đây, mình sử dụng pretrained weights của model seq2seq)
Ngoài ra, bạn cũng có thể tham khảo 1 bài viết khác của tác giả Bùi Quang Mạnh về OCR Tiếng Việt: Nhận dạng tiếng Việt cùng với Transformer OCR
from Predictor import Predictor
from vietocr_structure.vocab import Vocab
from vietocr_structure.load_config import Cfg
from vietocr_structure.ocr_model import VietOCR
from vietocr_structure.ocr_utils import get_image_list def build_model(config): vocab = Vocab(config['vocab']) model = VietOCR(len(vocab), config['backbone'], config['cnn'], config['transformer'], config['seq_modeling']) model = model.to(config['device']) return model, vocab # Load model ocr
config = Cfg.load_config_from_file('config/vgg-seq2seq.yml')
config['predictor']['beamsearch'] = False
model, vocab = build_model(config)
model.load_state_dict(torch.load( 'models/vgg-seq2seq.pth', map_location=config['device']), strict=False) def ocr(img, textline_list, imgH=32): image_list, max_width = get_image_list( textline_list, img, model_height=imgH) coordinate_list = [x[0] for x in image_list] crop_img_list = [x[1] for x in image_list] # load model ocr ocr_model = Predictor(model=model, config=config, vocab=vocab) set_bucket_thresh = config['set_bucket_thresh'] # predict ocr_result = ocr_model.batch_predict(crop_img_list, set_bucket_thresh) final_result = list(zip(coordinate_list, ocr_result)) return final_result table_result = ocr(img=table_image, textline_list=final_horizontal_list)

3.2 Cải tiến + Mở rộng
Dưới đây là một số cải tiến mà mình có thể improve kết quả hơn nữa, các bạn có thể thử áp dụng thêm và so sánh kết quả.
- Cải tiến table detection: Như phần trình bày với ảnh mẫu trên, một số cells và line chúng ta phát hiện được vẫn bị lệch một chút xíu so với các cạnh của bảng ban đầu. Nguyên nhân gây ra vẫn đề này có thể là do ảnh ban đầu bị lệch hoặc nghiêng đi một chút trong quasas trình chụp scan. Để khắc phục, chúng ta hoàn toàn có thể tiền xử lí, xoay ảnh cho thẳng rồi mới đến các bước tiếp theo.
- Cải tiến table extraction: Bên cạnh CRAFT, DB (Differentiable Binarization) cũng là 1 text detector đầy hứa hẹn với tốc độ xử lí nhanh hơn CRAFT mặc dù không có sẵn pretrained. Các bạn cũng hoàn toàn có thể thử train và inference DB với tác vụ này : Real-time Scene Text Detection with Differentiable Binarization
4. Conclusion
Trong bài viết này, mình đã trình bày tổng quan về Document Understanding cũng như Table Extraction. Một phương pháp Table Extraction dựa trên opencv cũng được giới thiệu kèm theo code đầy đủ (dù vẫn chưa đầy đủ hoàn toàn), đồng thời nêu ra những hưởng mở rộng có thể tiếp tục thực hiện trong tương lai. Hi vọng các bạn có hứng thú với chú đề này.
Nếu thấy hay, đừng quên Upvote + Clip + Share nhiệt tình để mình có động lực hoàn thành những bài viết chất lượng hơn nha.
Chúc các bạn một ngày học tập và làm việc hiệu quả. See ya !