Introduction
In my previous post, I described my project, which used AI to generate music automatically. To be more specific, my model used Transformer architecture in conjunction with VAE, taking use of its capacity to produce new data points in the latent space. I go over the model that I decided to use for the project in this article.
Before beginning the development process, two factors need to be taken into account in order to select an appropriate model: the method the model utilizes for learning and the manner in which the data is assessed and processed. Additionally, since one of the project’s objectives is to enable user interaction with a song’s characteristics as it is being generated, I have to select certain frameworks or methods that support that capability. Fortunately, I came across MuseMorphose, a paradigm that allows for human intervention not just during the production process but also introduces techniques for segment-based information retrieval from lengthy sequences.
Musical Representation
Prior to delving more into the model, allow me to briefly discuss REMI, a method that has more features than the original MIDI representation and is more like to how people would read a music sheet.
REMI stands for revamped MIDI. When making music, humans often layer recurring patterns and accents atop a metrical framework described in terms of subbeats, beats, and bars. However, the MIDI-like format may contain implicit versions of the structures that are expressed on score sheets. Therefore, REMI was born to benefit Transformer-based models from the human knowledge of music.
As can be seen from the Figure 1, REMI displays a note quite different from the original MIDI.In contrast to MIDI, which uses a pair of Note-On and Note-Off to display notes and switch on or off relevant notes, REMI uses Note-On, Note-Velocity, and Note-Duration as a set of three characteristics to show notes while they are on. Moreover, additional Tempo and Chord information gives consumers a better understanding of the data and makes the pre-process data section possible. Similar to words in a text, Position and Bar have the same relationship: Position identifies a note value in the corpus, while Bar event signals the beginning of the bar.
MuseMorphose
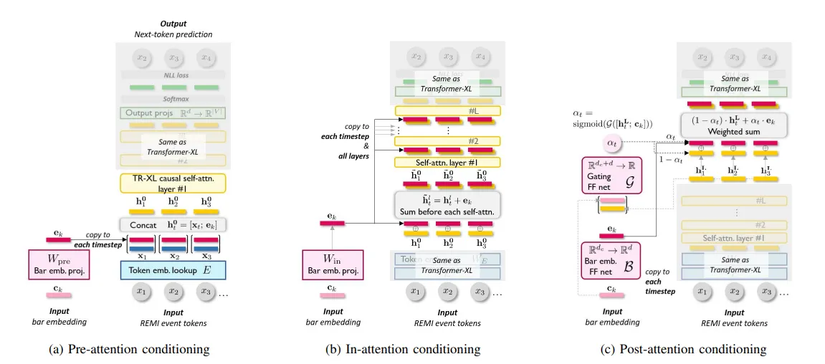
Prior going delving deeper into the architecture, let me briefly discuss the attention techniques MuseMorphose’s authors created, which enable information extraction from a sequence to improve segment-level conditions.
The segment-level conditioned can be understood as follows: given a segment of length K such that it can be subdivided into non-overlapping segments, these small segments are called segments; the conditional segment level occurs when we add conditions to these segments, which can be described by the formula:
Attention mechanisms include:
-
Pre-attention: The segment embeddingsproject the input embedding beforeentering self-attention layers.
-
In-attention: The self-attention layers’space and the segment embeddings’ spaceare both projected. The succeeding layers’input is formed by adding the results tothe self-attention layers.
-
Post-attention: The segment embeddingshave no interaction at all with theself-attention layers in post-attention. They are added on top of the final attention outputs.
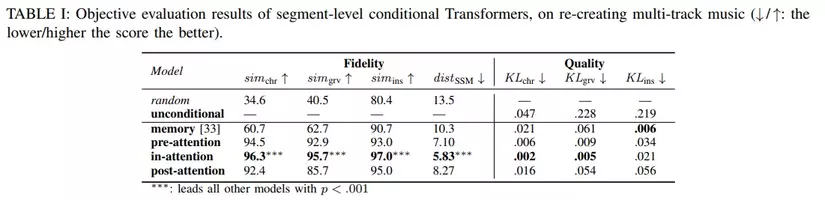
Experimental results show that in-attention achives the best performance.
Combining the in-attention mechanism with the VAE and Transformer design. The MuseMorphose architecture is composed of a KL divergence regularized latent space for the representation of musical bars between a standard Transformer encoder acting at the bar level and a standard Transformer decoder accepting segment-level conditions via the in-attention mechanism.
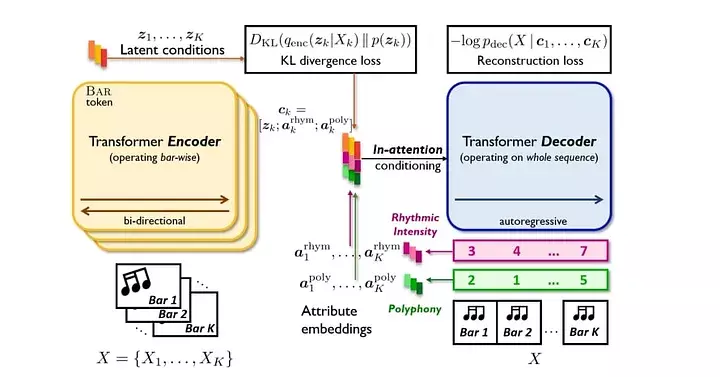
As can be seen from the Figure 5, the input of the encoder is a set of bar X1, X2, …, Xn, which would be fed into the encoder in parallel. Meanwhile, the decoder looks at the entire segment at once. Furthermore, the bar-level a ttributes, are, due to in-attention, converted into embeddingvectors before accessing the decoder. The following are descriptions of the activities occurring inside MuseMorphose:
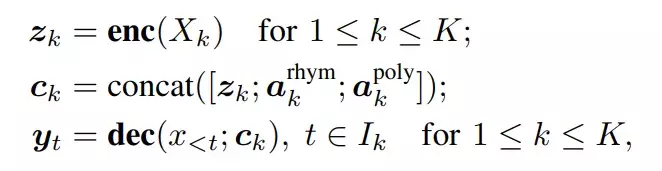
The VAE framework would then be fed by the encoder’s output, and its computation would be sent into the decoder through the in-attention method. In other words, the contextualized representation of the bar is handled as theencoder’s attention output. Then, it is projected using two separate learnable weights, Wµ and Wσ, to the mean and standard deviation (std) vectors.
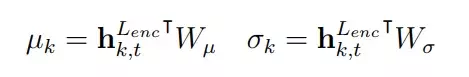
After that, the authors sample the latent condition to be fed to the decoder following the normal distribution.
I frequently brought up the musical attributes, rhythmic intensity and polyphony , those that even individuals without much musical experience may easily understand. Meanwhile, they have a significant role in determining musical emotion. A musical construct known as ”polyphony” consists of two or more separate melodic voices playing simultaneously. ”Rhythm intensity” refers to how strong or weak a beat is perceived to be. It is frequently said to feel ”heavy” or ”light”.
The proposed architecture is trained with the β-VAE-objective and freebits. Its main duty is to reduce the model objective, which described as follow:
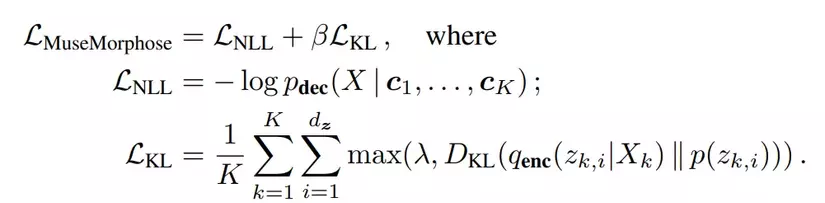
In the following, reconstruction NLL will be used to refer to the first term which is the conditional negative log-likelihood (NLL) for the decoder to create input X given the constraints c1, c2, …, cK. The second factor is the difference between the posterior distributions of zK’s calculated by the encoder and the prior.
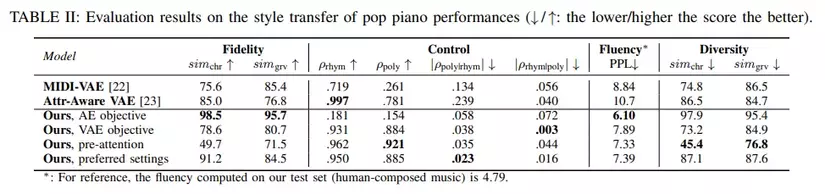
Experiments have shown that, MuseMorphose model, underpinned by Transformers and the in-attention conditioning mechanism, outperforms both baselines and ticks all the boxes in our controllable music generation task — in particular, it accomplishes high fidelity, strong and independent attribute control, good sequence-level fluency, and adequate diversity, all at once.
Conclusion
MuseMorphose uses fine-tuned control elements to achieve great performance in music generating tasks. Based on my own experiences, the authors have described the model as highly comprehensible. Despite the model’s heavy emphasis on piano parts, the generated tunes are enjoyable to listen to.
Thank you for reading this article; I hope it added something to your knowledge bank! Just before you leave:
👉 Be sure to press the like button and follow me. It would be a great motivation for me.