Title: Segment Anything in High Quality
Original Paper: https://arxiv.org/pdf/2306.01567.pdf
Code: https://github.com/SysCV/sam-hq
1. Giới thiệu
Gần đây, Segment Anything Model (SAM) đã đánh dấu một bước ngoặt lớn trong segmentation models. Mặc dù được huấn luyện với 1.1 tỉ mask nhưng mask prediction của SAM vẫn khá tệ trong nhiều trường hợp, đặc biệt là khi xử lý với những object mà có cấu trúc phức tạp. Nhóm tác giả đã giới thiệu HQ-SAM, vẫn giữ nguyên khả năng prompt, tính hiệu quả của SAM tuy nhiên sẽ chính xác hơn. Nhóm tác giả đã đưa ra một High-Quality Output Token đưa vào mask decoder của SAM với mục đích token này sẽ có nhiệm vụ giúp cho việc chất lượng mask dự đoán tốt hơn. Ngoài việc thêm High-Quality Output Token nhóm tác giả còn kết hợp features từ nhiều layer khác nhau để cải thiện độ chính xác của mask. Nhóm tác giả cũng xây dựng một bộ dataset HQSeg-44K bao gồm 44k fine-grained masks từ một vài nguồn khác nhau.
Việc segment một cách chính xác object là nền tảng cho nhiều ứng dụng như chỉnh sửa ảnh/video, robotic perception và Augmented Reality (AR) \ Virtual Reality (VR) nữa.
SAM ra đời đã cho hiệu quả khá ấn tượng, tuy nhiên kết quả segmentation của SAM trong một số trường hợp chưa tốt cụ thể như sau:
- Vùng biên của mask còn chưa mịn, còn thường xuyên bỏ qua những vùng có cấu trúc mỏng
- Dự đoán còn bị sai, mask còn bị vỡ, nhiều lỗi sai ở những trường hợp khó.

2. Methods
2.1 Segment Anything Model (SAM)
SAM bao gồm 3 thành phần:
- Image encoder: backbone kiến trúc VIT để extract image feature, đầu ra của Image Encoder sẽ là embedding có chiều không gian là 64x64
- Prompt Encoder: Encoder thông tin vị trí từ input bao gồm points / boxes / masks để đưa vào mask decoder
- Mask decoder: Là decoder theo kiểu transformer và có 2 layers nhận đầu vào là embedding từ Image Encoder và prompt tokens từ Prompt Encoder để dự đoán mask.
SAM Được huấn huyện trên lượng dữ liệu rất hớn là SA-1B, SA-1B chứa hơn 1 tỉ ảnh. Cũng bởi vậy mà SAM có khả năng dự đoán ảnh bất kì mà không cần train thêm dữ liếu (zero-shot segmentation). Tuy nhiên việc training SAM là vô cùng tốn kém, traing SAM với encoder là ViT-H-based cần tới 256 GPU với batch size là 256.
2.2 HQ-SAM
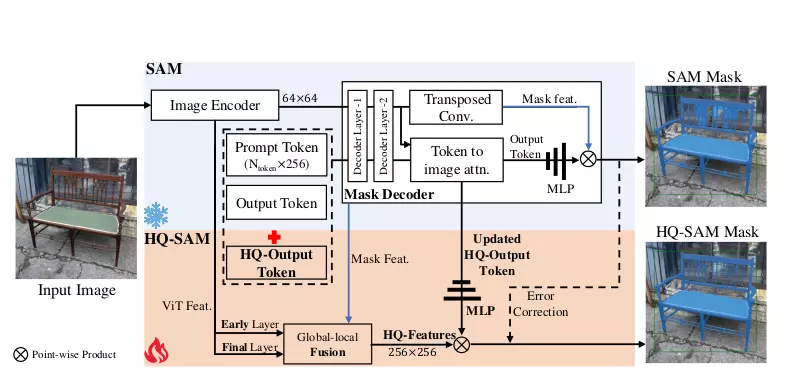
Để giữ nguyên khả năng zero-shot của SAM, Mask Decoder của SAM vẫn được sử dụng tuy nhiên sẽ nhận thêm đầu vào là HQ-Output Token. Lớp MLP mới cũng được thêm voà để thực hiện point-wise product HQ-Output Token với HQ-Features. Trong quá trình training pre-trained SAM được đóng băng và chỉ một phần nhỏ tham số của HQ-SAM được training.
Để cải thiện hiệu nang của SAM trong khi giữ nguyên khả năng zero-shot 2 thành phần chính của HQ-SAM được thêm vào là High-Quality Output Token và Global-local Feature Fusion.
High-Quality Output Token
HQ-Output Token giúp cho việc guide cho mask decoder tạo ra high-quality mask, trong khi Global-local Feature Fussion giúp cho việc lấy thông tin từ nhiều stage khác nhau, điều này giúp cho feature sẽ vừa có ngữ cảnh high-level object (high-level object context) và chi tiết low-level boundary (low-level boundary detail).
Việc thêm vào HQ-Output Token đã làm tăng cả năng predict mask của SAM. Cũng giống như thiết kế ban đầu của SAM, mask decoder cũng sử dụng output token (tương tự như object query trong DETR). Tuy nhiên, tác giả đã thêm vào cả Q-Output token và 1 lớp mask prediction nữa để predict ra high-quality mask.
Global-local Fusion for High-quality Features
Global-local feature fusion cải thiện chất lượng mask bằng việc fuse feature từ nhiều stage khác nhau của Image Encoder. Cụ thể, HQ-SAM fuse feature của layer đầu là features sau khi đi qua global attention đầu tiên của ViT encoder cùng với features của layer cuối cùng ViT encoder giúp feature có cả local và global feature. Feature này cùng với mask feature từ Mask Decoder của SAM sẽ tạo ra HQ-Features (Hình 2).
SAM vs HQ-SAM on Training and Inference
HQ-SAM thêm vào một số lượng tính toán không đáng kể, chỉ tăng ít hơn 0.5% tham số nhưng vẫn đạt được 96% tốc độ ban đầu. SAM-L được huấn luyện trên 128 GPUs A100 với 180k interations. Từ SAM-L, HQ-SAM chỉ cần 8 GPU RTX3090 và training trong vòng 4 giờ.

Trong quá trình training, tham số của pre-train SAM sẽ được fixed chỉ tham số của HQ-SAM được huấn luyện.
3. Thí nghiệm
Từ hình 1 cũng có thể cho ta thấy được sự cải tiến của HQ-SAM so với SAM. Khi ta cho vào prompt như nhau HQ-SAM sẽ đưa ra kết quả chi tiết hơn đặc biệt là với vùng biên. Ở cột bên phải cùng, SAM không thể segment ra được dây diều lướt ván và đưa ra vùng lỗi lớn cùng với những vùng trống ở trong bounding box trong khi HQ-SAM thực hiện khá tốt.
Trong phần Ablation, tác giả thực hiện thí nghiệm trên 4 tập dữ liệu fine-grained segmentation và sử dụng boxes convert từ GT mask làm box prompt.
Ablation trên HQ-Output Token
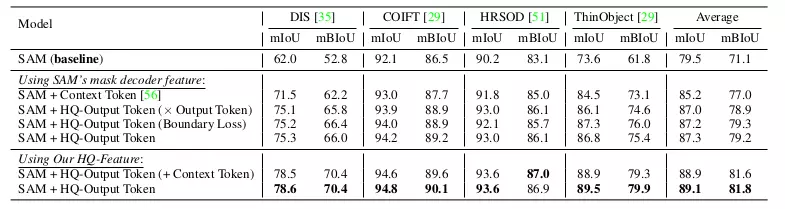
Bảng 2 so sánh HQ-Output Token với baseline SAM và những những chiến thuật học prompt/token khác như sử dụng 3 context tokens là learnable vectors và cho vào mask decoder của SAM để giúp cho SAM học context tốt hơn. Với HQ-Ouput Token tác giả cũng thực hiện một vài ablation như: Thực hiện dot product giữa output token của SAM với HQ-Output Token và chỉ thực hiện tính loss cho vùng boundary.
Ablation trên Global-local Fusion cho HQ-Features
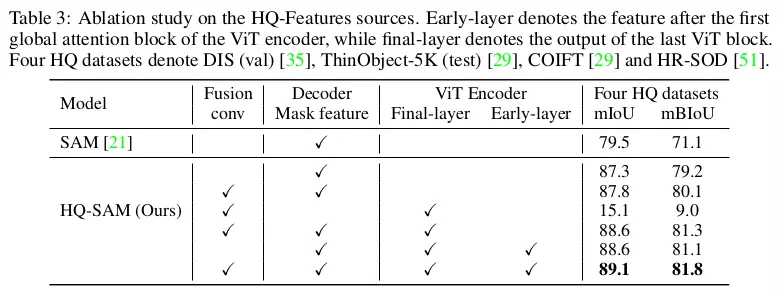 Bảng 3 miêu tả hiệu quả của việc global-local fusion cũng như đâu là thành phần quan trọng khi fuse. So với việc sử dụng trực tiếp Decoder Mask feature của SAM thì việc fuse thêm features đã giúp tăng 2.5 mBIoU trên 4 tập dữ liệu segmentation.
Bảng 3 miêu tả hiệu quả của việc global-local fusion cũng như đâu là thành phần quan trọng khi fuse. So với việc sử dụng trực tiếp Decoder Mask feature của SAM thì việc fuse thêm features đã giúp tăng 2.5 mBIoU trên 4 tập dữ liệu segmentation.
So sánh SAM finetuning và post-refinement
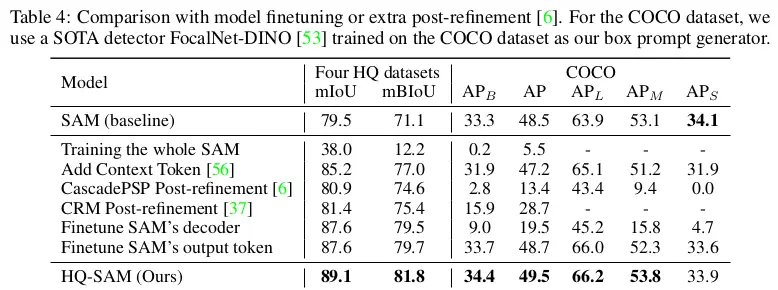
Bảng 4 so sánh HQ-SAM với thêm 1 mạng post-refinemnet và finetuning model bao gồm chỉ finetuning mask decoder hoặc output token.
Phân tích độ chính xác tại các ngưỡng BIoU khác nhau
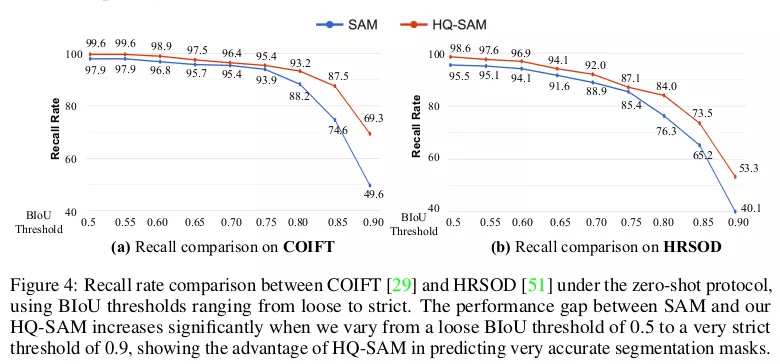
So sánh hiệu quả Zero-shot với SAM
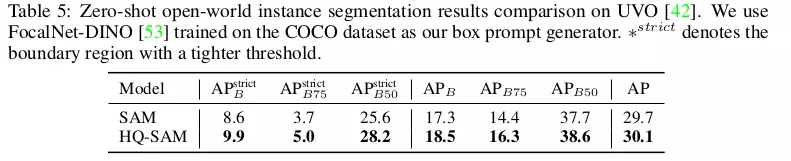 Bảng 5 thực hiện zero-shot instance segmentation bằng việc sử dụng FocalNet-DINO training trên COCO để tạo ra box prompt. Khi sử dụng chung object detector để tạo box prompt HQ-SAM cải thiện khá đáng kể so với SAM.
Bảng 5 thực hiện zero-shot instance segmentation bằng việc sử dụng FocalNet-DINO training trên COCO để tạo ra box prompt. Khi sử dụng chung object detector để tạo box prompt HQ-SAM cải thiện khá đáng kể so với SAM.
So sánh hiệu quả Zero-Shot Segmentation trên tập dữ liệu có độ phân giải cao BIG Dataset
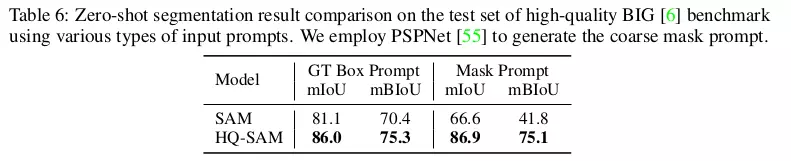 Tác giả sử dụng 2 loại prompt khác nhau là GT object boxes và coarse mask. HQ-SAM cũng hiệu quả hơn khá nhiều so với SAM, đặc biệt với mask prompt (generate bởi PSPNet).
Tác giả sử dụng 2 loại prompt khác nhau là GT object boxes và coarse mask. HQ-SAM cũng hiệu quả hơn khá nhiều so với SAM, đặc biệt với mask prompt (generate bởi PSPNet).
So sánh Point-based Interactive Segmentation
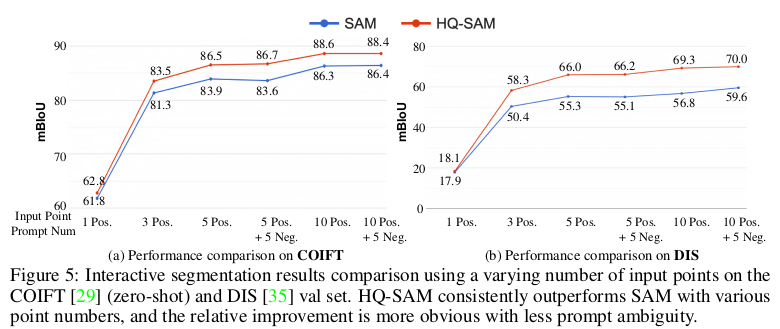
Hình 4 so sánh hiệu năng interative segmentation với số lượng point khác nhau trên 2 tập dataset là COIFT và DIS. Thí nghiệm cũng cho thấy rằng là khi ta sử dụng càng nhiều point prompt thì performance càng tăng.
4. Kết luận
Như vậy nhóm tác giả đã đưa ra một phiên bản cải tiến của SAM là HQ-SAM, HQ-SAM đã cải thiện đáng kể so với SAM. HQ-SAM cũng cần số lượng dữ liệu ít hơn SAM (chỉ 44k sample thay vì 1 tỉ sample). thí nghiệm ta có thể thấy cải thiện phần lớn đến từ High-quality Output Token. Hiệu năng cũng được chứng minh trên 8 tập benchmarks bao gồm cả dữ liệu ảnh lẫn video, cover nhiều loại object và ngữ cảnh khác nhau.
5. Tham khảo
- Segment Anything Model (SAM): arXiv link
- Segment Anything in High Quality:https://arxiv.org/abs/2306.01567