Đóng góp của bài báo
Bài báo đề xuất kiến trúc High-Resolution Net (HRNet) là một kiến trúc mạng nơ-ron sâu được phát triển cho các ứng dụng trong lĩnh vực thị giác máy tính, đặc biệt là trong bài toán object recognition và semantic segmentation. HRNet xuất phát từ việc nhận thấy rằng các mạng nơ-ron sâu truyền thống thường có sự mất mát thông tin không gian và độ phân giải khi tiến hành một loạt các phép tích chập để trích xuất đặc trưng từ hình ảnh.

HRNet giải quyết vấn đề này bằng cách thiết kế mạng sao cho thông tin không gian và độ phân giải được duy trì ở nhiều lớp khác nhau của mạng. Thay vì sử dụng một mạng nơ-ron sâu với nhiều lớp tích chập, HRNet xây dựng một mạng với các nhánh song song, mỗi nhánh xử lý độ phân giải khác nhau và sau đó kết hợp thông tin từ các nhánh này để có kết quả cuối cùng. Điều này giúp HRNet duy trì thông tin chi tiết ở nhiều mức độ độ phân giải khác nhau, từ đó cải thiện khả năng nhận diện và phân đoạn các chi tiết nhỏ trong hình ảnh.
HRNet đã đạt được kết quả ấn tượng trong nhiều nhiệm vụ thị giác máy tính, bao gồm Object recognition, Semantic segmentation và Human pose estimation. Mô hình đã trở thành một trong những kiến trúc quan trọng trong lĩnh vực thị giác máy tính và đã được ứng dụng rộng rãi trong nhiều ứng dụng thực tế như nhận diện khuôn mặt, xe tự hành, phát hiện các vật thể trong hình ảnh và video,...
Mặc dù HRNet có thể có nhiều biến thể và cải tiến nhưng ý tưởng chính về duy trì thông tin không gian và độ phân giải ở nhiều mức độ khác nhau đã giúp mô hình đạt được hiệu suất ấn tượng trong các ứng dụng thị giác máy tính.
High-resolution network
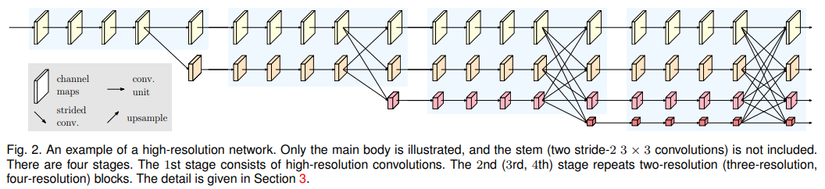
Stem là phần đầu tiên của mô hình HRNet. Nó chứa hai lớp conv 3x3 với stride bằng 2 và có nhiệm vụ nhận ảnh đầu vào. Các lớp conv này giúp giảm độ phân giải của ảnh xuống còn 1/4 so với ảnh gốc. Điều này đồng nghĩa với việc giảm kích thước của ảnh xuống 1/4 so với ban đầu. Các phần còn lại trong main body của mô hình HRNet là: Parallel multi-resolution convolutions, repeated multi resolution fusions và representation head.
Parallel Multi-Resolution Convolutions
Như tên gọi, mô hình HRNet bao gồm các luồng conv với nhiều độ phân giải và chạy song song với nhau (xem hình dưới). Bắt đầu với conv ở độ phân giải cao ban đầu, ta dần dần thêm các luồng conv mới có độ phân giải thấp hơn một cách tuần tự, từ đó tạo ra các stage mới. Mỗi stage bao gồm một luồng conv với độ phân giải thấp hơn so với stage trước đó. Do đó, độ phân giải cho các luồng conv song song ở giai đoạn sau bao gồm độ phân giải từ stage trước đó cùng với một độ phân giải thấp hơn nữa.
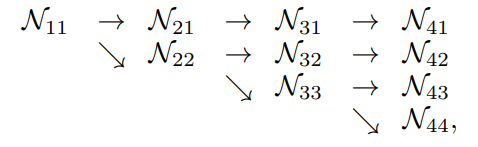
Như hình trên, ta có là một luồng đơn tại stage và là resolution index. Resolution index của luồng đầu tiên là . Độ phân giải của index bằng độ phân giải của luồng đầu tiên.
Cách thiết kế này giúp mô hình duy trì thông tin chi tiết từ các độ phân giải khác nhau 
Repeated Multi-Resolution Fusions
Mục tiêu của module fusion là trao đổi thông tin giữa các biểu diễn với độ phân khác nhau. Module này được lặp lại sau một số bước (thường là sau 4 residual unit, xem hình kiến trúc tổng quan để hiểu rõ hơn ).
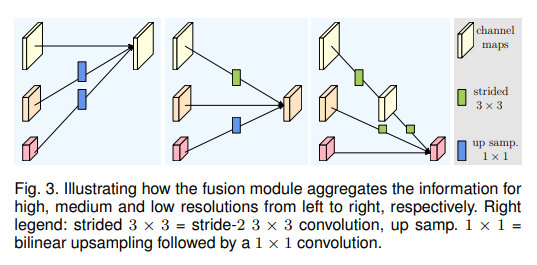
Cụ thể, nhiệm vụ của module fusion là liên kết thông tin từ các biểu diễn đa độ phân giải (xem hình trên). Điều này quan trọng để cải thiện khả năng nhận diện và xử lý hình ảnh ở nhiều mức độ chi tiết. Trong hình trên, bài báo minh họa việc liên kết thông tin từ 3 biểu diễn (tất nhiên việc liên kết 2 hay 4 biểu diễn là hoàn toàn tương tự).
Đầu vào của module fusion bao gồm ba biểu diễn: , trong đó là chỉ số độ phân giải, và các biểu diễn đầu ra liên quan là . Mỗi biểu diễn đầu ra là tổng của các biểu diễn đầu vào đã được biến đổi thông qua một số hàm biến đổi , và . Cụ thể, .
Hàm biến đổi phụ thuộc vào chỉ số độ phân giải đầu vào và chỉ số độ phân giải đầu ra . Nếu , . Nếu , thực hiện việc giảm độ phân giải của biểu diễn đầu vào thông qua các lớp conv 3x3 với bước nhảy (stride) là 2. Nếu , thực hiện việc tăng độ phân giải của biểu diễn đầu vào thông qua việc upsampling theo phương pháp bilinear upsampling, sau đó thực hiện một lớp conv 1x1 để cân bằng số lượng kênh.
Representation Head
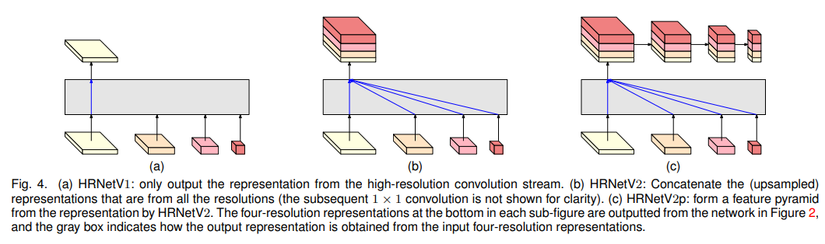
Có 3 loại representation head được minh họa trong hình trên, có tên lần lượt là HRNetV1, HRNetV2 và HRNetV1p.
HRNetV1: Trong HRNetV1, đầu ra biểu diễn chỉ bao gồm thông tin từ luồng comv ở độ phân giải cao nhất (high-resolution stream). Các đầu ra biểu diễn từ các luồng conv ở các độ phân giải thấp hơn bị bỏ qua và không được sử dụng. Điều này đảm bảo rằng mô hình chỉ tập trung vào thông tin ở độ phân giải cao nhất và không quan tâm đến các mức độ độ phân giải thấp hơn.
HRNetV2: Trong HRNetV2, các đầu ra biểu diễn ở độ phân giải thấp được rescale độ phân giải thông qua phương pháp bilinear upsampling mà không thay đổi số lượng kênh, sau đó chúng được concat lại với đầu ra biểu diễn ở độ phân giải cao nhất. Sau đó, một lớp conv 1x1 được sử dụng để kết hợp bốn đầu ra biểu diễn này lại với nhau.
HRNetV2p: Trong HRNetV2p, đầu ra biểu diễn ở độ phân giải cao nhất từ HRNetV2 được giảm độ phân giải xuống thành nhiều mức độ khác nhau (downsampling). Điều này tạo ra các biểu diễn đa mức (multi-level representations).
Trong bài báo, nhóm tác giả sử dụng ba loại đầu ra biểu diễn này để thực hiện ba nhiệm vụ khác nhau, mục tiêu là chọn loại đầu ra biểu diễn phù hợp cho từng tác vụ cụ thể, để mô hình có thể tối ưu hóa hiệu suất trong mỗi nhiệm vụ:
- HRNetV1 được áp dụng cho ước tính vị trí cơ thể người (human pose estimation).
- HRNetV2 được sử dụng cho phân đoạn ngữ nghĩa (semantic segmentation).
- HRNetV2p được áp dụng cho phát hiện đối tượng (object detection).
Instantiation
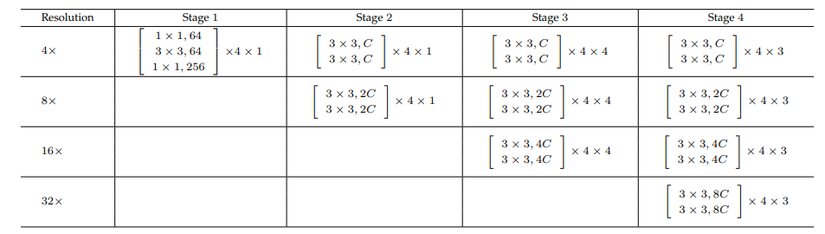
Main body của HRNet bao gồm bốn stage và mỗi stage này chứa 4 luồng conv song song. Mỗi stage của main body xử lý thông tin ở các độ phân giải khác nhau, lần lượt là 1/4, 1/8, 1/16 và 1/32 so với độ phân giải ban đầu.
Stage đầu tiên chứa bốn đơn vị residual (residual units). Mỗi đơn vị được hình thành bởi một "bottleneck" với độ rộng (width) là 64 và sau đó là một lớp conv 3x3, dùng để thay đổi độ rộng của các feature map thành giá trị . Các giai đoạn thứ hai, thứ ba và thứ tư lần lượt chứa 1, 4, 3 khối modularized (modularized blocks). Mỗi khối này có nhiệm vụ xử lý thông tin ở độ phân giải và độ rộng khác nhau. Mỗi nhánh trong luồng conv đa độ phân giải song song của khối modularized chứa 4 đơn vị residual. Mỗi đơn vị residual bao gồm hai lớp conv 3x3 cho mỗi độ phân giải, và sau mỗi lớp conv là lớp chuẩn hóa batch normalization và hàm kích hoạt phi tuyến tính ReLU. Độ rộng (số kênh) của các lớp conv ở 4 độ phân giải khác nhau lần lượt là , , và . Điều này cho biết rằng mỗi độ phân giải có số kênh khác nhau để biểu diễn đặc trưng ở các mức độ khác nhau của hình ảnh.
Phân tích
Trong phần này, nhóm tác giả tập trung phân tích hai thành phần chính của khối modularized trong mạng HRNet: Multi-resolution parallel convolutions và multi-resolution fusion.
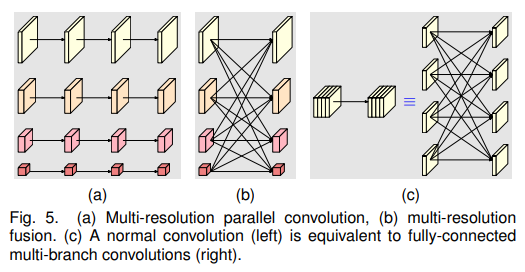
Multi-Resolution Parallel Convolutions (hình a) tương tự như group convolution. Tuy nhiên, khác biệt ở chỗ, trong Multi-Resolution Parallel Convolution, các kênh đầu vào được chia thành nhiều tập con (subsets) và sau đó thực hiện convolution thông thường trên mỗi tập con riêng biệt ở các độ phân giải không giống nhau. Trong group convolution thì các độ phân giải giữ nguyên. Thiết kế Multi-Resolution Parallel Convolution bao gồm một số ưu điểm có trong group convolution.
Multi-Resolution Fusion Unit (hình b, c) tương tự như cách một lớp conv thông thường có thể được chia thành nhiều lớp conv nhỏ (small convolutions). Trong đó, các kênh đầu vào được chia thành nhiều tập con, và các kênh đầu ra cũng được chia thành nhiều tập con. Các tập con đầu vào và đầu ra được kết nối với nhau (giống fully connected) và mỗi kết nối là một lớp tích chập thông thường. Mỗi tập con của kênh đầu ra là tổng hợp của các đầu ra từ các lớp conv ứng với từng tập con của kênh đầu vào. Sự khác biệt ở đây là quá trình hợp nhất đa độ phân giải của HRNet cần xử lý vấn đề thay đổi độ phân giải.
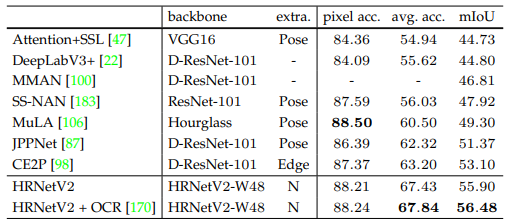
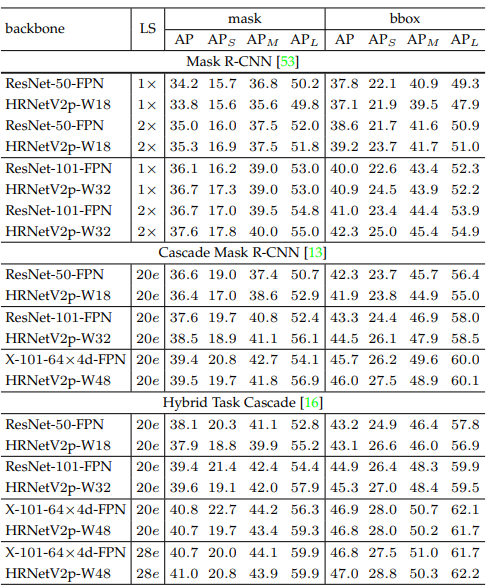
Human pose estimation

Hình trên minh họa một số kết quả thực tế khi áp dụng mô hình HRNet vào bài toán Human pose estimation. Kết quả thể hiện khả năng biểu diễn tốt của mô hình ở các kích thước, pose người khác nhau hay các background khác nhau.
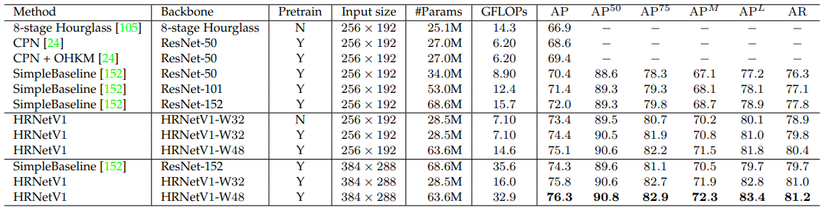
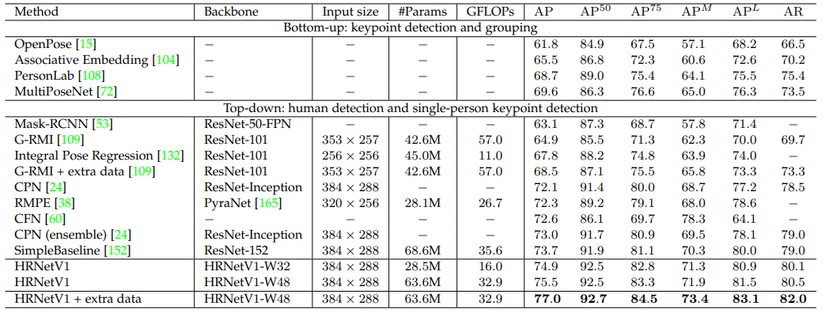
2 bảng dưới so sánh HRNet với các model baseline trên tập dữ liệu COCO val và COCO test.
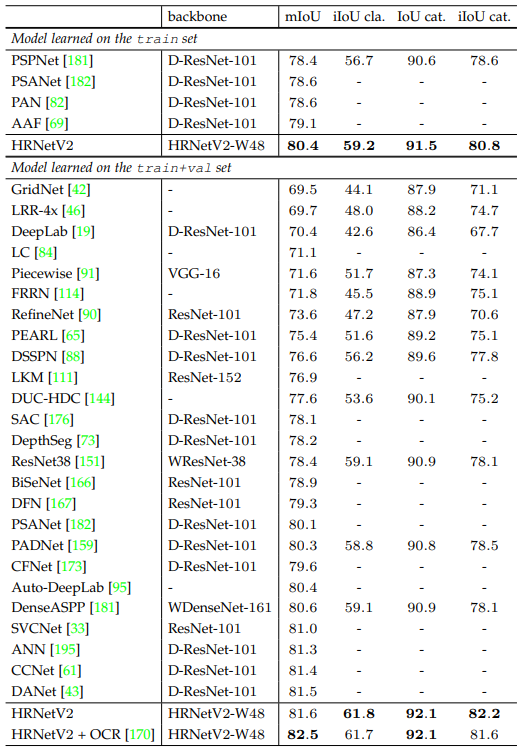
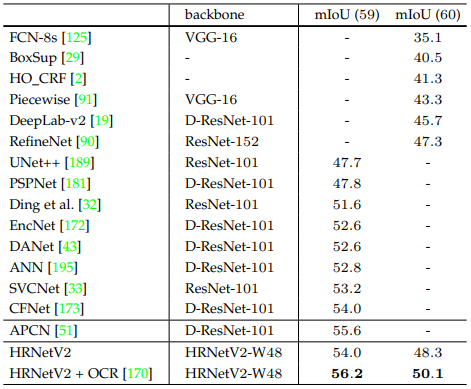
Semantic segmentation

Hình trên minh họa một số kết quả thực tế khi áp dụng mô hình HRNet vào bài toán Semantic segmentation.
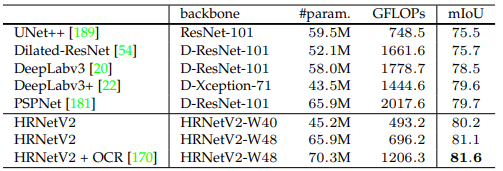
Các bảng dưới so sánh hiệu suất mô hình HRNet với các mô hình SOTA tính đến thời điểm viết bài báo. Các bộ dữ liệu được sử dụng lần lượt là Cityscapes val, Cityscapes test, PASCAL-Context và LIP.
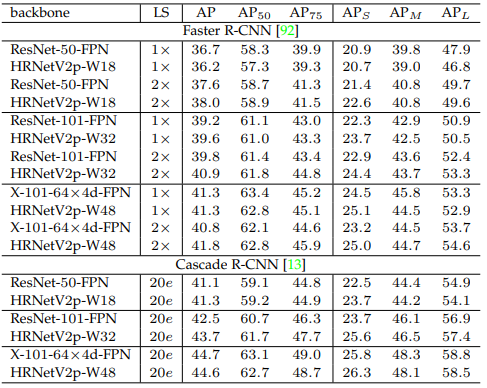
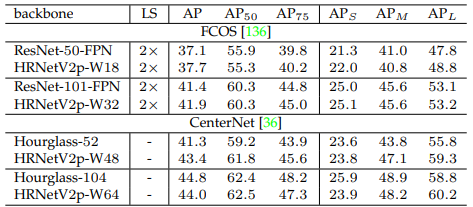
COCO Object detection

Hình trên minh họa một số kết quả thực tế khi áp dụng mô hình HRNet vào bài toán Object detection.
Các bảng dưới so sánh hiệu suất mô hình HRNet với các mô hình SOTA tính đến thời điểm viết bài báo. Bộ dữ liệu được sử dụng là COCO val.

Coding
Bảng dưới là kiến trúc phần main body của HRNet.
Cài đặt tham khảo:
import os
import logging import torch
import torch.nn as nn BN_MOMENTUM = 0.1
logger = logging.getLogger(__name__) def conv3x3(in_planes, out_planes, stride=1): """3x3 convolution with padding""" return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False) class BasicBlock(nn.Module): expansion = 1 def __init__(self, inplanes, planes, stride=1, downsample=None): super(BasicBlock, self).__init__() self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes) self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM) self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * self.expansion, momentum=BN_MOMENTUM) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out class HighResolutionModule(nn.Module): def __init__(self, num_branches, blocks, num_blocks, num_inchannels, num_channels, fuse_method, multi_scale_output=True): super(HighResolutionModule, self).__init__() self._check_branches( num_branches, blocks, num_blocks, num_inchannels, num_channels) self.num_inchannels = num_inchannels self.fuse_method = fuse_method self.num_branches = num_branches self.multi_scale_output = multi_scale_output self.branches = self._make_branches( num_branches, blocks, num_blocks, num_channels) self.fuse_layers = self._make_fuse_layers() self.relu = nn.ReLU(True) def _check_branches(self, num_branches, blocks, num_blocks, num_inchannels, num_channels): if num_branches != len(num_blocks): error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format( num_branches, len(num_blocks)) logger.error(error_msg) raise ValueError(error_msg) if num_branches != len(num_channels): error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format( num_branches, len(num_channels)) logger.error(error_msg) raise ValueError(error_msg) if num_branches != len(num_inchannels): error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format( num_branches, len(num_inchannels)) logger.error(error_msg) raise ValueError(error_msg) def _make_one_branch(self, branch_index, block, num_blocks, num_channels, stride=1): downsample = None if stride != 1 or \ self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion: downsample = nn.Sequential( nn.Conv2d( self.num_inchannels[branch_index], num_channels[branch_index] * block.expansion, kernel_size=1, stride=stride, bias=False ), nn.BatchNorm2d( num_channels[branch_index] * block.expansion, momentum=BN_MOMENTUM ), ) layers = [] layers.append( block( self.num_inchannels[branch_index], num_channels[branch_index], stride, downsample ) ) self.num_inchannels[branch_index] = \ num_channels[branch_index] * block.expansion for i in range(1, num_blocks[branch_index]): layers.append( block( self.num_inchannels[branch_index], num_channels[branch_index] ) ) return nn.Sequential(*layers) def _make_branches(self, num_branches, block, num_blocks, num_channels): branches = [] for i in range(num_branches): branches.append( self._make_one_branch(i, block, num_blocks, num_channels) ) return nn.ModuleList(branches) def _make_fuse_layers(self): if self.num_branches == 1: return None num_branches = self.num_branches num_inchannels = self.num_inchannels fuse_layers = [] for i in range(num_branches if self.multi_scale_output else 1): fuse_layer = [] for j in range(num_branches): if j > i: fuse_layer.append( nn.Sequential( nn.Conv2d( num_inchannels[j], num_inchannels[i], 1, 1, 0, bias=False ), nn.BatchNorm2d(num_inchannels[i]), nn.Upsample(scale_factor=2**(j-i), mode='nearest') ) ) elif j == i: fuse_layer.append(None) else: conv3x3s = [] for k in range(i-j): if k == i - j - 1: num_outchannels_conv3x3 = num_inchannels[i] conv3x3s.append( nn.Sequential( nn.Conv2d( num_inchannels[j], num_outchannels_conv3x3, 3, 2, 1, bias=False ), nn.BatchNorm2d(num_outchannels_conv3x3) ) ) else: num_outchannels_conv3x3 = num_inchannels[j] conv3x3s.append( nn.Sequential( nn.Conv2d( num_inchannels[j], num_outchannels_conv3x3, 3, 2, 1, bias=False ), nn.BatchNorm2d(num_outchannels_conv3x3), nn.ReLU(True) ) ) fuse_layer.append(nn.Sequential(*conv3x3s)) fuse_layers.append(nn.ModuleList(fuse_layer)) return nn.ModuleList(fuse_layers) def get_num_inchannels(self): return self.num_inchannels def forward(self, x): if self.num_branches == 1: return [self.branches[0](x[0])] for i in range(self.num_branches): x[i] = self.branches[i](x[i]) x_fuse = [] for i in range(len(self.fuse_layers)): y = x[0] if i == 0 else self.fuse_layers[i][0](x[0]) for j in range(1, self.num_branches): if i == j: y = y + x[j] else: y = y + self.fuse_layers[i][j](x[j]) x_fuse.append(self.relu(y)) return x_fuse blocks_dict = { 'BASIC': BasicBlock, 'BOTTLENECK': Bottleneck
}
Tham khảo
[1] Deep High-Resolution Representation Learning for Visual Recognition