Tóm tắt
Mục tiêu của Few-shot learning là tận dụng tri thức học được từ 1 hoặc nhiều model deep learning để đạt hiệu suất tốt trên một bài toán mới. Bài toán này có đặc điểm là chỉ có một vài mẫu được gán nhãn trong mỗi class. Vấn đề đặt ra là việc sử dụng model trích xuất tri thức chưa thật sự tối ưu, điều này dẫn đến một câu hỏi là cách tiếp cận mới có thật sự mang lại độ chính xác cao hơn so với mô hình ban đầu hay không. Trong paper, nhóm tác giả để xuất một phương pháp đơn giản đạt hoặc thậm chí đánh bại các phương pháp SOTA trong khi không cần thêm hyperparameter hay parameter. Phương pháp này cung cấp một baseline mới sử dụng để so sánh với các kỹ thuật khác.
Giới thiệu
Setting cơ bản của few-shot thường gồm 2 phần:
- Generic dataset. Bộ dữ liệu này gồm nhiều mẫu cho nhiều class và đảm bảo cho việc train model Deep learning hiệu quả. Thường bộ dữ liệu này chia làm 2 tập con riêng biệt được gọi là base và validation. Tập base được sử dụng cho training và tập validation dùng để đánh giá performance của model. Tuy nhiên, ngược lại với setting cho classification thông thường, dữ liệu trong tập base và validation chứa các class riêng biệt nhau. Vì vậy, performance được đánh giá trên các class mới, không có trong tập base.
- Novel dataset. Bộ dữ liệu này chứa các class không có trong Generic dataset. Ta chỉ có một số ít mẫu được gán nhãn cho mỗi class. Đây chính là bài toán few-shot
 Các mẫu được gán nhãn gọi là support set và phần còn lại được gọi là query set. Khi benchmark, người ta thường sử dụng novel dataset lớn với các few-shot task được lấy ngẫu nhiên, được gọi là run. Hiệu suất của mô hình được tính trung bình trên một lượng lớn run
Các mẫu được gán nhãn gọi là support set và phần còn lại được gọi là query set. Khi benchmark, người ta thường sử dụng novel dataset lớn với các few-shot task được lấy ngẫu nhiên, được gọi là run. Hiệu suất của mô hình được tính trung bình trên một lượng lớn run 
Chúng ta cũng cần phân biệt 2 vấn đề sau:
- Trong inductive few-shot learning, few-shot classifier chỉ được quan sát support dataset và thực hiện predict trên mỗi mẫu của query dataset một cách độc lập. Inductive few-shot learning tương ứng với trường hợp chúng ta bị khó khăn trong việc thu thập dữ liệu
- Đối với transductive few-shot learning, few-shot classifier được quan sát cả support dataset và query dataset. Mặc dù chưa biết nhãn của query dataset nhưng few-shot classifier có thể sử dụng các pattern và thông tin bổ sung từ dataset này để đưa ra dự đoán. Transductive few-shot learning tương ứng với trường hợp chúng ta gặp khó khăn trong việc gán nhãn dữ liệu
Trong bài báo, nhóm tác giả đề xuất một phương pháp đơn giản được thực hiện bằng cách kết hợp các thành phần phổ biến được sử dụng trong các tài liệu trước đây và đạt được hiệu suất cạnh tranh. Bài báo có 2 đóng góp sau:
- Giới thiệu một phương pháp rất đơn giản (được minh họa trong hình dưới) cho inductive và transductive few-shot learning. Phương pháp này không bổ sung thêm hyperparameters nào mới ngoại trừ các hyperparameters cho training backbone
- Chứng minh phương pháp đạt kết quả SOTA trên nhiều benchmark chuẩn khác nhau
Phương pháp
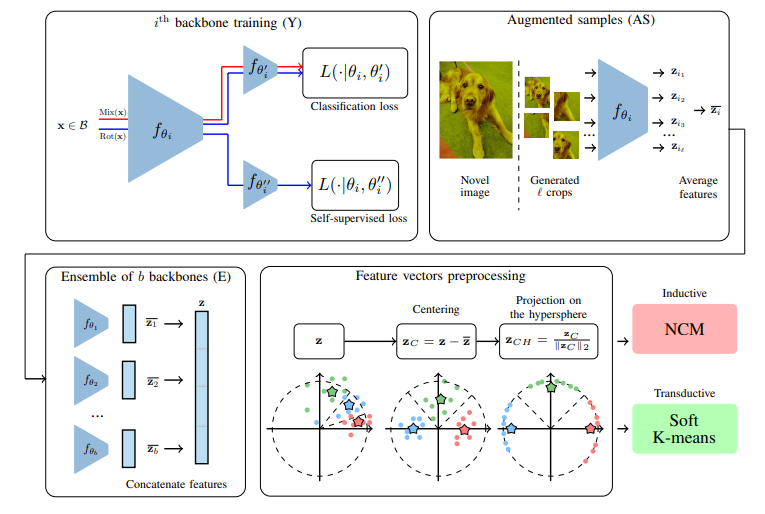
Phương pháp được đề xuất gồm 5 bước, Y: Train một ensemble các backbone sử dụng generic dataset. Nhóm tác giả sử dụng 2 cross-entropy loss song song: Một hàm loss cho phân loại các base class và loss còn lại cho self-supervised targets. Ngoài ra, nhóm tác giả cũng sử dụng manifold mixup. Tất cả các backbone được train sử dụng cách tiếp cận như nhau, điểm khác là việc khởi tạo (random) và thứ tự dữ liệu trong batch. AS: Với mỗi ảnh trong nodel dataset ta thực hiện crop thành nhiều phần, sau đó chuyển thành các feature vector và tính trung bình. E: Mỗi ảnh được biểu diễn bằng cách concat các output từ AS của mỗi backbone. Preprocessing: Bước này thêm một vài phương pháp tiền xử lý kinh điển Đầu tiên là Centering bằng cách trừ cho trung bình của feature vector trên base dataset trong inductive case hoặc novel feature vector cho transductive case, sau đó chiếu trên một không gian mới. Cuối cùng, nhóm tác giả sử dụng Nearest class mean classifier (NCM) nếu trong inductive setting hoặc thuật toán soft K-means trong transductive setting.
Backbone training (Y)
Nhóm tác giả sử dụng data augmentation với các phương pháp random resized crops, random color jitters và random horizontal flips.
Cosine-annealing scheduler được sử dụng. Trong một cosine cycle, learning rate được điều chỉnh giữa và 0. Kết thúc mỗi cycle, nhóm tác giả thực hiện warm-restart và bắt đầu lại với learning rate bằng , sau đó giảm dần giá trị này. ban đầu có giá trị 0.1 và giảm 10% sau mỗi cycle. Mỗi cycle bao gồm 100 epoch.
Nhóm tác giả train backbone sử dụng phương pháp S2M2R. Ý tưởng cơ bản là sử dụng một kiến trúc phân loại tiêu chuẩn (ví dụ như ResNet12) và bổ sung thêm nhánh logistic regression classifier sau layer áp chót (ngoài việc sử dụng classifier cho dự đoán class của mẫu đầu vào). Vì vậy hình thành model có hình chữ Y Classifier mới này để đưa ra dự đoán rotation của ảnh (có 4 class, mỗi class tương ứng với xoay ảnh 90 độ). Dữ liệu đầu vào được chia làm 2 batch, batch đầu tiên đưa vào classifier đầu tiên, được kết hợp với manifold mixup Batch thứ 2 được random rotate và đưa vào car 2 classifier. Sau quá trình training, backbone được đóng băng tham số.
Augmented samples (AS)
Nhóm tác giả thực hiện augmentation feature vector cho mỗi mẫu từ tập dữ liệu validation và novel bằng cách random resized crop ảnh tương ứng. Từ đó ta thu được nhiều phiên bản của mỗi feature vector và tính trung bình chúng. Thực tế, nhóm tác giả sử dụng 30 crops mỗi ảnh, giá trị lớn hơn không có lợi cho độ chính xác. Bước này là optional thui
Ensemble of backbones (E)
Để tăng hiệu suất hơn nữa, nhóm tác giả để xuất concat các feature vector. Các feature vector này thu được từ quá trình training nhiều backbone với cách tiếp cận giống nhau ngoại trừ random seed. Bước này cũng là optional
Feature vectors preprocessing
Tại bước này, nhóm tác giải thực hiện 2 biến đổi trên feature vector . là trung bình feature vector của base dataset nếu trong inductive setting hoặc trung bình novel feature vector trong transductive setting. Thao tác đầu tiên là tính
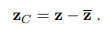
Thao tác tiếp theo là chiếu trên một không gian siêu cầu
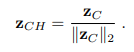
Classification
Trong trường hợp Inductive few-shot learning, nhóm tác giả sử dụng Nearest Class Mean classifier (NCM). Đầu tiên ta tính class barycenters từ mẫu được gán nhãn
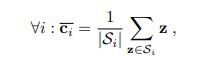
Trong đó, là tập các feature vector (đã được tiền xử lý) tương ứng với support set cho class và là tập các feature vector cho query dataset.
Sau đó ta liên kết mỗi query với barycenter gần nhất
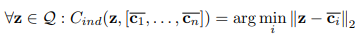
Trong trường hợp transductive learning, nhóm tác giả sử dụng thuật toán soft K-means. Ta tính theo công thức truy hồi dưới
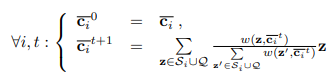
Trong đó là hàm trọng số trên trả về xác suất được liên kết với với barycenter
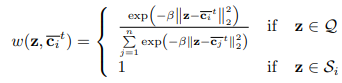
Trái ngược với thuật toán K-mean đơn giản, nhóm tác giả sử dụng giá trị trung bình có trọng số trong đó các giá trị trọng số được tính thông qua một hàm giảm của khoảng cách giữa các điểm dữ liệu và barycenter. Tại đây, một hàm softmax được điều chính bởi giá trị . Trong thực nghiệm, nhóm tác giả sử dụng , giá trị này đảm bảo kết quả nhất quán trên các tập dữ liệu và backbone. Thực tế, nhóm tác giả sử dụng hữu hạn bước. Bằng cách ký hiệu là vector kết quả cuối cùng, dự đoán đưa ra sẽ như sau
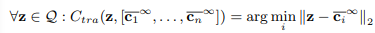
Kết quả thực nghiệm
Dưới đây là kết quả thực nghiệm của phương pháp
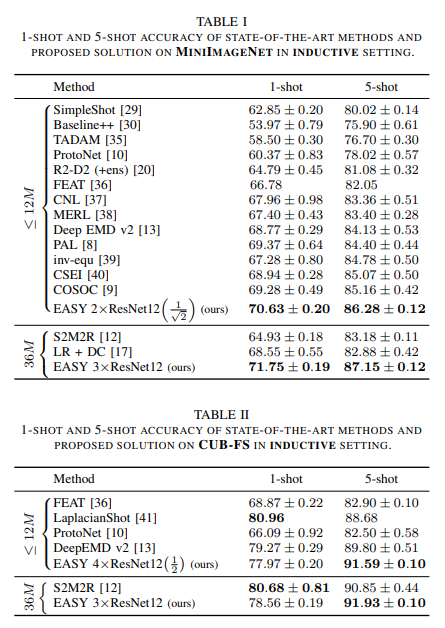
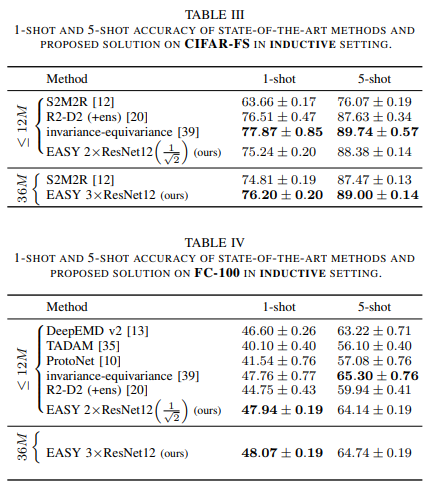
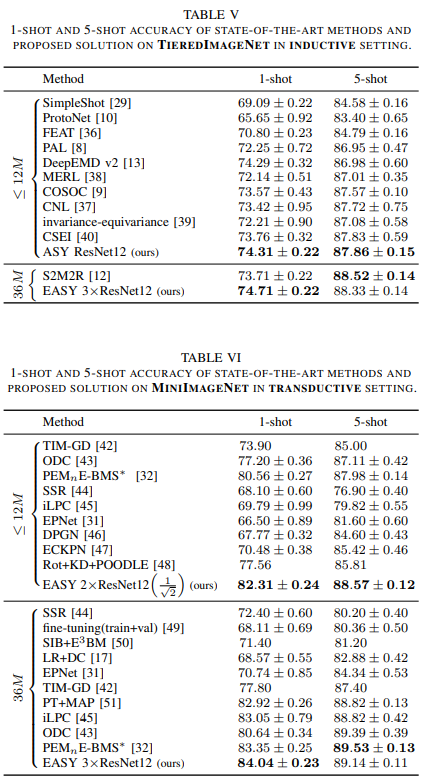
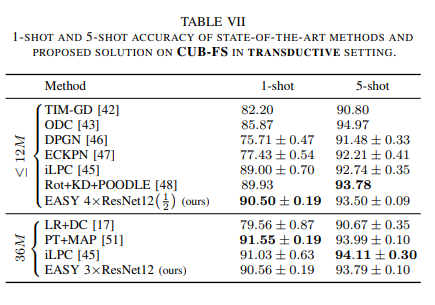
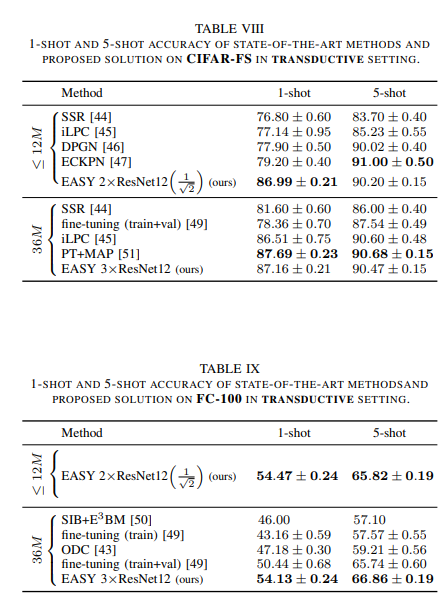
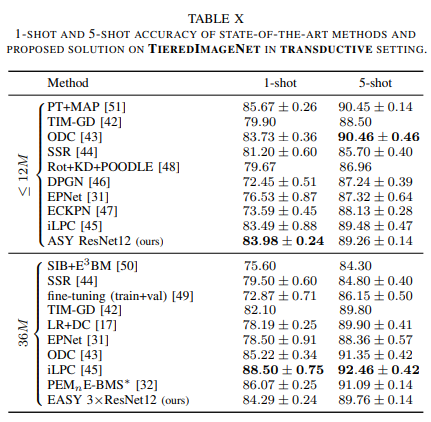
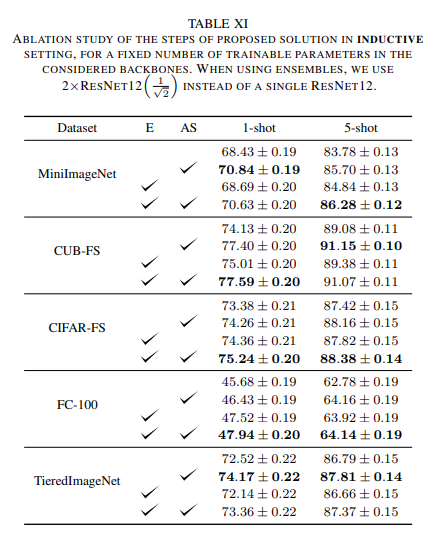
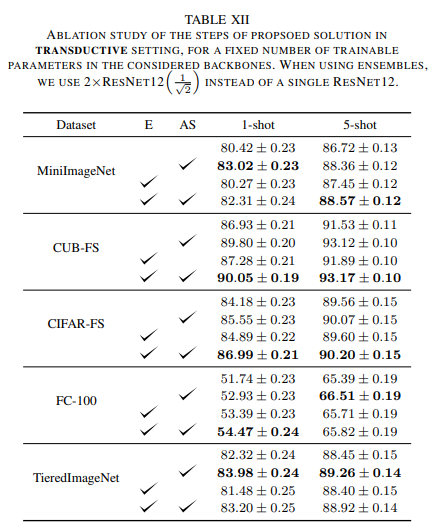
Tài liệu tham khảo
[2] Manifold Mixup: Better Representations by Interpolating Hidden States
[3] SGDR: Stochastic Gradient Descent with Warm Restarts
[4] Charting the Right Manifold: Manifold Mixup for Few-shot Learning
[5] https://github.com/ybendou/easy
[6] https://www.cs.cmu.edu/~02251/recitations/recitation_soft_clustering.pdf