1. Động lực
Các model Transformers based đạt kết quả SOTA nhưng lại ít khi được sử dụng trong thực tế với các bài toán Computer vision do thời gian infer của chúng thường rất chậm (lý do này đến từ cơ chế attention và model được thiết kế phức tạp). Điều này dẫn đến một ý tưởng mới: Liệu ta có thể thiết kế một mạng học sâu cho hình ảnh có tốc độ infer nhanh như các mạng CNNs và độ chính xác như các mạng Transformer based (ví dụ như ViT) hay không?
2. Đóng góp
Với động lực trên, nhóm tác giả đề xuất một model vision Transformer mới đáp ứng được việc triển khai hiệu quả trên môi trường production có tên là Next-ViT. Model này vượt trội so các model CNNs và ViTs nói chung về khía cạnh độ trễ và độ chính xác. Hai block mới trong model được đề xuất là Next Convolution Block (NCB) và Next Transformer Block (NTB) được phát triển để capture thông tin local và global với một cơ chế được thiết kế thân thiện khi mang đi triển khai. Tiếp theo đó là Next Hybrid Strategy (NHS) được thiết kế để stack NCB và NTB làm tăng hiệu suất mô hình trên các downstream task khác nhau. Các thực nghiệm cho thấy mô hình được đề xuất có hiệu suất vượt qua các mô hình CNNs, ViTs và CNN-Transformer hybrid hiện tại trên phương diện latency/accuracy trade-off ở các downstream task khác nhau.
3. Phương pháp
3.1. Tổng quan
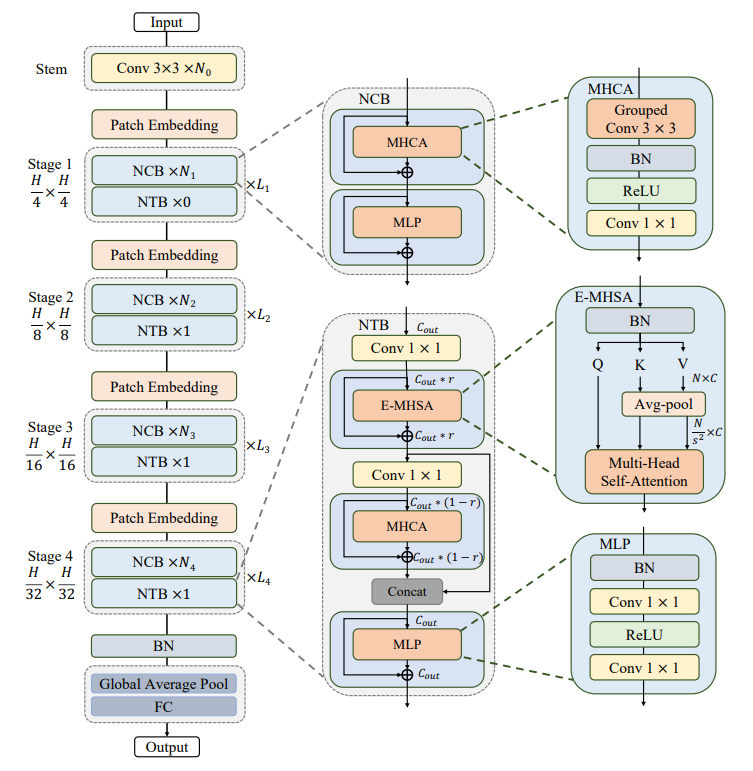
Hình trên mô tả kiến trúc của model Next-ViT, ta có một số điểm cần quan tâm về tổng thể thể model như sau:
-
Model theo kiến trúc phân cấp kim tự tháp.
-
Layer model là patch embedding và tập các Convolution và Transformer block tại mỗi stage.
-
Spatial resolution giảm dần dần đến 32 lần và số chiều của channel được mở rộng qua từng stage.
3.2. Next Convolution Block (NCB)
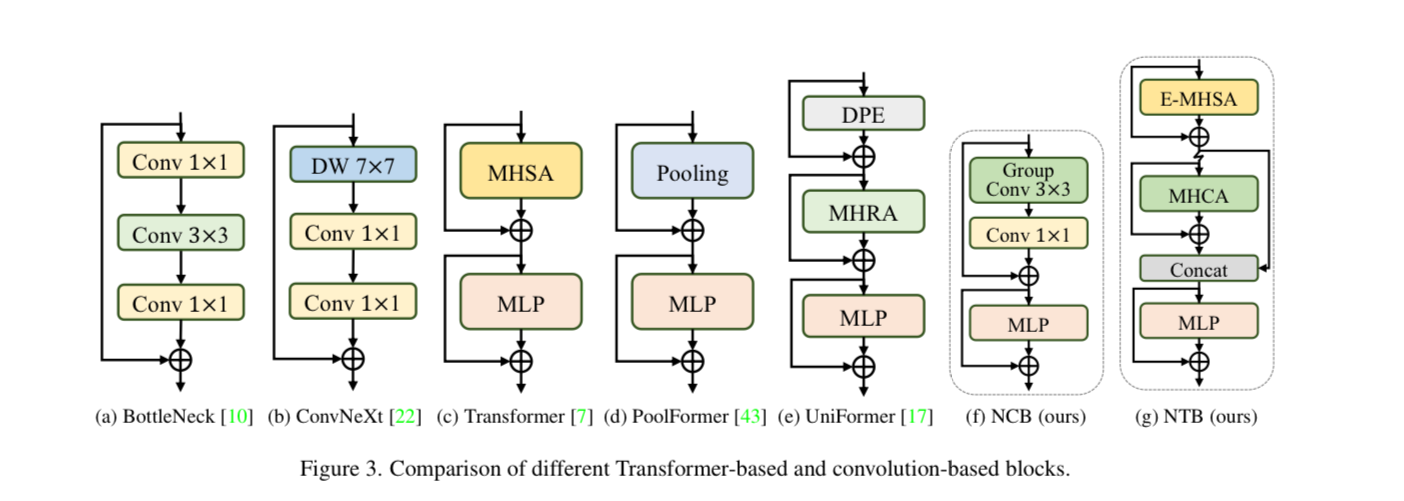
Trước khi trình bày tính ưu việt của block NCB, ta cùng review lại những block kinh điển trước đây. BottleNeck block được sử dụng trong ResNet đem lại sự hiệu quả nhờ tính kế thừa inductive bias và dễ dàng deploy trên nhiều nền tảng phần cứng khác nhau. Tuy nhiên, từ khi Transformer được phát triển và sử dụng cho visual data, ta thấy được rằng các model Transformer đạt được những kết quả SOTA rất ấn tượng. Tuy nhiên, tốc độ inference rất chậm do cơ chế attention phức tạp. ConvNeXt cải tiến BottleNeck dựa trên cách thiết kế của Transformer block, điều này làm cho hiệu suất của model phần nào tăng nhưng tốc độ inference trên TensorRT/CoreML vẫn bị hạn chế.
Để có thể tận dựng được lợi thế về tốc độ infer của BottleNeck trong khi vẫn giữ được hiệu suất tốt của Transformer block. NCB được xây dựng dựa trên kiến trúc chung của Metaformer như hình dưới.
Mặt khác, có một attention-based token mixer hiệu quả cũng rất quan trọng. Nhóm tác giả đã thiết kế Multi-Head Convolutional Attention (MHCA) là một token mixer hiệu quả sử dụng convolution dễ dàng cho việc deploy.
Vậy là ta đã có NCB cùng MHCA và MLP layer trên một sơ đồ kiến trúc MetaFormer  NCB có thể biểu diễn dưới dạng công thức như sau:
NCB có thể biểu diễn dưới dạng công thức như sau:
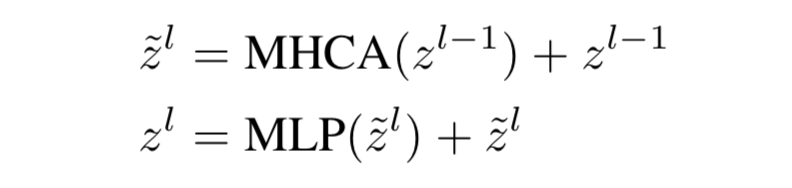
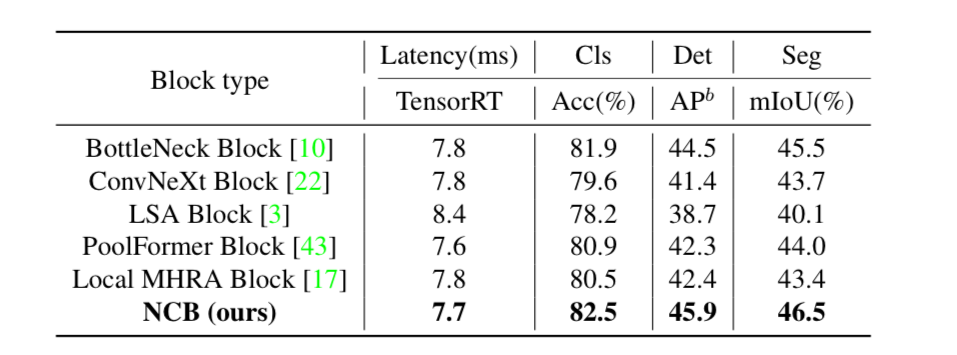
Mức độ hiệu quả khi sử dụng NCB so với các block khác được thể hiện trong bảng dưới:
Code:
class NCB(nn.Module): """ Next Convolution Block """ def __init__(self, in_channels, out_channels, stride=1, path_dropout=0, drop=0, head_dim=32, mlp_ratio=3): super(NCB, self).__init__() self.in_channels = in_channels self.out_channels = out_channels norm_layer = partial(nn.BatchNorm2d, eps=NORM_EPS) assert out_channels % head_dim == 0 self.patch_embed = PatchEmbed(in_channels, out_channels, stride) self.mhca = MHCA(out_channels, head_dim) self.attention_path_dropout = DropPath(path_dropout) self.norm = norm_layer(out_channels) self.mlp = Mlp(out_channels, mlp_ratio=mlp_ratio, drop=drop, bias=True) self.mlp_path_dropout = DropPath(path_dropout) self.is_bn_merged = False def merge_bn(self): if not self.is_bn_merged: self.mlp.merge_bn(self.norm) self.is_bn_merged = True def forward(self, x): x = self.patch_embed(x) x = x + self.attention_path_dropout(self.mhca(x)) if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged: out = self.norm(x) else: out = x x = x + self.mlp_path_dropout(self.mlp(out)) return x
3.2.1. Multi-Head Convolutional Attention (MHCA)
Nhóm tác giả thiết kế một cơ chế attention mới sử dụng convolution với mutli-head hiệu quả có thể tổng hợp thông tin từ nhiều biểu diễn không gian con khác nhau. Công thức của MHCA như sau:
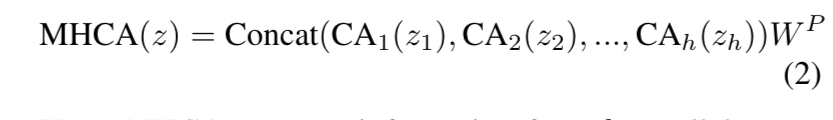
Trong đó:
-
MHCA capture thông tin từ biểu diễn không gian con song song
-
biểu thị việc chia input feature thành dạng multi-head trong channel dimension
Để tăng sự tương tác thông tin giữa các head, nhóm tác giả sử dụng MHCA với một projection layer (W^P). CA là một single-head convolutional attention được định nghĩa như sau:
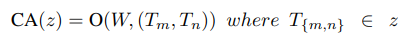
Trong đó:
-
và là các token kề nhau trong input feature
-
là tích vô hướng giữa trainable parameter với các input token
CA có khả năng học sự giống nhau giữa các token khác nhau trong một local receptive field qua việc tối ưu trainable parameter . Cụ thể cách cài đặt sẽ theo sơ đồ sau
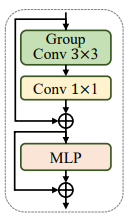
Ngoài ra, ta bổ sung thêm Batch Norm và hàm activation ReLU hơn là LayerNorm và GELU trong các Transformer block truyền thống với mục tiêu tối ưu thời gian infer.
Code:
class MHCA(nn.Module): """ Multi-Head Convolutional Attention """ def __init__(self, out_channels, head_dim): super(MHCA, self).__init__() norm_layer = partial(nn.BatchNorm2d, eps=NORM_EPS) self.group_conv3x3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, groups=out_channels // head_dim, bias=False) self.norm = norm_layer(out_channels) self.act = nn.ReLU(inplace=True) self.projection = nn.Conv2d(out_channels, out_channels, kernel_size=1, bias=False) def forward(self, x): out = self.group_conv3x3(x) out = self.norm(out) out = self.act(out) out = self.projection(out) return out class Mlp(nn.Module): def __init__(self, in_features, out_features=None, mlp_ratio=None, drop=0., bias=True): super().__init__() out_features = out_features or in_features hidden_dim = _make_divisible(in_features * mlp_ratio, 32) self.conv1 = nn.Conv2d(in_features, hidden_dim, kernel_size=1, bias=bias) self.act = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d(hidden_dim, out_features, kernel_size=1, bias=bias) self.drop = nn.Dropout(drop) def merge_bn(self, pre_norm): merge_pre_bn(self.conv1, pre_norm) def forward(self, x): x = self.conv1(x) x = self.act(x) x = self.drop(x) x = self.conv2(x) x = self.drop(x) return x
3.3. Next Transformer Block (NTB)
Việc capture local representation thì đã có NCB lo, còn để capture global representation là nhiệm vụ của NTB
Transformer có khả năng capture các tín hiệu với tần suất thấp, các tín hiệu này cung cấp global information (ví dụ như hình dạng hoặc cấu trúc tổng thể). Tuy nhiên, một vài nghiên cứu gần đây quan sát rằng Transformer block có thể làm giảm chất lượng của thông tin tần suất cao ở một mức độ nhất định (ví dụ như thông tin kết cấu cục bộ). Việc hợp nhất các tín hiệu với tần suất khác nhau giúp ta trích xuất được các feature cần thiết.
Từ những quan sát trên, nhóm tác giả phát triển NTB để capture tín hiệu đa tần suất một cách lightweight. Đầu tiên, NTB capture tin hiệu tần suất thấp bằng sử dụng Efficient Multi-Head Self Attention(E-MHSA) có công thức như sau:
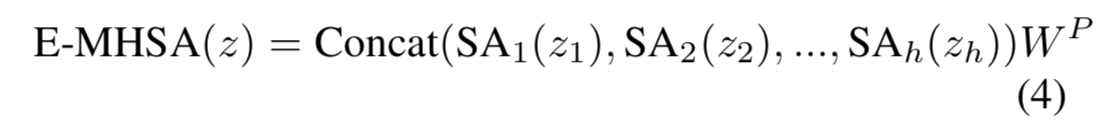
Trong đó:
-
biểu thị việc chia input feature thành dạng multi-head channel dimension.
-
SA là spatial reduction self-attention operator có công thức như sau
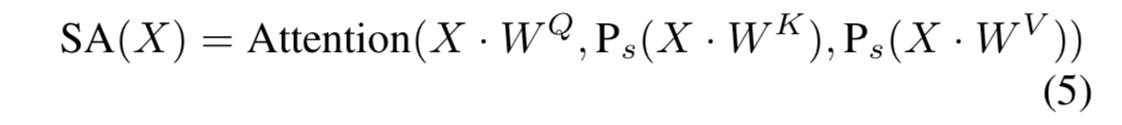
Trong đó:
-
Attention là một attention tiêu chuẩn được tính toán như sau: , biểu thị scaling factor.
-
là các linear layer cho context encoding.
-
là một avg-pool với stride sử dụng để downsampling spatial dimension trước khi thực hiện hoạt động attention để giảm chi phí tính toán.
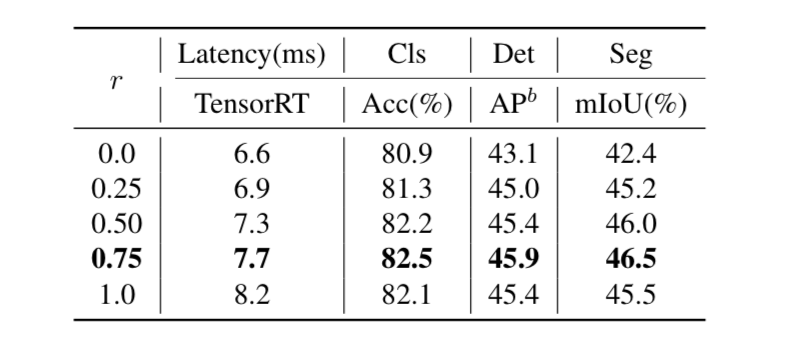
Nhóm tác giả cũng quan sát rằng thời gian chạy của module E-MHSA ảnh hưởng lớn bởi số channel. Do đó, NTB thực hiện channel dimension reduction (giảm chiều kênh) trước E-MHSA module bằng cách sử dụng các point-wise convolution. Tỉ lệ được sử dụng cho channel reduction. Nhóm tác giả cũng sử dụng Batch Normalization trong E-MHSA module để tăng tốc tốc độ infer. Ảnh hưởng của lên độ chính xác và latency được thể hiện trong bảng dưới.
Ngoài ra, NTB cũng sử dụng MHCA module kết hợp với E-MHSA module để capture tín hiệu đa tần suất. Sau đó, các output feature từ E-MHSA và MHCA được concat cho ra thông tin đa tần suất. Cuối cùng, MLP layer được sử dụng để trích xuất các feature cần thiết.

Trong đó, Proj là point-wise convolution layer sử dụng cho channel projection. Tại module này, nhóm tác giả cũng đề xuất sử dụng BN và ReLU thay cho LN và GELU.
Code cho module E-MHSA như sau:
class E_MHSA(nn.Module): """ Efficient Multi-Head Self Attention """ def __init__(self, dim, out_dim=None, head_dim=32, qkv_bias=True, qk_scale=None, attn_drop=0, proj_drop=0., sr_ratio=1): super().__init__() self.dim = dim self.out_dim = out_dim if out_dim is not None else dim self.num_heads = self.dim // head_dim self.scale = qk_scale or head_dim ** -0.5 self.q = nn.Linear(dim, self.dim, bias=qkv_bias) self.k = nn.Linear(dim, self.dim, bias=qkv_bias) self.v = nn.Linear(dim, self.dim, bias=qkv_bias) self.proj = nn.Linear(self.dim, self.out_dim) self.attn_drop = nn.Dropout(attn_drop) self.proj_drop = nn.Dropout(proj_drop) self.sr_ratio = sr_ratio self.N_ratio = sr_ratio ** 2 if sr_ratio > 1: self.sr = nn.AvgPool1d(kernel_size=self.N_ratio, stride=self.N_ratio) self.norm = nn.BatchNorm1d(dim, eps=NORM_EPS) self.is_bn_merged = False def merge_bn(self, pre_bn): merge_pre_bn(self.q, pre_bn) if self.sr_ratio > 1: merge_pre_bn(self.k, pre_bn, self.norm) merge_pre_bn(self.v, pre_bn, self.norm) else: merge_pre_bn(self.k, pre_bn) merge_pre_bn(self.v, pre_bn) self.is_bn_merged = True def forward(self, x): B, N, C = x.shape q = self.q(x) q = q.reshape(B, N, self.num_heads, int(C // self.num_heads)).permute(0, 2, 1, 3) if self.sr_ratio > 1: x_ = x.transpose(1, 2) x_ = self.sr(x_) if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged: x_ = self.norm(x_) x_ = x_.transpose(1, 2) k = self.k(x_) k = k.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 3, 1) v = self.v(x_) v = v.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 1, 3) else: k = self.k(x) k = k.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 3, 1) v = self.v(x) v = v.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 1, 3) attn = (q @ k) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x
Code cho block NTB:
class NTB(nn.Module): """ Next Transformer Block """ def __init__( self, in_channels, out_channels, path_dropout, stride=1, sr_ratio=1, mlp_ratio=2, head_dim=32, mix_block_ratio=0.75, attn_drop=0, drop=0, ): super(NTB, self).__init__() self.in_channels = in_channels self.out_channels = out_channels self.mix_block_ratio = mix_block_ratio norm_func = partial(nn.BatchNorm2d, eps=NORM_EPS) self.mhsa_out_channels = _make_divisible(int(out_channels * mix_block_ratio), 32) self.mhca_out_channels = out_channels - self.mhsa_out_channels self.patch_embed = PatchEmbed(in_channels, self.mhsa_out_channels, stride) self.norm1 = norm_func(self.mhsa_out_channels) self.e_mhsa = E_MHSA(self.mhsa_out_channels, head_dim=head_dim, sr_ratio=sr_ratio, attn_drop=attn_drop, proj_drop=drop) self.mhsa_path_dropout = DropPath(path_dropout * mix_block_ratio) self.projection = PatchEmbed(self.mhsa_out_channels, self.mhca_out_channels, stride=1) self.mhca = MHCA(self.mhca_out_channels, head_dim=head_dim) self.mhca_path_dropout = DropPath(path_dropout * (1 - mix_block_ratio)) self.norm2 = norm_func(out_channels) self.mlp = Mlp(out_channels, mlp_ratio=mlp_ratio, drop=drop) self.mlp_path_dropout = DropPath(path_dropout) self.is_bn_merged = False def merge_bn(self): if not self.is_bn_merged: self.e_mhsa.merge_bn(self.norm1) self.mlp.merge_bn(self.norm2) self.is_bn_merged = True def forward(self, x): x = self.patch_embed(x) B, C, H, W = x.shape if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged: out = self.norm1(x) else: out = x out = rearrange(out, "b c h w -> b (h w) c") # b n c out = self.mhsa_path_dropout(self.e_mhsa(out)) x = x + rearrange(out, "b (h w) c -> b c h w", h=H) out = self.projection(x) out = out + self.mhca_path_dropout(self.mhca(out)) x = torch.cat([x, out], dim=1) if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged: out = self.norm2(x) else: out = x x = x + self.mlp_path_dropout(self.mlp(out)) return x
3.4. Next Hybrid Strategy (NHS)
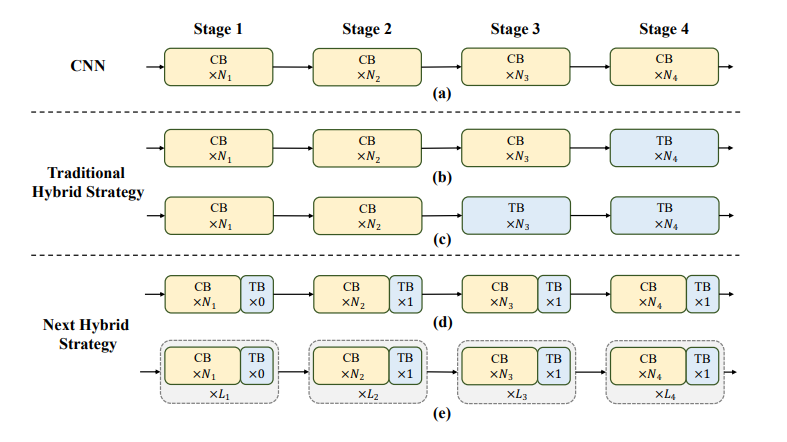
Các nghiên cứu trước đây cũng nghiên cứu cách kết hợp CNN và Transformer để deploy hiệu quả. Như hình trên, ta thấy rằng các mô hình hybrid truyền thống thường sử dụng convolution block tại các stage ban đầu và chỉ stack thêm Transformer block ở 1 hoặc 2 stage cuối. Cách làm này hiệu quả cho các bài toán classification. Tuy nhiên, với các downstream task như segmentation và detection thì hiệu suất chưa được tối ưu. Lý do là các bài toán classification chỉ sử dụng output từ stage cuối cùng để đưa ra dự đoán trong khi segmentation và detection thường phụ thuộc vào các feature tại mỗi stage để đạt kết quả tốt hơn. Vì cách thiết kế hybrid truyền thống mà model không thể capture được các thông tin global vốn rất cần thiết cho bài toán segmentation và detection.
Để giải quyết những vấn đề trên, nhóm tác giả đề xuất 1 Next Hybrid Strategy (NHS) với ý tưởng stack NCB và NTB. Đầu tiên, để cho các stage đầu khả năng capture thông tin global, nhóm tác giả thực hiện stack NCB và 1 NTB như hình dưới

Ta thấy NTB được đặt tại cuối mỗi stage, điều này cho phép model học các biểu diễn global từ các layer nông đầu tiên. Nhóm tác giả thực hiện một số thử nghiệm và có kết quả tại bảng sau
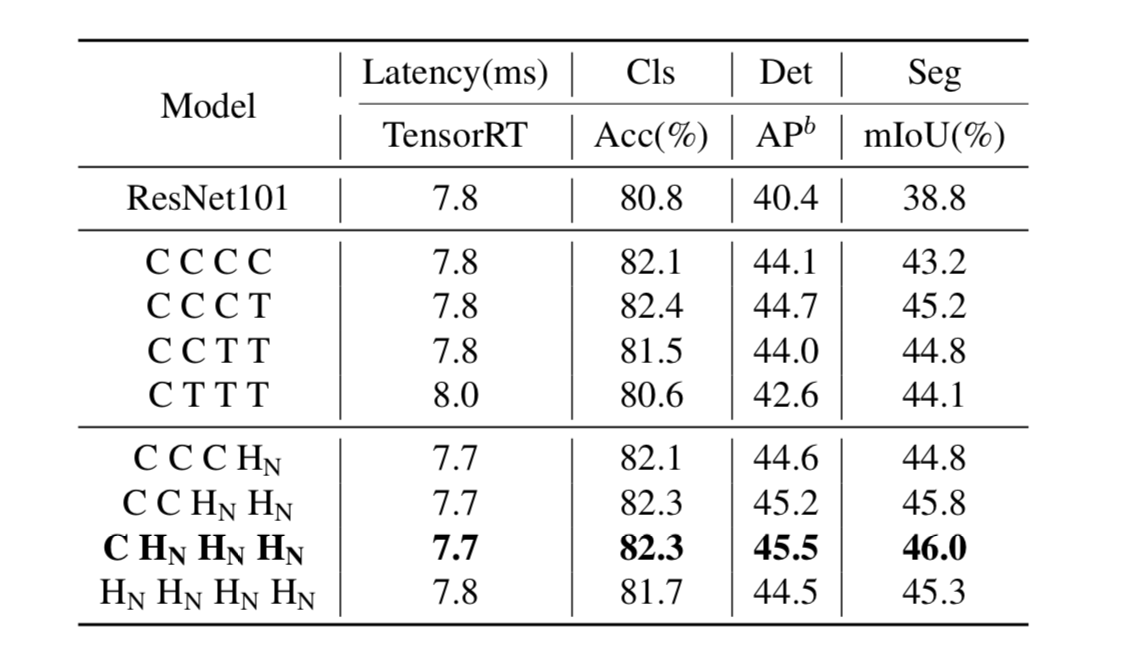
Trong đó C là stacking NCB tại 1 stage và T là sử dụng NTB. Đặc biệt, biểu thị việc stack NCB và NTB theo pattern (NCB * N + NTB * 1). Tất cả model trong bảng trên được sử dụng cho 4 stage. Từ bảng trên ta thấy rằng cho độ chính xác cũng như tốc độ tốt nhất. Bên cạnh đó cho thấy rằng đặt Transformer block tại stage đầu sẽ làm cho latency-accuracy trade-off của model giảm đi.
Nhóm tác giả cũng tăng số block tại stage thứ 3 để kiểm tra mức độ hiệu quả của . Kết quả được thể hiện tại bảng dưới:
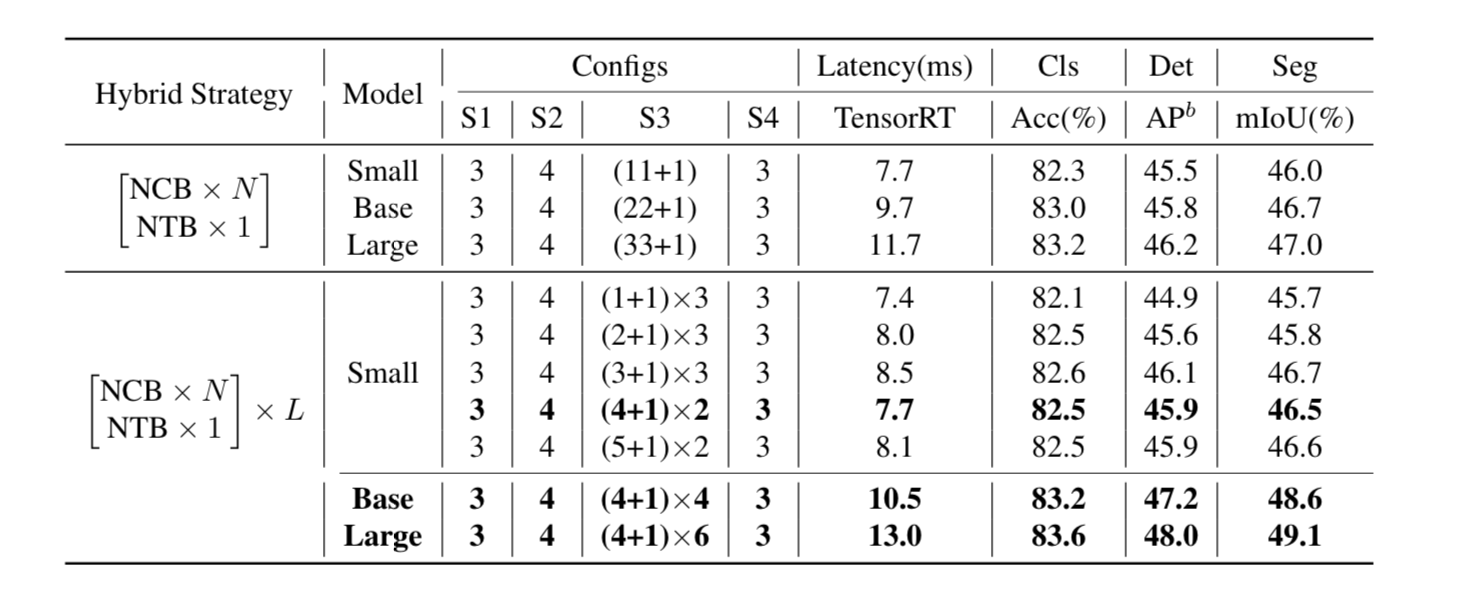
Nhận thấy rằng với và cho ta latency-accuracy trade-off tốt nhất.
3.5. Next-ViT Architectures
Để làm cho việc so sánh trở nên công bằng với các model trước đây nhóm tác giả đề xuất 3 mô hình Next-VIT-S/B/L với cấu hình như bảng dưới:
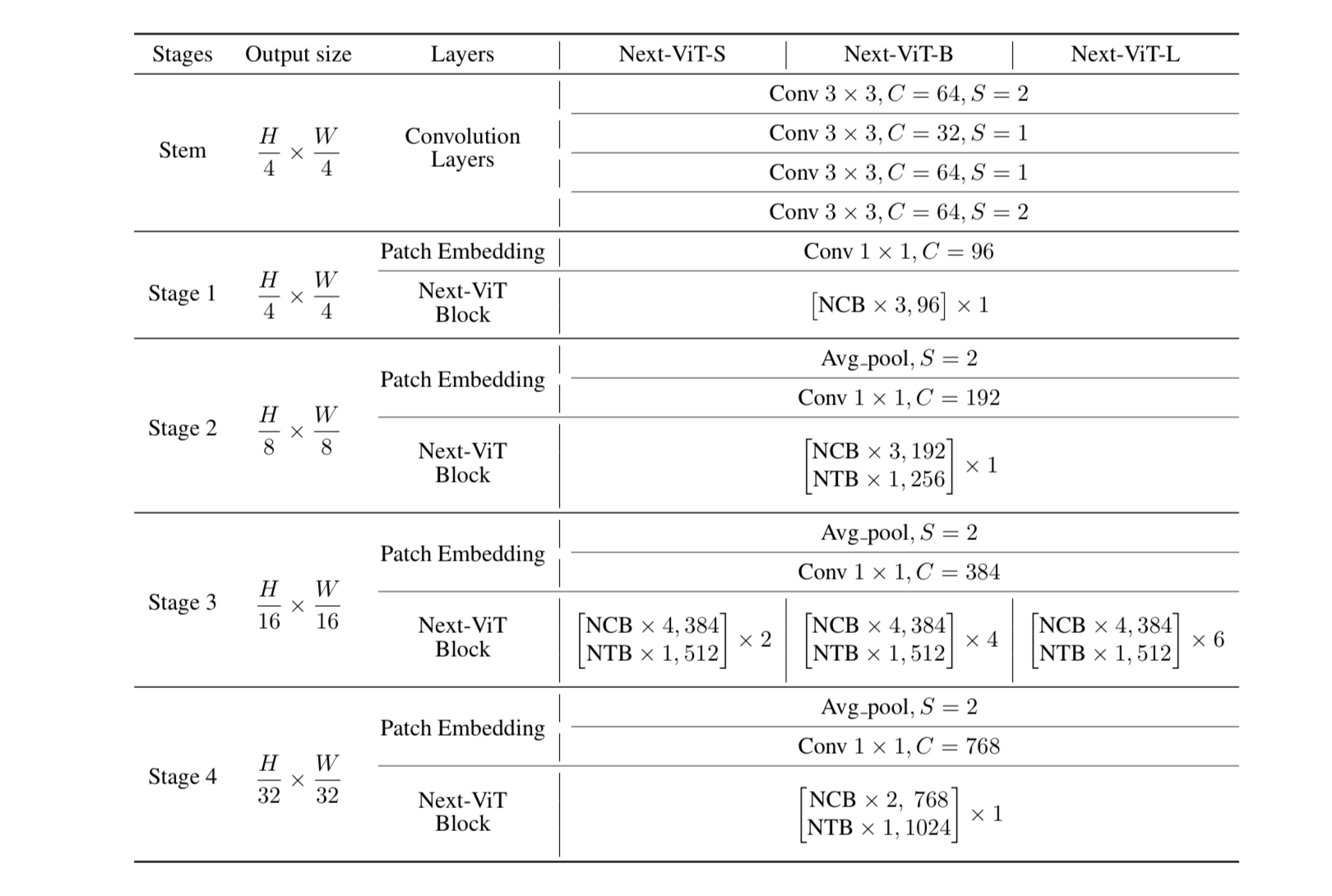
Ngoài ra, một số config không đề cập trong bảng trên như sau:
-
Shrink ratio trong NTB được đặt là 0.75
-
Spatial reduction ratio trong E-MHSA là [8, 4, 2, 1] tại các stage khác nhau
-
Head dim trong E-MHSA và MHCA được đặt là 32
-
Các expansion ratio của MLP được đặt là 3 cho NCB và 2 cho NTB
Code:
class NextViT(nn.Module): def __init__(self, stem_chs, depths, path_dropout, attn_drop=0, drop=0, num_classes=1000, strides=[1, 2, 2, 2], sr_ratios=[8, 4, 2, 1], head_dim=32, mix_block_ratio=0.75, use_checkpoint=False): super(NextViT, self).__init__() self.use_checkpoint = use_checkpoint self.stage_out_channels = [[96] * (depths[0]), [192] * (depths[1] - 1) + [256], [384, 384, 384, 384, 512] * (depths[2] // 5), [768] * (depths[3] - 1) + [1024]] # Next Hybrid Strategy self.stage_block_types = [[NCB] * depths[0], [NCB] * (depths[1] - 1) + [NTB], [NCB, NCB, NCB, NCB, NTB] * (depths[2] // 5), [NCB] * (depths[3] - 1) + [NTB]] self.stem = nn.Sequential( ConvBNReLU(3, stem_chs[0], kernel_size=3, stride=2), ConvBNReLU(stem_chs[0], stem_chs[1], kernel_size=3, stride=1), ConvBNReLU(stem_chs[1], stem_chs[2], kernel_size=3, stride=1), ConvBNReLU(stem_chs[2], stem_chs[2], kernel_size=3, stride=2), ) input_channel = stem_chs[-1] features = [] idx = 0 dpr = [x.item() for x in torch.linspace(0, path_dropout, sum(depths))] # stochastic depth decay rule for stage_id in range(len(depths)): numrepeat = depths[stage_id] output_channels = self.stage_out_channels[stage_id] block_types = self.stage_block_types[stage_id] for block_id in range(numrepeat): if strides[stage_id] == 2 and block_id == 0: stride = 2 else: stride = 1 output_channel = output_channels[block_id] block_type = block_types[block_id] if block_type is NCB: layer = NCB(input_channel, output_channel, stride=stride, path_dropout=dpr[idx + block_id], drop=drop, head_dim=head_dim) features.append(layer) elif block_type is NTB: layer = NTB(input_channel, output_channel, path_dropout=dpr[idx + block_id], stride=stride, sr_ratio=sr_ratios[stage_id], head_dim=head_dim, mix_block_ratio=mix_block_ratio, attn_drop=attn_drop, drop=drop) features.append(layer) input_channel = output_channel idx += numrepeat self.features = nn.Sequential(*features) self.norm = nn.BatchNorm2d(output_channel, eps=NORM_EPS) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.proj_head = nn.Sequential( nn.Linear(output_channel, num_classes), ) self.stage_out_idx = [sum(depths[:idx + 1]) - 1 for idx in range(len(depths))] print('initialize_weights...') self._initialize_weights() def merge_bn(self): self.eval() for idx, module in self.named_modules(): if isinstance(module, NCB) or isinstance(module, NTB): module.merge_bn() def _initialize_weights(self): for n, m in self.named_modules(): if isinstance(m, (nn.BatchNorm2d, nn.GroupNorm, nn.LayerNorm, nn.BatchNorm1d)): nn.init.constant_(m.weight, 1.0) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): trunc_normal_(m.weight, std=.02) if hasattr(m, 'bias') and m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Conv2d): trunc_normal_(m.weight, std=.02) if hasattr(m, 'bias') and m.bias is not None: nn.init.constant_(m.bias, 0) def forward(self, x): x = self.stem(x) for idx, layer in enumerate(self.features): if self.use_checkpoint: x = checkpoint.checkpoint(layer, x) else: x = layer(x) x = self.norm(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.proj_head(x) return x @register_model
def nextvit_small(pretrained=False, pretrained_cfg=None, **kwargs): model = NextViT(stem_chs=[64, 32, 64], depths=[3, 4, 10, 3], path_dropout=0.1, **kwargs) return model @register_model
def nextvit_base(pretrained=False, pretrained_cfg=None, **kwargs): model = NextViT(stem_chs=[64, 32, 64], depths=[3, 4, 20, 3], path_dropout=0.2, **kwargs) return model @register_model
def nextvit_large(pretrained=False, pretrained_cfg=None, **kwargs): model = NextViT(stem_chs=[64, 32, 64], depths=[3, 4, 30, 3], path_dropout=0.2, **kwargs) return
4. Thực nghiệm
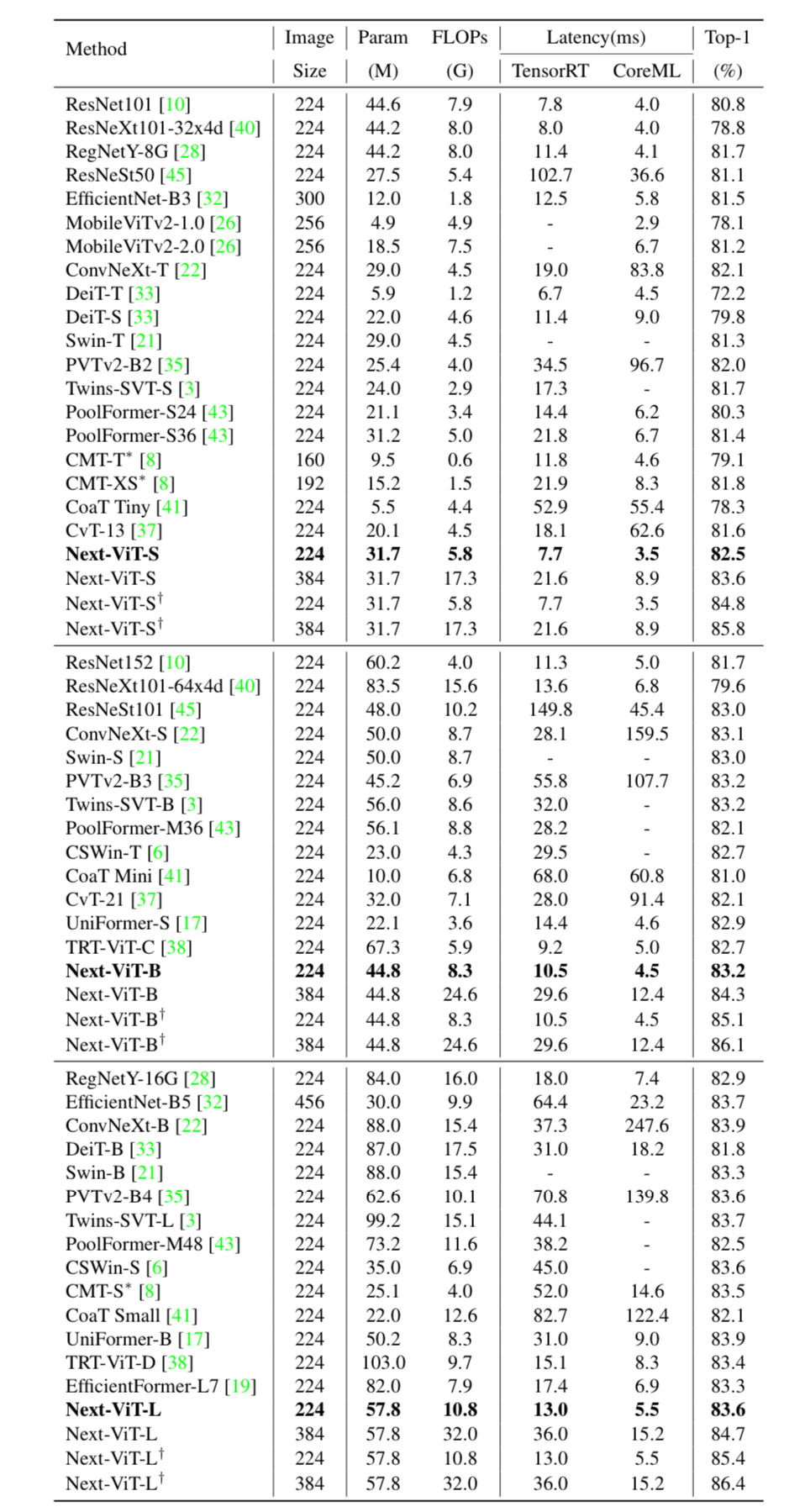
Bảng dưới so sánh các phương pháp SOTA khác nhau cho bài toán ImageNet-1K classification.
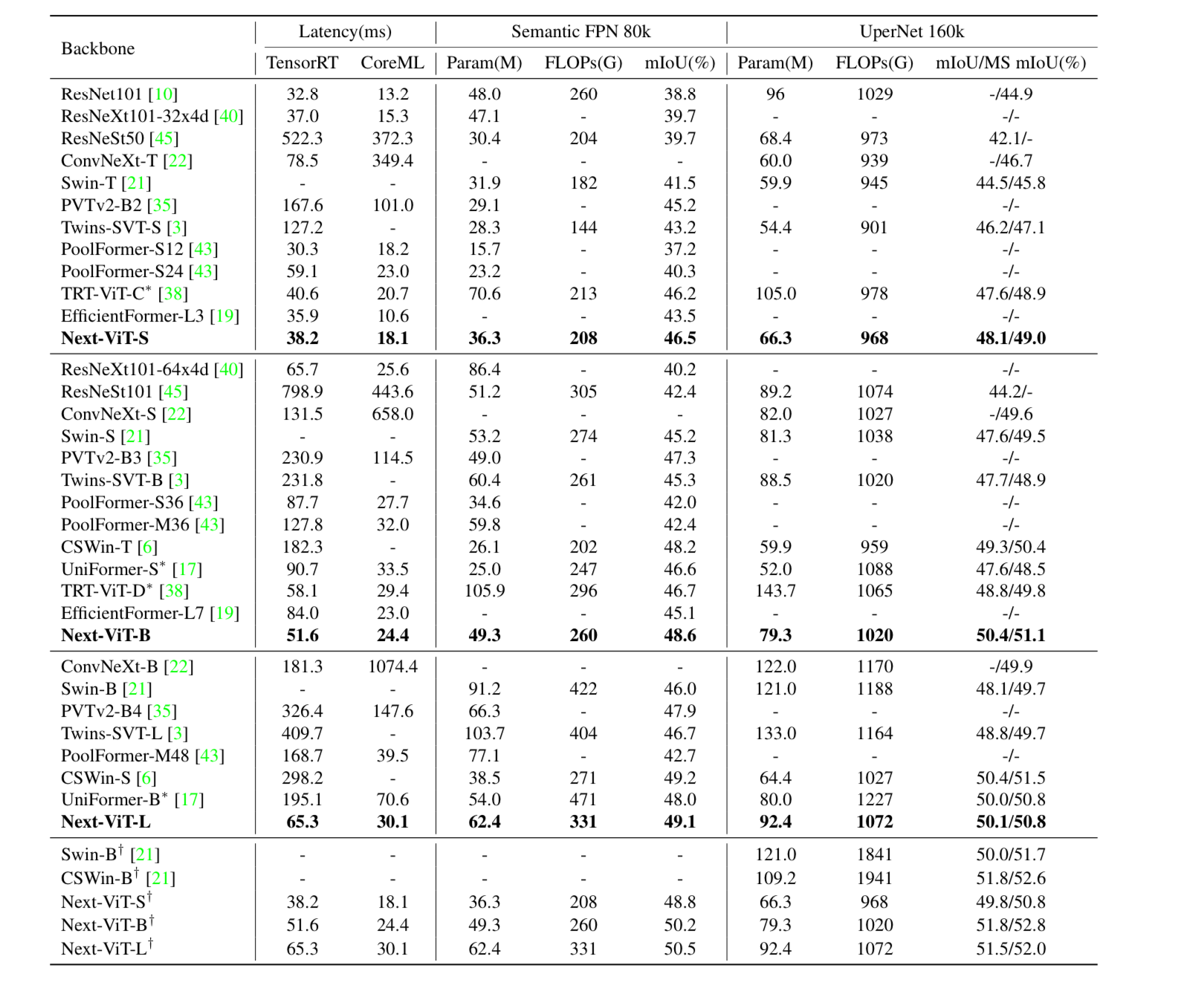
Đối với bài toán ADE20K Semantic segmentation, nhóm tác giả so sánh với các backbone khác nhau. Kết quả như sau:
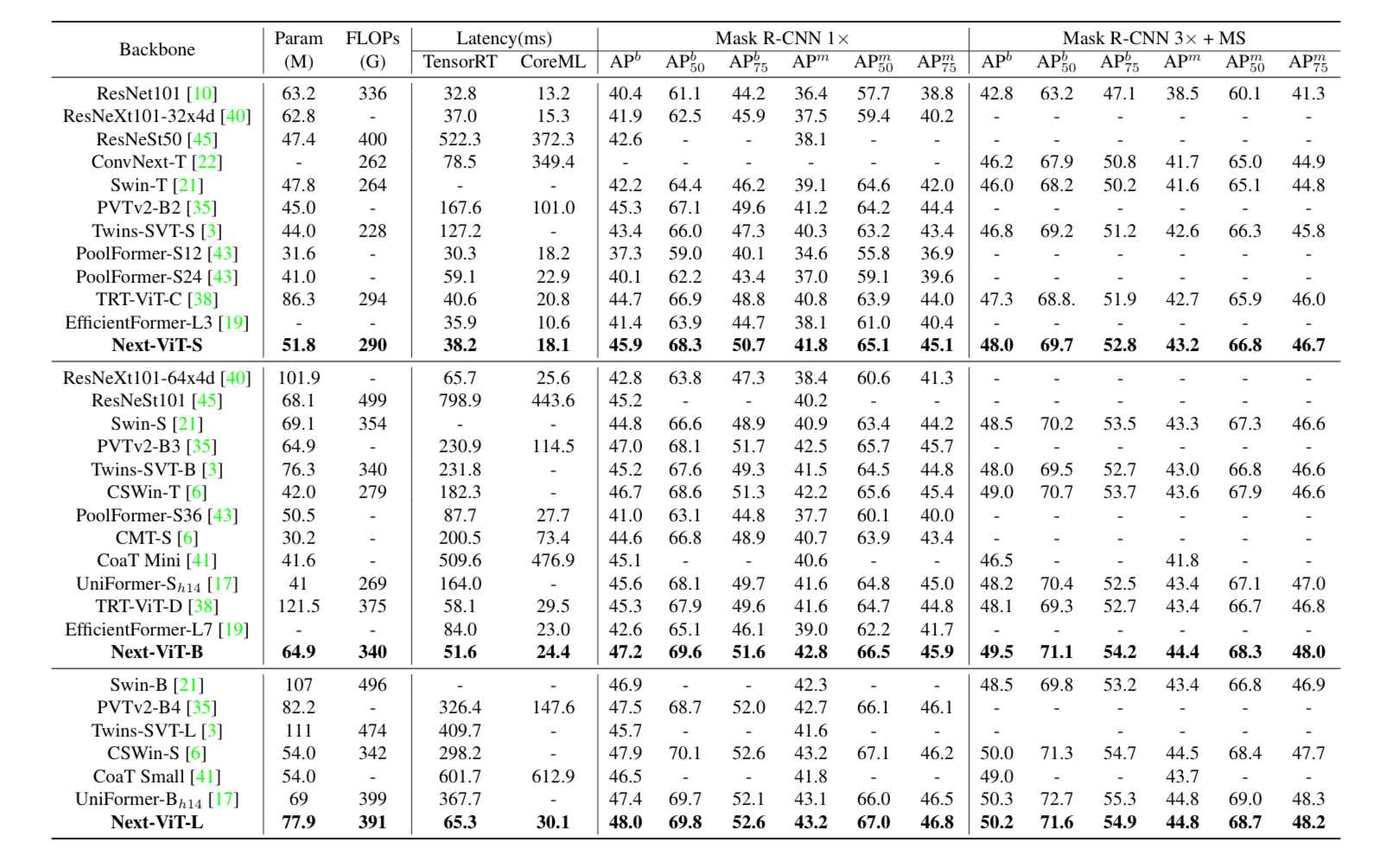
Đối với bài toán object detection và instance segmentation base trên Mask R-CNN, nhóm tác giả so sánh với các backbone khác nhau. Kết quả như sau:
5. Kết luận
Paper cung cấp cho ta một ý tưởng mới khá hay để có thể tận dụng sức mạnh của Transformer mà tốc độ infer vẫn đảm bảo chấp nhận được có thể deploy trên thiết bị di động hoặc server GPU. Việc tận dụng model này vào các production thực tế rất là tiềm năng. Ý tưởng để sử dụng transformer nhưng tốc độ vẫn đảm bảo như bài báo đề xuất là không mới, bạn đọc có thể tham khảo model Mobile-ViT.