Đóng góp của bài báo
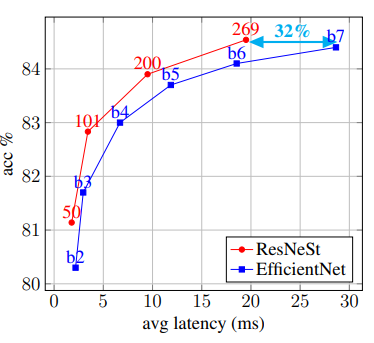
Bài báo giới thiệu một kiến trúc mô hình đơn giản có tên ResNeSt sử dụng channel-wise attention trên các nhánh của mạng với mục tiêu tận dụng sức mạnh capture thông tin tương tác giữa các đặc trưng (cross-feature interaction) và học đa dạng các biểu diễn. Mô hình ResNeSt vượt qua mô hình EfficientNet trên khía cạnh đánh đổi độ chính xác và độ trễ (accuracy and latency trade-off) trên task image classification.
Split-Attention Networks
Toàn bộ ý tưởng hay ho của ResNeSt nằm trong Split-Attention block. Split-Attention block bao gồm 2 thành phần là featuremap group và các split attention.
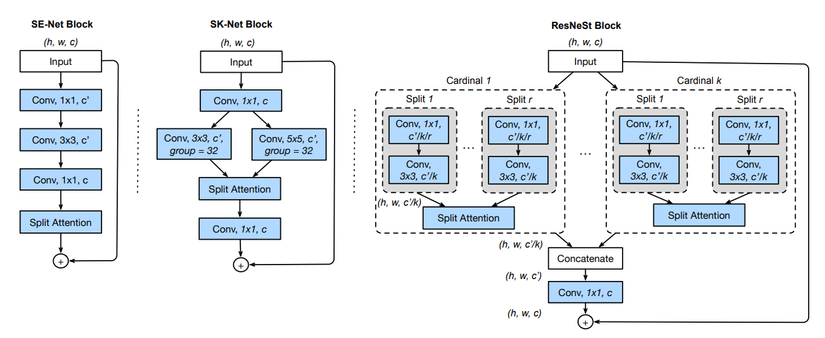
Featuremap Group. Tại Featuremap Group, feature được chia thành các nhóm, ta có thể đặt số lượng Featuremap group bằng một cardinality hyperparameter . Featuremap group có thể gọi là Cardinal group (xem hình trên). Trong bài báo, nóm tác giả cũng giới thiệu một hyperparameter nữa là (radix) thể hiện số lượng split trong cardinal group. Do đó, số lượng feature group là . Tại mỗi feature group, ta thực hiện trích xuất feature sử dụng các layer Conv. Đầu ra của các layer này sẽ được đưa vào Split Attention.
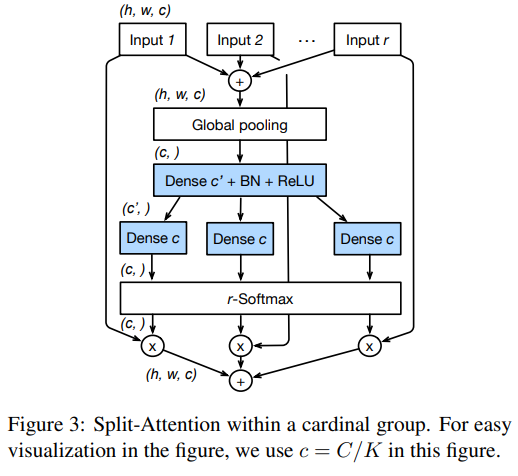
Split Attention trong Cardinal Group. Đầu ra của các split được tổng hợp thông qua phép toán tính tổng element-wise tất cả các split trong cardinal group. Biểu diễn của cardinal group thứ là trong đó là biểu diễn đầu ra của từng split. Các thông tin ngữ cảnh toàn cục sau đó được tổng hợp thông qua một layer global average pooling theo chiều không gian. Thành phần thứ được tính như sau:
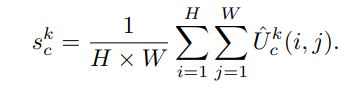
trong đó .
Sau đó, mỗi featuremap của channel được tính toán như sau:
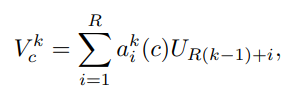
trong đó là trọng số được tính như sau:
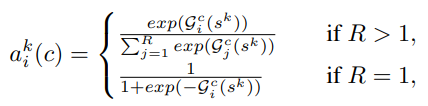
có vai trò xác định trọng số của mỗi split cho channel dựa vào biểu diễn ngữ cảnh toàn cục .
ResNeSt Block. Các biểu diễn của cardinal group sau đó được concat theo chiều channel . Giống như block trong model ResNet, ta sử dụng một kết nối tắt: nếu input và output featuremap có cùng kích thước. Nếu kích thước khác nhaum ta có thể sử dụng thêm một lớp convolution hoặc kết hợp convolution với pooling. Khi đó ta có .
Coding
Ta xây dựng các layer của model ResNeSt như sau:
import torch
import torch.nn as nn
import torch.nn.functional as F class GlobalAvgPool2d(nn.Module): ''' global average pooling 2D class ''' def __init__(self): super(GlobalAvgPool2d, self).__init__() def forward(self, x): return F.adaptive_avg_pool2d(x, 1).view(x.size(0), -1) class ConvBlock(nn.Module): ''' convolution 2D -> batch normalization -> ReLU ''' def __init__(self, in_channels, out_channels, kernel_size, stride, padding ): super(ConvBlock, self).__init__() self.block = nn.Sequential( nn.Conv2d( in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False, ), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) def forward(self, x): x = self.block(x) return x '''
Split Attention
''' class rSoftMax(nn.Module): ''' (radix-majorize) softmax class input is cardinal-major shaped tensor. transpose to radix-major ''' def __init__(self, groups=1, radix=2 ): super(rSoftMax, self).__init__() self.groups = groups self.radix = radix def forward(self, x): B = x.size(0) # transpose to radix-major x = x.view(B, self.groups, self.radix, -1).transpose(1, 2) x = F.softmax(x, dim=1) x = x.view(B, -1, 1, 1) return x class SplitAttention(nn.Module): def __init__(self, in_channels, channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, radix=2, reduction_factor=4 ): super(SplitAttention, self).__init__() self.radix = radix self.radix_conv = nn.Sequential( nn.Conv2d( in_channels=in_channels, out_channels=channels*radix, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups*radix, bias=bias ), nn.BatchNorm2d(channels*radix), nn.ReLU(inplace=True) ) inter_channels = max(32, in_channels*radix//reduction_factor) self.attention = nn.Sequential( nn.Conv2d( in_channels=channels, out_channels=inter_channels, kernel_size=1, groups=groups ), nn.BatchNorm2d(inter_channels), nn.ReLU(inplace=True), nn.Conv2d( in_channels=inter_channels, out_channels=channels*radix, kernel_size=1, groups=groups ) ) self.rsoftmax = rSoftMax( groups=groups, radix=radix ) def forward(self, x): ''' input : | in_channels | ''' ''' radix_conv : | radix 0 | radix 1 | ... | radix r | | group 0 | group 1 | ... | group k | group 0 | group 1 | ... | group k | ... | group 0 | group 1 | ... | group k | ''' x = self.radix_conv(x) ''' split : [ | group 0 | group 1 | ... | group k |, | group 0 | group 1 | ... | group k |, ... ] sum : | group 0 | group 1 | ...| group k | ''' B, rC = x.size()[:2] splits = torch.split(x, rC // self.radix, dim=1) gap = sum(splits) ''' !! becomes cardinal-major !! attention : | group 0 | group 1 | ... | group k | | radix 0 | radix 1| ... | radix r | radix 0 | radix 1| ... | radix r | ... | radix 0 | radix 1| ... | radix r | ''' att_map = self.attention(gap) ''' !! transposed to radix-major in rSoftMax !! rsoftmax : same as radix_conv ''' att_map = self.rsoftmax(att_map) ''' split : same as split sum : same as sum ''' att_maps = torch.split(att_map, rC // self.radix, dim=1) out = sum([att_map*split for att_map, split in zip(att_maps, splits)]) ''' output : | group 0 | group 1 | ...| group k | concatenated tensors of all groups, which split attention is applied ''' return out.contiguous() '''
Bottleneck Block
''' class BottleneckBlock(nn.Module): expansion = 4 def __init__(self, in_channels, channels, stride=1, dilation=1, downsample=None, radix=2, groups=1, bottleneck_width=64, is_first=False ): super(BottleneckBlock, self).__init__() group_width = int(channels * (bottleneck_width / 64.)) * groups layers = [ ConvBlock( in_channels=in_channels, out_channels=group_width, kernel_size=1, stride=1, padding=0 ), SplitAttention( in_channels=group_width, channels=group_width, kernel_size=3, stride=stride, padding=dilation, dilation=dilation, groups=groups, bias=False, radix=radix ) ] if stride > 1 or is_first: layers.append( nn.AvgPool2d( kernel_size=3, stride=stride, padding=1 ) ) layers += [ nn.Conv2d( group_width, channels*4, kernel_size=1, bias=False ), nn.BatchNorm2d(channels*4) ] self.block = nn.Sequential(*layers) self.downsample = downsample def forward(self, x): residual = x if self.downsample: residual = self.downsample(x) out = self.block(x) out += residual return F.relu(out) if __name__ == "__main__": m = BottleneckBlock(256, 64) x = torch.randn(3, 256, 4, 4) print(m(x).size())
Xây dựng model ResNeSt từ các layer trên như sau:
'''
ResNeSt
'''
import torch
import torch.nn as nn from layers import ConvBlock
from layers import GlobalAvgPool2d
from layers import BottleneckBlock class ResNeSt(nn.Module): ''' ResNeSt [1] class [1] ResNeSt : Split-Attention Networks, Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Zhi Zhang, Haibin Lin, Yue Sun, Tong He, Jonas Mueller, R. Manmatha, Mu Li, Alexander Smola, https://arxiv.org/abs/2004.08955 official implementation : https://github.com/zhanghang1989/ResNeSt ''' def __init__(self, layers, radix=2, groups=1, bottleneck_width=64, n_classes=1000, stem_width=64 ): super(ResNeSt, self).__init__() self.radix = radix self.groups = groups self.bottleneck_width = bottleneck_width self.deep_stem = nn.Sequential( ConvBlock( in_channels=3, out_channels=stem_width, kernel_size=3, stride=2, padding=1 ), ConvBlock( in_channels=stem_width, out_channels=stem_width, kernel_size=3, stride=1, padding=1 ), ConvBlock( in_channels=stem_width, out_channels=stem_width*2, kernel_size=3, stride=1, padding=1 ), nn.MaxPool2d( kernel_size=3, stride=2, padding=1 ) ) self.in_channels = stem_width*2 self.layer1 = self._make_layers( channels=64, blocks=layers[0], stride=1, is_first=False ) self.layer2 = self._make_layers( channels=128, blocks=layers[1], stride=2 ) self.layer3 = self._make_layers( channels=256, blocks=layers[2], stride=2 ) self.layer4 = self._make_layers( channels=512, blocks=layers[3], stride=2 ) self.classifier = nn.Sequential( GlobalAvgPool2d(), nn.Linear( in_features=512*BottleneckBlock.expansion, out_features=n_classes ) ) def _make_layers(self, channels, blocks, stride=1, is_first=True ): down_layers = None if not stride ==1 or not self.in_channels == channels * BottleneckBlock.expansion: down_layers = nn.Sequential( nn.AvgPool2d( kernel_size=stride, stride=stride, ceil_mode=True, count_include_pad=False ), nn.Conv2d( in_channels=self.in_channels, out_channels=channels*BottleneckBlock.expansion, kernel_size=1, stride=stride, bias=False ), nn.BatchNorm2d(channels*BottleneckBlock.expansion) ) layers = [] layers.append( BottleneckBlock( in_channels=self.in_channels, channels=channels, stride=stride, downsample=down_layers, radix=self.radix, groups=self.groups, bottleneck_width=self.bottleneck_width, is_first=is_first ) ) self.in_channels = channels * BottleneckBlock.expansion for _ in range(1, blocks): layers.append( BottleneckBlock( in_channels=self.in_channels, channels=channels, radix=self.radix, groups=self.groups, bottleneck_width=self.bottleneck_width ) ) return nn.Sequential(*layers) def forward(self, img): x = self.deep_stem(img) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.classifier(x) return x if __name__ == "__main__": m = ResNeSt( [3, 4, 6, 3] ) img = torch.randn(3, 3, 224, 224) print(m(img).size())
Thực nghiệm
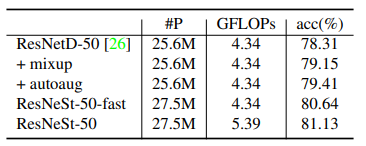
Bảng dưới là hiệu suất của các cải tiến từ model ResNet trên tập dữ liệu ImageNet.
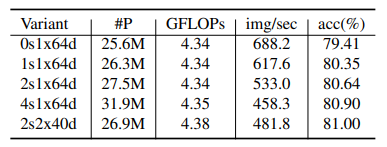
Bảng dưới là hiệu suất của model ResNeSt với các setting khác nhau. Ví dụ, 2s2x40d là radix = 2, cardinality = 2 và width = 40.
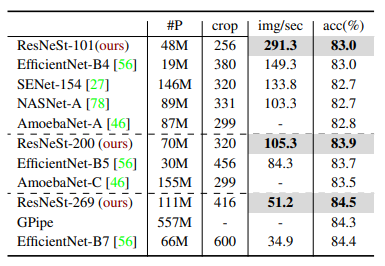
Bảng dưới so sánh độ chính xác và tốc độ inference của các SOTA model trên tập dữ liệu ImageNet. ResNeSt thể hiện sự cân bằng giữa độ chính xác và tốc độ inference một cách tối ưu nhất.
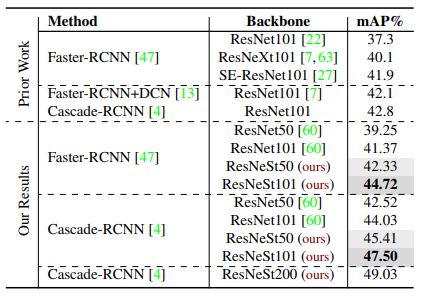
Kết quả trên task Object Detection với tập dữ liệu MS-COCO.
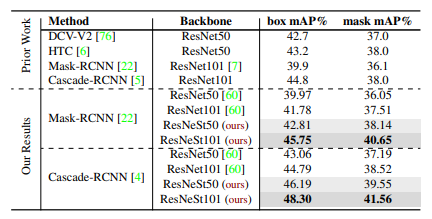
Bảng dưới so sánh kết quả trên task Instance Segmentation với tập dữ liệu MS-COCO.
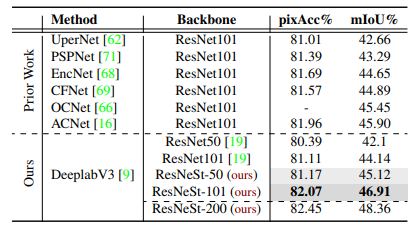
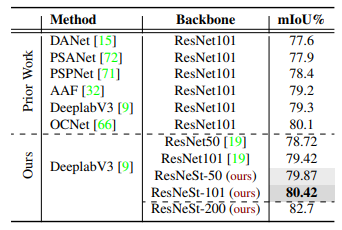
Tương tự với tập dữ liệu ADE20K, ta có kết quả sau:
Với bộ dữ liệu Citscapes, ResNeSt vẫn thể hiện sự vượt trội với các model SOTA trước đó.
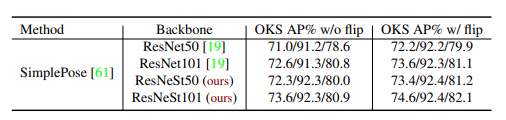
Không chỉ với các task hình ảnh đơn thuần, bảng dưới thể hiện kết quả trên task Pose estimation với tập MS-COCO.
Tham khảo
[1] ResNeSt: Split-Attention Networks
[2] Amazon Introduces ResNeSt: Strong, Split-Attention Networks
[3] https://github.com/zhanghang1989/ResNeSt/tree/master
[4] https://paperswithcode.com/method/channel-attention-module