Abstract
Tiếp nối chuỗi Series nâng cao kiến thức bản thân về ML, DL, bài viết này mình xin phép chia sẻ một bài viết thuộc chủ để Pruning. Vẫn với lí do lướt Towards Data Science, Medium thì thấy bài viết hay quá nên chia sẻ cùng mọi người
Cùng với việc phát triển mạnh mẽ của công nghệ và dữ liệu đã thúc đẩy Deep Learning ngày càng lớn mạnh với những thành tựu đánh kinh nể, có những bài toán có độ chính xác vượt xa cả con người. Các mô hình ngày càng lớn mạnh, đi kèm với việc tiêu tốn tài nguyên. Không nói gì xa, hiện tại khi muốn triển khai Deep Learning cho khách hàng, bên cạnh độ chính xác thì luôn phải cân nhắc tới việc tiêu tốn tài nguyên. Làm sao để giải quyết các bài toán lớn những phải phù hợp với tài nguyên hiện tại. Một trong các giải pháp giải quyết vấn đề này phải kể tới kỹ thuật Prunning.
Pruning là gì?
Nói một cách khai quát, Prunning là một trong những phương pháp đáp ứng việc Inference một cách hiệu quả đối với các mô hình có kích thước nhỏ hơn, tiết kiệm bộ nhớ hơn, suy luận nhanh hơn với độ chính xác giảm ít nhất có thể so với mô hình gốc ban đầu.
Trong Decision tree, Pruning là 1 kỹ thuật regularization để tránh Overfitting, trong đó, các leaf node có chung một non-leaf node sẽ được cắt tỉa và non-leaf node đó sẽ trở thành 1 leaf node, với class tương ứng là class chiếm đa số trong số mọi điểm được phân vào node đó
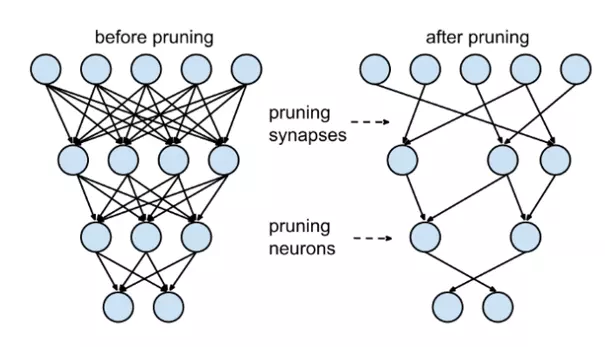
Ý tưởng cắt tỉa mạng neural network được lấy cảm hứng từ chính sự cắt tỉa liên kết neural trong não người, nơi các liên kết thần kinh giữa các neural(axon) bị phân rã hoàn toàn và chết đi xảy ra giữa thời thơ ấu và sự sự khởi đầu của dậy thì. Pruning trong Neural network chính là loại bỏ các kết nối dư thừa trong kiến trúc mạng. Việc cắt bỏ này thực chất là đưa các giá trị trọng số gần 0 về 0 để loại bỏ những kết nối không cần thiết, việc cắt tỉa này sẽ không gây ảnh hường nhiều đến quá trình Inference
Có nhiều cách khác nhau để Pruning model. Có thể cắt tỉa ngày từ đầu một số trọng số ngẫu nhiên, hoặc cũng có thể cắt tỉa khi kết thúc quá trinhg đào tạo để đơn giản hóa mô hình.
Chắc hẳn sẽ có bạn thắc mắc rằng tại sao một mô hình lại nên được cắt bớt thay vì được khởi tạo với ít tham số hơn từ lúc bắt đầu. Câu trả lời cho câu hỏi này là về bản chất bạn muốn giữa một kiến trúc mô hình tương đối phức tạp để đạo tạo, bao quát được dữ liệu. Đồng thời việc tinh chỉnh các lớp, giảm hay tăng kích thước các tính năng là một công việc không đem lại hiệu quả cao. So với đó thì việc Pruning model đơn giản mà mang lại hiệu quả hơn nhiều.
Prunning cùng Tensorflow
Giới thiệu tfmot
Tfmot là một công cụ với mục tiêu loại bỏ những weights yếu nhất vào cuối mỗi bước huấn luyện, đồng thời nó cho phép lập trình viên xác định một lịch trình cắt tỉa sẽ tự động xử lý việc loại bỏ các weights.
Bộ lập lịch này tuân theo một lịch trịch phân rã đa thức (polynomial decay schedule). Cần truyền vào cho công cụ các tham số như:
- Độ thưa ban đầu (initial sparsity)
- Độ thưa cuối cùng (final sparsity)
- Bước bắt đầu cắt tỉa
- Bước kết thúc cắt tỉa
- Số mũ của phép phân rã (exponent ò the polynomial decay) Tại mỗi bước, bộ công cụ sẽ loại bỏ đủ weights sao cho độ thưa thớt đạt được là:
Trong đó
- là độ thưa thớt
- là độ thưa thớt cuối cùng
- là độ thưa thớt ban đầu
- là time step hiện tại
- là time steop bắt đầu
- là số mũ (mặc định là 3)
Ngoài a ra thì các siêu tham số khác cần thay đổi để tìm ra giá trị tối ưu. Theo lời khuyên của tác giả, cần cắt tỉa từ từ, chút một để mô hình “thích nghi” với việc giảm weights, cũng giống như cắt cây, cắt một lèo thì còn gì đâu =))
Triển khai pruning cùng tfmot với ví dụ đơn giản
Để có thể hình dung và dễ sử dụng tfmot hơn, mình sẽ làm một thí nghiệm nhỏ vừa để hiểu cách sử dụng tfmot, vừa để so sánh việc cắt tỉa và không xem hiệu suất mô hình thay đổi như thế nào
Ở đây mình sử dụng sklearn để tạo dataset, đồng thời sử dụng một kiến trúc mạng MLP tương đối đơn giản để so sánh
- Tạo dataset
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression # Parameters of the data-set
n_samples = 10000
n_features = 1000
n_informative = 500
noise = 3
# Create dataset and preprocess it
x, y = make_regression(n_samples=n_samples, n_features=n_features, n_informative=n_informative, noise=noise)
x = x / abs(x).max(axis=0)
y = y / abs(y).max()
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.2, random_state=42)
- Tạo mô hình
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, ReLU model = tf.keras.Sequential()
model.add(Dense(1024, kernel_initializer="he_normal", input_dim=n_features))
model.add(ReLU())
model.add(Dense(1024))
model.add(ReLU())
model.add(Dense(1))
- Summary mô hình
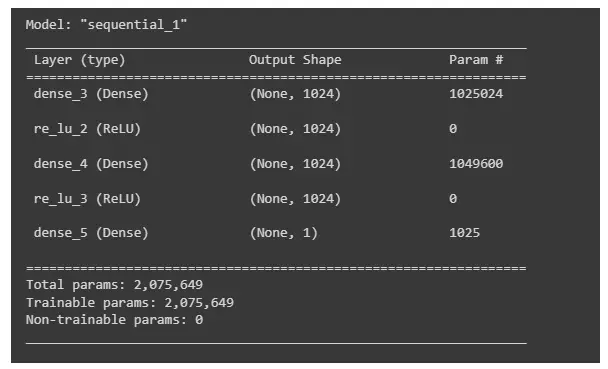
Với kiến trúc mạng đơn giản như vậy tuy nhiên tổng số lượng params cũng đã lên tới hơn 2 triệu, nói gì là các kiến trúc mạng phức tạp. Vì vậy, mình thử nghiệm việc đào tạo mô hình không Pruning và có Pruning xem có thay đổi đáng kể hiệu suất mô hình hay không
- Training mô hình không sử dụng Pruning
model.compile( loss="mse", optimizer=tf.keras.optimizers.Adam(learning_rate=0.001)
)
history = model.fit( x_train, y_train, validation_data = (x_val, y_val), epochs=200, batch_size=1024, verbose=1
)
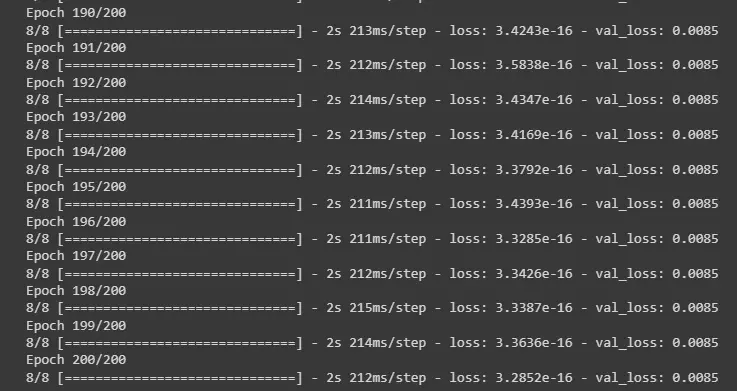
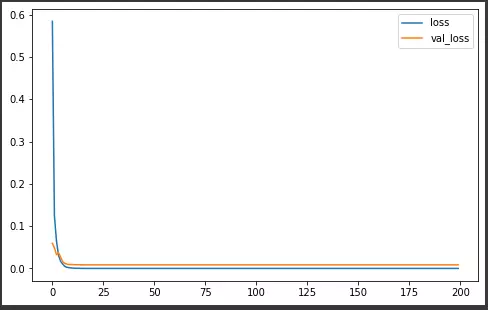
- Training mô hình sử dụng Pruning với công cụ tfmot
import tensorflow_model_optimization as tfmot initial_sparsity = 0.0
final_sparsity = 0.75
begin_step = 1000
end_step = 5000
pruning_params = { 'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay( initial_sparsity=initial_sparsity, final_sparsity=final_sparsity, begin_step=begin_step, end_step=end_step) }
model = tfmot.sparsity.keras.prune_low_magnitude(model, **pruning_params)
pruning_callback = tfmot.sparsity.keras.UpdatePruningStep()
Ở đây sử dụng tfmot như 1 callback, giống learning rate scheduler và early stopping
model.compile( loss="mse", optimizer=tf.keras.optimizers.Adam(learning_rate=0.001)
) history = model.fit( x_train, y_train, validation_data = (x_val, y_val), epochs=200, batch_size=1024, callbacks= pruning_callback, verbose=1
)
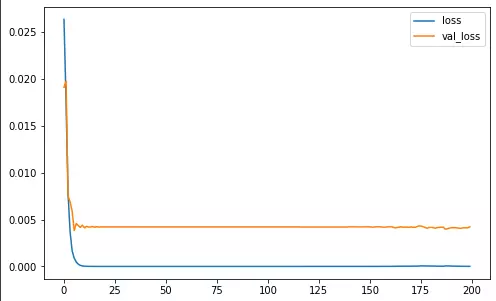
Đã có sự chênh lệch tuy nhiên khi sử dụng Pruning thì độ chính xác giảm đi không nhiều, val_loss vẫn ở mức chấp nhận được
Kết luận
Với cá nhân mình thấy Pruning là mọt phương pháp đang khá được để tâm tới do tính hữu dụng của nó trong việc “làm nhẹ” mô hình. MÌnh đã thử nghiệm một vài bái toán cùng team và nghe một vài buổi seminar nới về Pruning thì thấy kết quả của các tác giả thử nghiệm đem lại hiệu quả tương đối bất ngờ.
Song song với việc phát triển phần cứng thì chúng ta cũng cần có nhwung phương pháp xoa dịu mô hình nhẹ xuống để phần cứng hay tài chính, thời gian còn theo kịp =)))