Đây là bài viết nằm trong Series NestJS thực chiến, các bạn có thể xem toàn bộ bài viết ở link: https://viblo.asia/s/nestjs-thuc-chien-MkNLr3kaVgA
🌸🌼🐉🐲 Xin chào mọi người, ngày vía Thần Tài của mọi người như thế nào rồi, mặc dù hơi muộn nhưng chúc mọi người một năm mới vui vẻ và gặt hái được nhiều thành công 🐲🐉🌼🌸.
Đặt vấn đề 📜
Full Text Search là một khái niệm không có gì xa lạ với anh em đã có kinh nghiệm với lập trình nhưng với các bạn mới bắt đầu học thì có thể sẽ bỏ lỡ. Đa phần các bạn khi search chỉ dừng lại ở mức độ so sánh document nào match với searching keyword bằng filter query (ví dụ {name: 'John Doe'}) hoặc nâng cao hơn là search bằng substring sử dụng $regex (ví dụ {name: { $regex: 'John', $options: 'i'} }). Các cách dùng này tạm ổn với các dự án không đòi hỏi cao về optimize searching vì có thể gặp các vấn đề như:
- Search với filter query: bắt buộc keyword phải chính xác với document cần tìm.
- Search với substring: kết quả trả về sẽ bao gồm các document không mong muốn. Ví dụ chúng ta dùng keyword
'John'để tìm các document có tên là John (John Doe, John Wick, John Cena,...) tuy nhiên nếu dùng substring kết quả sẽ bao gồm các document như Johnathan Nguyen, Johnny Depp. (Có thể dùng trick để giải quyết case này nhưng thế thì không chuyên nghiệp cho lắm 😂)
Để giải quyết các vấn đề chúng ta sẽ đến với khái niệm Full Text Search (FTS), nó là cách để tìm kiếm thông tin dựa trên nội dung, chứ không chỉ dựa trên từ khóa. Điều này giúp tìm kiếm chính xác hơn và tìm được các tài liệu liên quan dựa trên nội dung thay vì chỉ theo từ hoặc cụm từ cụ thể.
Ở bài viết hôm nay chúng ta sẽ tìm hiểu về cách dùng Full Text Search trong MongoDB để xem lợi ích nó mang lại cho dự án như thế nào.
Thông tin package 📦️
-
MongoDB v6.0.5
-
MongoDB Compass v1.35.0
Lý thuyết 📚
Trước khi đi vào sử dụng chúng ta sẽ cùng tìm hiểu một số thuật ngữ liên quan đến FTS trước để lát nữa dễ dàng hơn trong quá trình tìm hiểu. Các thuật ngữ có thể kể đến như:
- Stop word: trong ngôn ngữ xử lý văn bản và xử lý ngôn ngữ tự nhiên (NLP), "stop word" là những từ thông thường và phổ biến trong một ngôn ngữ, như "and," "the," "in," "is," "of," và nhiều từ khác tương tự. Các stop word này thường không mang nhiều ý nghĩa hoặc giá trị trong việc phân tích văn bản hoặc tìm kiếm thông tin, và do đó, chúng thường được loại bỏ hoặc bỏ qua trong quá trình xử lý văn bản hoặc tìm kiếm giúp giảm kích thước của dữ liệu văn bản và cải thiện hiệu suất của các tác vụ tìm kiếm. Tùy vào ngôn ngữ sẽ có những stop word khác nhau.
- Stemming: là quá trình đưa các từ về gốc của nó, ví dụ opens, opening, opened về open. Mục tiêu của stemming là làm cho các biến thể của một từ gốc được giảm xuống thành cùng một dạng cơ bản, để giảm sự phức tạp trong việc xử lý và so sánh văn bản.
Phần tiếp theo là cách sử dụng cơ bản nhanh gọn lẹ dành cho các bạn nào cần phải sử dụng ngay nếu chức năng cần hoàn thành trong thời gian ngắn, bạn nào cần tìm hiểu chi tiết thì có thể skip qua để đến phần tiếp theo.
Cài đặt và sử dụng cơ bản 🛠
⚠️Lưu ý⚠️: bài viết này chúng ta dùng MongoDB Self-deployment chứ không phải MongoDB Atlas. MongoDB Atlas có cung cấp các bản trả phí nên các tính năng sẽ được support tốt hơn và tài liệu đôi lúc sẽ khác với MongoDB Self-deployment.
Đầu tiên chúng ta sẽ chuẩn bị một số record gồm tên (name) và địa chỉ (address), nhằm mục đính kiểm chứng các vấn đề nêu ra ở trên mình sẽ gộp first name và last name lại thành name như bên dưới:
db.users.insertMany( [ { name: "John Doe", address: "3817 Chardonnay Drive, Westport, Washington", }, { name: "John Wick", address: "1161 Stoney Lonesome Road, Williamsport, Pennsylvania", }, { name: "Johnathan Nguyen", address: "692 Bloomfield Way, Portland, Maine", }, { name: "Johnny Depp", address: "1347 Boone Street, Corpus Christi, Texas" }, { name: "Micheal Bob", address: "3282 Victoria Street, North Bonneville, Washington" }, { name: "Alexandra Vayne", address: "4465 Hemlock Lane, Winner, South Dakota" },
] )
Một khi đã có dữ liệu, chúng ta sẽ kiểm tra xem search với substring có gây ra vấn đề như mình đề cập ở trên hay không:
Ở trên có thể thấy rõ ràng record thứ 3 và 4 là Johnathan Nguyen và Johnny Depp, chúng ta đã chứng minh được vấn đề kết quả tìm kiếm chưa đạt được độ chính xác cần thiết.
1. Tìm kiếm thông thường 🔍️
Giờ chúng ta sẽ tiến hành cài đặt Full Text Search (FTS) để xem nó có khắc phục được vấn đề này hay không.
Syntax để implement FTS rất đơn giản:
db.users.find( { $text: { $search: "John" } }
)
Nhưng trước tiên điều kiện tiên quyết để có thể sử dụng FTS trong MongoDB là bắt buộc collection phải có Text Index. Nếu không sẽ gặp lỗi như bên dưới:
Lý do tại sao phải có Text Index mới có thể dùng theo mình suy đoán thì nó giúp chúng ta tăng hiệu suất tìm kiếm và sử dụng các tính năng nâng cao, chúng ta sẽ nói để ở phần sau.
Tiến hành cài đặt Text Index bằng lệnh sau.
// ⏬ Lưu ý loại Index chúng ta dùng ở đây bắt buộc phải là Text Index
db.users.createIndex( { "name": "text" } )
Có thể thấy kết quả trả về đã khắc phục được vấn đề chúng ta nêu ra ở trên là tìm kiếm với kết quả chính xác.
2. Tìm kiếm một cụm từ cụ thể 🔠
Bản chất khi tìm kiếm với FTS các từ (term) chúng ta nhập vào sẽ được tìm kiếm một cách riêng biệt nên đôi khi sẽ không đáp ứng được một vài yêu cầu của chúng ta.
Xét ví dụ chúng ta tạo index là field address và chúng ta muốn tìm kiếm với keyword Victoria Street để trả về user đang sinh sống ở trên con đường đó. Nhưng kết quả trả về lại bao gồm cả user đang ở Boone Street:
Để hiểu rõ hơn nguyên nhân tại sao các bạn hãy bấm qua tab Explain Plan trong MongoDB Compass hoặc nếu dùng CLI có thể dùng method explain(). Kết quả bên dưới ở phần terms sẽ là mảng chứa 2 từ riêng biệt là victoria và street, MongoDB sẽ dùng 2 từ đó để tìm kiếm kết quả chứ không phải là cụm từ Victoria Street.
Để đáp ứng trường hợp này, MongoDB cung cấp cho chúng ta syntax giúp tìm kiếm theo các cụm từ cụ thể:
{ $text: { $search: "\"Victoria Street\"" } }
Bằng cách wrap keyword bên trong \" và \" chúng ta có thể tìm kiếm các cụm từ một cách chính xác.
Chúng ta hãy cùng nhìn vào kết quả trong Explain Plan để xem sự khác biệt. Ở field phrasessẽ là nơi MongoDB tìm kiếm kết quả theo cụm từ và kết quả tìm kiếm phải đáp ứng 2 điều kiện ở field terms và phrases.
3. Loại trừ một term 🚫
Trong trường hợp các bạn muốn tìm kiếm mà cần loại bỏ các kết quả có liên quan tới một term cụ thể có thể thêm vào dấu - ở trước như sau:
{ $text: { $search: "John -Doe" } }
Câu search trên giúp chúng ta tìm ra các user tên John nhưng tên đầy đủ không được chứa từ Doe
💡Các bạn có thể kết hợp cả tìm kiếm theo cụm từ và loại trừ term với nhau. Ví dụ
{ $text: { $search: "Washington \"Victoria Street\" -4000" } }: tìm các user ở Washington trên Victoria Street ngoại trừ số nhà 4000.
Chúng ta đã đi qua xong các cách sử dụng cơ bản, phần tiếp theo sẽ giành cho các bạn muốn tìm hiểu sâu hơn về cách thức nó hoạt động behind the scene.
How it works? 🤔
Trước khi bắt đầu tìm hiểu về FTS chúng ta sẽ cùng nhìn sơ qua cách mà substring search hoạt động.
Các gif sau được lấy từ tài liệu của MongoDB:

Quá trình tìm kiếm sẽ được thực hiện ở Searched Fields quét qua từng từ một xem document nào match với Search Term thì nó sẽ được trả về.
Vậy còn FTS thì sao? Chúng ta sẽ cùng nhìn vào hình bên dưới:
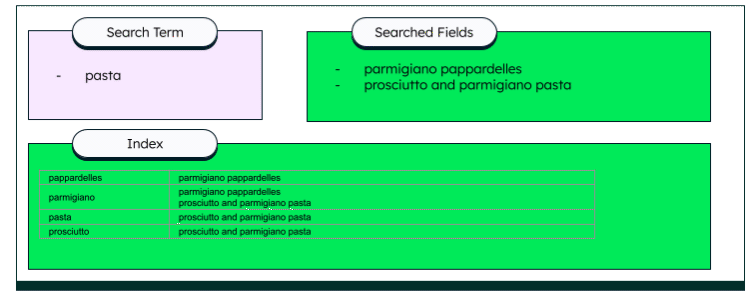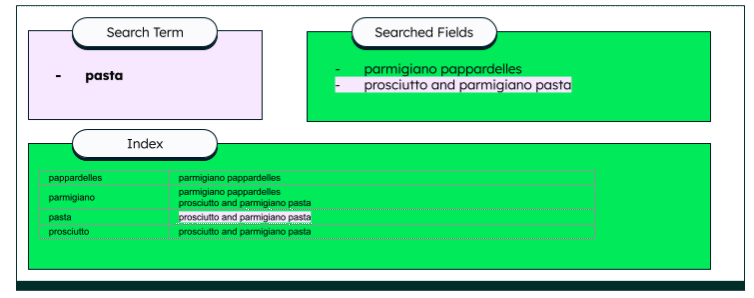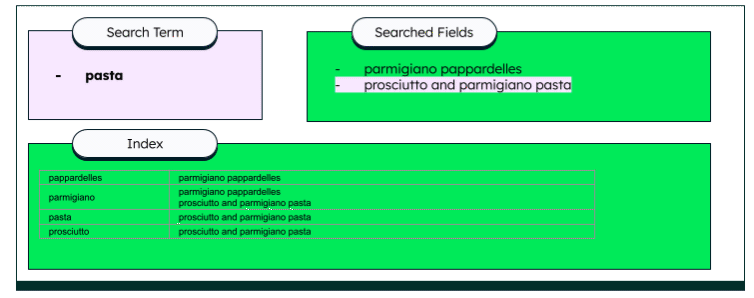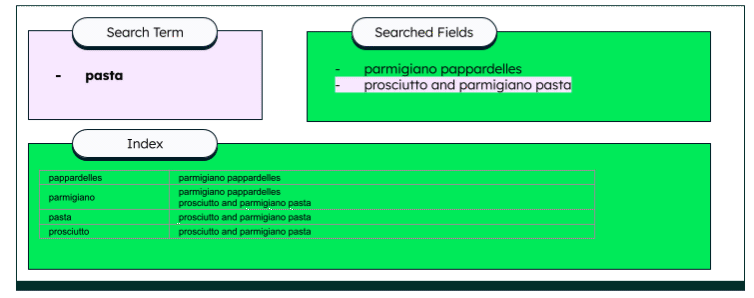
Do dữ liệu đã được index nên thay vì tìm kiếm trong Searched Fields chúng ta sẽ tìm trực tiếp trong Index, khi tìm thấy thì từ Index chúng ta sẽ có được document được nó reference tới. Như ví dụ trên keyword pasta match với Index ở hàng thứ 3 và nó reference tới prosciutto and parmigiano pasta, nếu chúng ta search bằng keyword parmigiano thì kết quả match trong Index sẽ là hàng thứ 2 và vì hàng 2 trỏ tới cả 2 document nên 2 document đó sẽ được trả về.
Do dùng Index nên tốc độ tìm kiếm của nó sẽ vượt trội hơn so với cách thông thường.
Các bạn có để ý thấy các từ trong 2 document được lưu trong Index bị thiếu đi từ and không?!! Nguyên nhân là do giá trị của field trước khi được lưu vào Index phải trải qua giai đoạn tiền xử lý rồi sau đó mới được lưu vào Index.
Chúng ta sẽ cùng tìm hiểu một chút về quy trình MongoDB xử lý dữ liệu khi lưu một document vào collection có Text Index:
Quá trình xử lý sẽ trải qua các giai đoạn sau:
- Without Diacritics: Bước đầu tiên trong quá trình sẽ là loại bỏ các dấu câu (ví dụ é, à, hoặc ç)
- Process Filter Words: Bước tiếp theo sẽ loại bỏ các Stop word tùy theo language mà chúng ta setup (lát nữa chúng ta sẽ nói đến phần này sau). Ví dụ các từ sau sẽ bị loại bỏ ứng với ngôn ngữ là
'en': a, an, the, is, at, which, etc.
Các Stop word bị loại bỏ cũng đồng nghĩa với việc chúng ta không thể tìm kiếm bằng các từ này.
- Steamming: Bước kế tiếp là đưa các từ về nguyên bản của chúng. Ví dụ standing, stands sẽ được đưa về stand, một ví dụ khác là eating, ate sẽ trở về eat.
Phần này mình không rõ ở các ngôn ngữ khác hoạt động như thế nào, bạn nào thông thạo về phần này có thể comment một vài ví dụ để giúp mình và mọi người hiểu rõ nha.
- Casing: Bước cuối cùng là thay đổi cách viết, ở đây có thể đưa về chữ hoa hoặc chữ thường.
Index sẽ được tạo bằng cách thêm các từ (term) vừa tạo với tham chiếu đến các document, từ đó giúp chúng ta có thể nhanh chóng tìm kiếm các document dựa vào những từ được Index (Lưu ý các term sẽ được lưu trữ theo thứ tự).
Chúng ta sẽ thử dựa vào lý thuyết vừa nêu để apply vào ví dụ ở trên:
Khi chúng ta tìm kiếm với từ khóa John thì nó sẽ tìm từ John trong Index, ứng với giá trị được lưu chúng ta có reference đến 2 document là 1 - John Doe và 2 - John Wick.
Lưu ý: ở phạm vi bài viết này chúng ta chỉ tìm hiểu sơ qua về cách FTS works, từ việc lưu vào Index như thế nào cho đến quá trình tìm kiếm ra sao. Tuy nhiên đó cũng chỉ là phần bên ngoài, còn cách thức hoạt động bên trong như thế nào (ví dụ: MongoDB loại bỏ các dấu câu (diacritics) hay các stop word ứng với từng loại ngôn ngữ) thì sẽ cần một bài viết chuyên sâu hơn.
Cách sử dụng nâng cao
Phần này chúng ta sẽ nói về một số cách dùng nâng cao mà các bạn có thể sẽ cần cho một số dự án cụ thể.
1. Compound Text Index
Việc tạo Text Index không chỉ dừng lại ở việc tạo Single Text Index mà chúng ta còn có thể tạo Compound Text Index, giúp tăng phạm vi tìm kiếm. Tuy nhiên cần lưu ý một điều mỗi collection chỉ có thể tạo duy nhất một Text Index, nếu cố tình tạo thì MongoDB sẽ báo lỗi.
Để lấy ví dụ chúng ta sẽ dùng collection collections trong dự án flash card đang phát triển:
db.collections.insertMany( [
{ name: "Living Spaces Vocabulary", description: "Vocabulary about types of rooms in the house such as Living Room, Kitchen, Bath Room, Dinning Room, etc.", level: "easy",
},
{ name: "Kitchen Vocabulary", description: "Vocabulary about kitchen utensils", level: "easy",
},
{ name: "Daily Life Vocabulary", description: "Familiar words often used in everyday life", level: "easy",
}
] )
Với Single Text Index chúng ta chỉ có thể trả về 1 kết quả như sau:
Nhưng nếu chúng ta muốn tăng phạm vi tìm kiếm lên thêm field description chúng ta có thể tạo Compound Text Index như bên dưới (lưu ý nhớ xóa Text Index cũ):
db.collections.createIndex( { name: "text", description: "text" }
)
Thử search lại sẽ thấy chúng ta đã có 2 kết quả:
Bằng cách dùng Compound Index các bạn có thể thêm vào nhiều field khác nữa để tăng phạm vi search theo yêu cầu.
Again there is no rose without a thorn: càng nhiều field thì việc tạo Index càng tốn nhiều thời gian và không gian.
2. Wildcard Text Index
Cần phân biệt giữa Wildcard Text Index và Wildcard Index. Wildcard Text Index hỗ trợ tìm kiếm bằng
$textcòn Wildcard Index thì không.
Phần vừa rồi chúng ta đã biết rằng có thể tạo Text Index trên nhiều field để mở rộng phạm vi tìm kiếm. MongoDB cung cấp thêm cho chúng ta Wildcard Text Index, chỉ cần một dòng code đơn giản có thể đánh Index cho toàn bộ field trong collection như sau:
db.<collection>.createIndex( { "$**": "text" } )
Bằng cách tạo như trên, khi thêm document vào collection tất cả các field dạng text đều sẽ được đánh Index. Tiện lợi là thế, nhưng nó đi kèm với hậu quả là ảnh hưởng khá nhiều tới hiệu năng khi insert và update. Tài liệu MongoDB cũng nói là Wildcard Text Index không hoạt động tốt như khi chúng ta đánh Index trên các field cụ thể.
=> Từ đó có thể kết luận rằng: chỉ nên dùng Wildcard Text Index với các collection có các field chưa thể xác định được do yêu cầu chưa rõ ràng hoặc các field có thể thay đổi trong tương lai. Bên cạnh đó, MongoDB cũng khuyến khích chúng ta nên thử re-design lại schema trước khi phải dùng tới Wildcard Text Index.
3. Sắp xếp kết quả tìm kiếm theo độ chính xác
When MongoDB returns text search results, it assigns a score to each returned document. The score indicates the relevance of the document to a given search query. - MongoDB Document
Mỗi khi chúng ta search với Text Index, nó sẽ tạo ra một score, score này có tác dụng cho biết mức độ khớp của keyword tìm kiếm với document. Điểm càng cao thì khả năng nó giống với nội dung cần được tìm kiếm càng lớn. Mặc định thì score không được hiển thị, chúng ta có thể cho nó hiển thị ra bằng cách dùng project và kết hợp với sort để sắp xếp theo thứ tự:
Có thể thấy ở hình trên, keyword của chúng ta là kitchen và nó xuất hiện 2 lần trong document Kitchen Vocabulary nên score của nó là 1.41 còn ở document Living Spaces Vocabulary thì chỉ xuất hiện 1 lần nên score sẽ thấp hơn là 0.54.
Công thức tính score trong MongoDB như sau: score = (weight * data.freq * coeff * adjustment). Mình sẽ không bàn sâu về công thức ở phạm vi bài viết này, bạn nào hứng thú tìm hiểu có thể tham khảo ở đây.
Sở dĩ chúng ta phải dùng sort vì kết quả trả về khi lấy ra thêm score sẽ không còn theo thứ tự (các bạn có thể xóa bỏ sort và gọi vài lần thì sẽ thấy sự xáo trộn về thứ tự).
Lưu ý: khác với khi lấy ra score, nếu không lấy thì kết quả trả về luôn được sắp xếp theo thứ tự (theo như mình test, nếu có exception nào các bạn góp ý giúp mình).
Vậy liệu chúng ta có thể chủ động tác động đến kết quả của score hay không? Câu trả lời là có! Chúng ta có thể thay đổi nó thông qua việc set giá trị weight mà chúng ta sẽ cùng tìm hiểu ở phần tiếp theo.
4. Sử dụng weight
Weight có thể được khai báo trong quá trình tạo Index, giúp cho biết tầm quan trọng của field đó so với các field còn lại trong Index, mặc định weight sẽ là 1 nếu chúng ta không khai báo. Với weight cao hơn sẽ ảnh hưởng đến score tìm kiếm cao hơn.
Để lấy ví dụ chúng ta sẽ xét 2 documents sau:
db.collections.insertMany( [
{ name: "Living Spaces Vocabulary", // ⏬ Kitchen ở dưới `description` description: "Vocabulary about types of rooms in the house such as Living Room, Kitchen, Bath Room, Dinning Room, etc.", level: "easy",
},
{ name: "Kitchen Vocabulary", // ⏪️ Kitchen ở `name` description: "Vocabulary about utensils", level: "easy",
}
] )
Với Compound Index không dùng weight sẽ cho kết quả như sau:
Kết quả document với name Kitchen Vocabulary có score cao hơn là 0.75 so với 0.54 của Living Space Vocabulary. Giờ chúng ta sẽ xóa Index cũ và tạo lại với weight cho field description là 10.
db.collections.createIndex( { name: "text", description: "text" }, { weights: { description: 10 } }
)
Có thể thấy được sau khi chúng ta tăng weight của field description lên 10 lần thì kết quả score cũng tăng lên 10 lần là 5.4. Chúng ta có thể tận dụng weight để điều chỉnh kết quả tìm kiếm theo các field mình mong muốn.
5. Sử dụng default language
Từ đầu đến giờ chúng ta dùng ngôn ngữ mặc định là English trong Text Index. Trong trường hợp dự án cần sử dụng ngôn ngữ khác thay vì English thì cần phải cẩn trọng. Bởi vì quá trình tạo Text Index các bước như loại bỏ Stop word và Stemming ứng với từng ngôn ngữ sẽ có cách loại bỏ khác nhau. Do đó chúng ta cần phải chú ý việc thay đổi ngôn ngữ để kết quả tìm kiếm được như mong đợi.
Syntax sẽ như sau:
db.<collection>.createIndex( { <field>: "text" }, { default_language: <language> }
)
Lưu ý MongoDB hiện chỉ support một số ngôn ngữ, các bạn có thể tham khảo bảng này để kiểm tra các ngôn ngữ được support.
Lấy ví dụ chúng ta có danh sách document bằng ngôn ngữ Spanish (Tây Ban Nha) như sau:
db.quotes.insertMany( [ { _id: 1, quote : "La suerte protege a los audaces." }, { _id: 2, quote: "Nada hay más surrealista que la realidad." }, { _id: 3, quote: "Es este un puñal que veo delante de mí?" }, { _id: 4, quote: "Nunca dejes que la realidad te estropee una buena historia." }
] )
Nếu chúng ta chỉ tạo Text Index theo cách thông thường như bên dưới thì khi tìm kiếm kết quả sẽ không đúng.
db.quotes.createIndex( { quote: "text" }
)
Ví dụ tìm với keyword hay, đây là 1 Stop words trong ngôn ngữ Spanish ,đáng lẽ kết quả sẽ trả về rỗng nhưng nó vẫn hiện thị ra.
Có thể các bạn (ngay cả mình lúc đầu đọc cũng vậy) sẽ nghĩ "Hiển thị ra thì tốt chứ sao! giúp kết quả chính xác hơn thôi mà", tuy nhiên khi đọc lại tài liệu của MongoDB thì có đoạn viết: To improve the performance of non-English text search queries, you can specify a different default language associated with your text index.. Có nghĩa là chọn ngôn ngữ phù hợp sẽ giúp cải thiện được hiệu năng của việc truy vấn tìm kiếm, vì nếu không cài đặt đúng ngôn ngữ các stop words sẽ không bị loại bỏ, dẫn đến chiếm tài nguyên và quá trình tìm kiếm cũng sẽ mất thời gian hơn.
Chúng ta sẽ fix bằng cách thêm vào default_language property:
db.quotes.createIndex( { quote: "text" }, { default_language: "spanish" }
)
Giờ thử gọi lại và thấy kết quả trả về đã như chúng ta mong đợi:
6. Multiples languages
Một trường hợp khá hay khác mà mình đọc được trong document của MongoDB là support tìm kiếm với document có chứa nhiều ngôn ngữ.
Trường hợp này mình chưa dự án thực tế bao giờ nên chỉ có giá trị giới thiệu để mọi người biết nếu có sai sót nhờ các bạn góp ý 😆.
Điều đầu tiên chúng ta cần làm là document khi được insert phải giống format bên dưới là có field language:
db.<collection>.insertOne( { <field>: <value>, language: <language> }
)
Giả sử chúng ta có document gồm các câu và bảng dịch của nó như sau:
db.quotes.insertMany( [ { _id: 1, language: "portuguese", ⏪️ Phải có field `language` original: "A sorte protege os audazes.", translation: [ { language: "english", ⏪️ Các embedded document cũng phải có `language` quote: "Fortune favors the bold." }, { language: "spanish", quote: "La suerte protege a los audaces." } ] }, { _id: 2, language: "spanish", original: "Nada hay más surrealista que la realidad.", translation: [ { language: "english", quote: "There is nothing more surreal than reality." }, { language: "french", quote: "Il n'y a rien de plus surréaliste que la réalité." } ] }, { _id: 3, original: "Is this a dagger which I see before me?", translation: { language: "spanish", quote: "Es este un puñal que veo delante de mí." } }
])
Khi đó chúng ta có thể tạo Compound Text Index như sau để tiến hành FTS:
db.quotes.createIndex( { original: "text", "translation.quote": "text" } )
Sau đó tiến hành tìm kiếm để kiểm tra kết quả:
Có thể thấy chúng ta đã tìm được kết quả từ trong quote được embed trong translation.
⚠️ Lưu ý quan trọng ⚠️: mặc dù với đa số từ chúng ta tìm kiếm được, nhưng với một số từ lại không cho ra kết quả, ví dụ mình thử với từ
réalitétrong chính ví dụ MongoDB cung cấp nhưng kết quả trả về lại là rỗng:Tương tự với các từ như
surrealista,realidad,surréalistecũng vậy, mình có thử khi tạo document như ở mục Sử dụng default language cóquote: Il n'y a rien de plus surréaliste que la réalité.kết hợp set default_language làfrenchvà khi tìm kiếm thì lại có kết quả.➡️ Có lẽ phần multiple language này của MongoDB có một vài vấn đề. Do đó khi sử dụng đến trường hợp này các bạn cần cân nhắc và nếu dùng thì phải test kỹ lưỡng.
Fuzzy Search 🔎🌫️
Khi search Google hoặc các search engine sẽ có trường hợp chúng ta nhập sai chính tả và kết quả trả về như sau:
Tại sao Google lại có thể biết được chúng ta cần tìm Viblo Asia mà hiển thị kết quả? Đó chính là Fuzzy Search (tìm kiếm "mờ") hay còn được gọi là Approximate Search (tìm kiếm "xấp xỉ").
Về mặt khái niệm thì Fuzzy Search là kỹ thuật giúp chúng ta tìm kiếm kết quả có nội dung gần giống với nội dung chúng ta nhập vào. Các thuật toán thường được dùng để triển khai Fuzzy Search có thể kể đến như:
-
Levenshtein Distance (Edit Distance): Thuật toán Levenshtein distance đo khoảng cách giữa hai chuỗi bằng cách đếm số lần sửa đổi (chèn, xóa hoặc thay thế một ký tự) cần thiết để biến một chuỗi thành chuỗi kia. Kết quả cho biết mức độ giống nhau giữa hai chuỗi.
-
Jaro-Winkler Distance: Thuật toán Jaro-Winkler distance cũng đo khoảng cách giữa hai chuỗi, tuy nhiên, nó tập trung vào việc so sánh các ký tự gần nhau và đánh giá các ký tự giống nhau ở phần đầu của chuỗi một cách cao hơn.
-
Soundex: Soundex là một thuật toán chuyển đổi một từ thành một chuỗi ký tự số dựa trên cách phát âm của từ đó. Các từ cùng mã số Soundex thường có cách phát âm tương tự.
-
Metaphone: Metaphone cũng là một thuật toán dựa trên cách phát âm của từ, nhưng nó sử dụng các quy tắc khác so với Soundex và có thể tạo ra các mã phát âm tốt hơn.
-
N-grams: N-grams là một kỹ thuật tách chuỗi thành các phần con có độ dài n liên tiếp. N-grams có thể được sử dụng để so sánh chuỗi dựa trên sự xuất hiện của các phần con giống nhau.
-
Cosine Similarity: Cosine similarity đo độ tương đồng giữa hai vector từ trong không gian vector. Nó thường được sử dụng trong tìm kiếm văn bản mờ và trong các ứng dụng liên quan đến phân tích văn bản.
-
TF-IDF (Term Frequency-Inverse Document Frequency): TF-IDF là một phương pháp đánh giá độ quan trọng của một từ trong một tài liệu so với tất cả các tài liệu khác. Nó cũng có thể được sử dụng để tìm kiếm mờ trong các tài liệu văn bản.
Các thuật toán này có ứng dụng trong nhiều lĩnh vực, bao gồm tìm kiếm thông tin, tìm kiếm chuỗi trong cơ sở dữ liệu, và tạo ra các chức năng tìm kiếm tùy chỉnh. Việc lựa chọn thuật toán phù hợp phụ thuộc vào bối cảnh và yêu cầu cụ thể của ứng dụng.
Về việc triển khai thì sẽ mất khá nhiều thời gian nên hẹn lại các bạn ở bài viết khác, bài viết này mình chỉ giới thiệu sơ qua để các bạn hình dung được quá trình tìm kiếm được diễn ra như thế nào và thông qua các kỹ thuật gì thôi.
Kết luận 📝
Vậy là thông qua bài viết này chúng ta đã tìm hiểu được Full Text Search là gì và cách triển khai nó trong MongoDB như thế nào. Bên cạnh đó cũng tìm hiểu được các cách dùng FTS trong các trường hợp cụ thể để kiểm soát được kết quả trả về theo ý muốn của chúng ta. Ngoài ra bài viết cũng đã giới thiệu sơ qua về Fuzzy Search để các bạn có thể hiểu về cách các search engine dùng để tìm kiếm kết quả cho chúng ta. Bài viết tiếp theo của mình có thể sẽ tiếp tục chủ đề searching này, nhưng sẽ ở một mức độ nâng cao hơn, đó chính là Elasticsearch. Ở bài viết đó chúng ta sẽ cùng tìm hiểu cách để triển khai một search engine mạnh mẽ và tối ưu cho các dự án cần hiệu năng về search.
⚠️ Vẫn không quên nhắc lại là nội dung bài viết trên dùng cho MongoDB Self-deployment, ở MongoDB Atlas sẽ có thể có các chức năng được support tốt hơn.
Hy vọng bài viết có thể giúp ích cho các bạn. Cảm ơn các bạn đã giành thời gian đọc bài viết của mình 😁.
Tài liệu tham khảo 🔍
- Ananya (2020) Mongo maths, Medium. Available at: https://ananya281294.medium.com/mongo-maths-676469e55f78 (Accessed: 24 September 2023).
- (No date) Perform a Text Search (Self-Managed Deployments) - MongoDB Manual. Available at: https://www.mongodb.com/docs/rapid/core/link-text-indexes/ (Accessed: 24 September 2023).
- Full-text search: What is it and how it works (no date) MongoDB. Available at: https://www.mongodb.com/basics/full-text-search (Accessed: 24 September 2023).
- Trivedi, A. (2023) Full-text search in mongodb: Envato tuts+, Code Envato Tuts+. Available at: https://code.tutsplus.com/full-text-search-in-mongodb--cms-24835t (Accessed: 24 September 2023).
- Thang, T.D. (2023) Simple fuzzy search, Viblo. Available at: https://viblo.asia/p/simple-fuzzy-search-BAQ3vV0nMbOr (Accessed: 24 September 2023).
Change log 📓
- September 24, 2023: Init document.
- February 19, 2024: Modify and public document.