Với những công nghệ hiện đại của thế kỷ 21 chúng ta đã có những phần cứng cũng như phần mềm mạnh mẽ để giải quyết những vấn đề và bài toán nan giải như face recognition, object detection, NLP,... Một trong những vấn đề nan giải cũng được mọi người chú ý ko kém những chủ đề trên là Object Tracking, và đặc thù hơn nữa là bài toán Person Re-identification. Để hiểu được khái niệm và đi sâu hơn vào Person Re-identification thì chúng ta cần phải hiểu những khái niệm cơ bản về person-tracking cũng như cách nó hoạt động, vì vậy mình sẽ đi luôn vào phần sau của nó nhanh và luôn...
Person Tracking
Person Tracking đơn giản là theo dõi một hoặc nhiều người trên các khung hình của video, nhận input một hoặc nhiều input object trong video được ghi trước từ camera giám sát hoặc video thời gian thực và cố gắng phân biệt mọi người và phân loại họ, về cơ bản ta sẽ gán ID cho các từng người một với các bounding box tương ứng và tracking ko để mất dấu họ trên các frame.

Vấn đề của Person Tracking
Như ở trên chúng ta đã biết các hoạt động cơ bản của Person Tracking, nhưng nó có một vấn đề, nếu trong trường hợp ta sử dụng nhiều camera cùng lúc để tracking và gán cùng một ID cho một người thì bài toán sẽ trở lên cực kỳ nan giải và khó. Ta lấy ví dụ một người đi vào trong trung tâm thương mại để mua đồ và tất nhiên trong trung tâm thương mại sẽ gắn rất nhiều camera và mỗi camera sẽ có một góc khác nhau, nếu như người đó cởi áo khoác giữa các máy quay, anh ta sẽ không được nhận ra. Các tư thế khác nhau, trang phục, ba lô và các chi tiết khác có thể khiến mô hình của chúng ta lộn xộn và nhận ra cùng một người là hai người khác nhau và điều hiển nhiên các ID sẽ bị đánh sai và vì thế ta mới cần đến Re-identification để nhận dạng người đó trong trường hợp họ rời khỏi khung hình cũng như những khả năng kể trên xảy ra, nhưng chúng ta làm thế bằng cách nào?... Xem phần tiếp theo nhé  ))
))
Một số thuật toán phổ biến cho Person Tracking
Đầu tiên ta sẽ giả sử chúng ta sẽ detect được mọi người trong khung hình và gán bounding boxs cho từng người trong khung hình đó + với IDs của họ. Câu hỏi đặt ra ở đây là làm sao ta có thể tracking IDs của họ trên khung hình ứng với từng người khi họ chuyển động trên các khung hình tiếp?
Centroid based object tracking
Chúng ta sẽ assign IDs cho objects dựa vào điểm trung tâm của bounding box ", chúng ta dự đoán được các điểm trung tâm tiếp bằng cách dựa vào khoảng cách từ các tâm trước đó và gán IDs dựa vào các khoảng cách tương đối giữa chúng qua từng frame. Nhưng nhược điểm của cách này sẽ xuất hiện khi các frame xuất hiện nhiều người hoặc nhiều đối tượng, nó có thể bị nhầm lẫn IDs giữa các đối tượng với nhau nếu họ quá gần nhau.
Kalman Filter
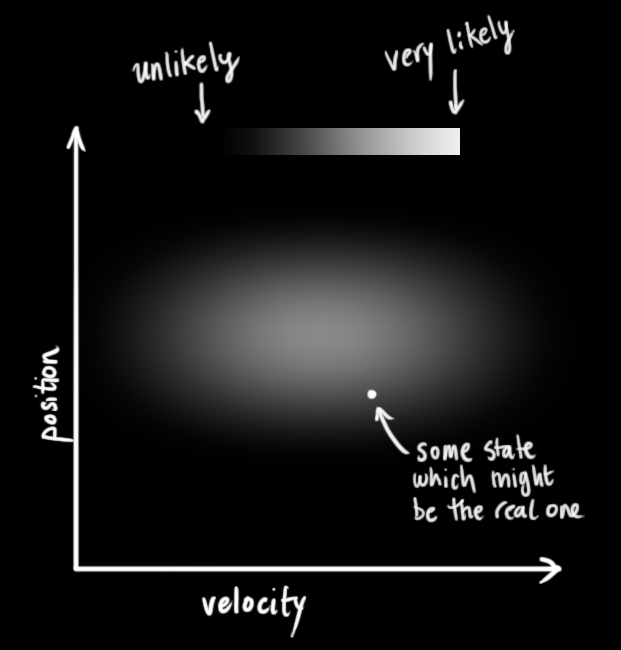
Thuật toán này sinh ra là để cải thiện thằng ở trên, thuật toán cho chúng ta tracking dựa trên vị trí của đối tượng và vận tốc của họ và cuối cùng là dự đoán vị trí của người được tracking. Nó dự đoán được tương lai và vận tốc dựa vào gaussians. Khi nhận được kết quả đọc mới, nó có thể sử dụng xác suất để gán phép đo cho dự đoán của nó và tự cập nhật. Bạn có thể đọc thê về Kalman filter tại đây.
Deep Sort Algorithm
Trong hai thuật toán nêu trên thì ta mới chỉ có sử dụng tới vận tốc, vị trí, hay như sử dụng trung tâm của bounding boxs để dự đoán được người ta đi về đâu dựa vào khoảng cách. Với thuật toán deep short ta sẽ tính toán các features trong từng bounding box rồi so sánh nó dựa trên độ tương đồng giữa các features với nhau để tracking object.
Vậy chúng ta compute các features với nhau lại như thế nào?
Ây dà vẫn một cách giống như bài face recognition thôi, ta sẽ build một model có khả năng học các features trong bounding box đã được detect sẵn, cụ thể các features là các vector 128-dimentional. Sử dụng các vector features này cho chúng ta một sự đảm bảo về độ chính xác hơn là những thuật toán tracking cổ điển
Nhưng về cơ bản là nó có hai điểm yếu lớn nhất đáng lo ngại:
- Nếu bounding box quá lớn thì sẽ có nhiều khoảng trống của background và khi cho vào mạng học thì mạng sẽ học các features của background nhiều hơn ảnh, từ đó làm giảm hiệu quả của thuật toán
- Nếu mọi người ăn mặc giống nhau trên ảnh thì khả năng cao các features sẽ bị nhầm lẫn là giống nhau và sẽ bị gán nhầm ID cho những người ăn mặc giống nhau đấy là một
Bạn có thể tìm hiểu nhiều hơn các thuật toán cũng như các thuật toán kể trên Tại bài viết này
Person Re-identification
Định nghĩa
Level tiếp theo của bài toán person tracking là Re-identification, bài toán đặt ra cho chúng ta là làm sao gán và định danh được đấy là ID của người vừa rồi nếu như họ đã rời đi và xuất hiện lại trên camera hoặc sử dụng nhiều camera trên cùng một thời điểm để tracking, đấy cũng chính là mục đích của bài viết này vậy đầu tiên chúng ta cần phải hiểu Re-identification là gì?
Re-identification là quá trình liên kết các hình ảnh hoặc video của cùng một người được chụp từ các góc độ và camera khác nhau. Mấu chốt của vấn đề là tìm ra các đặc điểm đại diện cho một người. Dạo những năm gần đây nhiều mô hình CNN đã đạt được những thành tựu đáng kể khi giải quyết bài toán này bằng các trích xuất các features của từng frame để cho vào mô hình học và đã đạt được nhiều kết quả khả quan.
Thách thức đặt ra
Tưởng tượng thế này, nếu cùng là bạn xuất hiện trên 4 góc camera khác nhau như hình một cụ ông ở dưới, vậy làm cách nào để chúng ta có thể làm cho máy tính hiểu và tính toán các phép tính để nhận ra đấy là cùng một người trên các camera? đấy chính là vấn đề lớn nhất mà chúng ta cần phải giải quyết, chúng ta sẽ chia nhỏ vấn đề này ở dưới

- Đầu tiên để gán đc ID thì chúng ta cần phải detect được người cần gán ID trên các camera và hiển nhiên là phải có bounding box của mỗi người. Nhưng trong nhiều trường hợp các case detect cũng khá là khoai như hình ở trên (Ô cụ kia đang nằm ưỡn ra đấy :v)
- Chúng ta xây dựng một hệ thống hoặc một model có thể lấy đầu vào là một hình ảnh (single shot hoặc nhiều hình ảnh (multi-shot). Trong đầu vào video, ta cần có khả năng thiết lập sự tương ứng giữa các đối tượng được phát hiện trên các khung hình và track theo họ theo từng chuyển động trên các khung hình đó.
- Các yếu tố ngoại cảnh như: Độ sáng, thời tiết, các sắc thái và màu sắc của từng frame cũng ảnh hưỡng rất nhiều đến các khung hình trên ảnh
- Độ phân giải thấp. Nhiều hệ thống camera quan sát cũ có camera có độ phân giải thấp. Do thiếu thông tin nên việc Re-ID càng trở nên khó khăn hơn
- Môi trường làm việc đông đúc, quần áo,... cũng là các yếu tố chính làm cho việc Re-ID gặp vấn đề ...
Re-ID normal approaches

Chúng ta có thể dựa vào thông tin từ camera như: Góc quay, vị trí, thời gian,... của một người đứng hoặc chuyển động từ camera đã thu để gán ID cho một người, dưới đây là một số phương pháp khả thi:
- Học dựa trên sự biến đổi ánh sáng, màu sắc: Bằng cách học những sự thay đổi dựa trên chức năng chuyển đổi độ sáng của hai đối tượng trên camera (BTF). ID sẽ được thực hiện trên sự chuyển đổi đó của hai đối tượng
- Học dựa trên mô tả: Phương pháp này, ta sẽ cố gắng tìm hiểu các tính năng phân biệt nhất hoặc một lược đồ trọng số phân biệt cho nhiều tính năng cho Re-ID
- Học dựa trên khoảng cách: Phương pháp này tập trung vào việc học các số liệu khoảng cách thích hợp có thể tối đa hóa độ chính xác của độ chính xác của một người trong các frame của video cho. Hay nói cách khác phương pháp này học dựa trên features của đối tượng trong các frame ...
AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
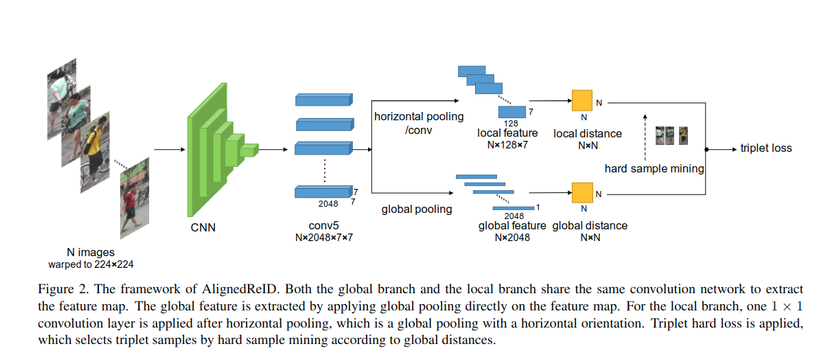
Đây là một bài báo đề xuất một phương pháp được gọi là AlignedReID, đầu vào sẽ là N images sau đó đi qua một mạng CNN là Resnet50 để trích xuất được các đặc trưng của ảnh với đầu ra là một Conv5 NxCxHxW, sau đó sẽ được chia làm 2 branch là global feature được extract từ global pooling, branch thứ hai là local feature được extract từ horizontal pooling. Với local features tác giả đã dùng layer cov1x1 để giảm số chanel xuống. Cuối cùng ta sẽ dùng triplet loss để tính toán similarity của các features với nhau.
Chúng ta có thể tìm hiểu rõ hơn cách thức hoạt động của phương pháp này Tại đây
Reference
1 - https://towardsdatascience.com/people-tracking-using-deep-learning-5c90d43774be
2 - https://arxiv.org/abs/1711.08184
3 - https://github.com/layumi/Person_reID_baseline_pytorch/tree/master/tutorial