Trong thế giới số ngày nay, âm nhạc đã trở thành một phần không thể thiếu trong cuộc sống hàng ngày của chúng ta, và các dịch vụ phát nhạc trực tuyến như Spotify đã làm thay đổi cách chúng ta tiếp cận và thưởng thức âm nhạc. Để cung cấp một dịch vụ nhạc trực tuyến hiệu quả và mượt mà cho hàng triệu người dùng, việc thiết kế một hệ thống mạnh mẽ, có khả năng mở rộng và đáng tin cậy là cực kỳ quan trọng. Bài viết này sẽ khám phá kiến trúc và thiết kế hệ thống đằng sau một dịch vụ phát nhạc trực tuyến, tập trung vào các thành phần chính, công nghệ liên quan, và các chiến lược được áp dụng để xử lý lượng lớn dữ liệu và lưu lượng truy cập cao một cách hiệu quả.

Bạn cho chúng mình xin 1 upvote và comment để chúng mình nhận giải của viblo nha. Và chúng mình có động lực ra những bài viết thú vị hơn nữa 😄😄😄
Cùng Sydexa khám phá những công nghệ thú vị nha!!! 😄😄
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Giai đoạn ban đầu: Phiên bản nền tảng
Những yêu cầu ban đầu
Trong giai đoạn khởi đầu, Spotify hướng tới mục tiêu xử lý đến 500 nghìn người dùng và 30 triệu bài hát. Người dùng sẽ nghe nhạc và các nghệ sĩ sẽ tải bài hát lên hệ thống.
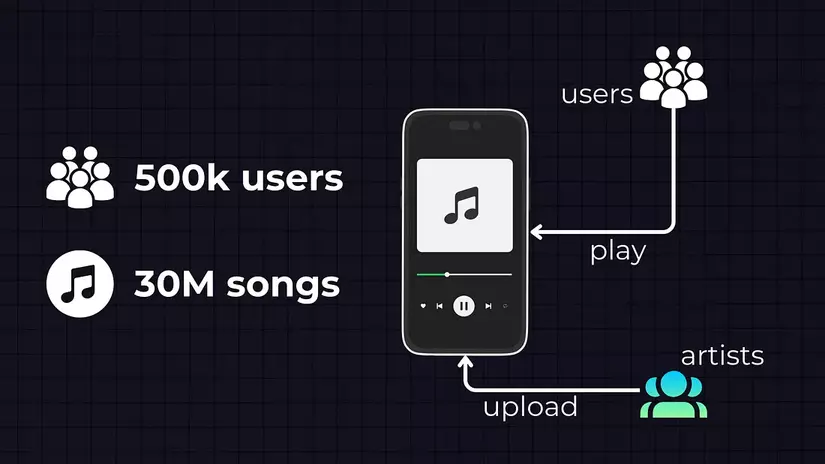
Ước lượng lượng dữ liệu
Bắt đầu bằng cách ước tính lượng lưu trữ mà chúng ta cần. Đầu tiên, chúng ta cần lưu trữ các bài hát trong một loại hình lưu trữ nào đó.
- Lưu trữ bài hát: Spotify hay các dịch vụ tương tự khác thường sử dụng các định dạng như Ogg Vorbis hoặc AAC cho việc phát trực tuyến, và giả sử mỗi bài hát trung bình là 3MB, chúng ta cần 3MB * 30 triệu = 90TB lưu trữ cho các bài hát.
- Metadata của bài hát: Chúng ta cũng cần lưu trữ metadata của bài hát và thông tin hồ sơ người dùng. Kích thước metadata trung bình cho mỗi bài hát là khoảng 100 bytes - 100 bytes * 30 triệu = 3GB
- Metadata của người dùng: Trung bình, chúng ta sẽ lưu trữ 1KB dữ liệu cho mỗi người dùng - 1KB * 500.000 = 0.5GB

Thiết kế tổng quan:
-
Ứng Dụng Di Động: Chúng ta sẽ có một ứng dụng di động, đây là giao diện mà người dùng tương tác với dịch vụ. Người dùng có thể tìm kiếm bài hát, phát nhạc, tạo danh sách phát, v.v. Khi người dùng thực hiện một hành động (như phát một bài hát), ứng dụng sẽ gửi yêu cầu đến các máy chủ.
-
Bộ Cân Bằng Tải: Nhưng trước khi tới được các máy chủ, chúng ta có một bộ cân bằng tải, nó phân phối lưu lượng truy cập đến cho nhiều máy chủ web. Điều này cải thiện khả năng sẵn có và khả năng chịu lỗi của ứng dụng.
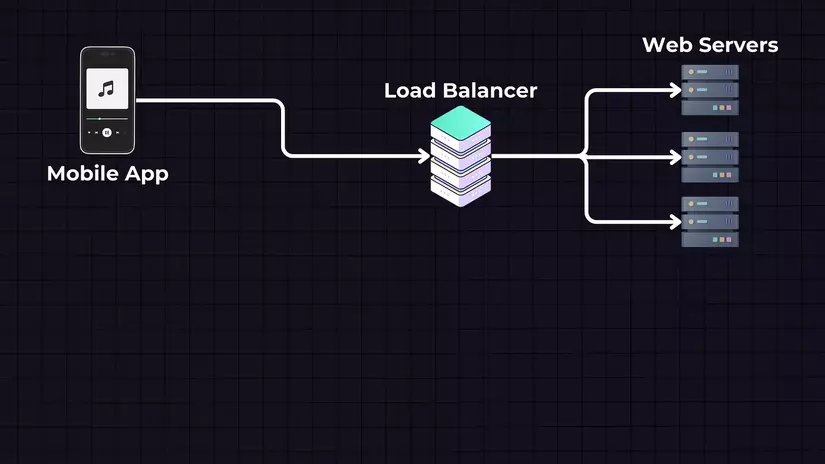
-
Máy Chủ Web (APIs): Các máy chủ web là các API xử lý các yêu cầu đến từ ứng dụng di động. Ví dụ, nếu người dùng muốn phát một bài hát, yêu cầu sẽ được gửi đến các máy chủ web này. Máy chủ sau đó xác định vị trí của bài hát (trong cơ sở dữ liệu hoặc dịch vụ lưu trữ) và cách để truy xuất nó.
Lưu trữ dữ liệu
Lưu trữ dữ liệu sẽ được chia thành hai dịch vụ riêng biệt — Bộ Lưu trữ Blob cho Bài hát, nơi chúng ta sẽ lưu trữ các tệp bài hát thực tế, và SQL Database, nơi chúng ta sẽ lưu trữ metadata bài hát và người dùng.
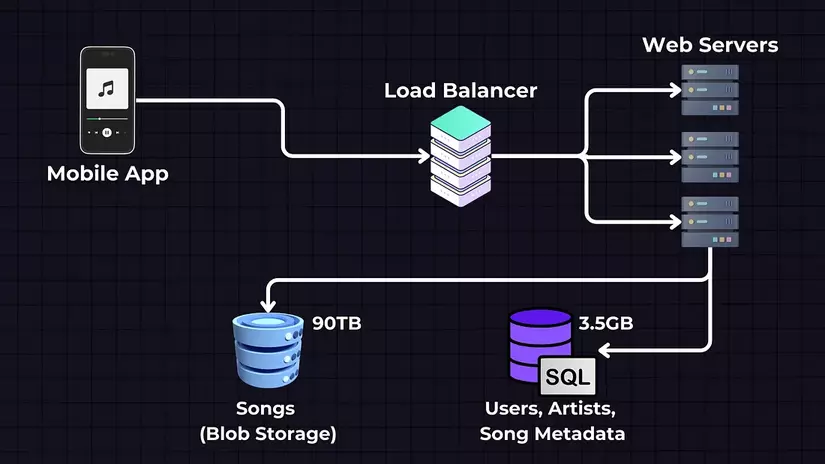
- Bài hát - Blob Storage (ví dụ: AWS S3, GCP, Azure Blob Storage): Các file nhạc thực tế được lưu trữ trong dịch vụ lưu trữ Blob (Binary Large Object). Các dịch vụ này được thiết kế để lưu trữ một lượng lớn dữ liệu phi cấu trúc.
- Người dùng, Nghệ sĩ và Metadata bài hát - Cơ sở dữ liệu SQL: Cơ sở dữ liệu SQL này lưu trữ dữ liệu có cấu trúc như thông tin người dùng (tên đăng nhập, mật khẩu, email) và metadata về bài hát (tên bài hát, tên nghệ sĩ, chi tiết album, v.v.).
Tại sao lại là SQL?
Cơ sở dữ liệu SQL là lựa chọn lý tưởng cho loại dữ liệu có cấu trúc này vì chúng cho phép thực hiện các truy vấn phức tạp và các mối quan hệ giữa các loại dữ liệu khác nhau. Mỗi file nhạc được lưu trữ là một ‘blob’ và cơ sở dữ liệu SQL thường sẽ lưu trữ tham chiếu đến file này (giống như URL).
Cấu trúc cơ sở dữ liệu SQL
Dưới đây là một bản mô tả cơ bản về các bảng và mối quan hệ của chúng mà chúng ta sẽ có trong cơ sở dữ liệu SQL:
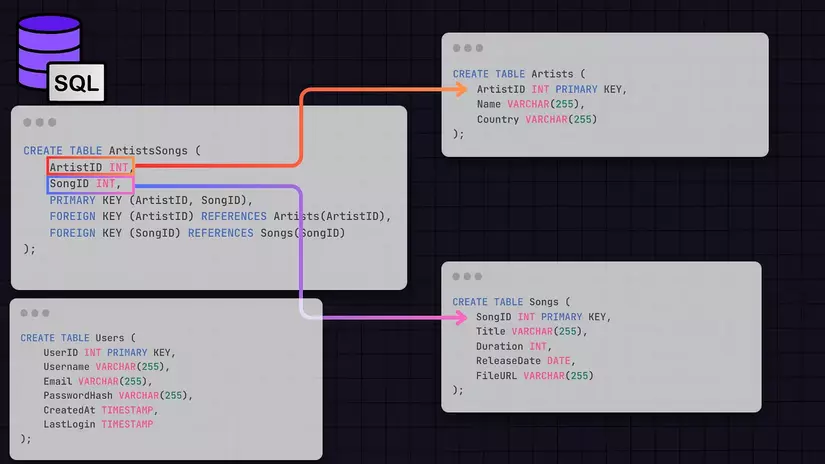
- Bảng Users: Chứa metadata người dùng như UserID, Username, Email, PasswordHash, CreatedAt, LastLogin, v.v.
- Bảng Songs: Lưu trữ thông tin metadata của bài hát, chẳng hạn như SongID, Title, ArtistID, Duration, ReleaseDate và FileURL (đây là URL đến vị trí lưu trữ file nhạc, ví dụ như trong Blob storage).
- Bảng Artists: Chứa thông tin nghệ sĩ - ArtistID, Name, Bio, Country, v.v.
- Các mối quan hệ: Ta có bảng phụ ArtistsSongs (được tạo ra do Artists và Songs là mối quan hệ nhiều-nhiều), nơi chúng ta sẽ có ArtistID (khóa ngoại trỏ đến bảng Artists) và SongID (khóa ngoại trỏ đến bảng Songs). Từ đó, chúng ta có thể lấy được metadata của bài hát, bao gồm cả thuộc tính FileURL, trỏ đến Blob Storage nơi bài hát được lưu trữ.
Ghép mọi thứ lại với nhau
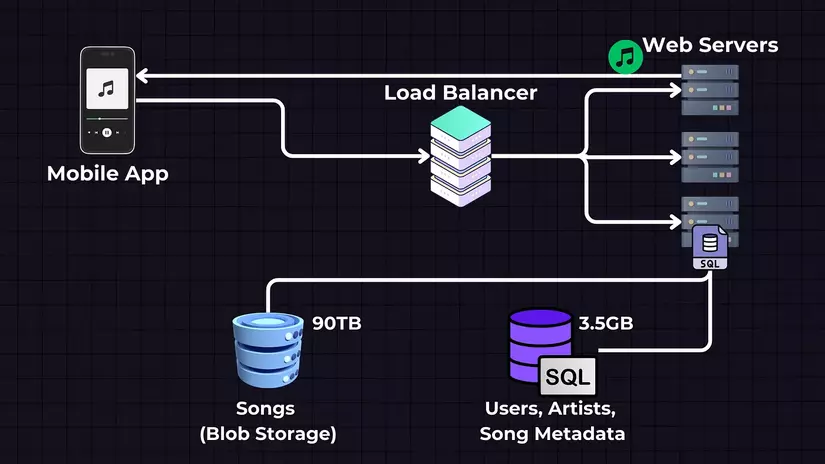
Từ đó ta thấy, máy chủ web sẽ lấy metadata bài hát từ cơ sở dữ liệu SQL, và từ metadata bài hát đó, nó sẽ lấy URL tệp, sau đó các dữ liệu sẽ được phát từ máy chủ theo từng khối (chunk) đến ứng dụng di động.
Giai đoạn mở rộng: 50 triệu người dùng, 200 triệu bài hát
Tính toán lại dữ liệu
Khi chúng ta mở rộng lên đến 50 triệu người dùng và 200 triệu bài hát, chúng ta trước tiên cần tính toán lại dữ liệu. Điều này có nghĩa là cơ sở dữ liệu SQL cần lưu trữ khoảng 200/30 ~ 6.66 lần metadata cho các bài hát: 100 byte cho mỗi bài hát * 200 triệu bài hát = 20GB.
Và tương tự cho metadata người dùng: 1KB cho mỗi người dùng * 50 triệu người dùng = 50GB.

Sự xuất hiện của CDN
Vì lưu lượng truy cập đã tăng lên, chúng ta cần đưa vào sử dụng bộ nhớ đệm và một CDN (như Cloudfront / Cloudflare) sẽ phục vụ các bài hát, và mỗi CDN sẽ được đặt gần với một khu vực nào đó. Do đó, nó có thể phục vụ bài hát nhanh hơn máy chủ web.
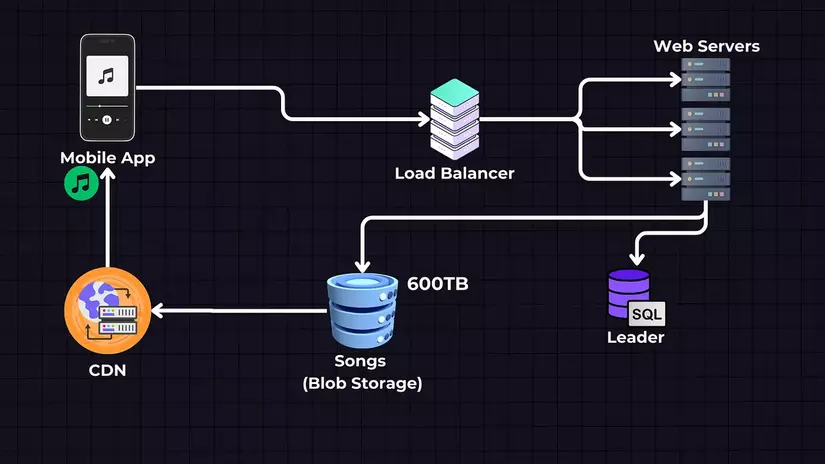
Chúng ta có thể sử dụng LRU (Least Recently Used) để xóa những dữ liệu ít được truy cập gần đây trong bộ nhớ đệm. Bộ nhớ đệm lưu trữ cho các bài hát phổ biến, và các bài hát không phổ biến vẫn sẽ được truy xuất từ lưu trữ Blob và sau đó được lưu vào bộ nhớ đệm trên CDN.
Các tệp bài hát cũng có thể được truyền trực tiếp từ lưu trữ đám mây đến khách hàng, điều này sẽ giảm tải trên các máy chủ web.
Mở rộng cơ sở dữ liệu: Kỹ thuật Leader-Follower
Cơ sở dữ liệu cũng cần được mở rộng. Vì chúng ta biết ứng dụng của mình có nhiều hoạt động đọc hơn ghi, có nghĩa là có nhiều người dùng nghe nhạc hơn là số lượng nghệ sĩ tải lên bài hát — chúng ta có thể sử dụng kỹ thuật Leader → Follower và có một cơ sở dữ liệu Leader sẽ chấp nhận cả đọc và ghi và nhiều cơ sở dữ liệu Follower hoặc Slave chỉ đọc (read-only) để truy xuất metadata bài hát và người dùng.
Nếu cần thiết, chúng ta cũng có thể thực hiện phân mảnh cơ sở dữ liệu và chia nó thành nhiều cơ sở dữ liệu SQL hoặc thực hiện kỹ thuật Leader ↔ Leader.
Và đó là một chuyến thám hiểm hệ hống của sportify. Sydexa hẹn các bạn ở một bài viết thú vị nữa nha 😍😍😍😍
Nếu thấy bài viết này hay thì cho chúng mình xin 1 upvote và comment để chúng mình nhận giải của viblo nha 😄😄😄
Lời nhắn
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com