Có lẽ khái niệm này cũng không quá xa lạ gì với các anh em Engineer và bản thân mình sau 2 năm đầu đi làm và lần đầu tiên nghe về khái niệm này cũng hiểu một cách rất là mơ hồ  . Yeah và dĩ nhiên không để nỗi đau thêm dài (thật ra mình tò mò là chính) nên mình cũng tìm hiểu về cách làm việc của Hash Table và chia sẻ với ae để có cái nhìn sâu sát hơn về Hash Table để ứng dụng vào công việc của mình một cách hiệu quả nhất
. Yeah và dĩ nhiên không để nỗi đau thêm dài (thật ra mình tò mò là chính) nên mình cũng tìm hiểu về cách làm việc của Hash Table và chia sẻ với ae để có cái nhìn sâu sát hơn về Hash Table để ứng dụng vào công việc của mình một cách hiệu quả nhất
Trước tiên mình cũng xin giải thích ngắn gọn: Hash Table là một tập các cặp key-value không theo thứ tự, và mỗi key là duy nhất (unique). Hash table thường được sử dụng để triển khai dữ liệu dạng collection có cấu trúc như Map, Set ... Và có thể dễ nhận thấy trong các ngôn ngữ lập trình phổ biến như Java, C++, Python, Go. Hash table thông thường sẽ có các hoạt động cơ bản bao gồm: tìm kiếm, thêm và xoá. Array hay Linked List sẽ không thể đạt được những điểm sau:
- Tìm kiếm trong một mảng không có thứ tự trong trường hợp xấu nhất sẽ tốn một lượng thời gian tuyến tính với độ dài của mảng đó
- Trong một mảng có thứ tự thì việc tìm kiếm sẽ rất nhanh nếu chúng ta dùng thuật toán tìm kiếm nhị phân (Binary Search) nhưng đánh đổi lại và việc chúng ta thêm một phần tử vào mảng lại không hiệu quả
- Với trường hợp của linked list thì ngược lại việc thêm/xoá một phần tử khá đơn giản nhưng việc tìm kiếm cũng tốn thời gian giống như trường hợp của mảng không có thứ tự
Và dựa trên đặc tính đó, hash table sử dụng một chuỗi các Linked List để giải quyết vấn đề đụng độ dữ liệu. Anh chàng Hash Table là đúc kết từ những điểm mạnh của Array và Linked List  Cách hoạt động của Hash Table sẽ bao gồm 2 bước:
Cách hoạt động của Hash Table sẽ bao gồm 2 bước:
- Key sẽ được chuyển đổi thành chỉ mục (index) dạng số bằng cách sử dụng hàm băm
- Chỉ mục này sẽ quyết định Linked List nào sẽ chứa cặp key-value tương ứng
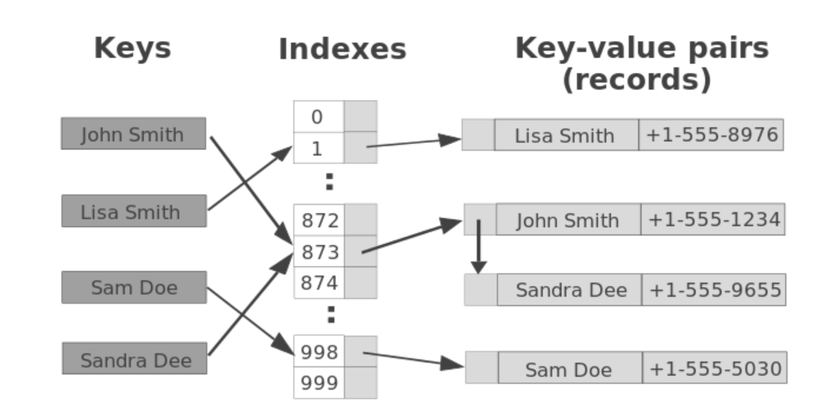
Để dễ hình dung hơn chúng ta cùng xem 1 ví dụ đơn giản sau. Chúng ta sẽ có cấu trúc dữ liệu chứa đến 1000 records với khoá là một số integer ngẫu nhiên. Và để phân bổ data một cách đồng đều, chúng ta sẽ dùng nhiều short list. Với tất cả các record có khoá kết thúc bằng 000 sẽ thuộc 1 list VD: 1000, 2000, 3000 .... tất cả các record có khoá kết thúc bằng 001 sẽ thuộc 1 list khác VD: 1001, 2001 ... và cứ tiếp tục như vậy chúng ta có 1000 list theo cách chia như trên. Và có thể triển khai dưới mặt coding như sau:
var table = new LinkedList[1000]
Ở đây LinkedList biểu diễn cho danh sách các cặp key-value có liên kết với nhau. Việc chúng ta thêm 1 record key-value bao gồm 2 bước:
- Chúng ta trích xuất 3 chữ số cuối của key
hash = key % 1000 - Sau đó chúng ta thêm cặp key-value này vào
table[hash]
hash = key % 1000
table[hash].AddFirst(key, value)
Hành động trên luôn tốn một lượng thời gian không đổi. Và việc chúng ta tìm kiếm sẽ như sau
value = table[key%1000].Find(key)
Bởi vì các khoá của 1 cặp key-value là ngẫu nhiên nên ta có thể xem số lượng record trong mỗi list là gần như nhau. Và vì chúng ta có 1000 list và nhiều nhất là 1000 record thế nên sẽ rất ít record trong 1 list table[key%1000] và dĩ nhiên việc tìm kiếm sẽ rất nhanh.
Ae có thể thấy Time Complexity (mức độ phức tạp đánh giá theo thời gian) của việc tìm kiếm và thêm mới là O(1). Cũng giống với cách hoạt động trên thì việc xoá cũng tốn một khoản thời gian không đổi
Thông qua ví dụ trên chúng ta cũng thấy việc Hash Table kết hợp cả Array và Linked List để lưu trữ dữ liệu như thế nào. Trong bài tiếp theo chúng ta sẽ đi sâu hơn để tìm hiểu các ví dụ mang tính thực tế hơn về Hash Table và khái niệm Amortized Constant Time Performance
Mình xin cảm ơn các bạn đã dành thời gian đọc bài chia sẻ này và mong nhận được feedback cũng như những chia sẻ đóng góp của anh em. Chúc anh em một cái tết vui vẻ bên gia đình và nhớ giữ gìn sức khoẻ trong thời điểm COVID vẫn đang còn phức tạp  Happy New Year!!!
Happy New Year!!!