Phần lớn các ứng dụng trong NLP như machine translation (dịch máy), chatbots, text summarization (tóm tắt văn bản), và language models(mô hình ngôn ngữ) có output là sinh ra văn bản. Bên cạnh đó, các tác vụ như image captioning (sinh chú thích cho bức ảnh) hay automatic speech recognition (tự động nhận dạng giọng nói) cũng có output là văn bản, mặc dù chúng không phải là các ứng dụng NLP thông thường.
Vậy độ tốt của các output như thế nào?
Vấn đề chung khi huấn luyện các task như thế này là cách làm sao để chúng ta xác định độ tốt của đầu ra? Với ứng dụng như image classification, predicted class có thể được so sánh 1 cách rõ ràng với target class để xác định xem output có đúng hay không. Tuy nhiên, vấn đề này khó hơn nhiều với bài toán khi output là 1 câu văn.
Trong những trường hợp như này chúng ta không có 1 output chính xác duy nhất mà có thể có nhiều hơn 1 output chính xác. Khi dịch 1 câu văn, ví dụ, 2 người sẽ có 2 cách dịch khác nhau và cả 2 cách đều đúng.
eg. "The ball is blue” and “The ball has a blue color”.
Vấn đề còn trở nên phức tạp hơn với bài toán như image captioning hay text summarization, khi độ dài của output là lớn hơn rất nhiều.

Để giải quyết những bài toán có output như trên, chúng ta cần 1 metric để evaluate chất lượng output. Trong bài này, chúng ta sẽ tìm hiểu 2 metric thường xuyên được sử dụng cho những bài toán này.
NLP Metrics
1. BLEU Score
Có rất nhiều NLP metrics được nghiên cứu để giải quyết vấn đề này, 1 trong những cái phổ biến nhất là Bleu Score. Nó khá dễ hiểu và đơn giản để tính toán. Nó dựa vào cơ sở rằng nếu predict sentence càng giống với human target sentence thì càng tốt.
Bleu Score có giá trị trong khoảng 0 đến 1. Mức độ 0.6 hoặc 0.7 đã được coi như là tốt. Kể cả với 2 người dịch kết quả giống nhau thì cũng rất ít khi đạt được 1. Vì thế, nếu đạt được điểm gần với 1 thì khả năng cao là mô hình đã bị overfitting.
Trước khi tìm hiểu cách tính Bleu Score, đầu tiên hãy tìm hiểu 2 khái niệm N-grams và Precision trước.
a) N-gram
N-gram là tần suất xuất hiện của n kí tự(hoặc từ) liên tiếp nhau có trong tập corpus. Một số mô hình n-grams phổ biến, ví dụ với câu đầu vào "The ball is blue":
- 1-gram (unigram): "The", "ball", "is", "blue"
- 2-gram (bigram): "The ball", "ball is", "is blue"
- 3-gram (trigram): "The ball is", "ball is blue"
- 4-gram: "The ball is blue"
Mô hình N-gram:
-
Để tính xác suất xuất hiện của 1 câu , ta sẽ tách thành tích các xác suất và sử dụng chain rule of probability:
-
Áp dụng chain rule, ta có:
-
Trong đó:
Một số cách làm mịn phổ biến:
- Discounting: giảm xác suất các cụm n-grams có xác suất lớn hơn 0 để bù cho các cụm n-grams chưa xuất hiện.
- Backoff: tính xác suất các cụm n-gram chưa xuất hiện bằng các cụm ngắn hơn và có xác suất lớn hơn 0.
- Interpolation: tính xác suất của tất cả các cụm n-gram bằng các cụm ngắn hơn.
b) Precision
Metric đo bằng số lượng từ ở trong predicted sentence mà cũng xuất hiện ở trong target sentence.
Ví dụ, ta có câu đầu vào:
- Target Sentence: He eats an apple.
- Predicted Sentence: He ate an apple.
Khi đó Precision sẽ được tính như sau:
Precision = Number of correct predicted words / Number of total predicted words
Precision = 3 / 4
Nhưng sử dụng Precision là không đủ tốt. Có 2 trường hợp nữa chúng ta cần xử lý
Repetition
Đây là vấn đề đầu tiên mà công thức ở trên cho phép chúng ta "qua mặt". Ví dụ với output:
- Target Sentence: He eats an apple.
- Predicted Sentence: He He He.
Khi đó Precision = 3 / 3 = 1.
Clipped Precision
Lấy 1 ví dụ để hiểu cách hoạt động. Giả sử chúng ta có các câu sau:
- Target Sentence 1: He eats a sweet apple.
- Target Sentence 2: He is eating a tasty apple.
- Predicted Sentence: He He He eats tasty fruit.
Bây giờ ta sẽ thực hiện các bước sau:
- So sánh mỗi từ ở trong predicted sentence với toàn bộ target sentence. Nếu có từ nào match với target sentence, xem như dự đoán đúng.
- Giới hạn số lượng cho mỗi từ về số lần nhiều nhất mà từ đấy xuất hiện ở target sentence. Điều này giúp tránh hiện tượng Repetition. Ta có bảng sau:
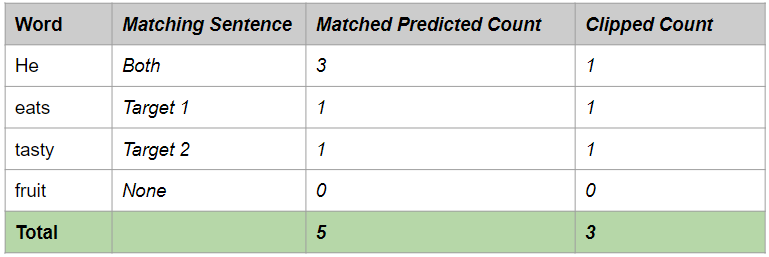
Ví dụ, từ "He" chỉ xuất hiện 1 lần trong Target Sentence. Vì thế, dù từ "He" xuất hiện 3 lần ở trong Predicted Sentence, chúng ta clip về 1, như là số lần xuất hiện tối đa trong Target Sentence.
Clipped Precision = Clipped number of correct predicted words / Number of total predicted words
Clipped Precision = 3 / 6
c) Cách tính BLEU Score
Giả sử chúng ta có 1 mô hình NLP mà sinh predicted sentence như dưới đây. Để đơn giản, chúng ta chỉ lấy 1 Target Sentence, dù trên thực tế có rất nhiều Target Sentence mang nghĩa như nhau.
- Target Sentence: The guard arrived late because it was raining.
- Predicted Sentence: The guard arrived late because of the rain.
Bước đầu tiên ta sẽ tính Precision Score cho 1-gram đến 4-gram
Precision 1-gram
Ta sử dụng phương pháp Clipped Precision vừa đề cập ở trên.
Precision 1-gram = Number of correct predicted 1-grams / Number of total predicted 1-grams

Do đó, Precision 1-gram = 5 / 8
Precision 2-gram
Precision 2-gram = Number of correct predicted 2-grams / Number of total predicted 2-grams

Do đó, Precision 2-gram = 4 / 7
Precision 3-gram
Tương tự, Precision 3-gram = 3 / 6
Precision 4-gram
Và cuối cùng, Precision 4-gram = 2 / 5
Geometric Average Precision Scores
Tiếp theo, chúng ta kết hợp các Precision Score sử dụng công thức dưới đây. Cái này có thể tính toán cho các N khác nhau và các giá trị weight khác nhau. Cụ thể, ta cho N = 4 và uniform weights = N / 4.
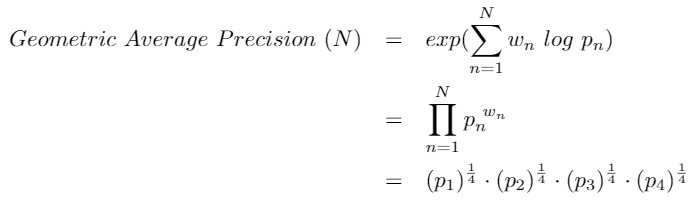
Brevity Penalty
Bước thứ 3 là tính "Brevity Penalty".
Nếu để ý cách Precision được tính toán, có thể thấy rằng output có predicted sentence chứ các từ đơn như "The" hay "late". Khi đó, 1-gram Precision sẽ là 1/1 = 1, perfect score. Điều này là sai vì nó khuyến khích model sinh đầu ra ngắn hơn và điểm cao hơn.
Do đó, Brevity Penalty penalize những câu trả lời quá ngắn.
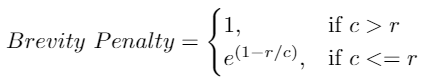
- c là predicted length = số lượng từ có trong predicted sentence
- r là target length = số lượng từ có trong target sentence
Công thức trên đảm bảo rằng Brevity Penalty không thể lớn hơn 1, cho dù predicted sentence ngắn hơn nhiều so với target sentence. Và nếu model predict rất ít từ, giá trị này sẽ càng nhỏ.
Trong ví dụ trên, c = 8 và r = 8, do đó giá trị Brevity Penalty = 1.
BLEU Score
Cuối cùng, để tính Bleu Score, ta nhân Brevity Penalty với Geometric Average of Precision Scores.
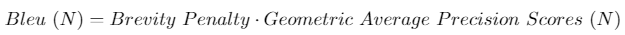
Bleu Score có thể tính toán cho nhiều giá trị N khác nhau. Cụ thể trong trường hợp này, ta xét N = 4.
- BLEU-1 sử dụng unigram Precision Score.
- BLEU-2 sử dụng geometric average of unigram and bigram Precision Score.
- BLEU-3 sử dụng geometric average of unigram, bigram, and trigram Precision Score.
- Và cứ tiếp tục như thế cho đến BLEU-N.
Với 1 số nguồn khác, hàm Bleu Score có thể được viết lại như sau:
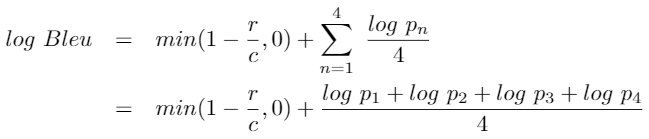
Implementing Bleu Score
from nltk.translate.bleu_score import corpus_bleu references = [[['my', 'first', 'correct', 'sentence'], ['my', 'second', 'valid', 'sentence']]]
candidates = [['my', 'sentence']]
score = corpus_bleu(references, candidates)
2. WER - Word Error Rate
Mặc dù Automatic Speech Recognition (ASR) model cũng có output là văn bản, target sentence là rõ ràng. Khi đó, metric Bleu Score không phải là 1 metric tốt.
Metric thường được sử dụng cho bài toán này là Word Error Rate (WER) hoặc là Character Error Rate (CER). Nó so sánh predicted output và target transcript, giữa từ với từ (hoặc giữa kí tự với kí tự) để tìm ra sự khác biệt giữa 2 câu.
Sự khác biệt giữa 2 câu có thể có từ xuất hiện trong transcript nhưng không có trong prediction (được tính như là Deletion), 1 từ không có trong transcript nhưng lại được thêm vào prediction (coi như là Insertion), hoặc 1 từ được thay thế giữa prediction và transcript (xem như là Substitution).
Công thức tính metric khá là dễ hiểu và sử dụng. Nó tính tỉ lệ phần số từ sự khác biệt giữa transcript và prediction.

Mặc dù WER là 1 metric được sử dụng phần lớn cho Speech Recognition, nó có 1 số nhược điểm như sau:
- Nó không thể phân biệt được giữa các từ quan trọng có ý nghĩa trong câu và các từ không liên quan.
- Khi so sánh các từ với nhau, nó không xem xét đến khả năng nếu 2 từ chỉ khác nhau 1 kí tự hay khác nhau hoàn toàn.
Hàm WER đã có sẵn trên thư viện HuggingFace. Chỉ với vài dòng code bạn đã có thể gọi hàm này và sử dụng.
from datasets import load_metric
metric = load_metric("wer")
3. Conclusion
Đây là bài viết đầu tiên của mình trên Viblo sẽ không tránh khỏi sai sót. Nếu bạn thấy có ích, hãy để lại cho mình 1 lượt upvote nhé. Có câu hỏi gì mọi người cứ cmt vào dưới bài viết, mình sẽ cố gắng trả lời ạ.
Cảm ơn mọi người rất nhiều!!!