Trước khi vào bài, hãy cùng xem qua những RAD-NeRF có thể làm được:
Lưu ý: bài đọc yêu cầu cần có kiến thức về NeRF, mọi người hãy đọc phần 1 ở đây để hiểu rõ hơn nhé!
Từ một video duy nhất, RAD-NeRF có thể tổng hợp được mô hình người có thể nói gần như bất kỳ từ hoặc câu nào trong thời gian thực với chất lượng khá tốt. Chúng ta có thể tạo hoạt ảnh cho phần đầu nói theo bất kỳ bản âm thanh nào trong thời gian thực. Điều này vừa tuyệt vời vừa đáng sợ đúng không?
Hãy tưởng tượng xem điều gì có thể xảy ra nếu mình có thể khiến bạn nói bất cứ điều gì chỉ với 1 video bạn nói trước ống kính trong 5 phút. Hoặc như với VASA-1 của nhóm Microsoft Research mới công bố gần đây gần dây, thậm chí họ chỉ cần một bức ảnh. Chỉ cần thông tin về gương mặt của chúng ta xuất hiện trên mạng xã hội, bất kỳ ai cũng có thể sử dụng mô hình này và tạo ra vô số video quay cảnh bạn nói về bất cứ điều gì họ muốn. Họ thậm chí có thể tổ chức các buổi phát trực tiếp bằng phương pháp này, điều này thậm chí còn nguy hiểm hơn😀.
Quay lại chủ đề chính, làm cách nào họ có thể làm điều đó trong thời gian thực từ bất kỳ âm thanh nào chỉ bằng một video …
1.Bối cảnh chung

Như nhóm tác giả đã công bố, mô hình RAD-NeRF của họ có thể chạy nhanh hơn 500 lần so với các sản phẩm trước đó với chất lượng hiển thị tốt hơn và khả năng kiểm soát tốt hơn. Làm thế nào điều đó có thể xảy ra? Chúng ta thường đánh đổi chất lượng để lấy hiệu quả, nhưng họ đã cải thiện được cả hai điều đó một cách đáng kinh ngạc. Hãy cùng tìm hiểu nhé.
RAD-NeRF sử dụng mạng nơ ron để dự đoán tất cả màu sắc và mật độ điểm ảnh cho góc nhìn của camera đang được hiển thị. Việc này được thực hiện cho tất cả các góc nhìn mà bạn muốn hiển thị khi camera xoay quanh đối tượng. Việc này đòi hỏi rất nhiều tính toán vì tại mỗi góc nhìn phải học cách dự đoán nhiều góc nhìn khác và các thông số cho từng tọa độ trong ảnh. Ngoài ra, trong trường hợp này, không chỉ NeRF mới tạo ra cảnh 3D. Âm thanh đầu vào cũng phải khớp sao cho môi, miệng, mắt và chuyển động khớp với những gì người đó đang nói. Tức là chúng ta phải tổng hợp trong không gian động.
Các vấn đề chính khi chuyển từ tĩnh sang động
Làm cách nào để RAD-NeRF thể hiện hiệu quả thông tin không gian và giọng nói cùng một lúc?
-
Các đặc trưng âm thanh thường được mã hóa thành vectơ 64 chiều và sau đó được đưa vào MLP chứa tọa độ không gian 3D để dùng training. Tuy nhiên, khi chúng ta cố gắng thêm nhiều chiều hơn (chẳng hạn như âm thanh) vào mô hình NeRF, chúng ta có thể gặp phải vấn đề tăng số lượng tham số theo cấp số nhân. Điều này là do mỗi chiều bổ sung sẽ nhân đôi số lượng điểm dữ liệu mà chúng ta cần để nội suy trong không gian.
-
Ví dụ: trong không gian 2D, nếu bạn muốn có 10 điểm nội suy theo mỗi hướng thì bạn sẽ cần tổng cộng 100 điểm dữ liệu. Nhưng nếu bạn muốn làm điều tương tự trong không gian ba chiều thì bạn cần 1.000 điểm dữ liệu. Điều này có nghĩa là khi chúng ta thêm nhiều chiều hơn, lượng dữ liệu cần được nội suy và xử lý sẽ tăng lên nhanh chóng. Điều này không chỉ làm tăng đáng kể các yêu cầu tính toán mà còn có thể vượt quá khả năng của phần cứng hiện có.
-
Ngoài ra, nội suy trong không gian nhiều chiều cũng gặp phải các thách thức khác: ví dụ, vấn đề “Curse”. “Curse” chỉ ra rằng, trong không gian chiều cao, dữ liệu trở nên thưa thớt, điều này làm cho việc sử dụng phương pháp thống kê hoặc học máy trở nên rất khó khăn.
Việc mô phỏng hiệu quả chuyển động của cơ thể cũng khó khăn. Các phương pháp trước đây hoặc sử dụng NERF đều tốn kém và phức tạp.
Tác giả giải quyết như thế nào?
-
Paper này đề xuất một phương pháp giải quyết không gian âm thanh, cho phép đào tạo và suy luận theo thời gian thực hiệu quả.
-
Tác giả đã tận dụng cách biểu diễn NeRF dựa trên lưới, đưa khả năng mô hình hóa cảnh tĩnh xuất sắc của nó vào mô hình hóa cảnh động do âm thanh điều khiển.
-
Điểm đóng góp chính của paper là việc phân tích các đặc điểm của chân dung nói (talking portrait) thành ba lưới đặc trưng (feature grid) có thể học được với kích thước mô hình nhỏ. Để mô hình hóa phần đầu, tác giả đã phân tách và biểu diễn thành hai lưới đặc trưng, mặc dù tọa độ không gian 3D vẫn không đổi, nhưng chuyển động của âm thanh được mã hóa vào các tọa độ kích thước thấp. Ngoài ra, tác giả còn chứng minh rằng có thể chia thành hai lưới đặc trưng có kích thước thấp riêng biệt thay vì truy vấn âm thanh và tọa độ không gian trong một lưới đặc trưng kích thước cao hơn, điều này làm giảm thêm chi phí nội suy, và giúp mô hình phần đầu nói chuyện hiệu quả hơn.
-
Về phần cơ thể, tác giả nhận thấy rằng chuyển động của cơ thể ít thay đổi hơn, do đó đề xuất một model nhẹ để mô hình hóa cơ thể bằng lưới đặc trưng 2D.
Grid-based NeRF (NeRF dựa trên lưới):
- NeRF mô hình hóa màu sắc và mật độ của các điểm trong không gian ba chiều, từ đó có thể render hình ảnh 2D chân thực từ bất kỳ góc độ nào.
- Grid-based NeRF là một cải tiến của phương pháp NeRF truyền thống. Trong NeRF truyền thống, mạng nơ-ron sẽ gán một giá trị màu sắc và mật độ cho mỗi điểm trong không gian 3D. Tuy nhiên, phương pháp này có thể gặp phải vấn đề về giới hạn bộ nhớ khi xử lý các cảnh quy mô lớn.
- Grid-based NeRF giải quyết vấn đề này. Nó chia không gian 3D thành một lưới và chỉ đánh giá mạng nơ-ron tại các đỉnh lưới, từ đó tối ưu hóa việc sử dụng bộ nhớ. Sau đó, sử dụng kỹ thuật nội suy để lấy giá trị màu sắc và mật độ tại các vị trí giữa các đỉnh lưới. Điều này cho phép xử lý các cảnh quy mô lớn hơn trong khi vẫn giữ được độ chính xác cao.
Tóm lại các điểm khác biệt chính của NeRF dựa trên lưới:
- Sử dụng bộ nhớ: Grid-based NeRF tối ưu hóa việc sử dụng bộ nhớ, cho phép xử lý các cảnh quy mô lớn hơn.
- Hiệu quả tính toán: Do chỉ cần đánh giá mạng nơ-ron tại các đỉnh lưới và sử dụng kỹ thuật nội suy để lấy thông tin vị trí khác, Grid-based NeRF đã cải thiện hiệu quả tính toán.
- Độ chính xác: Mặc dù sử dụng phương pháp đơn giản hóa, Grid-based NeRF vẫn có thể duy trì độ chính xác cao trong nhiều ứng dụng.
2.Phương pháp
2.1 Một số khái niệm cần biết
1. NeRF
NeRF sử dụng tọa độ 5 chiều để biểu diễn cảnh 3D, tức là một hàm 𝐹 : 𝑥 , 𝑑 → 𝜎 , 𝑐 . Giả sử một tia phát ra từ o, di chuyển theo hướng d, thì tại các điểm lấy mẫu tuần tự dọc theo tia , hàm 𝐹 sẽ được dùng để tính mật độ và màu sắc.
- NeRF động:
So với cảnh tĩnh, cảnh động sẽ bổ sung thêm một số điều kiện, chẳng hạn như thời điểm hiện tại t.
Có hai giải pháp chính cho các phương pháp trước đó:
1: Sử dụng phương pháp cơ sở biến dạng để tìm hiểu biến dạng và bước thời gian tại mỗi vị trí, sau đó thêm chúng vào vị trí. Tuy nhiên, loại phương pháp này không phù hợp với mô hình chuyển động cục bộ, chẳng hạn như chuyển động của môi. Nhưng nó có thể được sử dụng để làm mẫu cho vai. 2: Sử dụng phương pháp dựa trên Điều chế để đưa trực tiếp thời gian t vào NeRF và huấn luyện cùng với vị trí và hướng. Phương pháp này có thể được sử dụng để mô hình hóa phần đầu.
2. Dynamic NeRF:
Cảnh động so với cảnh tĩnh sẽ tăng thêm một số điều kiện bổ sung, chẳng hạn như thời gian hiện tại
Các phương pháp trước đây chủ yếu có hai cách giải quyết:
-
Sử dụng phương pháp dựa trên biến dạng (deformation-based) để học một biến dạng và bước thời gian tại mỗi vị trí, sau đó thêm vào vị trí. Tuy nhiên, phương pháp này không phù hợp cho việc mô hình hóa chuyển động cục bộ, như chuyển động của môi. Nhưng có thể dùng để mô hình hóa chuyển động của vai.
-
Sử dụng phương pháp dựa trên điều biến (modulation-based), trực tiếp đưa thời gian t vào NeRF, và huấn luyện cùng với vị trí, hướng. Phương pháp này có thể được sử dụng để mô hình hóa chuyển động của đầu.
**3. Chuẩn bị dữ liệu
Định dạng chung của dữ liệu tổng hợp chân dung người nói chuyện thường là như sau:
Thông thường sử dụng video của một cảnh cố định, được quay trong 3-5 phút với âm thanh liên tục. Sau đó video được tách thành video và âm thanh và được xử lý riêng.
Xử lý từng khung hình:
- Thực hiện cho các vùng đầu, cổ, thân và nền.
- Trích xuất các đặc trưng khuôn mặt 2D, bao gồm các đặc trưng của mắt và môi.
- Thực hiện face-tracking (theo dõi khuôn mặt) để ước lượng các tham số tư thế đầu.
Xử lý âm thanh:
Sử dụng mô hình Nhận dạng Giọng nói Tự động (Automatic Speech Recognition - ASR) để trích xuất các đặc trưng âm thanh. Các đặc trưng này sẽ được sử dụng để đồng bộ hóa chuyển động của môi và biểu cảm khuôn mặt với giọng nói trong video, tạo ra một video nói chuyện chân thực.
Dữ liệu sau khi chuẩn bị thành công mọi người có thể tham khảo tại link này:
4. Grid-based NeRF
NeRF dựa trên lưới (Grid-based NeRF) sử dụng bộ mã hóa lưới đặc trưng 3D để mã hóa thông tin không gian 3D của cảnh tĩnh.
Bộ mã hóa lưới đặc trưng 3D:
Công thức:
- là bộ mã hóa lưới đặc trưng 3D.
- là đặc trưng không gian 3D sau khi mã hóa
- là tọa độ trong không gian 3D ban đầu.
Quá trình xử lý này có thể tăng tốc quá trình đào tạo và suy luận, giúp xử lý cảnh 3D trong thời gian thực.
2.2 Decomposed audio-spatial encoding module (Mô-đun mã hóa audio-không gian tách biệt)
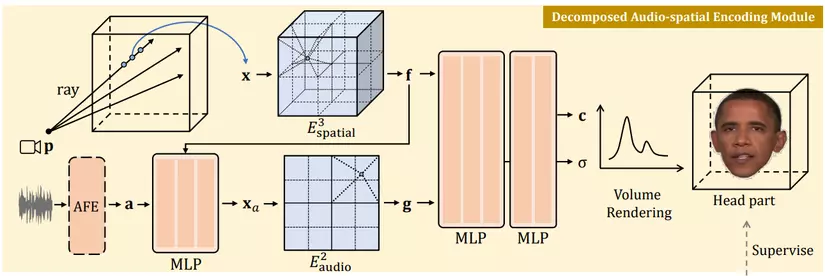
Phương pháp NeRF ẩn trước đây thường mã hóa tín hiệu âm thanh trực tiếp vào các đặc trưng, sau đó kết hợp với các đặc trưng không gian có nhiều chiều. Tuy nhiên, cách này đối với NeRF dựa trên lưới thì rất tốn kém như đã giải thích ở trên, vì vậy tác giả của bài báo này đã đề xuất cách tiếp cận khác
Đầu tiên, nén các đặc trưng âm thanh cao chiều thành tọa độ âm thanh thấp chiều , với rất nhỏ. Cách thực hiện là sử dụng:
Sau đó, mã hóa lưới audio-không gian được tách thành hai bộ mã hóa lưới để mã hóa riêng biệt audio và không gian, rồi kết hợp chúng lại.
Điều này làm giảm chi phí nội suy từ xuống với
- : Đây là bộ mã hóa lưới đặc trưng không gian 3D, mã hóa thông tin không gian từ tọa độ không gian 3D thành đặc trưng không gian
- : Đây là bộ mã hóa lưới đặc trưng âm thanh D chiều, mã hóa thông tin âm thanh từ tọa độ âm thanh thấp chiều thành đặc trưng âm thanh .
Việc tách biệt này giúp giảm đáng kể chi phí nội suy, đặc biệt là đối với các cảnh 3D.