Giới thiệu
Với sự ra đời của cơ chế attention thì vào năm 2017 paper Attention is all you need đã giới thiệu một kiến trúc mới dành cho các bài toán NLP mà không có sự xuất hiện của các mạng nơ-ron hồi tiếp (RNN, LSTM,...) hay là mạng nơ-rơn tích chập (CNN) - đó là Transformer. Như đã giới thiệu ở bài viết trước, trong các bài toán seq2seq các cấu trúc RNN hay LSTM đều có những hạn chế nhất định thì mô hình transformer đã khắc phục được những nhược điểm đó, khi giúp cho quá trình huấn luyện nhanh hơn và kết quả đạt được cũng tốt hơn. Hiện nay, transformer đã được phát triển thành nhiều biến thể khác nhau không chỉ phục vụ cho các bài toán seq2seq mà còn cho các mô hình ngôn ngữ (language modeling).
Bảng dưới đây sẽ thể hiện sự khác biệt của transformer với các mô hình trước đó, khi transformer hoàn toàn hoạt động dựa trên cơ chế attention!
| seq2seq | seq2seq với attention | transformer | |
|---|---|---|---|
| encoder | RNN/CNN | RNN/CNN | attention |
| decoder | RNN/CNN | RNN/CNN | attention |
| tương tác giữa encoder và decoder | vector | attention | attention |
Cụ thể hơn một chút, thì ta sẽ hiểu tại sao transformer lại mang lại sự hiệu quả tốt hơn RNN. Đối với quá trính encode một câu thì RNNs sẽ cần một khoảng thời gian để đọc lần lượt từng từ trong câu, đối với 1 câu dài quá trình này có thể diễn ra khá lâu, như vậy độ phức tạp của encoder để xử lí một câu có độ dài N là O(N). Ngược lại, trong quá trình encode của transformer, các source tokens sẽ "quan sát" nhau (cơ chế self attention) và cố gắng hiểu nhau trong ngữ cảnh của câu. Và độ phức tạp của quá trình này chỉ là O(1).
Cơ chế Self Attention
Có thể khẳng định rằng self -attention chính là thành phần quan trọng nhất của transformer. Sự khác biệt là, trong khi cơ chế attention sẽ tính toán dựa trên trạng thái của decoder ở time-step hiện tại và tất cả các trạng thái ẩn của encoder. Còn self-attention có thể hiểu là attention trong một câu, khi từng thành phần trong câu sẽ tương tác với nhau. Từng token sẽ "quan sát" các tokens còn lại trong, thu thập ngữ cảnh của câu và cập nhập vector biểu diễn.
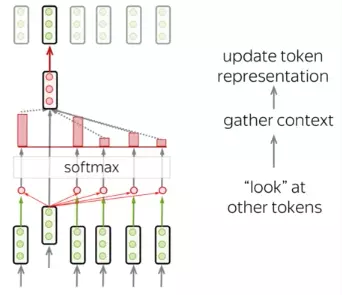
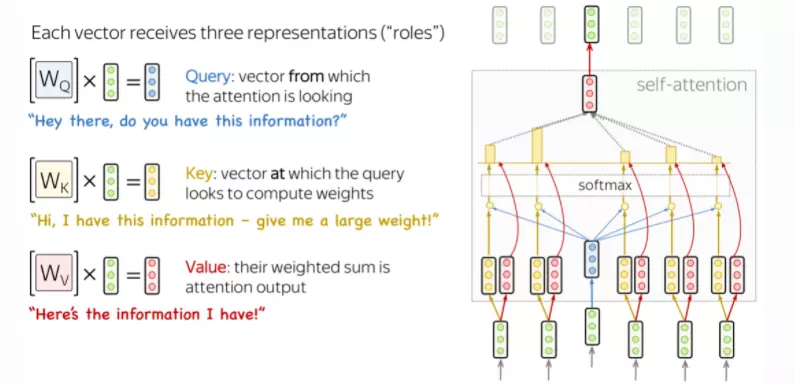
Để xây dựng cơ chế self attention ta cần chú ý đến hoạt động của 3 vector biểu diễn cho mỗi từ lần lượt là:
- Query: hỏi thông tin
- Key: trả lời rằng nó có một số thông tin
- Value: trả về thông tin đó
Query được sử dụng khi một token "quan sát" những tokens còn lại, nó sẽ tìm kiếm thông tin xung quanh để hiểu được ngữ cảnh và mối quan hệ của nó với các tokens còn lại. Key sẽ phản hồi yêu cầu của Query và được sử dụng để tính trọng số attention. Cuối cùng, Value được sử dụng trọng số attention vừa rồi để tính ra vector đại diện (attention vector). Trong ảnh 3 ma trận , và chính là các hệ số mà mô hình cần huấn luyện.
Biểu thức để tính attention vector như sau:
Với là số chiều của vector Key với mục đích tránh tràn luồng!
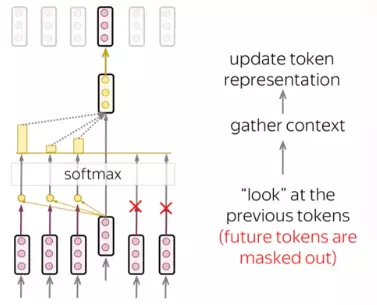
Cơ chế Masked Self Attention
Đây là cơ chế được sử dụng cho decoder trong transformer, cụ thể nó thực hiện nhiệm vụ chỉ cho phép target token tại time-step hiện tại chỉ được phép dùng các tokens ở time-step trước đó. Về hoạt động nó cũng giống như đã giới thiệu ở trên, ngoại trừ việc nó không tính đến attention của những tokens trong tương lai.
Multi-Head Attention
Thông thường, để có thể hiểu được vai trò của một từ trong một câu ta cần hiều được sự liên quan giữa từ đó và các thành phần còn lại trong câu. Điều này rất quan trọng trong quá trình xử lí câu đầu vào ở ngôn ngữ A và cả trong quá trình tạo ra câu ở ngôn ngữ B. Vì vậy, mô hình cần phải tập trung vào nhiều thứ khác nhau, cụ thể là thay vì chỉ có một cơ chế self attention như đã giới thiệu hay còn gọi là 1 "head" thì mô hình sẽ có nhiều "heads" mỗi head sẽ tập trung vào khía cạnh về sự liên quan giữa từ và các thành phần còn lại. Đó chính là multi-head attention.
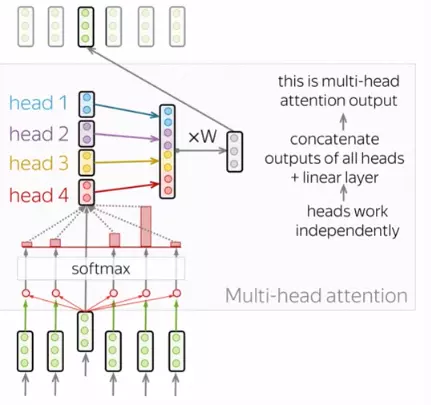
Khi triển khai, ta cần dựa vào query, key và value để tính toán cho từng head. Sau đó ta sẽ concat các ma trận thu được để thu được ma trận của multi-head attention. Để có đầu ra có cùng kích thước của đầu vào thì cần nhân với ma trận .
Kiến trúc của Transformer
Tiếp theo ta sẽ đi tìm hiểu về các thành phần chính cấu tạo nên transformer. Đây là cấu trúc của transformer được giới thiệu trong bài báo "Attention is all you need". Mô hình thực hiện chính xác những gì đã được giới thiệu ở trên. Ở bên trái là encoder, thông thường có Nx = 6 layers chồng lên nhau. Mỗi layer sẽ có multi-head attention như đã tìm hiểu và khối feed-forward. Ngoài ra còn các các kết nối residual giống như trong mạng Resnet. Ở bên phải là decoder, tương tự cũng có Nx = 6 layers chồng lên nhau. Kiến trúc thì khá giống encoder những chỉ có thên khối masked multi-head attention ở vị trí đầu tiên. Ta sẽ tìm hiểu sâu hơn các thành phần trong transformer.
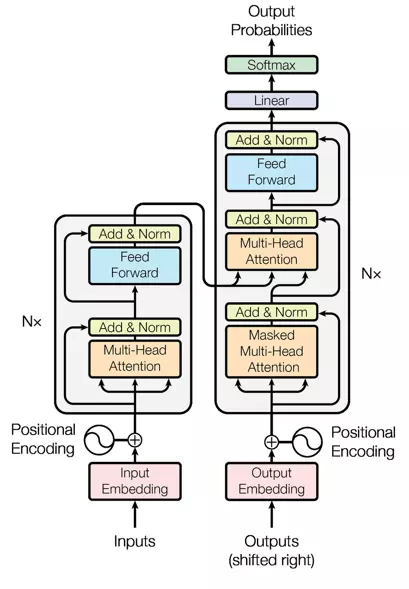
- Positional encoding: Bởi vì transformer không có các mạng hồi tiếp hay mạng tích chập nên nó sẽ không biết được thứ tự của các token đầu vào. Vì vậy, cần phải có cách nào đó để cho mô hình biết được thông tin này. Đó chính là nhiệm vụ của positional encoding. Như vậy, sau bước nhúng từ (embedding layers) để thu được các tokens thì ta sẽ cộng nó với các vector thể hiện vị trí của từ trong câu.
- Lớp Normalization: Trong hình ảnh cấu trúc, có lớp "Add & Norm" thì từ Norm thể hiện cho lớp Normalization. Lớp này đơn giản là sẽ chuẩn hóa lại đầu ra của multi-head attention, mang lại hiệu quả cho việc nâng cao khả năng hội tụ.
- Kết nối Residual: Kết nối residual bản chất rất đơn giản: thêm đầu vào của một khối vào đầu ra của nó. Với kết nối này giúp mạng có thể chồng được nhiều layers. Như trên hình, kết nối residual sẽ được sử dụng sau các khối FFN và khối attention. Như trên hình từ "Add" trong "Add & Norm" sẽ thể hiện cho kết nối residual.
- Khối Feed-Forward: Đây là khối cơ bản, sau khi thực hiện tính toán ở khối attention ở mỗi lớp thì khối tiếp theo là FFN. Có thể hiểu là cơ chế attention giúp thu thập thông tin từ những tokens đầu vào thì FFN là khối xử lí những thông tin đó.
Kết luận
Vừa rồi là một vài tìm hiểu về kiến trúc transformer. Transformer đã ra đời được khá lâu và không còn mới nhưng nó và những biến thể vẫn đang thể hiện một hiệu quả rất cao trong các bài toán NLP. Bài viết chắc chắn vẫn còn nhiều thiếu sót mong nhận được phản hồi của mọi người để mình có thể cải thiện tốt hơn!