What is a cluster?
Viết tắt computer clusters, kết nối các máy tính có cấu hình thấp với nhau ( thay vì 1 super computer). Mỗi máy tính được gọi là 1 node. Có 2 loại node đó là head node và computer node.
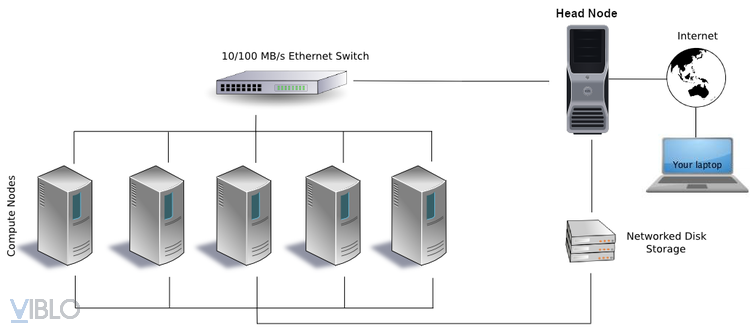
Terminology
Head Node:
Là nơi đăng nhập vào cluster, là nơi chỉnh sửa script, compile code, và submit jobs tới scheduler. Head Node được chia sẽ với các user khác nên các Job không nên được chạy ở Head Node. ( sẽ được nhắc lại ở quy tắc 10 - 10 bên dưới )
Compute Node:
Là nơi mà các Job được chạy, nhưng để được chạy ở các Node này chúng ta phải thông qua Job Scheduler bằng việc Submitting Job. Job sẽ được tự động chạy trên node này khi yêu cầu về resources ok.
Cores:
Có thể hiểu như là số lượng processor CPU-cores. Nó sẽ xử lí và thực hiện các yêu cầu phần lớn các công việc yêu cầu.
How Do HPC Clusters Work?
Để chương trình có thể chạy được trên cluster, bạn phải chuẩn bị các file sau ở trên Head Node:
-
Code chạy chương trình ( ví dụ file .py)
-
Một file SLURM script, file này sẽ yêu cầu resources bạn cần. Ví dụ ( Memory, number cpu, number node, …)
Khi file slurm được submited, scheduler sẽ kiểm tra nếu các yêu cầu về resources ok thì job sẽ được chạy, nếu không sẽ đưa vào hàng chờ.
Important Notes on Using HPC Clusters
The 10-10 Rule:
Một điều quan trọng bạn cần lưu ý đó là bạn có thể sử dụng các câu lệnh nhanh chóng trên các head node nhưng.
- Không quá 10 phút
- Không sử dụng quá 10% cores và memory Nếu vượt quá thì bạn sẽ làm ảnh hưởng đến người khác. Có một số cách để bạn có thể check thông tin của head node như: -
uname -a( hiển thị thông tin hệ thống ) -
lscpu( hiển thị liên quan đến cpu, số lượng cores, speed … ) -
free -m( Hiển thị memmory) -
df -h( check bộ nhớ lưu trữ ( disk ) ) -
top( hiển thị các thông tin đang chạy (cpu, mem..))Mỗi câu lệnh bạn có thể google thêm để biết thêm chi tiết.
No Internet Access on the Compute Nodes
- Điều này có thể xảy ra trên một vài Compute Node ( hpc ) về vấn đề bảo mật. Bạn không thể downloading dữ liệu, packages. Nếu gặp vấn đề download 1 dữ liệu lớn bằng slurm không được, bạn có thể chỉnh sửa file slurm bằng cách thay đổi sang node khác.
Introducing Slurm
Trên tất cả các hệ thống cluster, người dùng chạy chương trình bởi việc submitting scripts tới Slurm job scheduler. Một Slurm script phải chứa 3 thứ:
-
Quy định các tài nguyên cho Job
-
Set enviroment
-
Chỉ định công việc cần thực hiện dưới lệnh shell
Dưới đây là mẫu Slurm script để chạy code Python sử dụng Conda enviroment.
#!/bin/bash #SBATCH --job-name=myjob # create a short name for your job #SBATCH --nodes=1 # node count #SBATCH --ntasks=1 # total number of tasks across all nodes #SBATCH --cpus-per-task=1 # cpu-cores per task (>1 if multi-threaded tasks) #SBATCH --mem-per-cpu=2G # memory per cpu-core (4G is default) #SBATCH --time=00:01:00 # total run time limit (HH:MM:SS) #SBATCH --mail-type=begin # send email when job begins #SBATCH --mail-type=end # send email when job ends #SBATCH --mail-user=<YourNetID>@gmail.com module purge module load anaconda3/2020.11 conda activate pytools-env python myscript.py
Dòng đầu tiên của script chỉ định Unix shell được sử dụng. Tiếp theo đó là các dòng với bắt đầu bằng #SBATCH . Script trên yêu cầu 1 Cpu-core và 4 GB memory cho 1 phút run time. Ba dòng tiếp theo chỉ định môi trường cần chạy. Dòng cuối cùng đó là chương trình sẽ chạy những câu việc từ file myscript.py
Nếu Job của bạn bị fails trước khi specified time limit thì nó sẽ bị kill để nhường tài nguyên cho các Job khác chay. bạn nên ước tính chinhs xác thời gian chạy cộng thêm với 20 %. Một job script tên job.slurm sẽ được submit tới Slurm scheduler với câu lệnh sbatch.
$ sbatch job.slurm
Để check trạng thái của job, sử dụng command sau:
$ squeue -u <YourNetID>
Để xem thời gian bắt đầu dự kiến của các công việc đang xếp hàng:
$ squeue -u <YourNetID>