Mở đầu
SAM (Segment Anything Model) được Meta AI công bố vào tháng 4 năm 2023 trong dự án "Segment Anything" với vai trò là một foundation model có thể segment vật thể trong ảnh sử dụng prompt, hay nói cách khác là chỉ bằng việc click chọn một vài điểm bất kỳ của vật thể trong bức ảnh là mô hình có thể trả về một mask khá là sát với vật thể. Ngoài ra, SAM cũng có thể segment vật thể trong bức ảnh bằng cách vẽ bounding box quanh vật thể hay thậm chí là sử dụng đoạn văn bản bất kỳ để mô tả vật thể cần segment trong ảnh. Hơn thế nữa, để tăng độ chính xác trong việc xác định vật thể thì SAM còn có thể tạo ra nhiều mask khác nhau để người dùng có thể lựa chọn. Với những khả năng đó kèm theo việc có thể thực thi thời gian thực thì SAM đã và đang trở thành một trong những cải tiến đáng quan tâm nhất hiện nay và bài viết sau đây sẽ đi vào sâu hơn về SAM.

Hình 1: Demo cách hoạt động của SAM (Truy cập link này để xem thêm demo)
Tổng quan về foundation model
Foundation model (tạm dịch "mô hình nền tảng") thường được đề cập đến trong NLP (xử lý ngôn ngữ tự nhiên) là các mô hình có khả năng vượt trội trong các tác vụ zero-shot, one-shot learning. Hay nói cách khác, đó là các mô hình có khả năng generalize với những tác vụ và dữ liệu có phân phối nằm ngoài những gì học được trong quá trình training thông qua việc pretrain trên một tập dữ liệu vô cùng lớn. Cụ thể hơn là trong quá trình pretrain, các mô hình này sẽ được huấn luyện trên tập văn bản vô cùng lớn có sẵn ở trên web và không cần phải gán nhãn thông qua tác vụ như là dự đoán từ còn thiếu trong câu, hay là dự đoán câu tiếp theo trong đoạn văn. Sau đó các mô hình này sẽ được sử dụng cho các tác vụ khác như là dịch thuật, tóm tắt văn bản bằng cách prompt engineering, tức là sử dụng một đoạn văn bản mô tả để hướng dẫn cho mô hình đưa ra câu trả lời phù hợp, tương tự như cách chúng ta tương tác với ChatGPT. Một số mô hình điển hình mới ra gần đây có thể kể đến như là LLaMa của Meta hay GPT-4 của OpenAI.
Tuy nhiên, đối với Computer Vision (thị giác máy tính) thì mặc dù số lượng ảnh có sẵn trên web vô cùng nhiều nhưng lại phải cần đến con người để gán nhãn nên là việc phát triển một foundation model trong lĩnh vực này là một chuyện tương đối khó khăn, nhất là cho bài toán Image Segmentation khi dữ liệu có gán nhãn cho bài toán này tương đối hiếm. Và để có thể phát triển một foundation model cho bài toán Image Segmentation thì nhóm nguyên cứu đến từ Meta AI Research đã triển khai một dự án với 3 thành phần chính:
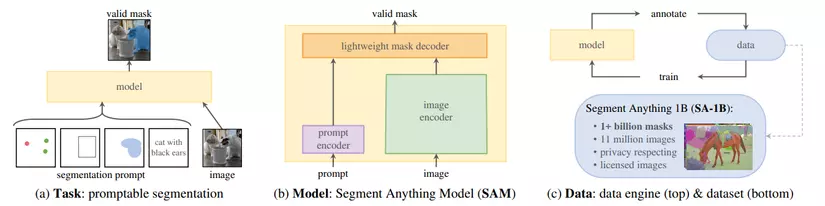
- Promptable segmentation task: Tác vụ segment ảnh sử dụng prompt để hướng dẫn mô hình segment vật thể trong ảnh, tuy nhiên khác với NLP thì prompt trong tác vụ này sẽ không chỉ dừng lại ở text (đoạn văn mô tả) mà còn bao gồm cả points (điểm ảnh), bounding box hay rough mask (mask còn thô sơ).
- Model: Mô hình trong tác vụ này sẽ nhận cả ảnh lẫn prompt làm đầu vào thay vì chỉ sử dụng mỗi ảnh như một số mô hình cổ điển khác như là Unet. Cấu trúc của mô hình sẽ được đề cập chi tiết hơn trong phần tiếp theo.
- Dataset: Tương tự như NLP thì bộ dữ liệu sử dụng cho bài toán này phải tương đối lớn và đa dạng để mô hình có thể generalize tốt đối với dữ liệu có phân phối khác. Tuy nhiên, số lượng segmentation masks có sẵn trên web tương đối ít cộng với việc tạo ra chúng tốn rất nhiều thời gian và công sức nên nhóm nguyên cứu của Meta AI Research đã thiết kế một "data engine", hay dịch nôm na là động cơ để vận hành hệ thống gán nhãn ảnh một cách tự động. Với data engine này thì họ đã tạo ra một bộ dữ liệu có tên gọi SA-1B bao gồm 11 triệu ảnh với hơn 1 tỷ mask, và data engine này sẽ được đề cập chi tiết hơn trong phần tiếp theo.
Kiến trúc mô hình
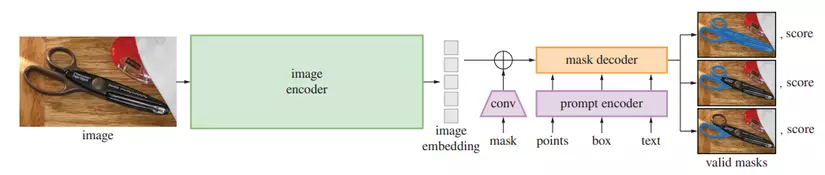
Kiến trúc mô hình của SAM bao gồm 3 thành phần chính:
- Image encoder: sử dụng masked auto-encoder (MAE) pre-trained Vision Transformer (ViT) để chuyển đổi ảnh thành embedding.
- Prompt encoder: encode points, bounding boxes dưới dạng positional encodings (tương tự như cách Transformer encode vị trí từng từ trong câu) và encode texts thông qua CLIP (Contrastive Language-Image Pretraining) rồi cộng từng phần tử lại với nhau, encode masks thành embedding thông qua convolutions (tích chập) và rồi cộng từng phần tử một với embedding của ảnh.
- Mask decoder: tương đối nhẹ, dựa vào embedding của ảnh, embedding của prompt và một ouput token để trả về mask tương ứng, sử dụng prompt self-attention và cross-attention theo hai hướng (từ embedding của prompt tới embedding của ảnh và ngược lại) thông qua biến thể của Transformer decoder block với một dynamic mask prediction head, sau đó tiến hành upsample embedding của ảnh và cho output token qua một lớp MLP (Multi-layer Perceptron) để dự đoán xác suất thuộc về vật thể ở mỗi vị trí trong ảnh.
Ngoài ra, do một điểm click chọn có thể ám chỉ tay cầm của kéo hoặc thậm chí là cả cái kéo như ở trong hình 3 nên SAM sẽ trả về nhiều mask khác nhau đối với mỗi một prompt (3 masks cho từng prompt là khá đủ trong đa số trường hợp). Để huấn luyện SAM thì hàm loss được sử dụng ở đây là tổ hợp tuyến tính giữa focal loss và dice loss.
Dataset

Data Engine
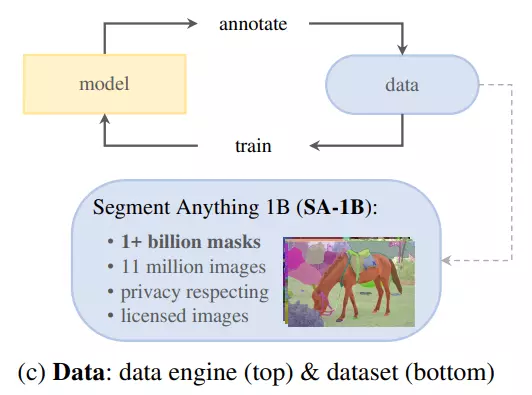
Data engine vừa là cách tạo ra bộ dữ liệu SA-1B, vừa là cách mà SAM được huấn luyện trong suốt quá trình gán nhãn dữ liệu. Data engine bao gồm 3 giai đoạn:
- Assisted-manual (Thủ công): Ở giai đoạn này thì SAM sẽ được huấn luyện trên những tập dữ liệu được công khai, sau đó một nhóm các chuyên gia gán nhãn sẽ tiến hành tạo ra masks cho bức ảnh dưới sự trợ giúp của SAM bằng cách click chọn vật thể hoặc background để ra mask rồi tiến hành chỉnh sửa để cho ra mask chất lượng hơn. Những masks này sẽ lại tiếp tục được sử dụng để huấn luyện cho SAM thêm lần nữa và việc huấn luyện này đã được lặp đi lặp lại 6 lần. Kến trúc của mô hình cũng theo đó được nâng lên để tăng độ chính xác (ViT-B → ViT-H cho image encoder), tốc độ trung bình để gán nhãn dữ liệu cũng theo đó mà giảm dần (34 → 14 giây / 1 mask ), số lượng masks mỗi ảnh tăng (20 → 44 masks) và thu được tổng cộng 4,3 triệu masks cho 120 nghìn ảnh.
- Semi-automatic (Bán tự động): Ở giai đoạn này thì các chuyên gia gán nhãn sẽ tiến hành gán nhãn cho các vật thể không được SAM gán nhãn trong số các masks được tạo ra bởi SAM với mục đích tăng độ đa dạng cho masks sinh ra bởi SAM. Sau đó tương tự như giai đoạn trước, những masks này được dùng để huấn luyện cho SAM thêm lần nữa (tổng cộng 5 lần) và sau giai đoạn này thu được tổng cộng 10,2 triệu masks cho 300 nghìn ảnh. Mặc dù tốc độ trung bình gán nhãn tăng trở lại 34 giây / 1 mask nhưng số lượng masks mỗi ảnh tăng từ 44 → 72 masks.
- Fully automatic (Tự động hoàn toàn): Ở giai đoạn này thì một mạng lưới các điểm kích thước 32×32 được dùng để làm prompt cho mô hình và mỗi điểm sẽ tương ứng một bộ masks dự đoán vật thể cần segment. Sau đó, IoU prediction module của mô hình được sử dụng để chọn ra confident masks, rồi từ confident masks chọn ra các masks ổn định hơn (hình dạng tương tự nhau khi xác suất để phân ngưỡng ở 0.5 − δ và 0.5 + δ), cuối cùng lọc ra các masks trùng lặp nhau thông qua non-maximal suppression (NMS). Ngoài ra để tăng chất lượng cho các masks nhỏ hơn thì sẽ tiến hành crop từng phần của bức ảnh để phóng to lên để xử lý (các phần này thường sẽ trùng lặp nhau để hạn chế masks bị chia cắt bởi các phần này). Và khi ứng dụng cách làm này với tất cả 11 triệu ảnh trong tập dữ liệu thì thu được tổng cộng 1,1 tỷ masks chất lượng cao.
Dataset comparison

Khi so sánh SA-1B với các bộ dữ liệu nổi tiếng khác dùng được trong bài toán Image Segmentation (LVIS v1, COCO, ADE20K, Open Images) thì ta có thể một số đặc điểm như sau:
- Xét về kích thước thì SA-1B có số lượng ảnh gấp 11 lần và số lượng masks gấp 400 lần so với bộ dữ liệu lớn nhất hiện tại là Open Images.
- Xét về tỉ lệ ảnh có số lượng masks mỗi ảnh nhiều (> 100 masks) thì SA-1B có tỉ lệ tận ~80% (tổng tỉ lệ ảnh có 51-100, 101-200, >200 masks), nhiều hơn hẳn so với các bộ dữ liệu còn lại (< 30%).
- Xét về kích thước của masks trong mỗi ảnh (đo bằng với S là diện tích) thì SA-1B có tỉ lệ masks kích thước vừa và nhỏ tương đối nhiều, lớn hơn so với các bộ dữ liệu còn lại, điều này có lẽ không có gì ngạc nhiên khi mà SA-1B có tỉ lệ masks mỗi ảnh tương đối lớn.
- Xét về độ phức tạp của hình dạng của masks (đo bằng độ lõm của mask: với S là diện tích, ch là convex hull - bao lồi của mask) thì SA-1B có phức tạp tương tự các bộ dữ liệu còn lại (phân phối về độ lõm tương tự nhau).
Kết quả
Kết quả thực nghiệm của SAM sẽ được đánh giá thông qua việc zero-shot transfer, tức là đánh giá trên tác vụ mô hình không được huấn luyện nhưng vẫn có thể ứng dụng được.
Zero-Shot Single Point Valid Mask
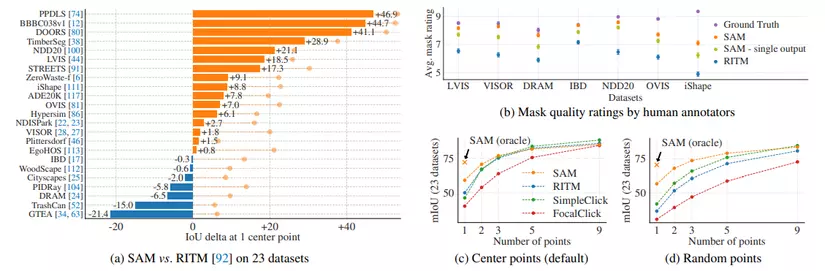
Single Point Valid Mask là tác vụ segment vật thể bằng 1 cú click chọn. Ở tác vụ này thì SAM sẽ được so sánh với RITM là thuật toán segmentation tốt nhất hiện tại ở trên 23 bộ dữ liệu:
- Xét về chỉ số mIoU trên 23 bộ dữ liệu ở biểu đồ (a) thì SAM cho kết quả tốt hơn trên 16 trong số 23 bộ dữ liệu. Nếu lấy kết quả "oracle" của SAM ra so sánh (kết quả đạt được của SAM khi lấy masks giống ground truth nhất trong số 3 masks mà SAM trả về thay vì lấy masks có confidence cao nhất, được biểu diễn bằng chấm tròn màu cam trong biểu đồ (a)), thì SAM hơn hẳn RITM trên tất cả 23 bộ dữ liệu.
- Xét về chất lượng của mask do người gán nhãn đánh giá bằng thang điểm từ 1 đến 10 thì SAM đạt trung bình 7-9 điểm, hơn hẳn RITM trên tất cả 7 bộ dữ liệu trong biểu đồ (b).
- Xét về chỉ số mIoU với số lượng điểm click chọn từ 1 trở đi thì cho dù điểm đó nằm vị trí giữa hay ngẫu nhiên trên vật thể ở biểu đồ (c), (d) thì SAM đều tốt hơn hẳn các RITM hay SimpleClick, FocalClick khi số lượng points ít, còn khi số lượng điểm click chọn nhiều thì mIoU đạt được tương tự nhau (một phần là do càng nhiều điểm click chọn thì càng dễ xác định vật thể hơn).
Zero-Shot Edge Detection

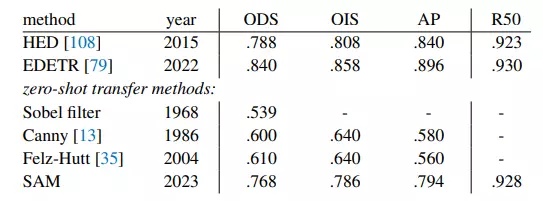
Phương pháp: Edge Detection là tác vụ xác định đường nét trong ảnh và SAM ứng dụng cho tác vụ này bằng cách sử dụng mạng lưới các điểm kích thước 16×16 với 3 masks mỗi điểm rồi dùng NMS để loại bỏ mask trùng lặp, sau đó cho qua thuật toán Sobel filtering và xử lý bằng edge NMS để ra edge map (ảnh trắng đen chỉ còn lại đường nét).
Kết quả: mặc dù SAM không được huấn luyện cho tác vụ này nhưng SAM vẫn có thể tạo ra edge map tương đối tốt, thậm chí còn nhiều đường nét hơn cả ground truth trong tập BSDS500. Chỉ số R50 (recall at 50% precision) của SAM tương đối cao, nhưng nếu xét theo chỉ số khác thì SAM vẫn còn thua tương đối so với các phương pháp tốt nhất được huấn huyện trên tập BSDS500 như HED, EDETR, một phần có thể là do các phương pháp này học được bias trong tập BSDS500 nên xác định được đường nét nào cần lược bỏ.
Zero-Shot Object Proposals
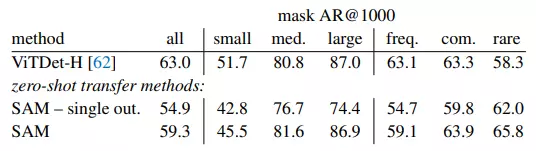
Metric được sử dụng trong tác vụ này là average recall trên 1000 proposals (AR@1000) do số lượng classes của vật thể trong tập LVIS v1 chỉ có tối đa là 1203 classes trong khi SAM được huấn luyện để segment bất cứ thứ gì nên sẽ segment nhiều vật thể hơn hẳn so với ground truth, tức là precision sẽ không phản ánh được điều gì, trong khi recall thì hoàn toàn có thể dùng để đánh giá xem SAM có bỏ sót vật thể nào trong ground truth hay không.
Phương pháp: Ở tác vụ này thì SAM sẽ phải xác định tất cả các vật thể có trong ảnh bằng cách sử dụng mạng lưới các điểm kích thước 64×64 với 3 masks mỗi điểm rồi dùng NMS để loại bỏ mask trùng lặp, sau đó sắp xếp chúng theo trung bình của mức độ confidence và stability rồi chọn ra top 1000 masks.
Kết quả: Xét về kết quả tổng thể thì ViTDeT-H vẫn là tốt nhất và SAM chỉ hơn VitDet đối với các vật thể kích cỡ trung bình và lớn, xuất hiện không thường xuyên còn đối với các vật thể nhỏ và xuất hiện thường xuyên thì ViTDeT-H vẫn vượt trội hơn so với SAM, một phần có thể là do ViTDeT-H được huấn luyện trên tập này còn SAM thì không.
Zero-Shot Instance Segmentation

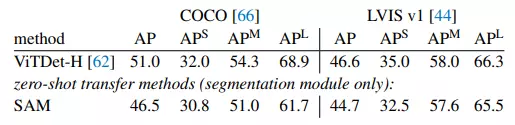
Phương pháp: Instance Segmentation là tác vụ xác định vị trí và segment từng vật thể trong ảnh. SAM ứng dụng cho tác vụ này bằng cách sử dụng một object detector (ví dụ như ViTDeT) để trả về bounding boxes rồi bounding boxes đó được dùng làm prompt để SAM segment vật thể.
Kết quả: Xét về chỉ số mask AP (average precision) trên tập COCO với LVIS v1 thì SAM vẫn kém hơn tương đối so với ViTDeT-H, một phần là do SAM không được huấn luyện trên các tập này. Tuy nhiên, masks trả về từ SAM khi so với ViTDeT-H thì có phần chất lượng hơn, thậm chí là có thể segment cái đĩa mà không bao gồm thức ăn trong khi cả ViTDeT-H hay ground truth trong tập LVIS v1 đều bao gồm thức ăn.
Zero-Shot Text-to-Mask

Phương pháp: Text-to-Mask là tác vụ sử dụng text để segment vật thể tương ứng và để ứng dụng SAM cho tác vụ này thì SAM sẽ được huấn luyện để nhận thức về văn bản (text-aware) mà không cần phải dùng văn bản làm nhãn. Cụ thể là với mỗi mask có diện tích lớn hơn thì sẽ cho mask đấy qua image encoder của CLIP để ra embedding và sử dụng cái embedding này để làm prompt cho SAM trong quá trình huấn luyện. Ý tưởng ở đây là CLIP được huấn luyện để liên kết ảnh này với đoạn văn bản kia nên embedding của chúng sẽ có phần tương tự nhau, dẫn đến việc có thể sử dụng embedding của mask trong quá trình huấn luyện, còn embedding của text trong quá trình inference của SAM (text được cho qua text encoder của CLIP để ra embedding).
Kết quả: SAM có thể segment vật thể tương đối tốt với text prompt đơn giản như là "a wheel" hay "beaver tooth grille", nhưng lại không được tốt với text prompt là "a wiper" hay "wipers" do xác định sai vật thể và phải cần đến point mới xác định đúng.
Kết luận
Tổng kết lại thì SAM là mô hình không chỉ có khả năng segment vật thể trong ảnh sử dụng prompt (points, box, rough mask, text) mà còn có khả năng generalize tương đối tốt đối với các tác vụ và bộ dữ liệu nằm ngoài quá trình huấn luyện trong bài toán Image Segmentation, đạt kết quả không thua kém gì so với các mô hình tốt nhất hiện tại trong các tác vụ đó. Ngoài ra, với việc cho phép người dùng lựa chọn vật thể để segment trong thời gian thực thì SAM hoàn toàn có thể được dùng làm một công cụ để gán nhãn ảnh, hay thậm chí là chỉnh sửa ảnh, video, segment vật thể trong kính AR dựa trên hướng người dùng đang nhìn.
Tham khảo
- Segment Anything official website (https://segment-anything.com/)
- Segment Anything paper (https://arxiv.org/pdf/2304.02643.pdf)
- Segment Anything code (https://github.com/facebookresearch/segment-anything)
- Meta AI's New Breakthrough: Segment Anything Model (SAM) Explained (https://encord.com/blog/segment-anything-model-explained/)
- Segment Anything Model (SAM) from Meta AI: model architecture, data engine, results and limitations (https://www.youtube.com/watch?v=qa3uK3Ewd9Q)