Hello mọi người và chúc mừng năm mới!!!
Vài hôm trước, mình lướt FB thì thấy sếp share một bài viết khá thú vị trên reddit về StyleGAN: Link bài viết
Dưới phần comment, tác giả có giải thích là đã sử dụng kỹ thuật gọi là model blending để trộn lẫn 2 mô hình StyleGAN2: một mô hình được train trên tập FFHQ để sinh mặt người trông như thật, mô hình thứ 2 thì được finetune từ mô hình trên với bộ dữ liệu nhân vật Pixar. Mô hình mới sẽ có thể tạo ra nhân vật Pixar từ mặt người thật. Sau đó, tác giả sử dụng thêm First Order Motion để animate ảnh mới theo một video mẫu.
Trong bài viết này thì mình sẽ giới thiệu cho mọi người phần model blending để tạo nhân vật hoạt hình từ ảnh thật nhé. Let's get started!
Giới thiệu về GAN và StyleGAN
Phần này mình sẽ nói nhanh về GAN và StyleGAN chứ sẽ không nói kỹ về lý thuyết.
GAN
Generative Adversatial Network (GAN) là một trong những mô hình hot nhất hiện nay trong lĩnh vực deep learning với nhiều ứng dụng trong lĩnh vực sinh ảnh. GAN bao gồm 2 mạng neural cạnh tranh với nhau gọi là generator và discriminator. Nhiệm vụ của generator là đánh lừa mạng discriminator rằng ảnh do nó sinh ra là ảnh thật, còn mạng discriminator sẽ phân lớp giữa ảnh thật (từ bộ dữ liệu) và ảnh giả (ảnh từ generator).
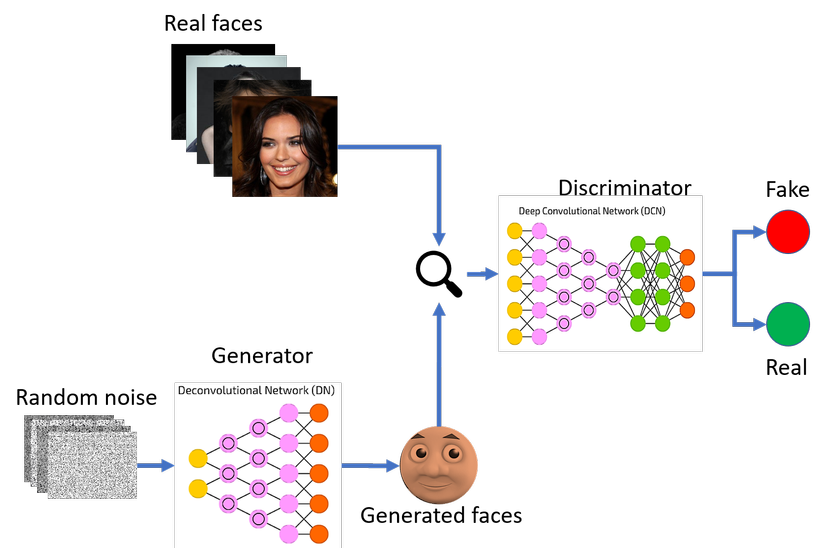
Mạng discriminator sẽ được train trước bằng cách cho xem một batch ảnh thật từ bộ dữ liệu và một batch ảnh nhiễu (do generator vẫn chưa được train)
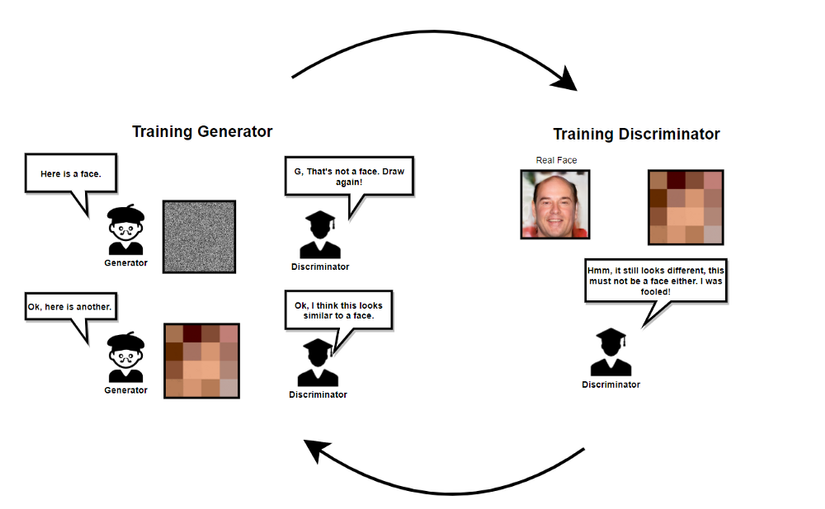
 Sau đó, ta chuyển sang train generator. Mạng generator sẽ học cách sinh ra ảnh với chất lượng cao hơn nhờ vào phản hồi từ discriminator (ảnh do nó sinh ra được dự đoán là thật hay giả) cho tới khi discriminator không phân biệt được giữa ảnh thật và giả nữa. Tiếp theo ta lại chuyển qua train discrminator và quy trình cứ tiếp tục như vậy cho tới khi generator có thể sinh ra ảnh rất gần với ảnh trong bộ dữ liệu.
Sau đó, ta chuyển sang train generator. Mạng generator sẽ học cách sinh ra ảnh với chất lượng cao hơn nhờ vào phản hồi từ discriminator (ảnh do nó sinh ra được dự đoán là thật hay giả) cho tới khi discriminator không phân biệt được giữa ảnh thật và giả nữa. Tiếp theo ta lại chuyển qua train discrminator và quy trình cứ tiếp tục như vậy cho tới khi generator có thể sinh ra ảnh rất gần với ảnh trong bộ dữ liệu.
StyleGAN
Mô hình StyleGAN được giới thiệu bởi NVIDIA vào năm 2018. StyleGAN giới thiệu một kiến trúc generator mới cho phép ta điều khiển các mức độ chi tiết của ảnh từ các chi tiết thô (dáng đầu, kiểu tóc...) tới các chi tiết nhỏ hơn (màu mắt, đeo khuyên tai...).
StyleGAN cũng tích hợp các kỹ thuật từ PGGAN, cả 2 mạng generator và discrminator ban đầu sẽ được train trên ảnh 4x4, sau nhiều lớp sẽ dần được thêm vào và kích thước ảnh cũng dần tăng lên. Bằng kỹ thuật này, thời gian huấn luyện được rút ngắn đáng kể và quá trình huấn luyện cũng ổn định hơn.
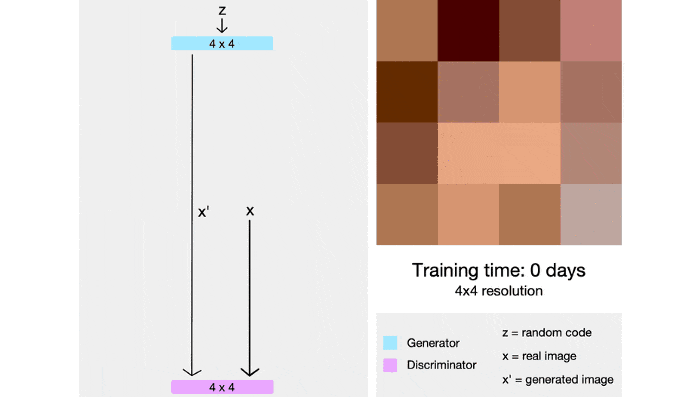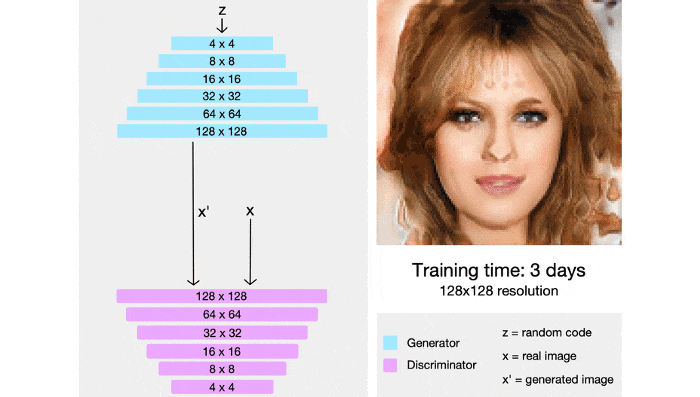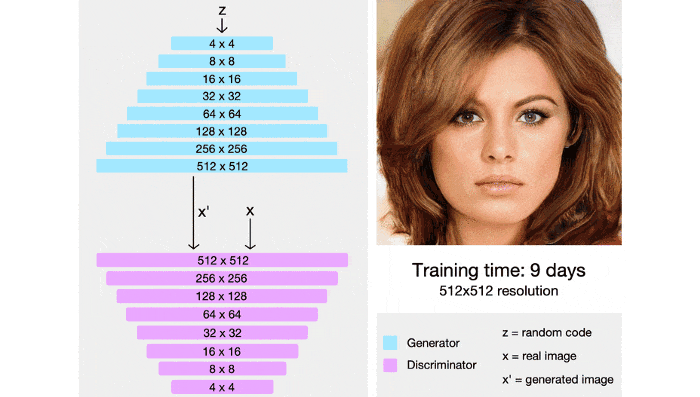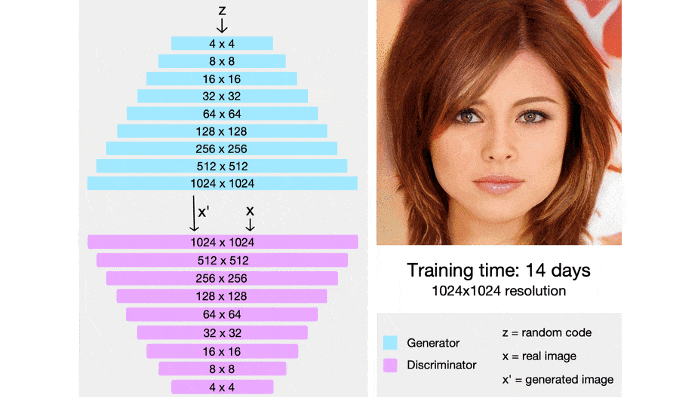
StyleGAN có khả năng điều khiển các mức độ chi tiết các nhau bằng cách sử dụng thêm một mạng mapping để mã hóa vector z (lấy từ phân phối chuẩn nhiều chiều) thành một vector w. Vector w sau đó sẽ được đưa vào nhiều vị trí khác nhau trong mạng genertor, tại mỗi vị trí vector w sẽ điều khiển các đặc trưng khác nhau.
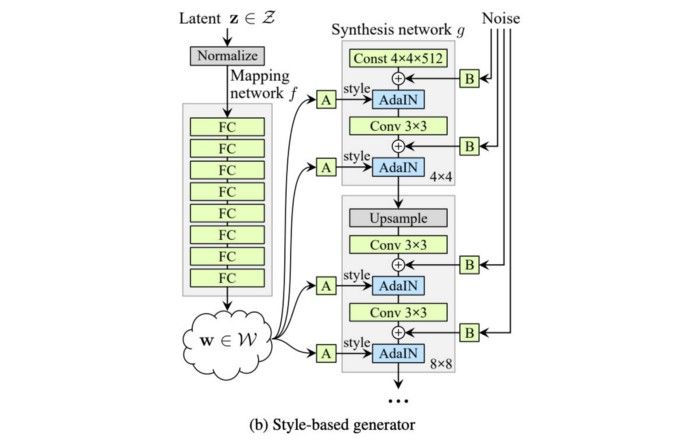 Các vị trí đầu (ở các lớp có độ phân giải 4x4, 8x8) sẽ kiểm soát các đặc trưng thô như dáng đầu, kiểu tóc, đeo kính. Các vị trí cuối (ở các lớp có độ phân giải 512x512, 1024,x1024) sẽ kiểm soát các đặc trưng kết cấu khuôn mặt như màu da, màu tóc, màu mắt...
Các vị trí đầu (ở các lớp có độ phân giải 4x4, 8x8) sẽ kiểm soát các đặc trưng thô như dáng đầu, kiểu tóc, đeo kính. Các vị trí cuối (ở các lớp có độ phân giải 512x512, 1024,x1024) sẽ kiểm soát các đặc trưng kết cấu khuôn mặt như màu da, màu tóc, màu mắt...


Network blending
Như đã viết ở trên, các lớp ở độ phân giải thấp của mô hình sẽ kiểm soát các đặc trưng về cấu trúc (structure) của khuôn mặt và các lớp ở độ phân giải cao kiểm soát các đặc trưng về kết cấu (texture) của khuôn mặt. Bằng cách tráo đổi trọng số mô hình ở các độ phân giải khác nhau, ta có thể chọn và blend các đặc trưng sinh ra bởi các mạng generator khác nhau. Ví dụ như một bức ảnh mặt người thật nhưng có kết cấu của nhân vật hoạt hình.
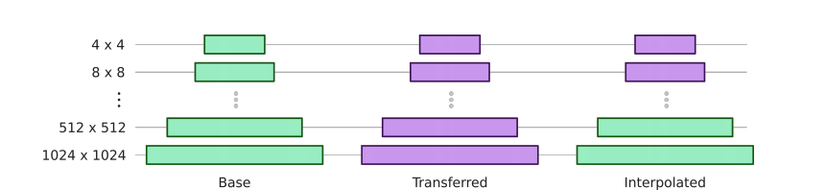

Quá trình blend 2 mạng generator diễn ra như sau:
- Bắt đầu với 1 mô hình StyleGAN pretrain với trọng số
- Finetune mô hình gốc trên bộ dữ liệu mới được mô hình
- Kết hợp trọng số của mô hình gốc và mô hình vừa finetune thành bộ trọng số mới
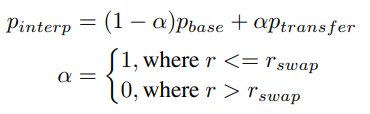
trong đó, là độ phân giải mà quá trình đổi trọng số của 2 mô hình bắt đầu.
Code
Lý thuyết như vậy đủ rồi, bắt đầu code thôi! Ai muốn muốn dùng thử mà không cần code thì có thể xem link này nhé. Hoặc một phiên bản mới hơn ở đây nhưng mất phí.
Đầu tiên, ta cần clone repo của StyleGAN về, ở đây mình dùng StyleGAN2 nhé
!git clone https://github.com/NVlabs/stylegan2.git
Tiếp theo là tải trọng số của mô hình pretrain xuống và load mô hình. Một mô hình là do NVIDIA open source trên bộ dữ liệu FFHQ và một mô hình là mô hình đã được finetune trên một bộ dữ liệu nhân vật hoạt hình.
!wget https://nvlabs-fi-cdn.nvidia.com/stylegan2/networks/stylegan2-ffhq-config-f.pkl
!gdown https://drive.google.com/uc?id=1_fQCDp6A630MO0GZgsGySTlAuzEMDatB
_, _, Gs_1 = pretrained_networks.load_networks('/content/stylegan2/stylegan2-ffhq-config-f.pkl')
_, _, Gs_2 = pretrained_networks.load_networks('/content/stylegan2/ffhq-cartoons-000038.pkl')
Cùng xem thử output của 2 mô hình gốc nhé


Tiếp theo là code để blend 2 mô hình. Mọi người có thể test với độ phân giải khác nhau xem kết quả thế nào nhé
def get_layers_names(model): names = model.trainables.keys() conv_names = [] resolutions = [4*2**x for x in range(9)] level_names = [["Conv0_up", 'Const'], ["Conv1", "ToRGB"]] position = 0 for res in resolutions: root = f'G_synthesis/{res}x{res}/' for level, level_suffixes in enumerate(level_names): for suffix in level_suffixes: search_name = root + suffix matched = [x for x in names if x.startswith(search_name)] to_add = [(name, f"{res}x{res}", level, position) for name in matched] conv_names.extend(to_add) position += 1 return conv_names def blend(model_1, model_2, resolution, level): resolution = f"{resolution}x{resolution}" model_1_names = get_layers_names(model_1) model_2_names = get_layers_names(model_2) Gs_out = model_1.clone() short_names = [(x[1: 3]) for x in model_1_names] full_names = [(x[0]) for x in model_2_names] split_point_idx = short_names.index((resolution, level)) split_point_pos = model_1_names[split_point_idx][3] ys = [] for name, resolution, level, position in model_1_names: x = position - split_point_pos y = 1 if x > 1 else 0 ys.append(y) tfutil.set_vars( tfutil.run( {Gs_out.vars[name]: (model_2.vars[name] * y + model_1.vars[name] * (1-y)) for name, y in zip(full_names, ys)} ) ) return Gs_out Gs = blend(Gs_2, Gs_1, 32, 1)
Và đây là kết quả. Cũng không tệ nhỉ  )
)

Just for fun
Phần này chỉ để mình share vài mô hình sau khi đã kết hợp.
Chân dung theo phong cách ukioe và tranh ukioe theo phong cách "siêu thực" (hơi cursed 1 tí ))))))))) )



Phong cách tranh vẽ
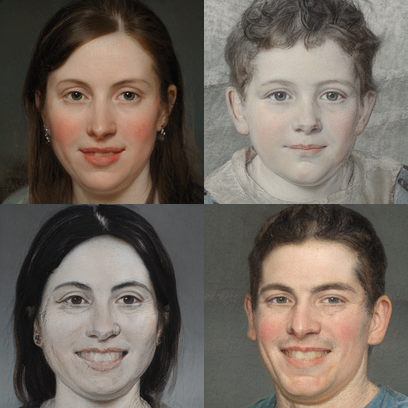
Figure drawings



Phong cách ???


Lời kết
Cảm ơn mọi người đã bỏ chút thời gian đọc bài và chúc mọi người có một năm mới an khang thịnh vượng
Link colab cho ai muốn chạy thử : https://colab.research.google.com/drive/1bNBnOjQEXlSqTqNaGI_IPOxtYp5-7kaf?usp=sharing
References
https://arxiv.org/pdf/2010.05334.pdf
https://arxiv.org/abs/1812.04948
https://github.com/justinpinkney/stylegan2
https://github.com/justinpinkney/awesome-pretrained-stylegan2
https://github.com/NVlabs/stylegan
https://www.justinpinkney.com/stylegan-network-blending/