Tổng quan
Tổng quan bài toán: Trong lĩnh vực xử lí ảnh trong Học sâu, đặc biệt là liên quan đến bài toán nhận dạng kí tự quan học, các bài toán phát hiện và nhận dạng văn bản vẫn đang là một bài toán thử thách và có tính ứng dụng cao trong cộng đồng phân tích tài liệu văn bản. Không những về độ khó đòi hỏi mô hình xử lí có cấu trúc phức tạp mà nó còn là một đề tài nghiên cứu có tính ứng dụng cao trong cuộc sống như : trích xuất thông tin từ hóa đơn, trích xuất thông tin từ giấy tờ tùy thân (chứng minh thư, căn cước công dân, bằng lái xe,...). Trong bài toán phát hiện và nhận dạng văn bản trước đây, các nhà nghiên cứu đều đưa ra các mô hình riêng biệt để xử lí chúng, cụ thể là mô hình phát hiện văn bản và mô hình nhận dạng văn bản. Các mô hình học sâu trở đều trở nên cốt lõi và thông trị cả 2 bài toán trên. Trong bài toán phát hiện văn bản, hầu hết mô hình đều sử dụng một mạng tích chập để trích xuất đặc trưng từ ảnh, sau đó các mô hình sử dụng các phương thức khác nhau để giải mã các khu vực chứa văn bản. Trong khi đó, bài toán nhận dạng văn bản cũng sử dụng một mạng tích chập để trích xuất thông tin từ ảnh sau đó sử dụng một mạng dự đoán tuần tự để tìm ra chữ cái xuất hiện trên ảnh đầu vào. Điều này có nhược điểm về thời gian lớn khi phải xử lí trên những ảnh có rất nhiều vùng văn bản như hợp đồng, sách báo,... Hơn nữa, việc các mô hình độc lập xử lí từng tác vụ sẽ làm cho mô hình phát hiện văn bản không được bổ sung tri thức từ nhận dạng văn bản, điều này làm cho mô hình phát hiện văn bản có thể dự đoán sai vùng là văn bản nhưng không đọc được.
Đặt vấn đề: Hiện nay, ở Việt Nam, việc áp dụng các thiết bị máy quay trên các đường cao tốc, đường phố để phát hiện các lỗi vi phạm và phạt nguội các tài xế thông qua việc nhận dạng biển số xe đang trở nên phổ biến. Tuy nhiên, do đòi hỏi tốc độ xử lí cao trên thiết bị đích nên các mô hình học sâu được áp dụng để giải quyết 2 bài toán tách biệt này gặp trở ngại rất lớn về thời gian. Hơn nữa, biển số xe ở Việt Nam hiện nay đang có cả biển 1 dòng và biển 2 dòng, vấn đề này gặp khó khăn trong các mô hình nhận dạng văn bản theo tuần tự từ trái sang phải, điều này chỉ giải quyết trong dữ liệu biển 1 dòng.
Phương pháp đề xuất: Để giải quyết các vấn đề trên, trong bài viết này, chúng tôi đưa ra một mô hình đầu cuối cho phát hiện và nhận dạng văn bản sử dụng cơ chế thích nghi không gian để xử lí dữ liệu nhiều dòng. Mô hình sử dụng một mạng trích xuất đặc trưng chung, giải mã chúng và sử dụng kết quả dự đoán của nhánh phát hiện văn bản làm đầu vào của nhánh nhận dạng văn bản. Ở nhánh phát hiện văn bản, mô hình sử dụng kiến trúc FPN để giải mã chúng, sau đó nhánh phát hiện văn bản sẽ đề xuất các vùng mà nó cho là văn bản thông qua phương thức lấy mẫu, trong đó RoI Rotate là phương pháp đạt kết quả tối ưu nhất trong bài toán của chúng tôi. Roi Rotate có nhiệm vụ cầu nối giữa nhánh phát hiện văn bản và nhánh nhận dạng văn bản, nó sử dụng một ma trận để điều chỉnh, biển đổi không gian của vùng đề xuất từ ảnh có chữ nghiên, chéo về ảnh chữ thẳng. Ở nhánh nhận dạng văn bản, chúng tôi sử dụng mô hình Transformer để dự đoán tuần tự kí tự, cùng với đó, chúng tôi áp dụng phương thức Mã hóa trị trí 2 chiều vào để mô hình có thể hiểu và tập trung nhận dạng được kí tự tuần tự theo từng dòng.
Phương pháp đề xuất
Chúng tôi đề xuất một phương pháp đầu cuối kết hợp 2 nhiệm vụ phát hiện và nhận diện văn bản nhiều dòng, mô hình là sự thống nhất giữa nhánh phát hiện và nhánh nhận dạng . Theo hình 1, mô hình có các thành phần chính như sau: Mạng chia sẻ, nhánh phát hiện đối tượng, RoI Rotate, Mã hóa vị trí 2 chiều và nhánh Nhận dạng.
Tổng quan về mô hình
 Hình 1: Cấu trúc mô hình đề xuất
Hình 1: Cấu trúc mô hình đề xuất
Lấy nguồn cảm hứng từ mô hình FOTS, chúng tôi chọn ResNet-50 làm mô hình cơ sở trích xuất đặc trưng . Để cải thiện độ chính xác phát hiện cho các biển số xe nhiều tỷ lệ to nhỏ, chúng tôi sử dụng kiến trúc mạng FPN để kết hợp các bản đồ đối tượng đặc trưng cấp thấp và cấp cao. Khi cho ảnh đầu vào qua kiến trúc Mạng chia sẻ, thu được ma trận đặc trưng chia sẻ có tỉ lệ bằng tỉ lệ ảnh đầu vào. Sau đó, nhánh phát hiện sử dụng một mạng tích chập lên ma trận đặc trưng chia sẻ để thu được kết quả dự đoán về lớp, tọa độ bao đóng, được xác định và tối ưu trên từng pixel. Dựa trên kết dự đoán ra bao đóng của nhánh phát hiện hoặc nhãn đầu vào, RoI Rotate được đề xuất sẽ cắt bỏ vùng tương ứng với chiều cao cố định và thay đổi chiều rộng để giữ tỷ lệ của vùng ban đầu. Cuối cùng, trong nhánh nhận dạng, trước tiên, chúng tôi đưa vùng được RoI Rotate đề xuất cho qua các khối CNN nông để trích xuất thêm một số đặc trưng chi tiết về cấp kí tự. Tiếp theo, lấy ý tưởng ban đầu từ SATRN, chúng tôi áp dụng mã hóa vị trí 2 chiều cho các vùng do RoI Rotate đề xuất để làm cho mô hình có khả năng chú ý đến nhiều dòng. Cuối cùng, cho qua mô hình Transformer để có thể mã hóa kí tự từ đặc trưng ảnh.
Mạng chia sẻ
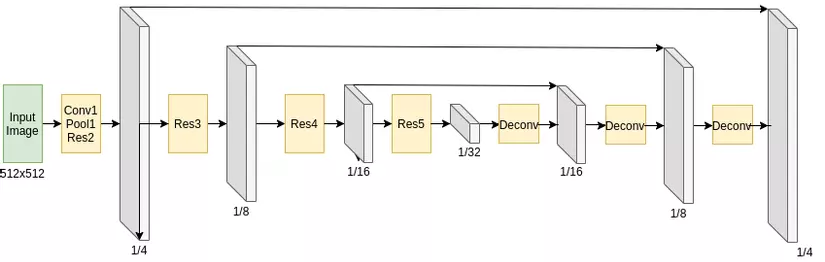
Hình 2: Cấu trúc Mạng chia sẻ
Quan sát thấy rằng cả hai mô hình phát hiện văn bản và nhận dạng văn bản trước đây đều sử dụng hai mạng cơ sở riêng biệt để trích xuất các tính năng, chúng tôi đề xuất kết hợp hoàn toàn hai mạng cơ sở thành một mạng chung thống nhất. Chúng tôi áp dụng kiến trúc mạng tích chập chia sẻ được đề xuất trong \cite{liu2018fots} để tích hợp với mô hình của chúng tôi trong đó, để sử dụng phù hợp với mô hình của chúng tôi, chúng tôi phải tùy chỉnh các siêu tham số để phù hợp với phương pháp của chúng tôi.
Mạng chia sẻ sử dụng ResNet-50 làm bộ mã hóa và kiến trúc mạng FPN làm bộ giải mã. Khi hình ảnh đầu vào được Mạng chia sẻ chuyển tiếp, độ phân giải đầu ra sẽ là một trong bốn hình ảnh gốc. Đặc biệt, chúng tôi sử dụng tới năm lớp ResNet-50. Chúng tôi nối các lớp 3-5 dưới dạng bản đồ tính năng cấp thấp với kết quả đầu ra tương ứng của lớp Deconv dưới dạng bản đồ đối tượng đại dương cấp cao. Lớp có tên Deconv bao gồm một kênh tính năng tích phân suy giảm, tiếp theo là một hoạt động lấy mẫu hai tuyến tính. Trong các thử nghiệm sau này của chúng tôi, chúng tôi nhận thấy rằng số lượng kênh trong mỗi lớp có tác động giữa hai bên. Đây là một siêu tham số xác định sự cân bằng của mạng đường trục giữa nhánh phát hiện và nhánh nhận dạng.
Để hiểu rõ hơn về kiến trúc Mạng chia sẻ, chúng tôi sẽ giới thiệu về kiến trúc mạng cơ sở ResNet và kiến trúc mạng FPN
Mạng cơ sở Resnet
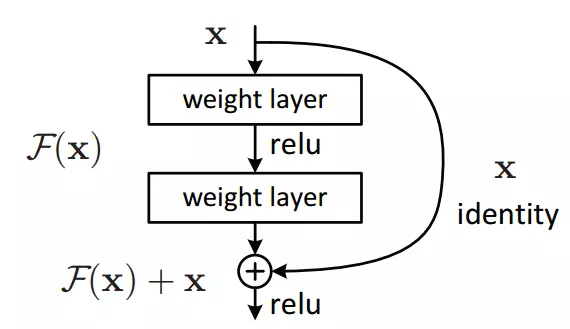
Hình 3: Khối phần dư
Trước đây, vấn đề phổ biến của các mô hình học sâu là xảy ra hiện tưởng Gradient biến mất và Gradient bùng nổ. Điều này làm cản trở mô hình học sâu xây dựng được kiến trúc sâu hơn. Trước khi Resnet ra đời thì kiến trúc mạng VGG cũng được xem là khá nông vì chỉ gồm một số khối CNN. Resnet giải quyết được vấn đề về Gradient biến mất nhờ sử dụng phương pháp Khối phần dư có kiến trúc như trong hình 3. Có công thức biểu diễn như sau:
Trong đó x,y lần lượt là véc-tơ đầu vào và đầu ra của Khối phần dư. Hàm được biểu diễn là kiến trúc học cho phần dư. Theo hình 3 thì F có hai lớp , được tính , trong đó là hàm kích hoạt ReLU.
Tác dụng của Khối dư làm cho mô hình có thể xây dựng được một kiến trúc sâu mà không làm mất đi mức độ tổng quát của dữ liệu mà còn thêm tính năng cho đầu vào khi mỗi lần đi qua một Khôi phần dư. Nhìn chung, kiến trúc của ResNet sẽ sử dụng kết hợp rất nhiều các Khối dư lại với nhau để xây dựng mô hình có kiến trúc sâu.
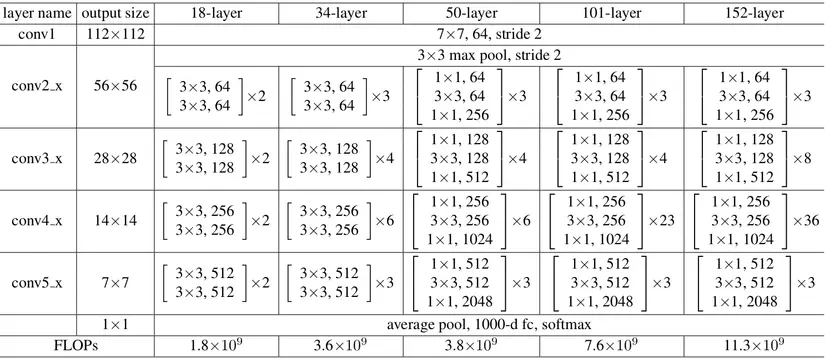
Hình 4: Thông số kiến trúc các mạng cơ sở resnet
Ta có theo hình 4, tổng quan mô hình ResNet có 5 lớp gồm lớp conv1,conv2_x,conv3_x,conv4_x và conv5_x. Trong các kiến trúc khác nhau như ResNet-18,Resnet 34 hay ResNet-50,... thì kiến trúc tại các lớp có sự khác nhau. Trong mô hình của chúng tôi, chúng tôi sử dụng kiến trúc mạng ResNet-50.
Kiến trúc mạng FPN
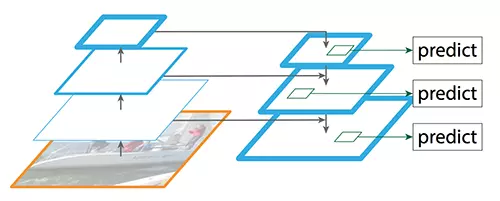
Hình 5: Kiến trúc mạng FPN
Kiến trúc mạng FPN là một công cụ trích xuất tính năng được thiết kế giống như một kim tự tháp và nó đạt được khả năng trích xuất tính chính xác hơn và tốc độ nhanh hơn. Với kiến trúc đa tỉ lệ, FPN cho chúng ta thông tin từ thấp đến cao, việc này giúp cho quá trình trích xuất không bị bỏ sót các đối tượng có kích thước nhỏ. Hơn nữa, qua mỗi tầng giãi mã, nó còn sử dụng thông tin tương ứng của tầng mã hóa, làm cho thông tin được khôi phục tốt và không làm mất đi đặc trưng của nó.
Kiến trúc FPN có thiết kế và ý tưởng khác rõ ràng, nó giải quyết tốt cho các bài toán phát hiện đối tượng. Hiện nay các mô hình về phát hiện đối tượng phổ biến hiện nay đều sử dụng các kiến trúc dựa trên cơ sở kiến trúc FPN.
Nhánh phát hiện đối tượng
Lấy cảm hứng từ FOTS, chúng tôi sử dụng một lớp tích chập để dự đoán hộp bao đóng dựa trên từng pixel. Giả sử rằng nhận được một ma trận đặc trưng từ Mạng chia sẻ, nó có kích thước , trong đó là kích thước của lô, là số lượng kênh đầu ra của Share Convolution, , lần lượt là chiều cao và chiều rộng tương ứng của ảnh đầu vào. Chúng tôi áp dụng lớp tích chập cho ma trận đặc trưng trên để thay đổi số lượng kênh từ xuống còn 6. Trong đó, kênh đầu tiên có nhiệm vụ để tính xác suất của mỗi pixel để nó thuộc lớp tích cực , ví dụ các pixel nằm trong vùng chưa văn bản được coi là tích cực. Trong 4 kênh tiếp theo, mô hình thực hiện học và dự đoán ra khoảng cách từ mỗi pixel được coi là tích cực đến các cạnh trên, dưới, trái và phải của hộp bao đóng tương ứng. Cuối cùng, kênh cuối cùng có nhiệm vụ học và dự đoán hướng của hộp bao đóng chứa văn bản, điều này giúp cho việc biến đổi vùng ảnh ở phần sau sao cho chữ được thẳng lại, giúp cho quá trình nhận dạng trở nên dễ dàng và chính xác hơn. Và để nhánh này phát hiện được tốt đối tượng, cũng như 6 kênh trên học được tốt từng nhiệm vụ của chúng thì chúng tôi đưa ra 2 hàm phạt đó là : cross entropy loss và regression loss. Hàm phạt đầu tiên dùng để phạt những dự đoán của mô hình và tối thiểu hóa sự khác biệt giá trị giữa dự đoán đầu ra của mô hình về nhãn và nhãn thật của từng pixel. Hàm cross entropy loss được đề xuất như sau:
Trong đó là số lượng các phần tử mà ở đây là các pixel có trong lô huấn luyện đó. biểu diễn hàm cross entropy loss giữa dự đoán ma trận điểm do mô hình dự đoán ra là và nhãn nhị phân ban đầu .
Ở hàm phạt thứ hai, chúng tôi cũng áp dụng hàm IoU và rotation angel loss được biểu diễn như nau:
Trong đó biểu diễn hàm IoU giữa dự đoán bao đóng của mô hình và vùng thật . và lần lượt là dự đoán về hướng và nhãn của dữ liệu. Trong việc huấn luyện, chúng tôi cài đặt siêu tham số là 5. Cuối cùng, tổng hàm phạt trong nhánh phát hiện đội tượng này như sau:
Do nhận thấy 2 hàm phạt đóng vai trò quan trọng như nhau nên chúng tôi đặt tham số cho hai hàm phạt là giống nhau.
Roi Rotate
Việc ý tưởng đề xuất một mô hình thống nhất thay vì hai mô hình riêng biệt để xử lí từng tác vụ của bài toán phát hiện và nhận dạng là rất hay. Tuy nhiên để làm được điều này cần phải có cầu nối giữa chúng. Phương pháp lấy mẫu đã có từ lâu trong các mô hình về phát hiện đối tượng như Faster RCNN sử dụng phương pháp lấy mẫu Roi Pooling hay Mask RCNN đã sử dụng phương pháp lấy mẫu Roi Align. Để tạo ra một mô hình đầu cuối phát hiện và nhận dạng, hầu hết các phương thức trước đây đều áp dụng các loại lớp lấy mẫu khác nhau, như RoI Pooling, RoI Align, RoI Rotate đóng vai trò là cầu nối giữa nhánh phát hiện văn bản và nhánh nhận dạng văn bản. Trong phương pháp của chúng tôi, chúng tôi thử nghiệm với cả 3 phương pháp lấy mẫu trên, và kết quả của từng phương thức được chúng tôi thể hiện ở hình 9. Do dữ liệu của chúng tôi có sự đa dạng bao gồm dữ liệu ảnh có biển số xe cong, nghiêng và nhiều dòng, nên việc sử dụng phương pháp lấy mẫu RoI Rotate cho kết quả tốt nhất trong 3 phương pháp trên.
RoI Pooling chuyển đổi vùng từ ma trận đặc trưng thành một vùng có kích thước cố định thông qua phương pháp gộp lấy phần tử lớn nhất còn gọi là max-pooling, trong khi RoI Align và RoI Rotate sử dụng bộ nội suy song tuyến tính để tính toán các giá trị đầu ra. Bởi vì đầu ra của phương thức lấy mẫu này sẽ là dữ liệu đầu vào cho nhánh nhận dạng nên việc giữ lại thông tin đặc trưng của từng kí tự là việc rất quan trọng, việc RoI Pooling sử dụng max-pooling làm cho thông tin đặc trưng về hình dạng của các kí tự bị mất đi đáng kể.
RoI Rotate vẫn giữ được tỉ lệ của vùng đề xuất ban đầu bằng cách cố định chiều cao của vùng đầu ra, sau đó tính chiều rộng bằng cách lấy tỉ lệ giữa chiều rộng và chiều cao của vùng ban đầu để nhân với chiều cao cố định. Trong cùng 1 lô dữ liệu, tăng thêm kích thước ma trận để đưa chúng về cùng kích thước. So với việc sử dụng nội suy song tuyến tính giống RoI Align, RoI Rotate có sử dụng việc điều chỉnh không gian ma trận và vẫn giữ được tỉ lệ giữa chiều cao và chiều rộng của bao đóng chứa văn bản. Do đó, RoI Rotate có thế lấy mẫu từ ma trận đặc trưng một cách tốt nhất với kiễu dữ liệu đa dạng mà vẫn giữ được đặc trưng của từng ký tự, giúp cho việc nhận dạng trở nên dễ dàng hơn rất nhiều.
RoI Rotate được chia làm hai giai đoạn. Đầu tiên, các tham số chuyển đổi của ma trận chuyển được tính toán thông qua tọa độ dự đoán hoặc tọa độ nhãn chứa văn bản. Sau đó, ma trận chuyển được áp dụng vào các ma trận đặc trưng cho từng khu vực tương ứng. Theo bài báo FOTS, Liu cùng với cộng sự tính toán ma trận chuyển không gian như sau:
Trong đó, M là ma trận chuyển không gian. là chiều cao và chiều rộng của ma trận đặc trưng sau khi biến đổi không gian. biểu diễn tọa độ của điểm trên ma trận đặc trưng chia sẻ là đầu ra của Mạng chia sẻ và lần lượt là khoảng cách từ cạnh trên, dưới, trái và phải của bao đóng chứa văn bản. là hướng của bao đóng. (t,b,l,r) và nhận được từ nhãn trong quá trình huấn luyện và nhận được từ nhánh phát hiện trong giai đoạn thử nghiệm.
Sau khi có ma trận chuyển M, áp dụng vào để tính các đặc trưng của vùng thích nghi:
Trong đó là giá trị đầu ra của vị trí trong kênh và là giá trị đầu vào tại vị trí của kênh . biễu diễn chiều cao và rộng của đầu vào, và là các tham số của bộ lọc mẫu k() dùng để xác định phương pháp nội suy song tuyến.
Khác với phân loại đối tượng, nhận dạng văn bản rất nhạy cảm với nhiễu phát hiện. Một lỗi nhỏ trong vùng văn bản được dự đoán có thể cắt bỏ một số ký tự, điều này có hại cho việc đào tạo mạng, vì vậy chúng tôi sử dụng tọa độ bao đóng văn bản nhãn thay vì tạo độ bao đón chứa văn bản được dự đoán trong quá trình đào tạo. Khi thử nghiệm, ngưỡng và NMS được áp dụng để lọc các vùng văn bản được dự đoán. Sau khi RoI Rotate, các bản đồ đối tượng được chuyển đổi sẽ được đưa đến nhánh nhận dạng văn bản.
Mã hóa vị trí hai chiều
Trong kiến trúc Transformer, mã hóa vị trí (Positional Encoding - PE) được định nghĩa là một phương thức làm cho mô hình có thể tính toán theo thứ tự . PE có thể giữ đươc thông tin về mối quan hệ về vị trí giữa các mã hóa trong dãy, từ đó khi đưa vào mô hình Transformer nó có thêm thông tin về vị trí, sư tương quan lẫn nhau giữa các mã hóa trong dãy, giúp cho việc dự đoán trở nên tốt hơn. Trong bài toán OCR, Transformer thường sẽ được kết hợp cùng với mạng trích xuất đặc trưng CNN. PE đóng vai trò quan trọng là cầu nối giữa CNN và Transformer. Ban đầu, PE được thiết kế để nhúng các giá trị vị trí thành 1 ma trận đặc trưng 1 chiều, tuy nhiên, điều này làm cho mô hình chỉ chú ý vào dãy tuần tự từ trái sang phải và nó không phù hợp với dữ liệu nhiều dòng.
Lấy cảm hứng từ ý tưởng được đưa ra trong bài báo On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention , chúng tôi áp dụng kỹ thuật mã hóa vị trí hai chiều (2D Positional Encoding - 2DPE) vào trong nhánh nhận dạng của mô hình. Trong khi PE làm mất đi thông tin vị trí theo chiều dọc của ảnh thì 2DPE có thể giải quyết được vấn đề này bằng cách cho mô hình chú ý là cả chiều dọc và chiều ngang của ảnh. Điều này làm cho mô hình có thể chú ý trên từng dòng của và từ trái qua phải. Do vậy, nhánh nhận dạng có thể học dữ liệu cong, xiêng, nhiều dòng mà không cần xoay ảnh.
Giả sử rằng chúng ta có một ma trận đặc trưng hai chiều được sinh ra bởi Mạng chia sẻ. Đặt nó là ma trận và có chiều , trong đó là kích thước của 1 lô dữ liệu, và lần lượt là chiều cao và chiều rộng của dữ liệu ảnh đầu vào. Cho rằng , , chúng ta có ma trận được xem là . Khi đó cơ chế tự chú ý được tính toán như sau:
Trong đó , và , và là trọng số tuyến tính của mô hình. là trọng số thể hiện hệ số chú ý của ma trận đặc trưng khi , trong khi ma trận truy vấn đặc trưng có kích thước , trong cơ chế tự chú ý thì .
Mã hóa vị trí hai chiều 2DPE được biểu diễn như sau:
Trong đó, , là các mã hóa vị trí theo chiều cao và chiều rộng có dạng hình sin :
Ở đây, và chỉ số vị trí trong dãy và số chiều. Các hệ số tỷ lệ, và , được tính toán từ ma trận đặc trưng đầu vào \textbf{S} với hai lớp tích chập được áp dụng vào tính năng trung bình toàn cục như sau:
Trong đó, là trọng số tuyến tính của mô hình. Hàm chỉ ra một hình thức gộp trung bình trên tất cả các tính năng của . Đầu ra được cho qua hàm kích hoạt sigmoid. và đã xác định ảnh hưởng trực tiếp đến mã hóa vị trí chiều rộng và chiều cao để kiểm soát tỷ lệ tương ứng giữa trục dọc và trục ngang để duy trì sự đa dạng về không gian. Theo đó, 2DPE cho phép mô hình phản ánh một cách thích ứng sự liền kề của chiều rộng và chiều cao khi tính toán trọng lượng của sự chú ý bằng cách sử dụng và
Nhánh nhận dạng
Chúng tôi sử dụng một kiến trúc mạng CNN nông đóng vai trò là thành phần để trích xuất tính năng và kiến trúc Transformer làm mô-đun bộ mã hóa và giải mã trong nhánh nhận dạng. Vì Mạng chia sẻ đóng một vai trò quan trọng trong trình trích xuất tính năng, chúng tôi chỉ cần chọn một kiến trúc CNN nông, cấu trúc được mô tả trong hình 6. Lựa chọn một mạng CNN nông là vừa không làm cho mô hình trở nên quá công kềnh và giảm sự tính toán không cần thiết.

Hình 6: Kiến trúc nhánh nhận dạng
Sau khi đưa ma trận đặc trưng và tọa độ bao đóng dự đoán được ở phần phát hiện đối tượng vào phương thức lấy mẫu, sau đó đưa qua một mạng CNN nông ta thu được một tensor . Trong thí nghiệm của chúng tôi, chúng tôi lựa chọn chiều cao , trong đó chiều rộng phụ thuộc vào từng lô dữ liệu. Cho đi qua mã hóa vị trí không gian hai chiều (2DPE), thu được . Mô-đun Transformer lấy là đầu vào của mô hình mã hóa, trong đó cùng với đầu ra của mô hình mã hóa là đầu vào của mô hình giải mã. Trong đó là tổng số lượng ký tự trong văn bản, là vị trí tương ứng của kí từ trong tập từ điển. Để giúp mô hình chống hiện tượng học quá khớp, chúng tôi sử dụng kỹ thuật làm mượt nhãn cho hàm phạt, việc sử dụng kĩ thuật này làm cho mô hình học tốt và đạt kết quả cao hơn do chống được hiện tượng học quá khớp.
Việc sử dụng kĩ thuật làm mượt nhãn, chúng tôi thay thể véc-tơ mã hóa one-hot với việc kết hợp và phân phối đều như sau:
Trong đó là số lượng nhãn và là siêu tham số để xác định lượng mà muốn làm mượt nhãn. Hàm phạt của nhánh nhận dạng được viết như sau:
Trong đó được tính bởi hàm kích hoạt softmax:
là giá trị tương ứng của lớp . Kết hợp hàm phạt của nhánh phát hiện, hàm phạt cuối cùng của mô hình như sau:
Kết quả áp dụng mô hình vào bài toán phát hiện và nhận dạng biển số xe Việt Nam trên
Hình 7: hình ảnh dữ liệu biển số xe Việt Nam
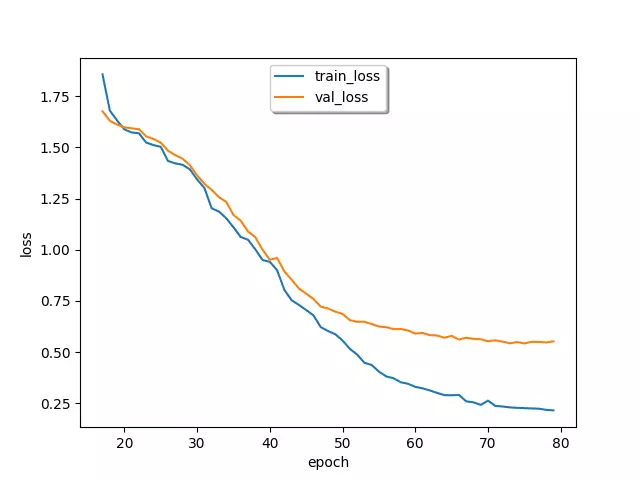
Hình 8: Biểu đồ thay đổi giá trị hàm mất mát trong quá trình huấn luyện
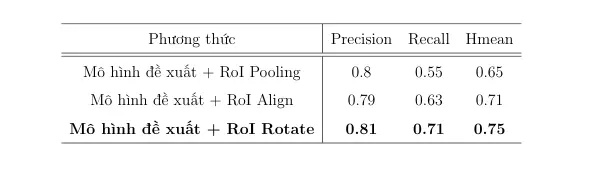
Hình 9: Kết quả thực nghiệm trên bộ dữ liệu tính theo độ đô cuộc thi phát hiện và nhận dạng văn bản IC
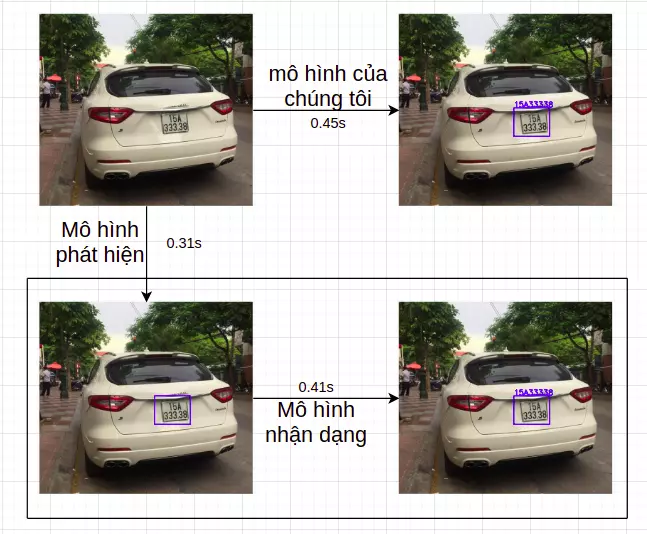
Hình 10: Kết quả so sánh tốc dộ dự đoán giữa mô hình 1 pha mà sử dụng 2 mô hình riêng biệt

Hình 11: Một số trường hợp dự đoán của mô hình
Kết luận
Mô hình là 1 sự kết hợp của một số kĩ thuật đã có hiện nay để giải quyết đồng thời 2 bài toán đó là phát hiện và nhận dạng biển số xe nhiều dòng. Mô hình có khả năng huấn luyện và dự đoán đồng thời 2 tác vụ trên, ngoài ra mô hình còn giúp tăng đáng kể thời gian dự đoán so với việc sử dụng 2 mô hình riêng biệt. Bài viết này của mình đưa ra mô hướng tiếp cận mới cho bài toán phát hiện và nhận dạng biển số xe nhiều dòng tại Việt Nam. Nếu thấy bài viết bổ ích thì chần chờ gì nữa mà không upvote cho mình nhé, cảm ơn các bạn.