Hầu hết chúng ta đã quá quen thuộc với bài toán phát hiện đối tượng người: chỉ đơn giản là vẽ bounding box quanh đối tượng được cho là người. Vậy làm thế nào để biết người đó đang hoạt động hay đang làm gì? Để trả lời cho câu hỏi này, có nhiều phương pháp, trong đó ước lượng tư thế (pose estimation) là cách thường được sử dụng. Đối với bài toán phát hiện tư thế lại có nhiều mô hình học máy giải quyết vấn đề này và trong đó lại có YOLO-POSE. Nói về Yolo thì cũng đã quá quen thuộc trong các bài toán phát hiện đối tượng nói chung, hay đối tượng đặc thù như phát hiện khuôn mặt (Yolo-face), không bỏ qua nhiệm vụ phát hiện tư thế, Yolo-pose được sinh ra là đại diện tham gia cho dòng họ Yolo lâu đời.
Bài toán phát hiện tư thế
Bài toán phát hiện tư thế con người (2D) là nhiệm vụ với đầu vào (input) là một ảnh bao gồm một hoặc nhiều người, mục tiêu đầu ra (output) là phát hiện ra từng người (bounding box) và vị trí các khớp điểm trên cơ thể họ (keypoints). Đây là một thử thách khó khi gặp phải nhiều vấn đề trong quá trình suy luận như bộ phận người bị che khuất, có quá nhiều người đi lại trong video,... Có hai hướng giải pháp phổ biến cho bài toán là Top-down và Bottom-up. Với Top-down, là cách tiếp cận two-stage, tức là ban đầu sẽ sử dụng một mô hình phát hiện người với độ chính xác cao và sau đó ước lượng tư thế cho từng người đã được phát hiện. Phương pháp này tốn nhiều thời gian xử lý, nhất là khi số lượng người trong ảnh ngày càng tăng lên. Ngược lại, với Bottom-up, thời gian xử lý sẽ nhanh vì sử dụng heat map để phát hiện tất cả các điểm keypoints một lần và hậu xử lý khá phức tạp để gộp nhóm các keypoints cho từng người riêng biệt. Tuy nhiên, ngay cả khi đã hậu xử lý, heat map cũng không đủ sắc nét có thể phân biệt chính xác hai điểm khớp gần nhau cùng loại (ví dụ hai đầu gối, hai cổ tay hay hai khủy tay của hai người đi sát cạnh nhau) và như vậy độ chính xác cũng sẽ giảm xuống.
Yolo pose giải quyết vấn đề
2.1 Tổng quát
Yolo pose cũng là một phương pháp single shot để giải quyết vấn đề real time, tuy nhiên khác với bottom up, nó không sử dụng heatmap. Về cơ bản nó cũng dựa trên phiên bản phát hiện đối tượng của YOLO và có dự đoán thêm các điểm keypoints. Với phát hiện tư thế của người sẽ có 17 điểm keypoints (lấy theo dataset COCO). Dưới đây là kiến trúc của Yolo-pose dựa trên Yolov5:
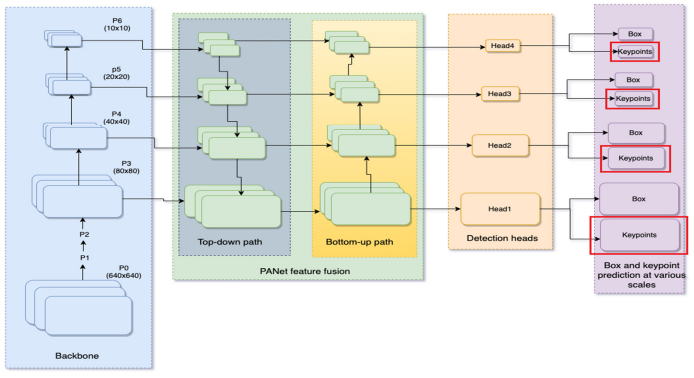 Nhìn vào hình vẽ có thể thấy rằng, Yolo-pose sử dụng backbone CSP-darknet53 và PANet để phát hiện các đặc trưng với nhiều tỉ lệ khác nhau, với mỗi tỷ lệ lại có một đầu ra (head), và nó sẽ phải dự đoán thêm các điểm keypoint cùng với bounding box. Điều này sẽ giúp cho mô hình dự đoán các đối tượng với nhiều tỷ lệ to nhỏ khác nhau, sau cùng sẽ được tổng hợp lại, đi qua NMS (Non-Maximum Suppression) để loại bỏ các dự đoán trùng lặp. Đầu ra dự đoán cho một đối tượng sẽ gồm 4 thành phần:
Nhìn vào hình vẽ có thể thấy rằng, Yolo-pose sử dụng backbone CSP-darknet53 và PANet để phát hiện các đặc trưng với nhiều tỉ lệ khác nhau, với mỗi tỷ lệ lại có một đầu ra (head), và nó sẽ phải dự đoán thêm các điểm keypoint cùng với bounding box. Điều này sẽ giúp cho mô hình dự đoán các đối tượng với nhiều tỷ lệ to nhỏ khác nhau, sau cùng sẽ được tổng hợp lại, đi qua NMS (Non-Maximum Suppression) để loại bỏ các dự đoán trùng lặp. Đầu ra dự đoán cho một đối tượng sẽ gồm 4 thành phần:
- Bounding box với tọa độ tâm box (cx, cy), chiều rộng chiều cao w-h của box
- Độ tin cậy có vật thể của box box_conf
- Độ tin cậy phân loại đối tượng class_conf (với phát hiện tư thế cho người thì luôn là 1 lớp-class person)
- 17 điểm keypoints tương ứng với người, với mỗi điểm keyponts này sẽ có 3 phần dự đoán tương ứng là {x,y, conf} - tọa độ (x,y), độ tự tin có điểm đó xuất hiện trong hình ảnh.
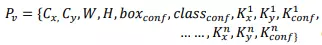
2.2 Anchor box
Cũng như Yolo bình thường, Yolo pose cũng sử dụng anchor box, mỗi anchor ứng với một người, và ngoài lưu trữ 4 điểm cho bounding box, anchor của pose còn có các điểm keypoints (2D). Bounding box anchor và các điểm keypoints sẽ được tính bằng biến đổi so với điểm tâm của anchor. Ví dụ như điểm tâm anchor là (50, 50), điểm keypoint 1 là (70, 60) thì sau khi biến đổi theo tâm nó sẽ là (70-50, 60-50) = (20,10). Điều này giúp mô hình sẽ tập trung vào các đặc trưng cục bộ xung quanh anchor thay vì bị ảnh hưởng bởi vị trí tuyệt đối trong ảnh và khi các keypoint được biểu diễn dưới dạng tương đối so với tâm của anchor, mô hình trở nên ít nhạy cảm hơn với sự thay đổi vị trí của đối tượng trong ảnh, điều này rất có lợi vì trong video các đối tượng luôn thay đổi vị trí trong ảnh. Riêng phần bounding box sẽ được chuẩn hóa (normalize) dựa trên chiều cao và chiều rộng của anchor, để giúp mô hình không bị lệ thuộc vào kích thước tuyệt đối của các đối tượng, mà thay vào đó học cách nhận diện các tỉ lệ và hình dạng của đối tượng, và cũng đảm bảo rằng các giá trị đầu vào cho mô hình có một phạm vi giá trị nhất quán. Ngoài ra phương pháp anchor box như này có thể mở rộng để áp dụng cho các mô hình phát hiện đối tượng không cần anchor như YOLOX và FCOS.
2.3 Hàm mất mát
Hàm mất mát của Yolo-pose được tính toán dựa trên việc so sánh dự đoán với các ground truth (bounding boxes và keypoints) trên nhiều mức tỷ lệ (scale) và anchor boxes khác nhau. Loss tại mỗi vị trí và anchor ở scale cụ thể là hợp lệ nếu một ground-truth box được khớp với anchor đó. Tổng loss được tính bằng cách tổng hợp tất cả các loss trên các scales, anchors, và vị trí. Nó có 4 thành phần và được nhân hệ số để cân bằng:
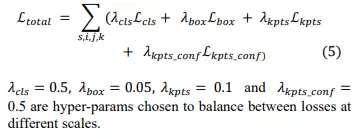
- Hàm CIoU loss cho bounding box. Nó là một cải tiến của IoU loss giống như GIoU, DIoU... Nếu GIoU giải quyết vấn đề hai box không giao nhau dựa trên vùng diện tích bao phủ hai box, DIoU thì xét khoảng cách giữa các tâm của box dự đoán và ground-truth box , giúp các box dự đoán gần trung tâm của ground-truth hơn, cải thiện độ chính xác. CIoU loss kết hợp ưu điểm của cả IoU và DIoU, đồng thời thêm vào yếu tố tỉ lệ khung hình (aspect ratio), tỷ lệ chiều rộng và chiều cao của bounding box, điều này giúp cải thiện độ chính xác và độ nhất quán của dự đoán bounding box.
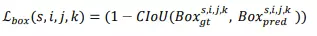
- Hàm Keyponts Loss được tính từ các OKS (Object Keypoint Similarity) gọi là độ tương đồng của mỗi điểm keypoints so với ground-truth keypoints. Hàm có các thành phần khoảng cách Euclid giữa 2 điểm cho biết mức độ sai lệch của mô hình khi dự đoán vị trí của keypoint. Tỷ lệ của đối tượng đánh giá công bằng cho các đối tượng lớn và nhỏ. Trọng số quan trọng của keypoint, trọng số này xác định độ ảnh hưởng của mỗi keypoint. Và cờ hiển thị (visibility flag) vị trí của ground-truth keypoint trên ảnh (giá trị bằng 0 nếu keypoint không xuất hiện-ví dụ như ảnh từ vai hất lên thì những điểm hông, chân sẽ không có trong ảnh; bằng 1 nếu keypoint có trong ảnh).
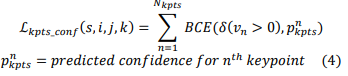
- Hàm mất mát độ tin cậy của các điểm keypoints. Nó được tính bằng Binary Cross-Entropy (BCE) để đo độ sai khác giữa độ tự tin của keypoints dự đoán và ground-truth.
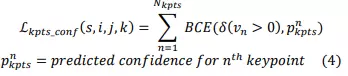
- Hàm mất mát phân loại lớp. Nếu chỉ phân loại cho một lớp người (có người hay không) thì cũng sử dụng Binary Cross-Entropy (BCE), với nhiều lớp thì dùng Categorical Cross-Entropy (CCE)