Sau seri HIVE thì mình sẽ mang đến tiếp tục seri về Apache Presto, thằng này thì có thể sử dụng HIVE như là một connector trong kiến trúc của nó, cùng tìm hiểu về nó nhé, let's start!
Apache Presto là một công cụ SQL phân tán mã nguồn mở. Presto bắt nguồn từ Facebook cho nhu cầu phân tích dữ liệu và sau đó được mở nguồn. Bây giờ, Teradata tham gia cộng đồng Presto và cung cấp sự hỗ trợ.
Apache Presto rất hữu ích để thực hiện các truy vấn thậm chí là hàng petabyte dữ liệu. Kiến trúc mở rộng và giao diện plugin lưu trữ rất dễ tương tác với các hệ thống tệp khác. Hầu hết các công ty công nghiệp tốt nhất hiện nay đang áp dụng Presto vì tốc độ tương tác và hiệu suất độ trễ thấp.
Chúng ta cùng đi vào khám phá kiến trúc, cấu hình và plugin lưu trữ của Presto. Và cùng thảo luận về các truy vấn cơ bản và nâng cao, cuối cùng là kết thúc với các ví dụ thời gian thực. Hướng dẫn này sẽ cung cấp cho bạn đủ kiến thức để có thể hiểu biết về Apache Presto. Trước khi tiếp tục theo dõi loạt hướng dẫn này, bạn nên hiểu rõ về Core Java, DBMS và bất kỳ hệ điều hành Linux nào.
Phân tích dữ liệu là quá trình phân tích dữ liệu thô để thu thập thông tin liên quan nhằm đưa ra quyết định tốt hơn. Nó chủ yếu được sử dụng trong nhiều tổ chức để đưa ra các quyết định kinh doanh. Phân tích dữ liệu lớn liên quan đến một lượng lớn dữ liệu và quá trình này khá phức tạp, do đó các công ty sử dụng các chiến lược khác nhau.
Ví dụ, Facebook là một trong những công ty cung cấp dữ liệu hàng đầu và có kho dữ liệu lớn nhất trên thế giới. Dữ liệu kho của Facebook được lưu trữ trong Hadoop để tính toán quy mô lớn. Sau đó, khi dữ liệu kho tăng lên đến petabyte, họ quyết định phát triển một hệ thống mới với độ trễ thấp. Vào năm 2012, các thành viên trong nhóm Facebook đã thiết kế “Presto” để phân tích truy vấn tương tác sẽ hoạt động nhanh chóng ngay cả với hàng petabyte dữ liệu.
Định nghĩa : Apache Presto là gì ?
Apache Presto là một công cụ thực thi truy vấn song song phân tán, được tối ưu hóa cho độ trễ thấp và phân tích truy vấn tương tác. Presto chạy các truy vấn một cách dễ dàng và mở rộng quy mô mà không mất thời gian kể cả từ gigabyte đến petabyte.
Một truy vấn Presto duy nhất có thể xử lý dữ liệu từ nhiều nguồn như HDFS, MySQL, Cassandra, Hive và nhiều nguồn dữ liệu khác. Presto được xây dựng bằng Java và dễ dàng tích hợp với các thành phần cơ sở hạ tầng dữ liệu khác. Presto rất mạnh và các công ty hàng đầu như Airbnb, DropBox, Groupon, Netflix đang áp dụng nó.
Tính năng
Presto chứa các tính năng sau:
- Kiến trúc đơn giản và có thể mở rộng.
- Đầu nối có thể cắm được - Presto hỗ trợ trình kết nối có thể cắm được để cung cấp siêu dữ liệu và dữ liệu cho các truy vấn.
- Thực thi theo đường ống pipeline - Tránh chi phí độ trễ I/O không cần thiết.
- Các chức năng do người dùng xác định - Các nhà phân tích có thể tạo các chức năng tùy chỉnh do người dùng xác định để di chuyển dễ dàng.
- Xử lý cột được vector hóa.
Lợi ích
Dưới đây là danh sách các lợi ích mà Apache Presto cung cấp:
- Các phép toán SQL chuyên dụng
- Dễ dàng cài đặt và gỡ lỗi
- Lưu trữ đơn giản trừu tượng
- Nhanh chóng chia tỷ lệ dữ liệu petabyte với độ trễ thấp
Ứng dụng
Presto hỗ trợ hầu hết các ứng dụng công nghiệp tốt nhất hiện nay. Hãy cùng xem qua một số ứng dụng đáng chú ý.
-
Facebook - Facebook đã xây dựng Presto cho nhu cầu phân tích dữ liệu. Presto dễ dàng mở rộng tốc độ lớn của dữ liệu.
-
Teradata - Teradata cung cấp các giải pháp đầu cuối trong phân tích Dữ liệu lớn và lưu trữ dữ liệu. Đóng góp của Teradata cho Presto giúp nhiều công ty có thể đáp ứng mọi nhu cầu phân tích dễ dàng hơn.
-
Airbnb - Presto là một phần không thể thiếu của cơ sở hạ tầng dữ liệu Airbnb. Hàng trăm nhân viên đang thực hiện các truy vấn mỗi ngày với công nghệ này.
Why Presto?
Presto hỗ trợ ANSI SQL tiêu chuẩn giúp các nhà phân tích và phát triển dữ liệu rất dễ dàng. Mặc dù nó được xây dựng bằng Java, nó tránh được các vấn đề điển hình của mã Java liên quan đến cấp phát bộ nhớ và thu gom rác. Presto có kiến trúc trình kết nối thân thiện với Hadoop. Nó cho phép dễ dàng cắm vào các hệ thống tập tin.
Presto chạy trên nhiều bản phân phối Hadoop. Ngoài ra, Presto có thể tiếp cận từ nền tảng Hadoop để truy vấn Cassandra, cơ sở dữ liệu quan hệ hoặc các kho dữ liệu khác. Khả năng phân tích đa nền tảng này cho phép người dùng Presto trích xuất giá trị kinh doanh tối đa từ gigabyte đến petabyte dữ liệu.
Kiến trúc của Presto
Kiến trúc của Presto gần như tương tự như kiến trúc DBMS MPP (xử lý song song hàng loạt) cổ điển. Sơ đồ sau minh họa kiến trúc của Presto.
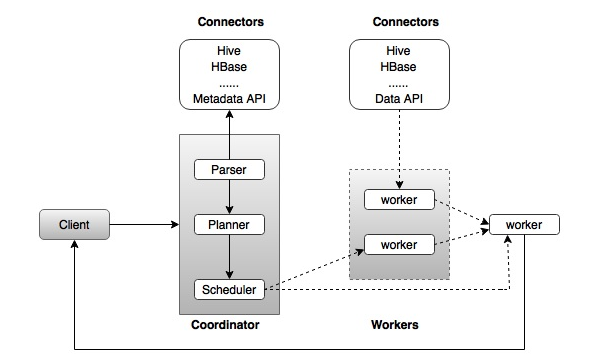
Sơ đồ trên bao gồm các thành phần khác nhau. Bảng sau mô tả chi tiết từng thành phần.
| STT | Thành phần và Mô tả |
|---|---|
| 1 | Client: Client (Presto CLI) gửi các câu lệnh SQL cho Coordinator để nhận kết quả. |
| 2 | Coordinator (điều phối viên): Coordinator là một daemon chính. Điều phối viên ban đầu phân tích cú pháp các truy vấn SQL sau đó phân tích và lập kế hoạch cho việc thực thi truy vấn. Bộ lập lịch thực hiện thực thi đường ống, giao công việc cho nút gần nhất và giám sát tiến độ. |
| 3 | Connector ( trình kết nối ) : Các plugin lưu trữ được gọi là trình kết nối. Hive, HBase, MySQL, Cassandra và nhiều hơn nữa hoạt động như một trình kết nối; nếu không, bạn cũng có thể triển khai một tùy chỉnh. Trình kết nối cung cấp siêu dữ liệu và dữ liệu cho các truy vấn. Coordinator sử dụng trình kết nối để lấy siêu dữ liệu nhằm xây dựng kế hoạch truy vấn. |
| 4 | Worker: Coordinator giao nhiệm vụ cho các nút worker. Worker lấy dữ liệu thực tế từ trình kết nối. Cuối cùng, nút worker cung cấp kết quả cho máy khách. |
Workflow
Presto là một hệ thống phân tán chạy trên một cụm các nút. Công cụ truy vấn phân tán của Presto được tối ưu hóa để phân tích tương tác và hỗ trợ ANSI SQL tiêu chuẩn, bao gồm các truy vấn phức tạp, tổng hợp, liên kết và chức năng cửa sổ. Kiến trúc Presto đơn giản và có thể mở rộng. Ứng dụng khách Presto (CLI) gửi các câu lệnh SQL tới bộ điều phối daemon chính.
Bộ lập lịch kết nối thông qua đường ống thực thi. Bộ lập lịch chỉ định công việc cho các nút gần nhất với dữ liệu và giám sát tiến độ. Điều phối viên giao nhiệm vụ cho nhiều nút công nhân và cuối cùng nút công nhân gửi lại kết quả cho máy khách. Máy khách lấy dữ liệu từ quá trình đầu ra. Khả năng mở rộng là thiết kế quan trọng. Các trình kết nối phù hợp như Hive, HBase, MySQL, v.v., cung cấp siêu dữ liệu và dữ liệu cho các truy vấn. Presto được thiết kế với “sự trừu tượng hóa lưu trữ đơn giản” giúp dễ dàng cung cấp khả năng truy vấn SQL chống lại các loại nguồn dữ liệu khác nhau này.
Mô hình thực thi
Presto hỗ trợ công cụ thực thi và truy vấn tùy chỉnh với các toán tử được thiết kế để hỗ trợ ngữ nghĩa SQL. Ngoài việc lập lịch được cải thiện, tất cả quá trình xử lý đều nằm trong bộ nhớ và được kết nối trên mạng giữa các giai đoạn khác nhau. Điều này tránh chi phí độ trễ I/O không cần thiết.
That's all về việc giới thiệu về Apache Presto chung chung, tiếp sau mình sẽ viết về cách cài đặt, config và sử dụng Apache Presto như thế nào nhé, mọi người cùng đón xem ^^
Source: https://www.tutorialspoint.com/