1. Giới thiệu
Trước khi đi vào nội dung chính mình muốn kể 1 câu chuyện sau:
Mình và thằng bạn mình có đầu tư tiền ảo, nó nảy ra 1 ý tưởng là lấy data từ các sàn để có thể tự cài các phân tích kỹ thuật trên các biểu đồ nến nhật, từ đó có thể biết đâu là thời điểm vào lệnh mua coin hoặc vào lệnh long/short.
Mình thấy ý tưởng này rất hay, mình đã nghĩ tới nhiều database để có thể lưu trữ hàng triệu record mỗi ngày như Mysql, HBase, TimescaleDB, thậm chí cả Aerospike (lưu trên cache) ???. Sau 1 thời gian đắn đo suy nghĩ mình thấy các database trên đều không phù hợp: Mysql thì nó quá chậm nếu có quá nhiều records, HBase nghe cũng hợp lý đấy nhưng có vẻ không realtime được, TimescaleDB nghe cũng vẻ đc vì nó thuộc Timeseries DB nhưng để phân tích phức tạp trên dữ liệu thì hơi có vấn đề, lưu trên Cache thì mình đùa thôi (không bị dở hơi).
Vậy nên mình lang thang trên google, các diễn đàn lớn nhỏ thì thấy Apache Druid có vẻ OK, càng khám phá bên trong thì mình thấy nó càng hợp với nhu cầu của mình.
Trong bài biết này, mình sẽ giới thiệu và trình bày về Apache Druid, để các bạn đọc có cái nhìn tổng quan về nó nhằm đánh giá những lợi ích mà nó đem lại cho job của bạn.

Hãy tưởng tượng rằng doanh nghiệp hoặc nền tảng của bạn đang tạo ra một lượng lớn dữ liệu mỗi giây và đống dữ liệu đó sẽ trở lên vô nghĩa nếu bạn không phân tích, bóc tách chi tiết các thông tin trong dữ liệu. Để thực hiện được việc đó bạn phải dùng nhiều câu truy vấn phức tạp, điều đó sẽ làm cho máy chủ có độ trễ và tải tăng theo cấp số nhân. Và Apache Druid ra đời để giải quyết vấn đề trên một cách dễ dàng.
Druid ra đời vào năm 2011 và được chuyển sang Giấy phép Apache vào tháng 2 năm 2015, được viết bằng Java. Druid là một kho dữ liệu phân tích hiệu suất cao, thời gian thực cho dữ liệu hướng sự kiện, là một hệ thống phân tán với khá nhiều thành phần, để phân tích dữ liệu theo phương pháp phân tích slice-and-dice trên tập dữ liệu lớn (OLAP). Druid thường được dùng làm cơ sở dữ liệu cho các trường hợp sử dụng thời gian thực, có tốc độ truy vấn nhanh.
Cách thức lưu trữ và truy vấn hoàn toàn dựa trên timestamp, rất phù hợp với những truy vấn liên quan đến thời gian. Nó có thể mở rộng theo chiều ngang một cách dễ dàng.
Các lĩnh vực phổ biến cho Druid:
- Clickstream analytics (web and mobile analytics)
- Network telemetry analytics (network performance monitoring)
- Server metrics storage
- Supply chain analytics (manufacturing metrics)
- Application performance metrics
- Digital marketing/advertising analytics
- Business intelligence / OLAP
Hiện tại mình đang sử dụng Druid trong nhiều việc khác nhau :
- Một job vui vui là lấy dữ liệu chứng khoán, tiền ảo để cài những phân tích kỹ thuật vào đó từ đó đặt lệnh mà ăn tiền thôi, cơ mà chắc mấy kỹ thuật mình cài vào bị ghẻ quá nên toàn cháy tài khoản

- Phục vụ cho các job cần lưu trữ và tổng hợp lại theo từng giờ, ngày, ....
Còn nhiều ứng dụng nữa nhưng chưa nghĩ ra, bạn nào có ý tưởng nào hay thì comment gợi ý giúp mình nhé.
2. Sơ đồ kiến trúc
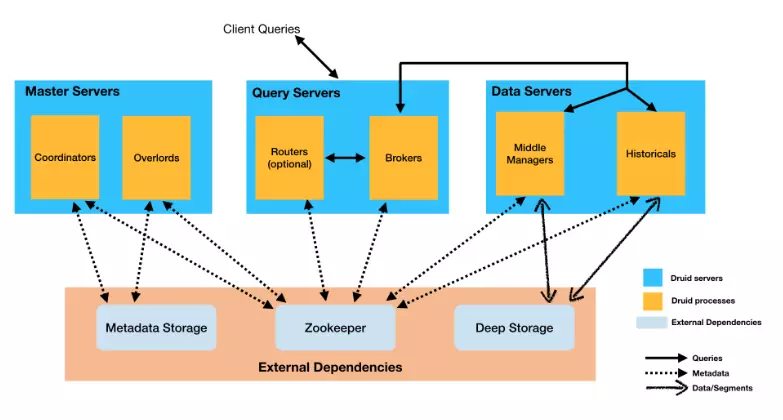
2.1. Server
Apache Druid đã đề suất có 3 loại máy chủ: Master Servers, Query Servers và Data Servers.
- Master: máy chủ này chịu trách nhiệm bắt đầu các công việc nhập dữ liệu mới và xem xét tính khả dụng của data trên Data servers. Bao gồm Coordinator process và Overlord process.
- Query: cung cấp các điểm cuối mà client tương tác, định tuyến các truy vấn đến Data servers hoặc Query server khác. Bao gồm Broker process và Router process.
- Data: thực thi các công việc nhập và lưu dữ liệu. Bao gồm Historical process và MiddleManager process.
2.2. Process
Druid có kiến trúc phân tán, mutil-process. Mỗi process của Druid có thể được cấu hình và mở rộng một cách độc lập, điều đó đem lại sự linh hoạt tối đa đối với cluster đồng thời cũng cung cấp khả năng chịu lỗi cao (khi có sự cố của 1 thành phần sẽ không gây ảnh hưởng ngay đến các thành phần khác). Druid có một số process sau đây:
- Coordinator process: quản lý tính khả dụng của data trên cluster, giám sát Historical processes trên Data servers. Thực hiện việc chỉ định các segment cho server cụ thể và đảm bảo các segment trong Historical processes được cân bằng.
- Overlord process: giám sát và giao nhiệm vụ cho MiddleManager process trên Data servers.
- Broker process: nhận truy vấn từ client và chuyển tiếp các truy vấn đó cho Data Servers, Broker sẽ tổng hợp kết quả từ Data Servers để trả ra kết quả cuối cùng của truy vấn.
- Router process: tùy chọn các process để có thể định tuyến các yêu cầu đến Broker, Coordinator và Overlord.
- Historical process: xử lý việc lưu trữ và truy vấn dữ liệu, Historical process tải các segment từ Deep storage và trả lời các truy vấn trên các segment này. Chú ý: process này chỉ có quyền đọc.
- MiddleManager process: xử lý việc nhập dữ liệu mới vào cluster, chịu trách nhiệm cho việc đọc data từ các nguồn bên ngoài và xuất ra các segment.
2.3. External dependencies
Ngoài các process tích hợp bên trong, Druid còn có các external dependencies. Những thứ này nhằm mục đích tận dụng cơ sở hạ tầng hiện có:
- Deep storage: là nơi các phân đoạn được lưu trữ, mức độ bền vững của dữ liệu phụ thuộc vào cơ sở hạ tầng của Deep storage. Dù Druid mất bao nhiêu nodes cũng không ảnh hưởng đến dữ liệu, nhưng khi các segment ở Deep storage bị mất thì dữ liệu ở các segment đại diện sẽ mất theo. Khi truy vấn Historical process không đọc từ Deep storage mà sẽ đọc từ các segment đã được tìm nạp trước đó. Điều này giúp Druid có độ trễ thấp, nhưng yêu cầu phải có đủ dung lượng cho Deep storage và Historcal process.
- Metadata storage: lưu trữ các thông tin của hệ thống như:
- Segment table: lưu trữ các segment có sẵn trong hệ thống.
- Rule table: lueu trữ các rule khác nhau về vị trí các segment, các rule này được Coordinator sử dụng khi đưa ra các quyết định phân bổ segment về các cluster.
- Config table: lưu trữ các cấu hình trong thời gian chạy.
- Task-related tables: được Overlord và MiddleManager sử dụng khi quản lý các task.
- Audit table: lưu trữ lịch sử kiểm tra cho các sự thay đổi của cấu hình.
- ZooKeeper: quản lý trạng thái của tất cả các cluster, các hoạt động mà ZooKeeper quản lý là:
- "Bầu cử" lãnh đạo Coordinator.
- Hỗ trợ giao thức "publishing" segment từ Historical.
- Hỗ trợ giao thức load/drop segment giữa Coordinator and Historical.
- "Bầu cử" lãnh đạo Overlord.
- Quản lý tác vụ Overlord và MiddleManager.
3. Datasources and segments
Từ nãy nói đến dữ liệu, segment chắc hẳn các bạn hơi khó hiểu, phần này mình sẽ giải thích kỹ hơn về cách thức tổ chức và lưu trữ dữ liệu.
Dữ liệu của Druid được lưu trong "datasource". Mỗi datasource được phân vùng theo thời gian và có thể được phân vùng theo các thuộc tính khác, mỗi phân vùng này được gọi là chuck (ví dụ: 1 giờ, 1 ngày, ....). Trong mỗi chuck, dữ liệu được phân vùng thành 1 hay nhiều segment (mỗi segment là 1 tệp duy nhất chứa tối đa vài triệu rows, nó được gọi là segment files).
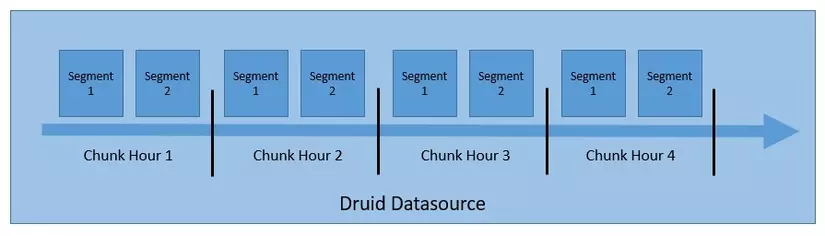
Quy ước đặt tên cho segment: datasource_intervalStart_intervalEnd_version_partitionNum
Ví dụ:
sampleData_2021-06-24T02:00:00:00Z_2021-06-24T03:00:00:00Z_v1_0
Apache Druid lưu trữ các index của nó trong các segment files và được phân vùng theo thời gian.
Dữ liệu cho mỗi column được trình bày trong các cấu trúc dữ liệu riêng biệt, bằng cách này Druid có thể giảm độ trễ truy vấn bằng cách chỉ scan những column thực sự cần thiết cho truy vấn.
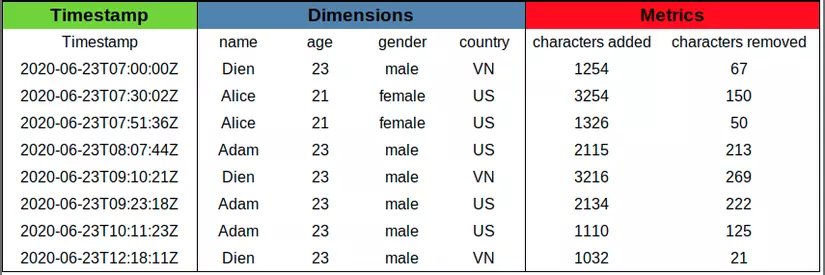
Có 3 loại column cơ bản:
- Timestamp: column này là mảng các giá trị số nguyên được nén bằng thuật toán LZ4 (nếu có cơ hội mình sẽ có 1 bài trình bày về thuật toán này)
- Metrics: tương tự như Timestamp column này là 1 mảng các giá trị số nguyên hoặc dấu phẩy động và cũng được nén bằng thuật toán LZ4
- Dimensions: column này là khác biệt so với 2 column trên vì nó hỗ trợ filter và group-by, vì vậy mỗi dimension yêu cầu cấc trúc dữ liệu như sau:
- Xây dựng một dictionary ánh xạ các giá trị trong từng dimension với ID là số nguyên.
- Danh sách các giá trị của column, được mã hóa bằng cách sử dụng dictionary
- Với mỗi giá trị trong column, 1 bitmap chỉ ra row nào chứa giá trị đó.
Nói nhiều cũng chẳng tưởng tượng nổi, sau đây mình sẽ cho các bạn 1 ví dụ về cấu trúc dữ liệu của Dimensions của bảng trên ở column "name".
1. Dictionary { "Dien": 0, "Alice": 1, "Adam": 2 } 2: Column data [0, 1, 1, 2, 0, 2, 2, 0] 3: Bitmaps value="Dien": [1, 0, 0, 0, 1, 0, 0, 1] value="Alice": [0, 1, 1, 0, 0, 0, 0, 0] value="Adam": [0, 0, 0, 1, 0, 1, 1, 0]
Ví dụ về queries:
"Dien" OR "Alice" = [1, 0, 0, 0, 1, 0, 0, 1] OR [0, 1, 1, 0, 0, 0, 0, 0] = [1, 1, 1, 0, 1, 0, 0, 1]
4. Nhập dữ liệu
Apache Druid có thể nhập dữ liệu ở dạng denormalized như JSON, CSV,.. tuy nhiên mình khuyên các bạn dùng JSON vì nó dễ ?.
Ví dụ:
{"timestamp": "2021-06-25T11:58:39Z", "name": "Dien", "age" : "23", "gender" : "male", "handsome" : "true", "country":"Viet Nam", "city":"Ha Noi"}
Việc nhập dữ liệu được chia thành 2 giai đoạn chính:
- Indexing
- Fetching
4.1. Indexing
- Dữ liệu sẽ được thu thập từ Stream hoặc Files.
- Sau đó chúng được lập chỉ mục và tổng hợp lại.
- Cuối cùng là tạo các segment mới và published vào Deep Storage.
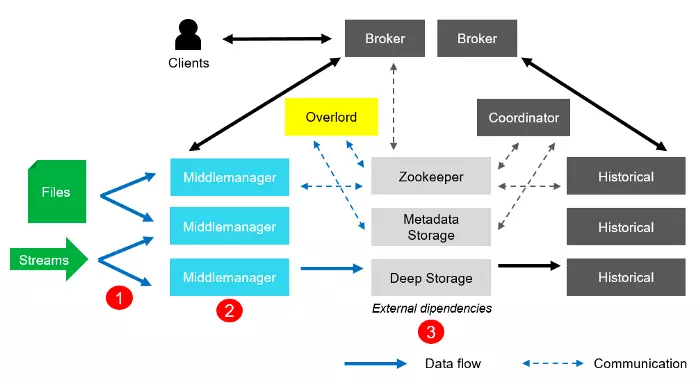
4.2. Fetching
Trong giai đoạn này, Fetching được thực hiện như sau:
4. Coordinator luôn lắng nghe Metadata Storage cho các segment mới được published.
5. Khi tìm thấy một segment mới đã được published và sử dụng nhưng không có sẵn, nó sẽ chọn một Historical Process để load segment đó vào bộ nhớ.
6. Cuối cùng Historical thực hiện nhiệm vụ của mình và bắt đầu cung cấp dữ liệu.
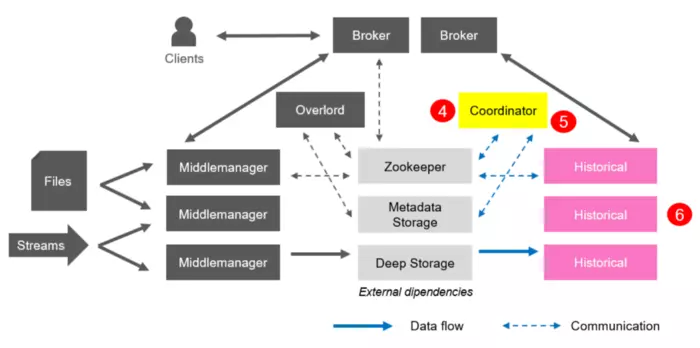
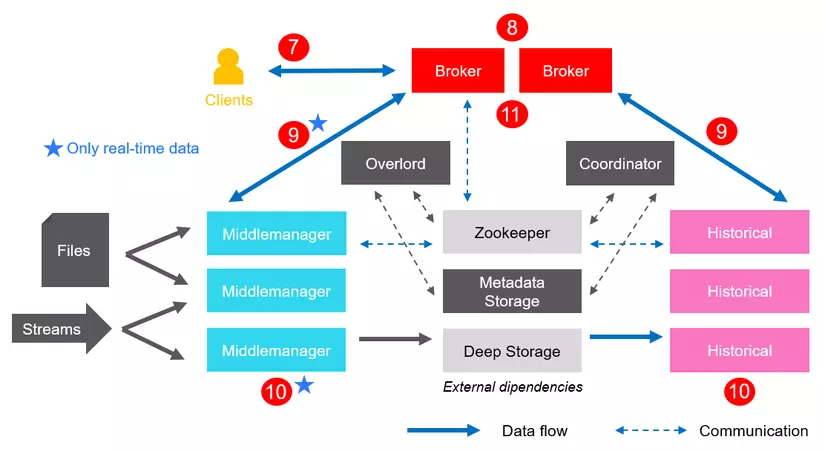
5. Xử lý truy vấn
- Client đưa ra truy vấn.
- Broker sẽ tiếp nhận truy vấn và sẽ xác định các phân đoạn tương ứng với câu truy vấn đó.
- Câu truy vấn sẽ được phân tách rồi gửi đến MiddleManger và Historical.
- Câu truy vấn sẽ được thực thi trên toàn bộ cụm.
- Các kết quả truy vấn được Broker thu thập và tổng hợp lại, cuối cùng trả lại kết quả cho client.
6. Kết luận
Cấu trúc của Apache Druid không thực sự nhẹ, vì có nhiều thành phần. Tuy nhiên, điều này cho phép mở rộng Druid theo chiều ngang , chỉ đơn giản bằng cách tăng số lượng các node (MiddleManagers, Historicals, ...) Hơn nữa, nó mang lại hiệu quả cao về mặt xử lý dữ liệu, cả theo thời gian thực và batch.
Hi vọng với những điều mà mình đã giới thiệu và trình bày ở trên, phần nào sẽ giúp các bạn hiểu về Apache Druid. Chỉ có thể hiểu rõ về nó các bạn mới biết nó dùng để làm gì, áp dụng vào job nào cho phù hợp.
Phần 2 mình sẽ đi vào thực hành, hướng dẫn từ A-Z cách cài đặt và code demo.
Chờ nhé ...