1. Mở đầu
Attention là một kĩ thuật được sử dụng trong các mạng neural, kỹ thuật này được sử dụng trong các mô hình thực hiện các task như dịch máy hay ngôn ngữ tự nhiên. BERT và GPT là 2 mô hình điển hình có sử dụng Attention. Attention là thành phần chính tạo nên sự đình đám của mô hình Transformer, mô hình này chính là sự đột phá trong các bài toán xử lý của NLP so với các mạng neural hồi quy. Vậy Attention là gì mà tại sao nó lại là sự khác biệt đến vậy, hãy cũng tôi đi tìm hiểu trong bài viêt ngày hôm nay với tiêu đề “All you need Attention - Tất tần tận về Attention”
2. Động lực cho sự phát triển của Attention
2.1. Recurrent Neural Network (RNN) và sự hạn chế đáng kể
2.1.1. Ý tưởng cốt lõi của RNN
Con người chúng ta không thể bắt đầu suy nghĩ của mình tại tất cả các thời điểm, cũng giống như việc bạn đang đọc bài viết này, bạn hiểu mỗi chữ ở đây dựa vào các chữ mà bạn đã đọc và hiểu trước đó, chứ không phải đọc xong là quên chữ đó đi rồi đến lúc gặp thì lại phải đọc và tiếp thu lại. Giống như trong bài toán của chúng ta. Các mô hình mạng nơ-ron truyền thống lại không thể làm được việc trên. Vì vậy mạng nơ-ron hồi quy (RNN) được sinh ra để giải quyết việc đó. Mạng này chứa các vòng lặp bên trong cho phép nó lưu lại các thông tin đã nhận được. RNN là một thuật toán quan trọng trong xử lý thông tin dạng chuỗi hay nói cách khác là dạng xử lý tuần tự.
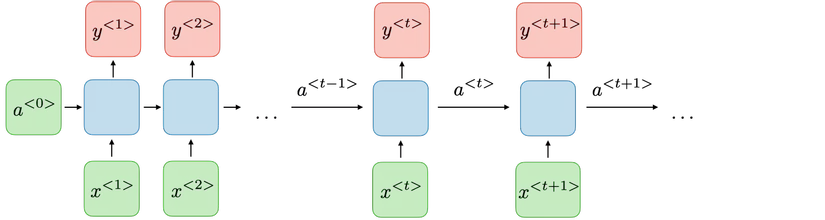
Cấu trúc cơ bản của RNN
Vậy như nào là xử lý tuần tự - Xử lý tuần tự là mỗi block sẽ lấy thông tin của block trước và input hiện tại làm đầu vào
Tại mỗi bước t, giá trị kích hoạt và đầu ra được biểu diễn như sau:
ta có thể viết gọn lại như sau:
Từ với ta có công thức tính đầu ra tương ứng :
Trong đó: là các trọng số chia sẻ tạm thời trong từng hidden state tương ứng
Hãy cùng đi đến phần chúng ta cần để ý trong phần này đó là ưu và nhược điểm của RNN
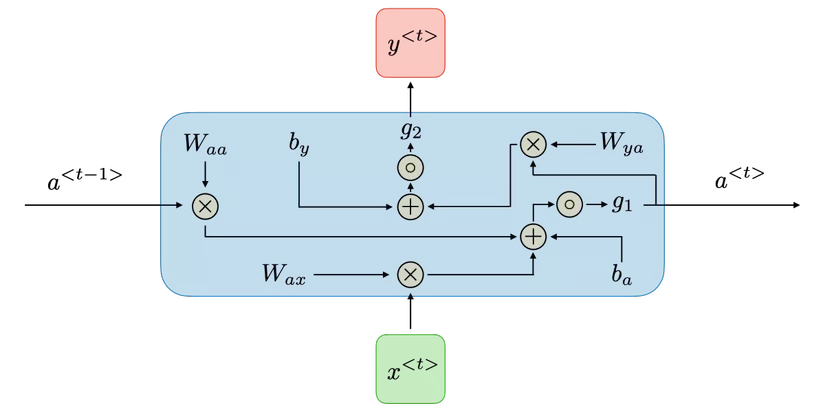
Cấu trúc một block trong RNN
2.1.2. Ưu điểm và nhược điểm của RNN
| Ưu điểm | Nhược điểm |
|---|---|
| Khả năng xử lý các chuỗi đầu vào có độ dài khác nhau | Tính toán khá chậm |
| Kích cỡ mô hình không bị tăng lên theo kích thước đầu vào | Khó truy cập lại thông tin đã đi qua ở một khoảng thời gian dài trước đó - hay còn gọi là bị quên thông tin khi gặp nhiều thông tin mới |
| Quá trình tính toán có sử dụng thông tin trước đo | Phải thực hiện tuần tự nên không tận dụng triệt để được khả năng tính toán song song của GPU |
| Trọng số được chia sẻ trong suốt qua trình học | Vanishing gradient |
2.1.3. Vấn đề của RNN
Một điểm nổi bật của RNN là nó có thể lấy các thông tin trước đó để dự đoán cho hiện tại. Ví dự như “Team AI toàn trai đẹp” thì chỉ cần đọc tới “Team AI toàn trai” là đủ biết chữ tiếp theo là “đẹp” rồi. Nhưng… đó là với chuỗi ngắn thôi, còn đối với chuỗi dài thì sao? Cũng giống như chúng ta đó, khi đọc 1 cầu dài thì khả năng nhớ lại những thông tin trước đó là khó (hay còn gọi là học trước quên sau đó 🤫) Với chuỗi có độ dài lớn thì RNN không thể nhớ và học được nữa hix 😧
2.2. Vấn đề gặp phải của Long Short Term Memory (LSTM)
2.2.1 Ý tưởng cốt lõi của LSTM (Long short term memory)
LSTM là một dạng đặc biệt của RNN, nó có khả năng học các thông tin ở xa. Về cơ bản thì LSTM và RNN không khác nhau là mấy nhưng LSTM có cải tiển một số phép tính trong 1 hidden state và nó đã hiểu quả. Hiệu quả như nào thì chúng ta hãy cũng đọc tiếp nhé!
Cấu trúc của LSTM không khác gì RNN, nhưng sự cải tiến ở đây năm ở phần tính toán trong từng hidden state như sau: Thay vì chỉ có một tầng mạng nơ-ron, LSTM thiết kế với 4 tầng mạng nơ-ron tương tác với nhau một các rất đặc biệt.
Dưới đây là 2 hình ảnh biểu diễn sự khác nhau giữa RNN và LSTM
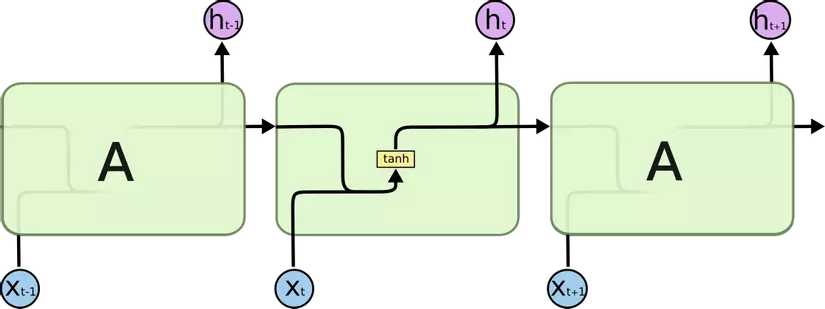
RNN with tanh function
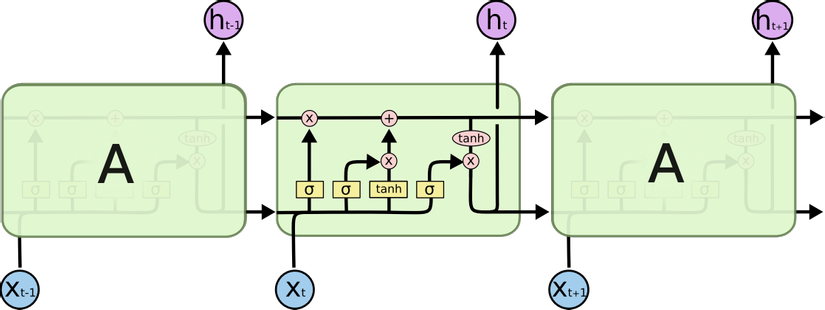
LSTM with tanh and sigmoid functions
Chìa khóa để giúp LSTM có thể truyền tải thông tin giữa các hidden state một các xuyên suốt chính là cell state (hình dưới):
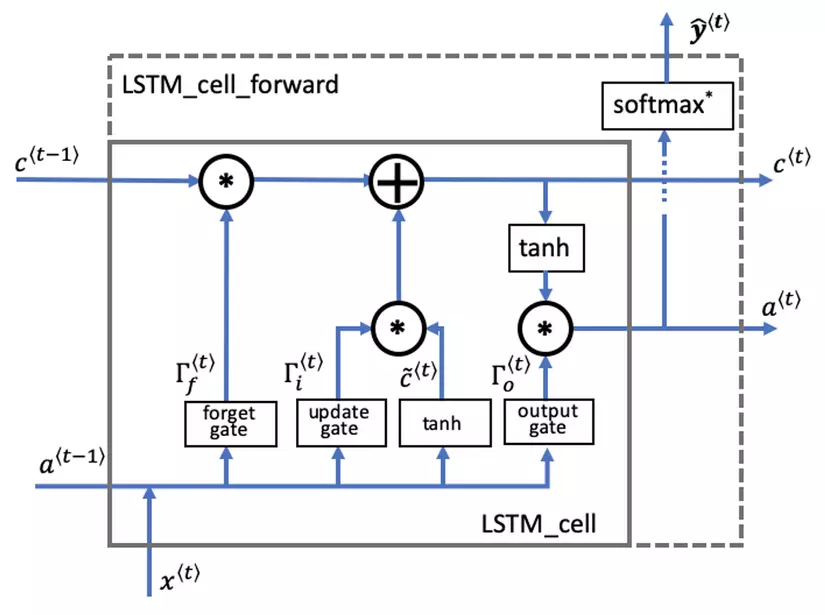
LSTM cell state
Forget gate
Đầu ra là hàm sigmoid chứa các giá trị từ 0 đến 1.
Nếu forget gate có giá trị bằng 0, LSTM sẽ "quên" trạng thái được lưu trữ trong đơn vị tương ứng của trạng thái cell trước đó.
Nếu cổng quên có giá trị bằng 1, LSTM sẽ chủ yếu ghi nhớ giá trị tương ứng ở trạng thái được lưu trữ.
Candidate value
Chứa thông tin có thể được lưu trữ từ time step hiện tại.
Update gate
Quyết định xem phần thông tin nào của có thể thêm vào .
Cell state
Là bộ nhớ trong của LSTM. Cell state như 1 băng tải truyền các thông tin cần thiết xuyết suất cả quá trình, qua các nút mạng và chỉ tương tác tuyển tính 1 chút. Vì vậy thông tin có thể tuyền đi thông suốt mà không bị thay đổi.
Output gate
Cổng điều chỉnh lượng thông tin đầu ra của cell hiện tại và lượng thông tin truyền tới trạng thái tiếp theo.
Hidden state
Được sử dụng để xác định ba cổng của time step tiếp theo.
Prediction
Dự đoán trong trường hợp sử dụng này là phân loại, vì vậy bạn sẽ sử dụng softmax.
2.2.2. Hạn chế của LSTM và động lực cho sự phát triển của Attention
Nhìn chung, LSTM khá giống với RNN hay nói cách khác thì RNN là một dạng đặc biệt của LSTM. LSTM giải quyết phần nào Vanishing gradient so với RNN, nhưng chỉ một phần.
Ngươc lại ,với lượng tinh toán như trên thì RNN đã chậm rồi, LSTM còn chậm hơn nữa.
-
RNN và LSTM vẫn bị xảy ra trường hợp vanishing gradient và thậm chị còn mất khá nhiều thời gian. Bên cạnh đó việc nó không tương thích với dữ liệu có cấu trúc khiến cho việc mô hình bị mất đi cơ chế học được sự liên quan giữa các từ trong câu với nhau.
-
Vì vậy, Attention đã ra đời, để tăng cường thôn tin giữa các hidden sate - thể hiện sự tương quan giữa các hidden state với nhau, với việc loại bỏ hoàn toàn tính tuần tự , cái thiện với việc song song hoá, tăng tốc độ xử lý. Mục đích cuối cùng là để tinh toán mối tương quan giữa input và output.
3. Attention
Ở phần này, chúng ta hãy cùng nhau đi tìm hiểu các phương thưc hoạt động và tính chất của Attention. Hãy cũng xem Attention có những đặc điểm gì vượt trội nhé!
3.1. Cơ chế Attention và sự khác biệt
Với cơ chế Attention, Transormer sẽ không cần tới các phép toán convolutional và recurrence, với cơ chế xử lý song song rõ ràng cho thấy được cơ chế này cung cập một hiệu suất vượt trội và thời gian huấn luyện được tối ưu đang kể.
Việc ở các mạng trước đó, khi sử dụng với chuỗi đầu vào là một chuỗi dài, sẽ khiến cho việc tìm hiểu mỗi tương quan giữa các từ trở nên khó khăn hơn rất nhiều. Trong Transformer vấn đề này đã được giải quyết nhưng sẽ phải giảm effective resolution do lấy trung bình các attention-weighted postion, nhưng vấn để này cũng sẽ được giải quyết ở phần sau với Multi-head attention.
Trong bài toán NLP, đối với trường hợp cụ thể như ta cần mã hóa(encode) một chuỗi đầu vào thành một vector chứa ngữ cảnh rồi sau đó giải mã (decode) dự đoán các từ trước đó. Nhưng chúng ta sẽ gặp một số vấn đề như sau:
-
Vanishing gradient: mất mát đạo hàm ở những hidden state cuối khi đầu vào là một chuỗi dài như đoạn văn
-
Exploding gradient: Hiện tượng gradient tăng mất kiểm soát do dồn ở những lớp cuối và đặc biệt xảy ra với những câu dài như đoạn văn.
-
Nén bộ nhớ (Memory compression): Do việc embed chuỗi đầu vào thành vector cố định kích thước, qua nhiều lần thử nghiệm cho thấy được mô hình này học với các câu dài rất kém trong khi đó lại rất lãng phí bộ nhớ với những câu ngắn. Vấn đề này vẫn còn xuất hiện trong LSTM và GRU
Không phù hợp với dạng dữ liệu có mối quan hệ liên kết ngữ nghĩa: Ví dụ với câu: “She is doing homework”. Nhận thấy “homework” có mối quan hệ nhiều hơn với “doing”. Đối với RNN - học tuần tự từ trái sang phải nhưng không có cơ chế để mô hình học được sự liên quan giữa các từ
3.2. Self-Attention là gì?
Cơ chế self-attention là thành phần quan trọng nhất của Transformer. Sự khác biệt giữa RNN, Attention và self-attention là: Trong attention sẽ tính toán dựa trên trạng thái của decoder ở time-step hiện tại và tất cả các trạng thái ẩn của encoder. Còn self-attention có thể hiểu là attention trong 1 câu, khi từng thành phần trong câu sẽ tương tác với nhau. Từng token sẽ quan sát các tokens còn lại, thu thập nhữ cảnh của câu và cật nhập vào vector biểu diễn.
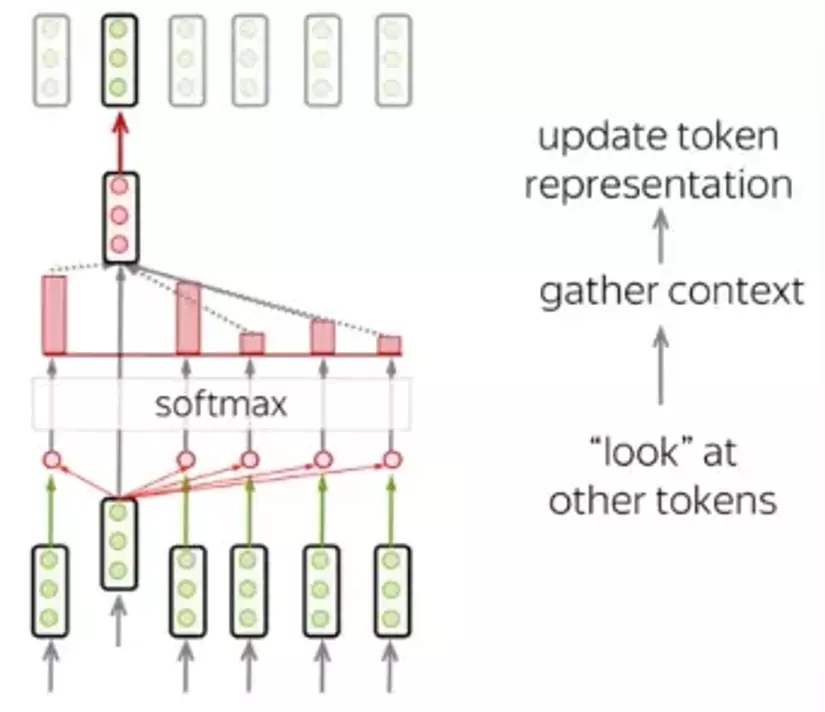
Để xây dựng cơ chế self-attention ta cần chú ý đến hoạt động của vector biểu diễn cho mỗi từ lần lượt là:
Query: được sử dụng để đặt câu hỏi rằng từ này ở trong câu có ý nghĩa gì
Key: trả lời rằng từ hiện tại có liên quan thế nào đến từ mà query đang hỏi
Value: chứa thông tin của từ đang hỏi
Dựa vào ý nghĩa của q, k, v có thể giải thích được công thức của Transformers Attention:
- q.k qua hàm softmax để đưa ra xác xuất của từ liên quan nhất với từng từ đươc hỏi tương ứng.
- Sau đó nhân với v để đưa ra giá trị dựa vào sự tương quan đó.
Query được sử dụng khi một token quan sát những tokens còn lại, nó sẽ tìm kiếm thông tin xung quanh để hiểu được ngữ cảnh và mối quan hệ của nó với tokens còn lại. Key sẽ phản hồi yêu cầu của Query và được sử dụng để tính trọng số attention. Cuối cùng, Value được sử dụng trong số attention vừa rồi để tính ra vector đại diện (attention vector).
Q, K, V đều được tính toán bằng công thức: wx + b.
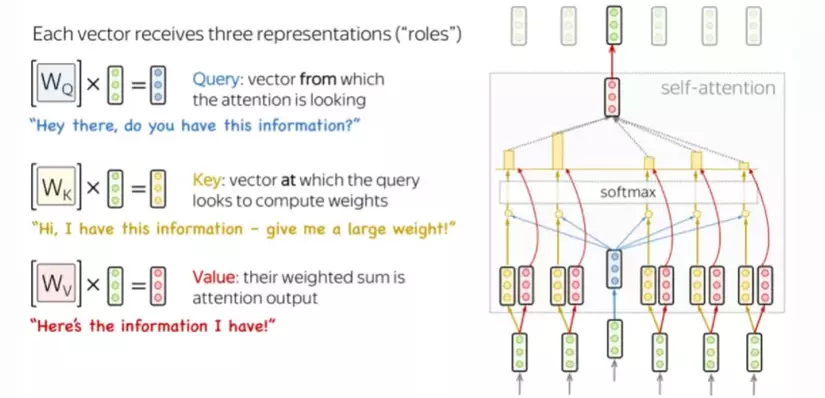
Trong ảnh trên là ma trận là các hệ số mà mô hình cần huấn luyện.
3.3. Multi-head Attention
Mỗi quá trình như vậy được gọi là 1 head của attention. Khi lặp lại quá trình này nhiều lần (trong bài báo là 3 heads) ta sẽ thu được quá trình Multi-head Attention như biến đổi bên dưới:
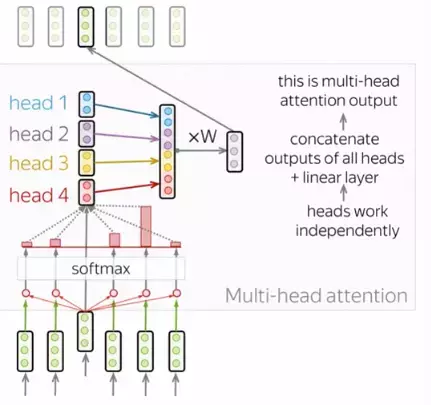
Để trả về output có cùng kích thước với ma trận input chúng ta chỉ cần nhân với ma trận để chiều rộng bằng với chiều rộng của ma trận input.
4.Cấu trúc của Transformer
"Attention Is All You Need” đây là tên của Attention Is All You Need mà transformer được nhắc tới lần đầu tiên. Hừm, tại sao paper của transformer mà lại không mang tên transformer 🤔, để biết tại sao mời các bạn đọc tiếp để biết transformer rốt cuộc là gì nhé.
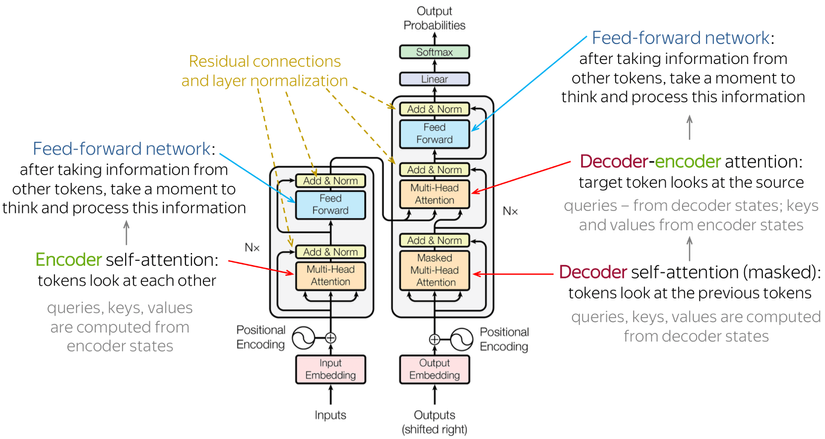
Cấu trúc của mô hình Transformer
Với kiến trúc của Transformer có 2 phần chính là encoders và decoders:
Encoders: gồm bộ lớp encoder giống hệt nhau và xếp chống lên nhau. Mỗi lớp có 2 khối chính đó là: attetion block và feed forward block, feed-forward network được kết nối đầy đủ theo vị trí ( positionwide fully connected feed-forward network )
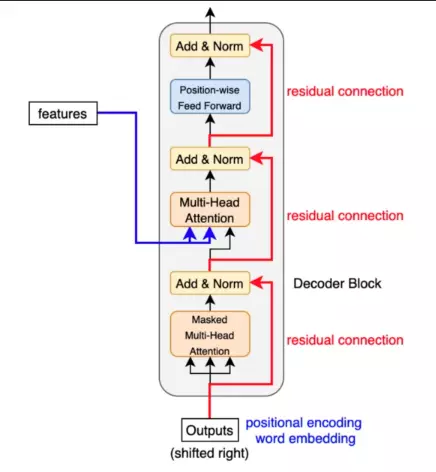
Decoders: Mỗi khối decoder nhận được các features từ encoder. Chúng ta có thể hình dung được sự liên kết giữa decoder và encoder như hình dưới đây
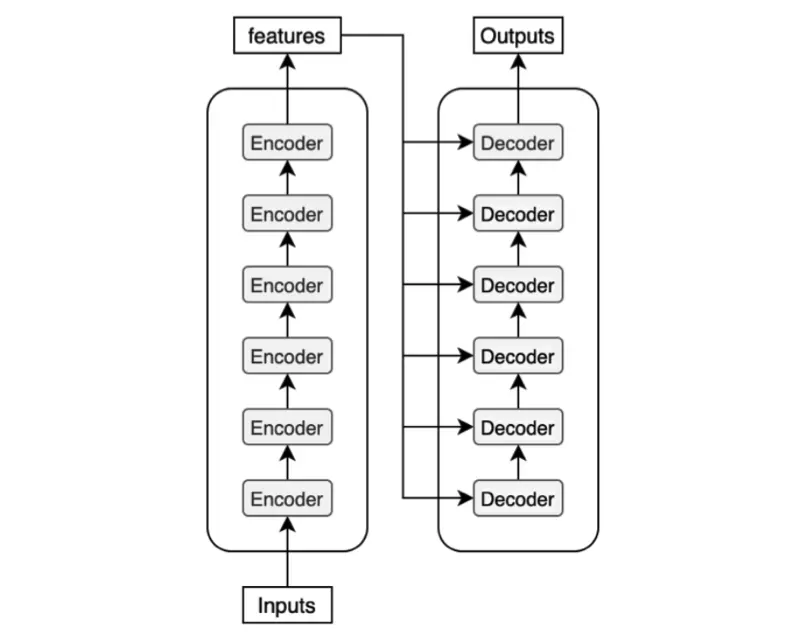
4.1. Positional Encoding
Khác với việc học tuần tự của RNN, Transformer loại bỏ cơ chế học tuần tự để học song song dựa trên multi-head self-attention, nên máy tính không hiểu được cấu trúc của câu dẫn đến việc sai về mặt ngữ nghĩa. Do đó cần một cách để giúp máy tính hiểu được thứ tự các từ trong câu, ý tưởng là ta sẽ đánh trọng số cho các từ trong câu:
Cách tiếp cận ngây thơ để đánh trọng trọng số là thêm giá trị mỗi từ theo tuyến tính. Có nghĩa là với từ đầu tiên thêm 1, từ thứ hai thêm hai, cứ như vậy cho đến hết. Với cách tiếp cần này sẽ có vài vấn đề như: các giá trị sẽ trở lên quá lớn, mô hình mất nhiều thời gian để hội tụ hơn (lý do các bạn có thể tìm kiếm với từ khóa “feature scalling”)
Một cách tiếp cận khác là thêm các giá trị trong khoảng [0, 1]; với giá trị 0 cho từ đầu tiên và 1 cho từ cuối cùng. Một trong những vấn đề đối với cách tiếp cần này là bạn không thể tìm ra có bao nhiêu từ hiện diện trong một phạm vi cụ thể. Nói cách khác, giá trị cộng thêm không có ý nghĩa nhất quán trong các câu khác nhau.
Các tiếp cận tốt nhất nên thỏa mãn các yêu cầu sau:
- Giá trị được thêm nên là duy nhất với mỗi time-step.
- Khoảng cách giữa các từ trong câu nên thống nhất với mọi câu.
- Giá trị thêm vào cần phải được giới hạn.
- Giá trị thêm vào cần phải làm rõ được vị trí các từ trong câu.
Phương pháp được đề xuất trong paper là các giá trị được cộng thêm sẽ bằng:
Tương ứng ta sẽ được giá trị
Kết quả sau quá trình Positional encode:
4.2. Masked Multi-Head Attention
Một layer tương tự như Multi-Head Attention, điểm khác biệt là ở lúc train, khi đã biết rõ output mong muốn để đưa vào làm input của time-step tiếp theo. Để hiểu rõ điều này trước tiên bạn cần biết cách Decoder vận hành, tôi sẽ lấy ví dụ trong bài toán text generate với câu “Tall house with wide door”:
Cũng giống như RNN, Decoder sử dụng output của time-step trước làm input của time-step hiện tại. Tức với ví dụ trên ta sẽ có các bước decode sau:
- input = “” qua Masked Multi-Head Attention, nhận thêm thông tin từ Encoder để đưa ra thông tin đầu tiên output = “Tall”.
- input = “Tall” → output = “Tall house”.
- input = “Tall house” → output = “Tall house with”.
- input = “Tall house with” → output = “Tall house with wide”.
- input = “Tall house with wide” → output = “Tall house with wide door”.
Mọi thứ sẽ như trên nếu mô hình đã được train xong 😁, nhưng trong quá trình train output ở time-step trước có thể sai khiến output của time-step hiện tại cụng có thể sai theo. Và đương nhiên việc này có thể dần cải thiện trong quá trình train, nhưng sẽ rất tốn tài nguyên. Vị vậy giải pháp được đưa ra là sử dụng output mà chúng ta muốn đưa vào làm input của từng time-step.
Mỗi time-step sẽ nhập input tương ứng nên có ở thời điểm đó, tức sẽ cho biết các từ nên được generate ở thời đó và che đi phần còn lại. Để máy tính hiểu được cách làm trên ta sử dụng Look-ahead Mask là ma trận tam giác dưới với các giá trị 1 biểu thị từ không muốn che, và 0 cho từ muốn che.
4.3. Add & Norm layers và Feed-forward layers
Normalization layers: Trong cấu trúc của transformer có các lớp “Add và Norm” thì “Norm” ở đây thể hiện cho Normalization layer. Lớp này đơn giản là sẽ chuẩn hóa lại đầu ra của multi-head attention, mang lại hiệu quả cho việc nâng cao khả năng hội tụ.
Khối Feed-forward: Sau khi thực hiện tính toán ở khối attention cho mỗi lớp thì khối tiếp theo là FFN. Có thể hiểu là cơ chế attention giúp thu thập thông tin từ những tokens đầu vào thì FFN là khối xử lý những thông tin đó
5. Triển khai với Python
5.1. Xây dựng khối Positional Embedding
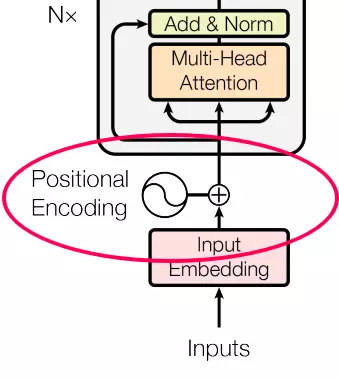
Khởi tạo khối mã hóa vị trí các input embedding. Mã hóa dựa trên các hàm sin và cô-son với các frequencies khác nhau. Các frequencies này được xác định bởi một hệ số, hệ số này được tính toán dựa trên vị trí trong chuỗi và các parameter đã học.
class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=5000): super().__init__() # Khởi tạo lớp Dropout self.dropout = nn.Dropout(p=0.1) # Khởi tạo một ma trận position ecoder có cùng kích thước với đầu vào d_model pe = torch.zeros(max_len, d_model) # Khởi tạo vị trí (size = [max_len,1] ) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # Khởi tạo công thức tính W_k div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # Khởi tạo công thức tính f(t) pe[:, 0::2] = torch.sin(position * div_term) # Thêm 1 chiều với dim bằng 0 cho Tensor pe = pe.unsqueeze(0) self.register_buffer('pe', pe) def forward(self, x): # Kết quả sau quá trình Position encoder x = x + self.pe[:, :x.size(1)] return self.dropout(x)
5.2. Xây dựng khối Encoder
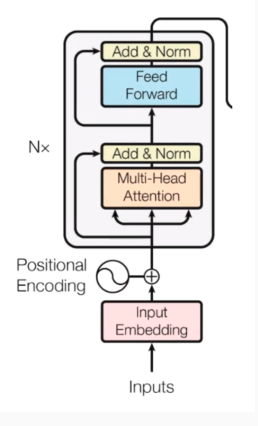
Ở phần này chúng ta cùng đi khởi tạo khối encoder bằng các layers được cung cấp bổi thư viện Pytorch: MultiheadAttention, LayerNorm, Sequential, Linear, ReLU, Linear
class EncoderLayer(nn.Module): def __init__(self, d_model, n_heads): super().__init__() # Khởi tạo lớp multi-head attention tương ứng với n_heads self.multihead_attn = nn.MultiheadAttention(d_model, n_heads) # Khởi tạo Norm layers self.norm1 = nn.LayerNorm(d_model) # Khởi tạo feed forward layer self.feedforward = nn.Sequential( nn.Linear(d_model, 2048), nn.ReLU(), nn.Linear(2048, d_model), ) # Khởi tạo lớp Norm thứ 2 self.norm2 = nn.LayerNorm(d_model) def forward(self, x): # Đưa input vào lớp Add & Norm và tính toán qua lớp multi-head attention x = self.norm1(x) attn_output, _ = self.multihead_attn(x, x, x) x = x + attn_output # Tiếp tục đưa x qua lớp Norm và tính toán output của multi head attetion layer vào khối feed forward x = self.norm2(x) ff_output = self.feedforward(x) x = x + ff_output # Thu được đầu ra của khối encoder return x
5.3. Xây dựng khối decoder
Trong mô hình Transformer, decoder có vai trò tạo chuỗi đầu ra dựa trên chuỗi đầu và đã được encode. Decoder tương tự như Encoder, gồm nhiều lớp self-attention và feed-forward networks. Bộ giải mã lấy đầu vào là một chuỗi embedding, được đưa qua các lớp self-attention để cho phép decoder tham gia vào các phần khác nhau của chuỗi đầu vào. Sau đó, decoder sẽ lấy các đầu ra của ecoder bằng cơ chế muilti-head attention. Đầu ra của cơ chế attetion này được concate với đầu vào của decoder và được cung cấp thông qua Feed-forward networks. Quá trình này được lặp lại cho mỗi token trong chuỗi đầu ra.
class DecoderLayer(nn.Module): def __init__(self, d_model, n_heads): super().__init__() # KHởi tạo lớp multi-head attention tương ứng với n_heads self.multihead_attn1 = nn.MultiheadAttention(d_model, n_heads) # Khởi tạo Norm layers self.norm1 = nn.LayerNorm(d_model) # KHởi tạo lớp multi-head attention thứ 2 tương ứng với n_heads self.multihead_attn2 = nn.MultiheadAttention(d_model, n_heads) # Khởi tạo Norm layers thứ 2 self.norm2 = nn.LayerNorm(d_model) # Khởi tạo feed forward layer self.feedforward = nn.Sequential( nn.Linear(d_model, 2048), nn.ReLU(), nn.Linear(2048, d_model), ) # Khởi tạo lớp Norm thứ 3 self.norm3 = nn.LayerNorm(d_model)
5.4. Xây dựng mô hình Transformer
Sau khi khởi tạo được các khối Position Embedding, Encode, Decoder. Ta tiến hình ghép laị thành mô hình hoàn chỉnh
class Transformer(nn.Module): def __init__(self, vocab_size, d_model, n_heads, n_layers): super().__init__() # Khởi tạo embedding self.embedding = nn.Embedding(vocab_size, d_model) # kHỞi tạo mã hóa vị trí self.pos_encoding = PositionalEncoding(d_model) # Khởi tạo encoder self.encoder_layers = nn.ModuleList([ EncoderLayer(d_model, n_heads) for _ in range(n_layers) ]) # Khởi tạo decoder self.decoder_layers = nn.ModuleList([ DecoderLayer(d_model, n_heads) for _ in range(n_layers) ]) self.fc = nn.Linear(d_model, vocab_size) self.softmax = nn.Softmax(dim=2) def forward(self, src, trg): # Thực hiện embed input src = self.embedding(src) # Gắn địa chỉ cho từng giá trị đầu vào src = self.pos_encoding(src) trg = self.embedding(trg) trg = self.pos_encoding(trg) # Truyền vào encoder tương ứng với n heads và layers đã khởi tạo for layer in self.encoder_layers: src = layer(src) # Sau khi đưa qua encoder ta tiếp tục truyền đầu ra của encoder vào decoder for layer in self.decoder_layers: trg = layer(trg, src) # Đưa vào lớp Linear output = self.fc(trg) output = self.softmax(trg) return output 6. Đánh giá và kết luận
Qua bài viết này, chúng ta đã cùng nhau sơ lược và phân tích sự động lực hình thành nên cơ chế Attention và mô hình Transformer. Có thể thấy sự tối ưu cũng như khả năng học tập giúp cho Transformer đang có chỗ đứng rất chắc chắn trong thị trường mô hình học máy. Trong bài viết này chúng ta mới chỉ tìm hiểu sơ qua về cấu trúc của Transformer và biết được cách Transformer học tập với dữ liệu dạng ngôn ngữ, hay NLP, dữ liệu dạng chuỗi. Vậy còn dạng dữ liệu hình ảnh thì sao? Transformer có thể áp dụng được không?
Hãy chờ đón bài blogs tiếp theo, chúng ta cùng đi sâu vào phần kiến trúc của Transformer, làm rõ hơn cách tính trọng số của attention trong mô hình và cách chúng học tập với hình ảnh để làm nổi bật lên cái hay của Transformer như thế nào nhé!
7. Tham khảo
- Attention Is All You Need
- Natural Language Processing with Attention Models by DeepLearning.AI
- Pytorch document
- Neural machine translation with a Transformer
- Deep Learning for NLP
- The Illustrated Transformer
8. Lời cảm ơn
Tôi xin chân thành cảm ơn các đọc giả đã dành thời gian để đọc bài blogs này. Bài viết này được chắt lọc bởi góc nhìn và tìm hiểu chủ quan, còn nhiều thiếu sót, hy vọng bạn đọc cùng đóng góp để giúp mình tôi cải thiện được kĩ năng cũng như kiến thức. Cảm ơn AidenDam đã có nhiều ý kiến đóng góp để bài blogs được hoàn thiện. Hy vọng chúng ta sẽ được gặp nhau ở nhiều bài blogs sắp tới. Hãy cũng HIT Tech chia sẻ nhưng bài viết hay và thú về về công nghệ nhé!