Giới thiệu
Trong bối cảnh AI hiện nay, mô hình “Simple Agentic” đã trở thành mặc định: một LLM được cung cấp các công cụ (tools) để truy xuất dữ liệu, nhưng bản thân mô hình chịu trách nhiệm phân tích và tổng hợp dữ liệu đó để đưa ra câu trả lời cuối cùng. Đây là một cách tiếp cận rất hấp dẫn vì nó cực kỳ dễ xây dựng và demo, nhưng như bài viết này sẽ chỉ ra, nó tiềm ẩn những rủi ro nghiêm trọng ở cấp độ doanh nghiệp.
Để kiểm tra giới hạn của mô hình này, tác giả đã xây dựng và instrument đầy đủ một hệ thống đơn giản nhằm trả lời các truy vấn phức tạp dựa trên dữ liệu, chạy hoàn toàn trên môi trường local (AMD Max+395 Frame.work system, chạy llama.cpp). Mục tiêu không chỉ là kiểm tra xem hệ thống có hoạt động hay không, mà là quan sát trực tiếp prompt thực tế và phản hồi thô của LLM, để hiểu rõ cách các quyết định tool-call được đưa ra.
AppliedIngenuity.ai: Practical AI Solutions là một ấn phẩm được hỗ trợ bởi độc giả. Để nhận bài viết mới và ủng hộ công việc của tác giả, bạn có thể đăng ký miễn phí hoặc trả phí.
Bài viết này mổ xẻ toàn bộ quy trình đó. Chúng ta sẽ xem:
- Văn bản chính xác được gửi tới LLM
- Các reasoning tokens mà mô hình sinh ra
- Vì sao mô hình “tools fetch, LLM analyzes” tạo ra rủi ro nghiêm trọng về độ chính xác, chi phí và khả năng kiểm chứng
Dù mô hình này thường cho kết quả rất ấn tượng, nó chứa những failure mode vô hình mà mọi technical leader cần hiểu rõ trước khi chuyển từ prototype sang production.
Prototype 600 dòng code: Kiến trúc và mục tiêu
Để nghiên cứu mô hình “Simple Agentic”, tác giả đã xây dựng một thử nghiệm tập trung: một trợ lý tài chính có khả năng trả lời các truy vấn dữ liệu tùy ý dựa trên một cơ sở dữ liệu local.
Toàn bộ phần lõi agentic của hệ thống chỉ gồm chưa tới 600 dòng Python, không phụ thuộc đáng kể vào thư viện ngoài, và được xây dựng trong vài giờ. Hệ thống này tương đương với việc yêu cầu một công cụ sinh code:
“Build me an agentic system that can answer financial queries about stocks.”
Mục tiêu là tạo ra một hệ thống được instrument hoàn toàn, nơi mọi bước — prompt, phản hồi, tool-call — đều có thể audit theo thời gian thực.
System Stack
Hệ thống chạy hoàn toàn trên phần cứng local để đảm bảo quyền riêng tư dữ liệu và kiểm soát chính xác LLM được sử dụng.
- Compute: AMD Max+395 (128 GB) Frame.work server chạy llama.cpp
- Models: GPT-OSS-120b (hoặc QWEN-3-Next 80b) – các LLM agentic mạnh, hỗ trợ tool-calling native
- Financial data: DuckDB local chứa dữ liệu thị trường lịch sử theo ngày
- Instrumentation: session logger ghi lại toàn bộ quyết định, prompt và response thông qua jinja template
Giải phẫu một tool-call: vòng lặp ra quyết định
Trong hệ thống “Simple Agentic”, LLM đóng vai trò bộ máy suy luận, quyết định:
- Có gọi tool hay không
- Gọi tool nào
- Với tham số gì
Điểm quan trọng của kiến trúc này là các quyết định không bao giờ độc lập. Thay vì request–response đơn lẻ, agent duy trì một thread có trạng thái. Mỗi lần gọi LLM, toàn bộ lịch sử hội thoại được gửi lại, cho phép mô hình “ghi nhớ” kết quả các tool-call trước đó.
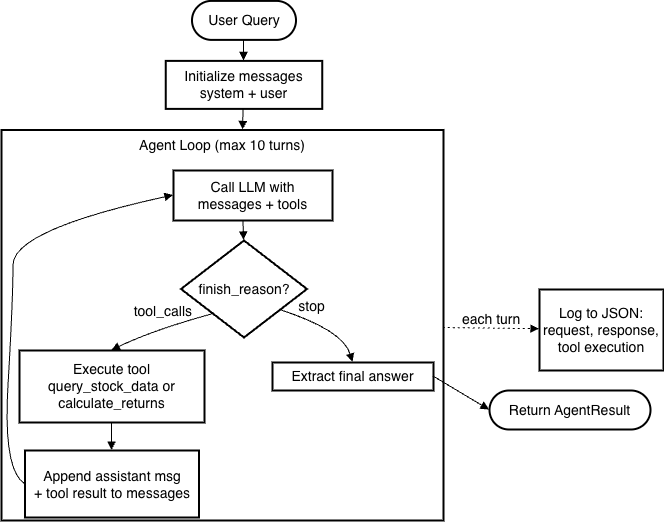
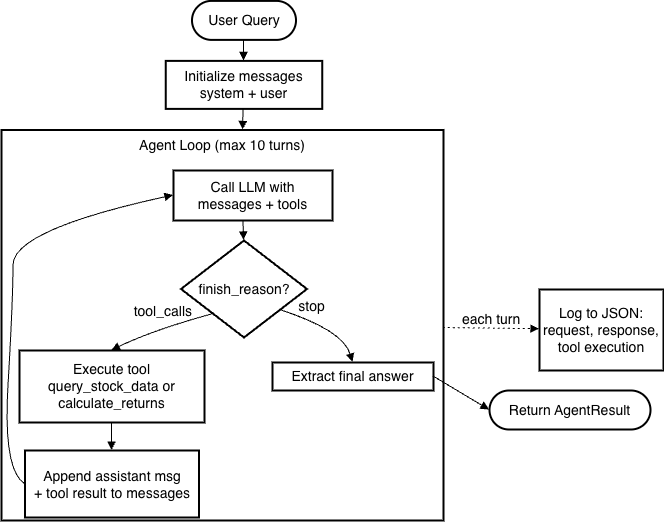
Luồng thực thi
Hệ thống hoạt động theo logic “Repeat Until Done”:
- Initialize – Kết hợp user query, system prompt và JSON schema của tools
- Reasoning & Selection – LLM sinh reasoning tokens (scratchpad nội bộ), sau đó xuất tool-call có cấu trúc
- Action – Python script chặn tool-call, thực thi truy vấn DB local, rồi append dữ liệu thô vào thread
- Synthesis – LLM nhận thread mới; nếu đủ dữ liệu thì sinh câu trả lời cuối, nếu chưa thì tiếp tục gọi tool
Toolset: Cầu nối giữa code và LLM
Định nghĩa tools (OpenAI function calling format)
TOOLS = [
{
"type": "function",
"function": {
"name": "query_stock_data",
"description": "Query historical stock price data from the database",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "Stock ticker symbol (e.g., MSFT) or comma-separated list (e.g., MSFT,AAPL,NVDA)"
},
"start_date": {
"type": "string",
"description": "Start date in YYYY-MM-DD format"
},
"end_date": {
"type": "string",
"description": "End date in YYYY-MM-DD format"
}
},
"required": ["ticker"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate_returns",
"description": "Calculate the percentage return for a stock over a time period",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "Stock ticker symbol"
},
"start_date": {
"type": "string",
"description": "Start date in YYYY-MM-DD format"
},
"end_date": {
"type": "string",
"description": "End date in YYYY-MM-DD format"
}
},
"required": ["ticker", "start_date", "end_date"]
}
}
}
]
Các mô tả trong JSON schema (đặc biệt là trường description) được LLM sử dụng để quyết định tool nào phù hợp và ánh xạ tham số từ câu hỏi người dùng.
DuckDB Schema
CREATE TABLE IF NOT EXISTS stock_prices (
ticker VARCHAR,
date DATE,
open DOUBLE,
high DOUBLE,
low DOUBLE,
close DOUBLE,
volume BIGINT,
adj_close DOUBLE,
PRIMARY KEY (ticker, date)
)
Gọi LLM: Construct tools request
client = OpenAI(
base_url=config.LLM_ENDPOINT,
api_key=config.LLM_API_KEY
)
messages = [
{"role": "system", "content": config.SYSTEM_PROMPT},
{"role": "user", "content": query}
]
response = client.chat.completions.create(
model=config.LLM_MODEL,
messages=messages,
tools=TOOLS,
temperature=temperature
)
Xử lý response
choice = response.choices[0]
if choice.finish_reason == "tool_calls" or (
choice.message.tool_calls and len(choice.message.tool_calls) > 0
):
tool_call = choice.message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
tool_result = execute_tool(tool_name, tool_args)
LLM quyết định tool nào cần gọi, với tham số gì, sau đó Python runtime thực thi truy vấn tương ứng.
Prompt thực tế gửi tới LLM
Ví dụ prompt raw cho câu hỏi:
What did Amazon close at on March 15, 2024?
<|start|>system<|message|>
Knowledge cutoff: 2024-06
Current date: 2026-01-26
Reasoning: medium
# Valid channels: analysis, commentary, final.
Calls to these tools must go to the commentary channel: 'functions'.
<|end|>
...
Chat template tự động inject Knowledge cutoff và Current date, tạo ra nguồn non-determinism ẩn: cùng một user prompt nhưng khác ngày chạy có thể cho kết quả khác nhau.
Sự hiệu quả đầy mê hoặc
Ở các ví dụ truy vấn đơn giản, đa lượt, và có ràng buộc phức tạp, hệ thống cho kết quả đúng mà developer không cần viết logic nghiệp vụ (so sánh ngày, tìm max, tính delta…).
Nếu dừng ở đây, bạn có một VC demo hoàn hảo. Tuy nhiên, mô hình “LLM-as-Analyst” che giấu một vấn đề cốt lõi: thiếu tính quyết định (non-determinism).
Rủi ro 1: Helpfulness Paradox – LLM tự bịa khi hệ thống lỗi
Khi DuckDB bị lock và tool trả về lỗi IO, LLM bỏ qua lỗi và sinh ra câu trả lời “hợp lý” dựa trên training data.
Điều này cực kỳ nguy hiểm trong bối cảnh doanh nghiệp: một hệ thống fail bằng cách nói dối còn tệ hơn fail hard.
Rủi ro 2: Xử lý xác suất thay vì logic quyết định
LLM không thực sự tính toán; nó dự đoán token tiếp theo. Vì vậy, ngay cả với dữ liệu đúng, mô hình vẫn có thể:
- Chép nhầm số
- Trộn dữ liệu giữa các dòng
- Làm tròn không kiểm soát
Khi context vượt ngưỡng 40–50%, hiện tượng Intelligence Degradation xuất hiện, làm sụt giảm mạnh độ chính xác.
Rủi ro 3: LLM không hiểu khái niệm nghiệp vụ
LLM không có đồng hồ nội tại, không hiểu chuẩn kế toán hay logic nghiệp vụ. Khi được hỏi “Q1 return” hoặc “last week”, mô hình buộc phải suy đoán dựa trên training data.
Bạn đang âm thầm giao quyền định nghĩa nghiệp vụ cho mô hình.
Rủi ro 4: Bùng nổ chi phí và độ trễ
Trong agentic loop, toàn bộ context được gửi lại LLM ở mỗi lượt:
- Token bị tính phí lặp lại
- Latency tăng dần
- Chi phí vận hành bùng nổ
Đây là cách đắt đỏ và chậm nhất để xử lý dữ liệu có cấu trúc.
Rủi ro 5: Thiếu khả năng kiểm chứng (verifiability)
Kết quả có thể rất thuyết phục, nhưng người dùng không thể biết:
- Dữ liệu đến từ đâu
- Có bị làm tròn hay bịa không
- Có đúng với database hay không
Thiếu audit trail khiến hệ thống không phù hợp cho quyết định có rủi ro cao.
Kết luận: vượt ra ngoài demo 600 dòng
Mô hình “Simple Agentic” phù hợp cho prototype và demo, nhưng là nền tảng mong manh cho production.
Giải pháp không phải bỏ AI agent, mà là đổi kiến trúc:
- LLM dùng để hiểu ngôn ngữ và điều phối
- Logic xử lý dữ liệu phải deterministic
- Kết quả phải có audit trail rõ ràng
Tiếp theo là gì?
Bài viết tiếp theo sẽ trình bày kiến trúc:
“LLM-Computation Reduced, Deterministic Output Generation”
Trong đó:
- LLM không trực tiếp xử lý dữ liệu
- Mọi phép tính đều deterministic
- Kết quả có thể truy vết và kiểm chứng
- Chi phí và độ trễ thấp hơn
Đây là bước cần thiết để đưa agentic systems từ demo sang production-grade software.