Lời mở đầu
JOIN là một trong những lệnh cơ bản nhưng đồng thời cũng là quan trọng nhất khi làm việc với dữ liệu bằng SQL. Trong Apache Spark, cụ thể là SparkSQL cũng cung cấp phép JOIN như các database truyền thống với đủ các loại như INNER JOIN, OUTER JOIN, CROSS JOIN, ...
Khi thực hiện phép JOIN trong một hệ thống phân tán (distributed systems) như Spark, những yếu tố có thể ảnh hưởng đến hiệu suất bao gồm:
- Data size: Khi thực hiện JOIN trên các bộ dữ liệu có thể gây ra hiện tượng Shuffle (xáo trộn data giữa các node trong cluster). Đây là một hành động nên được hạn chế tối đa do nó có ảnh hưởng đến network I/O, dung lượng bộ nhớ và bộ xử lý.
- Skew data: Dữ liệu được phân tán không đều hay bị lệch (skew) giữa các partitions, dẫn đến một vài node có thể bị overloaded dẫn đến performance bottlenecks.
Tuy nhiên chúng ta không nói để các loại JOIN như ở trên. Trong bài này mình sẽ nói về phần chiến lược thực thi đằng sau thực hiện các phép JOIN này. Chọn đúng chiến lược thực thi là một phần quan trọng để tối ưu hiệu suất chương trình Spark, đặc biệt khi thực hiện với những dataset lớn.
Giả sử dataset gồm 2 table như sau:
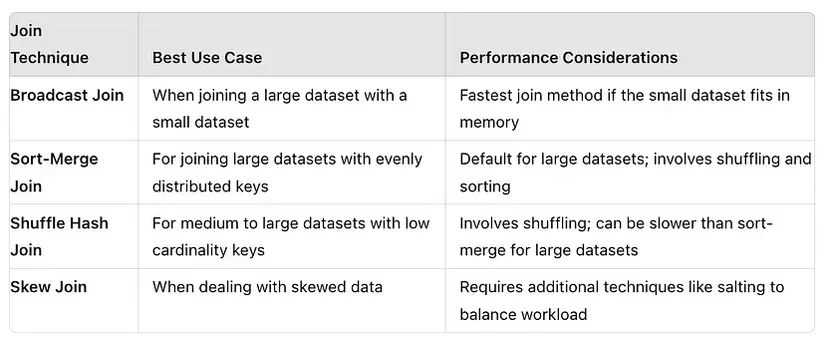
Các chiến lược thực thi phép JOIN trong Spark gồm:
- Broadcast Join (Broadcast Hash Join)
- Shuffle Hash Join
- Sort Merge Join
- Skew Join hmm
- Còn mấy cái nữa mà ít thấy ~~~
Broadcast Join
Với Broadcast Join, dataset nhỏ hơn (customer) sẽ được "phát" (broadcast) đến tất cả các node trong cluster, sau đó dataset lớn hơn (orders) sẽ thực hiện JOIN với nó trên mỗi. Do dataset customer được coi là đủ "nhỏ" nên nó có thể được gửi đến mọi node mà có thể bỏ qua vấn đề về I/O, throughput.
Output của mỗi node và Final output
Trong mỗi node, phép JOIN được thực hiện giữa phần của bảng order của node đó và toàn bộ bảng customer được broadcast đến node đó.

Kết quả cuối cùng được collect từ mỗi node sau khi thực hiện Broadcast JOIN
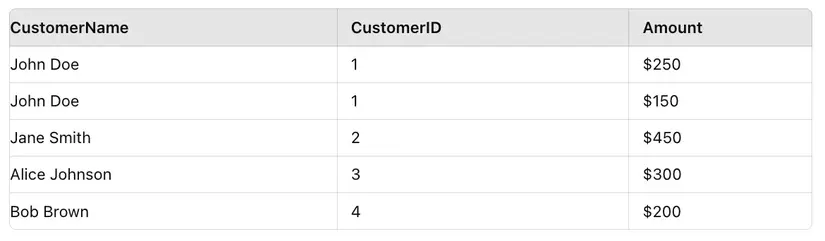
from pyspark.sql import SparkSession
from pyspark.sql.functions import broadcast spark = SparkSession.builder.appName("BroadcastJoinExample").getOrCreate() # Create sample data
customers = [(1, "John Doe"), (2, "Jane Smith"), (3, "Alice Johnson"), (4, "Bob Brown")]
orders = [(101, 1, 250), (102, 2, 450), (103, 1, 150), (104, 3, 300), (105, 4, 200)] # Create DataFrames
customers_df = spark.createDataFrame(customers, ["CustomerID", "CustomerName"])
orders_df = spark.createDataFrame(orders, ["OrderID", "CustomerID", "Amount"]) # Perform Broadcast Join
joined_df = orders_df.join(broadcast(customers_df), "CustomerID")
joined_df.show() Data movement và Final output
Note: Độ lớn của dataset để được broadcast có thể được setting qua config
spark.sql.autoBroadcastJoinThreshold, mặc định là 10MB, tức là nếu có dataset có dung lượng nhỏ hơn 10MB thì nó sẽ được broadcast.
- Data movement: Do bảng
customerđủ nhỏ nên nó được gửi đến mọi node trong cluster. Mỗi node sau đó sẽ thực hiện JOIN giữa bảng lớn bên trong node đó và bảng được broadcast đến. - Final output: Sau khi thực hiện JOIN trong mỗi node, output được collect tạo thành final output.
- Thường dùng khi thực hiện JOIN giữa 1 bảng kích thước nhỏ và bảng còn lại kích thước lớn.
Sort Merge Join
Đây là chiến lược JOIN được Spark sử dụng khi nhận thấy các bảng trong phép JOIN trước tiên không đủ nhỏ để thực hiện Broadcast, đồng thời các bảng đều đã được partition (phân vùng) và sort (sắp xếp) dựa trên khóa được lấy để JOIN. Trong trường hợp ở 2 bảng ví dụ ở trên, khóa được lấy để JOIN là CustomerID. Spark sẽ thực hiện shuffle và sort data giữa các node dựa theo CustomerID.

Sau khi shuffle, các record có cùng CustomerID sẽ được colocate ở cùng 1 node.

Output của mỗi node và Final output
Phép JOIN được thực hiện trong mỗi node sau khi đã sort data

Ouput cuối cùng sau khi collect
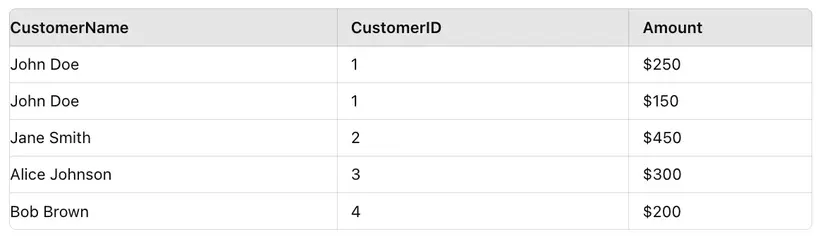
# Initialize Spark session
spark = SparkSession.builder.appName("SortMergeJoinExample").getOrCreate() # Create sample data
customers = [(1, "John Doe"), (2, "Jane Smith"), (3, "Alice Johnson"), (4, "Bob Brown")]
orders = [(101, 1, 250), (102, 2, 450), (103, 1, 150), (104, 3, 300), (105, 4, 200)] # Create DataFrames
customers_df = spark.createDataFrame(customers, ["CustomerID", "CustomerName"])
orders_df = spark.createDataFrame(orders, ["OrderID", "CustomerID", "Amount"]) # Perform Sort-Merge Join
joined_df = customers_df.join(orders_df, "CustomerID")
joined_df.show()
Data movement và Final output
- Data movement: Spark sẽ shuffle để đảm bảo các record có giá trị giống nhau trong khóa được dùng để JOIN (trong trường hợp này là
CustomerID) sẽ được ở cùng 1 node, sau đó thực hiện sort theo khóa (CustomerID). Sau khi sort, Spark thực hiện JOIN bằng cách "merge" qua 2 bảng đã sort => do đó có tên gọi Sort Merge. - Final output: Sau khi thực hiện JOIN trong mỗi node, output được collect tạo thành final output.
- Thường dùng khi JOIN các bảng kích thước từ vừa tới lớn với các khóa cần JOIN được evenly distributed.
Shuffle Hash Join
Cũng là chiến lược khi Spark nhận thấy không bảng nào đủ nhỏ để có thể Broadcast. Spark sẽ thực hiện shuffle trong cả 2 bảng. Trong mỗi bảng, khi thực hiện shuffle giữa các partition, các record có cùng giá trị trong khóa để JOIN (CustomerID) sẽ được đưa về cùng partition, sau đó thực hiện Hash JOIN trên mỗi partition.

Sau khi partitioning
Spark thực hiện partition cả 2 bảng dựa trên khóa CustomerID và thực hiện JOIN chúng trên mỗi partition.

Output của mỗi node và Final output
Phép JOIN được thực hiện trong mỗi node (sử dụng Hash JOIN)

Output cuối cùng sau khi collect:
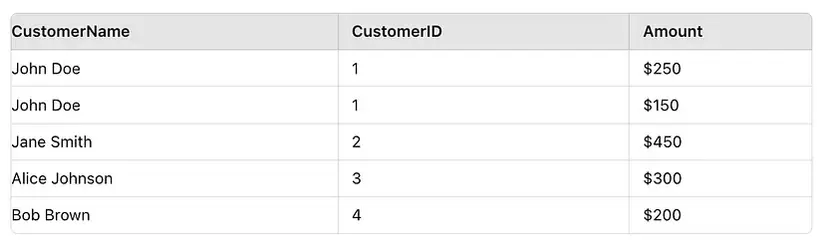
# Initialize Spark session
spark = SparkSession.builder.appName("ShuffleHashJoinExample").getOrCreate() # Create sample data
customers = [(1, "John Doe"), (2, "Jane Smith"), (3, "Alice Johnson"), (4, "Bob Brown")]
orders = [(101, 1, 250), (102, 2, 450), (103, 1, 150), (104, 3, 300), (105, 4, 200)] # Create DataFrames
customers_df = spark.createDataFrame(customers, ["CustomerID", "CustomerName"])
orders_df = spark.createDataFrame(orders, ["OrderID", "CustomerID", "Amount"]) # Perform Shuffle Hash Join
# Spark decides to use Shuffle Hash Join when the datasets are medium in size
joined_df = customers_df.join(orders_df, "CustomerID")
joined_df.show()
Data movement và Final output
- Data movement: Spark thực hiện partititoning cả 2 bảng dựa trên khóa để JOIN (
CustomerID), sau đó thực hiện Hash JOIN ở mỗi partition tương . - Final output: Sau khi thực hiện JOIN trong mỗi node, output được collect tạo thành final output.
- Thường dùng khi JOIN các bảng kích thước vừa do phép JOIN này thực hiện shuffle, nên sử dụng khi khóa JOIN có ít giá trị distinct (low cardinality)
Skew Join
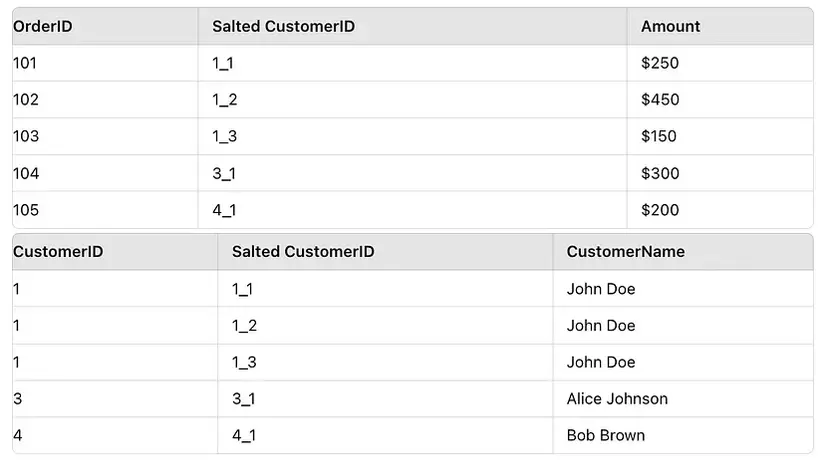
Skew là hiện tượng data được phân bổ trong mỗi partition không đều tức là bị lệch (skew), ví dụ như trong một cột, có một giá trị xuất hiện nhiều hơn hẳn các giá trị khác. Một phương pháp đơn giản và phổ biến để giải quyết vấn đề này là Salting, tức là thêm một giá trị ngẫu nhiên vào cột có các giá trị đang bị skew để đảm bảo khi partition, các giá trị sẽ được distribute đều hơn =))
Trước khi salting
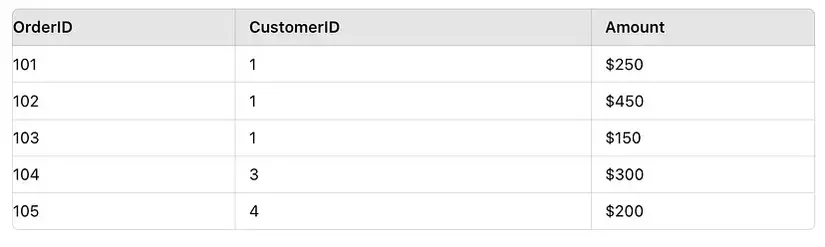
Sau khi salting (thực hiện ở cả 2 bảng)
from pyspark.sql import functions as F # Initialize Spark session
spark = SparkSession.builder.appName("SkewJoinExample").getOrCreate() # Create sample data with skewed distribution
customers = [(1, "John Doe"), (2, "Jane Smith"), (3, "Alice Johnson"), (4, "Bob Brown")]
orders = [(101, 1, 250), (102, 1, 450), (103, 1, 150), (104, 3, 300), (105, 4, 200)] # Create DataFrames
customers_df = spark.createDataFrame(customers, ["CustomerID", "CustomerName"])
orders_df = spark.createDataFrame(orders, ["OrderID", "CustomerID", "Amount"]) # Add a salt to the CustomerID in the orders dataset to reduce skew
orders_df_salted = orders_df.withColumn("SaltedCustomerID", F.concat(F.col("CustomerID"), F.lit("_"), (F.rand() * 3).cast("int"))) # Also add salt to the CustomerID in the customers dataset to match
customers_df_salted = customers_df.crossJoin(spark.range(0, 3)).withColumn("SaltedCustomerID", F.concat(F.col("CustomerID"), F.lit("_"), F.col("id"))).drop("id") # Perform the join using the salted CustomerID
joined_df = orders_df_salted.join(customers_df_salted, "SaltedCustomerID").drop("SaltedCustomerID")
joined_df.show()
Các loại khác
Ngoài các kiểu chiến lược thực thi ở trên, có vài loại khác tuy nhiên ít được thấy và sử dụng hơn, ví dụ như Broadcast Nested Loop Join, Shuffle and Replicate Nested Loop Join, Cartesian Join hay Cross Join, ....
Lời kết
Kiểu như này:
Và như này =))
