Ở bài viết trước chúc ta đã tìm hiểu về Event-Driven architecture, Apache Kafka có thể được sử dụng với vai trò như một Broker trong kiến trúc này. Apache Kafka là một nền tảng phân phối dữ liệu mã nguồn mở được xây dựng bởi Apache Software Foundation. Nó được thiết kế để xử lý lưu lượng dữ liệu lớn và cung cấp một cách hiệu quả để truyền tải dữ liệu từ nguồn đến đích.
Ứng dụng của Kafka
Apache Kafka có thể được sử dụng trong nhiều trường hợp khác nhau trong các ứng dụng và hệ thống, bao gồm nhưng không giới hạn:
- Xử lý dữ liệu thời gian thực
- Xử lý logs và giám sát
- Xây dựng hệ thống thống kê và phân tích dữ liệu
- Message Queue
Một sô điểm nổi bật của Kafka
- Khả năng mở rộng ngang (Horizontal Scalability): Kafka có thể mở rộng dễ dàng bằng cách thêm các broker vào cụm mà không làm gián đoạn dịch vụ, cho phép xử lý lưu lượng dữ liệu lớn mà không cần phải thay đổi cấu trúc.
- Tính nhất quán (Durability): Kafka lưu trữ dữ liệu trên đĩa và có khả năng duy trì theo thời gian. Điều này đảm bảo tính nhất quán của dữ liệu và cho phép xử lý lại dữ liệu nếu cần thiết.
- Hiệu suất cao (High Throughput): Kafka có khả năng xử lý hàng triệu messages mỗi giây trên một cụm broker, làm cho nó phù hợp với các ứng dụng có yêu cầu về hiệu suất cao.
- Độ tin cậy (Reliability): Kafka cung cấp sao chép dữ liệu (replication) và đồng bộ hóa dữ liệu giữa các broker, giúp đảm bảo tính sẵn sàng và độ tin cậy của hệ thống.
- Tích hợp mạnh mẽ: Kafka có khả năng tích hsợp với nhiều công nghệ và ngôn ngữ lập trình khác nhau: Java, Python, Golang, JavaScript,...
- Event-driven architecture (EDA): Kafka hỗ trợ mô hình kiến trúc dựa trên sự kiện, cho phép các ứng dụng xử lý và phản ứng linh hoạt theo sự kiện xảy ra.
- Community lớn: Kafka được phát triển và duy trì bởi Apache Software Foundation và có một cộng đồng lớn của các nhà phát triển và người dùng, cung cấp hỗ trợ và tài nguyên phong phú.
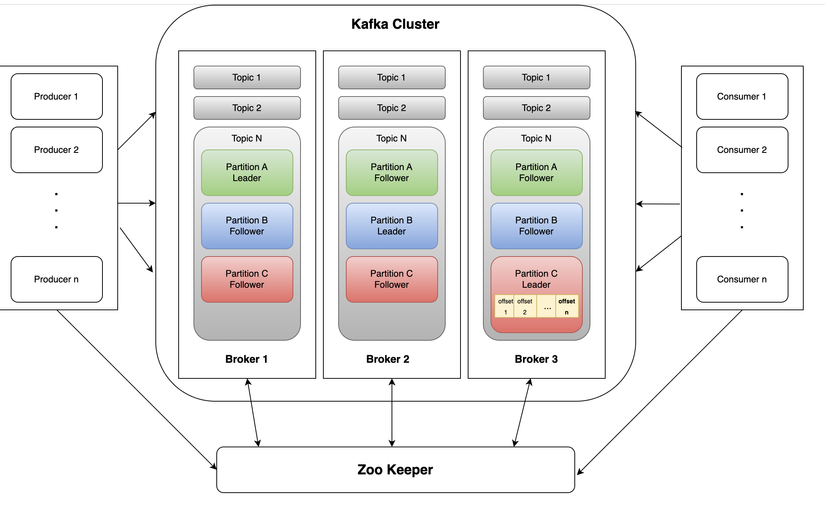
Kiến trúc tổng thể của Kafka
- Kafka Broker là một phần quan trọng, đóng vai trò như một máy chủ Kafka trong một cụm (cluster) Kafka. Mỗi Kafka Broker là một tiến trình độc lập chạy trên một máy chủ vật lý hoặc máy ảo.
- Kafka Cluster: là một tập hợp các máy chủ Kafka (broker) hoạt động độc lập với nhau nhau để lưu trữ và xử lý dữ liệu. Cluster Kafka bao gồm ít nhất 1 broker, nhưng thường được triển khai với nhiều broker để tăng khả năng mở rộng và độ tin cậy (thường là số lẻ 3, 5, 7).
- Zoo Keeper: được sử dụng để lưu trữ metadata và trạng thái của các broker, topic, partition và offset. ZooKeeper là một phần quan trọng của Kafka Cluster, giúp đảm bảo tính nhất quán và độ tin cậy của hệ thống Kafka. Tuy nhiên, từ phiên bản Apache Kafka 2.8.0, ZooKeeper không còn là một phần bắt buộc của Kafka nữa, thay vào đó Kafka sử dụng Kafka's Raft metadata quorum (KRaft) để quản lý metadata mà không cần sử dụng ZooKeeper.
- Event: đơn giản là một thông điệp hoặc một bản ghi dữ liệu được gửi từ một Producer và được xử lý bởi một hoặc nhiều Consumer. Events có thể là bất kỳ loại dữ liệu nào, từ thông điệp văn bản đến dữ liệu cấu trúc phức tạp.
- Kafka Producer: là thành phần đưa dữ liệu vào Kafka. Producer gửi các bản tin (messages) tới các topic đã được chỉ định trong Kafka. Mỗi bản tin có một key và một giá trị.
- Kafka Consumer: là thành phần lấy dữ liệu ra từ Kafka. Consumer đăng ký theo dõi một hoặc nhiều topic và sau đó lấy các thông điệp từ chúng để xử lý hoặc lưu trữ.
- Kafka Topic: là cơ chế cơ bản để tổ chức và quản lý dữ liệu trong Kafka. Mỗi topic có một tên duy nhất và có thể chứa một hoặc nhiều messages được gửi từ các Producer. Các Consumer có thể theo dõi (subscribe) các topic để nhận dữ liệu từ chúng. Một Broker có thể chứa nhiều Topic
- Kafka Topic Parttion: một topic được phân chia thành nhièu partition. Mỗi partition là một dãy có thứ tự các messages và được lưu trữ trên một hoặc nhiều Kafka Broker trong một cụm Kafka Cluster.
- Kafka Event's Offset: là một con số duy nhất đại diện cho vị trí của một message trong một partition của một topic. Offset được sử dụng để xác định message cụ thể mà một consumer đã đọc hoặc chưa đọc từ partition. Mỗi khi một message mới được gửi đến một partition, Kafka sẽ gán một offset tăng dần cho message. Offset này là một số nguyên không âm và duy nhất trong partition đó. Khi một consumer đọc thông điệp từ partition, nó sẽ xác định offset hiện tại của mình và sử dụng offset đó để yêu cầu thông điệp tiếp theo từ partition. Offset rất quan trọng trong Kafka vì nó cho phép các consumer đọc và xử lý dữ liệu một cách nhất quán và theo thứ tự. Offset cũng cho phép các consumer theo dõi các thông điệp đã được xử lý và đảm bảo rằng không có thông điệp nào bị mất hoặc xử lý lại.
- Kafka Partition's replication: Khi nói về sao chép (replication) partition trong Apache Kafka, ta đề cập đến việc tạo ra các bản sao của một partition và phân phối chúng trên các Kafka Broker khác nhau trong cụm Kafka. Quá trình này có thể được tổ chức dưới dạng một số bản sao (replica) của mỗi partition, với một trong số chúng được chọn làm leader và các bản sao còn lại được gọi là follower. Quá trình sao chép partition diễn ra một cách tự động và liên tục trong Kafka, với dữ liệu được sao chép từ leader đến các bản sao follower và đảm bảo rằng các bản sao đều giữ được một bản sao đồng nhất của dữ liệu. Điều này giúp đảm bảo rằng dữ liệu trong Kafka luôn có sẵn (availability) và tin cậy ( reliability), thậm chí trong trường hợp có sự cố xảy ra.
Sơ đồ kiến trúc tổng thể của Kafka
Tổng kết
Như vậy mình đã giới thiệu tổng quan về kiến trúc thổng thể, ưu điểm cũng như ứng dụng của Apache Kafka. Ở những bài viết sau mình sẽ hướng dẫn cách cài đặt Apache Kafka trên Docker cũng như đi sâu vào việc sử dụng Kafka như một Messsage Queue để giao tiếp bất đồng bộ giữa các microservices theo kiến trúc EDA. Cảm ơn các bạn đã đọc bài viết.