Ở bài 2 chúng ta đã đề cập đến việc xử dụng RAPIDS trong việc xử lí và phân tích data bằng GPU thì ở bài viết này mình sẽ hướng dẫn cách dùng
cuDF
cuDF: hay còn gọi là cuda dataframe - dùng để xử lí data bằng cuda nhưng 1 điều tuyệt vời là syntax của cuDF hoàn toàn giống với pandas nhưng về mặt hiệu suất lại nhanh gấp 10-400 lần
Cách hoạt động của cuDF
Có thể hiểu đơn giản là khi bạn call cudf.pandas thì việc import pandas (hoặc bất kì sub-module nào của nó ) sẽ không thực sự hoạt động như 1 thư viện pandas bình thường mà thay vào đó là gọi proxy module (module thay thế/tạm thời) có chức năng thay thế tạm thời cho các thành phần trong pandas. Điều này cho phép tận dụng sức mạnh của GPU để xử lý dữ liệu mà vẫn giữ syntax giống pandas
- Đầu tiên khi chúng ta load cudf.pandas nó sẽ "giả lập (spoof)" module của pandas, nghiã là khi bạn gọi pandas nhưng thực tế là bạn đang dùng cudf.pandas
- Code của bạn hoặc các thư viện bên thứ ba có sử dụng pandas đều sẽ được hoạt động thông qua cudf.pandas
Ví dụ:
%load_ext cudf.pandas import pandas as pd import seaborn as sns df = pd.DataFrame({ 'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]
}) df['C'] = df['A'] + df['B']
print(df) sns.barplot(x='A', y='B', data=df) Thì ở đây df['A'] + df['B'] sẽ được thực hiện ở GPU (thông qua cudf.pandas) và việc dùng seaborn (như 1 thư viện bên thứ ba có sử dụng pandas) thì plot cũng sẽ được thực thi ở GPU
Các thư viện thứ 3 khác hỗ trợ cudf
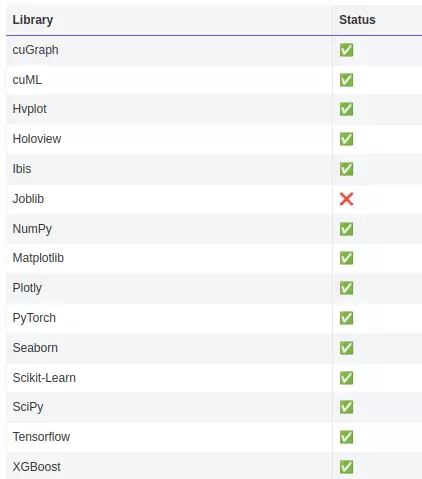
-
Khi chúng ta gọi các hàm của pandas thì cudf.pandas sẽ xử lý thay thế nếu có các hàm tương ứng trong cudf.
-
Nếu không có các hàm tương ứng trong cudf thì dữ liệu sẽ được copy về lại CPU để dùng phiên bản gốc của pandas. Sau khi xử lí xong có thể copy về lại GPU nếu cần thiết hoặc in kết quả
Ở đây chúng ta có 2 cách sử dụng cudf.pandas:
- Load trực tiếp cudf.pandas rồi xử dụng
- import pandas rồi convert từ pandas sang cudf.pandas
Code
Trên Notebook
%load_ext cudf.pandas
import pandas as pd
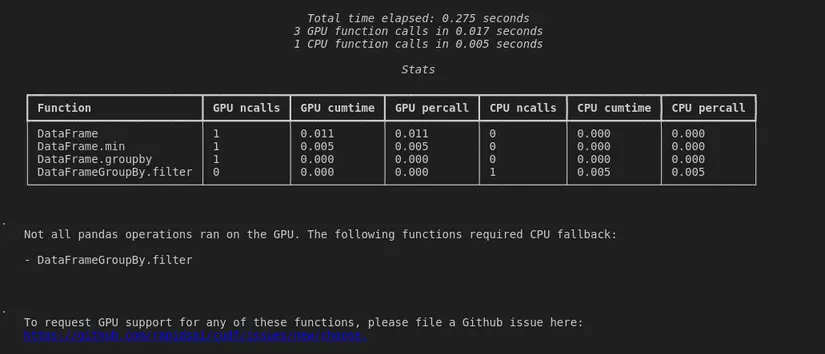
%%cudf.pandas.profile
df = pd.DataFrame({'a': [0, 1, 2], 'b': [3, 4, 3]}) df.min(axis=1)
out = df.groupby('a').filter( lambda group: len(group) > 1
) 
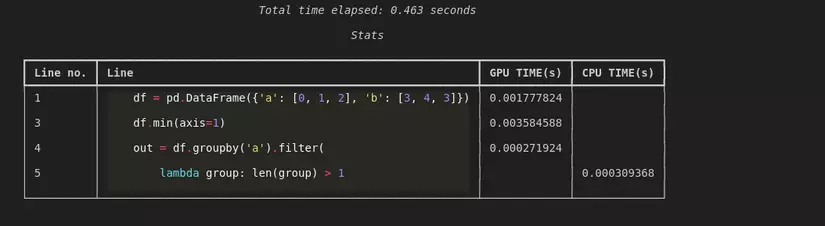
%%cudf.pandas.line_profile
df = pd.DataFrame({'a': [0, 1, 2], 'b': [3, 4, 3]}) df.min(axis=1)
out = df.groupby('a').filter( lambda group: len(group) > 1
) 
Trên Local
import pandas as pd df = pd.DataFrame({'a': [0, 1, 2], 'b': [3, 4, 3]}) df.min(axis=1)
out = df.groupby('a').filter( lambda group: len(group) > 1
)
chạy command để sử dụng cudf.pandas
$python3 -m cudf.pandas <tên file>.py
-m cudf.pandas hoạt động giống như %load_ext cudf.pandas
Và để profile thì dùng câu lệnh này:
$python3 -m cudf.pandas --profile <tên file>.py
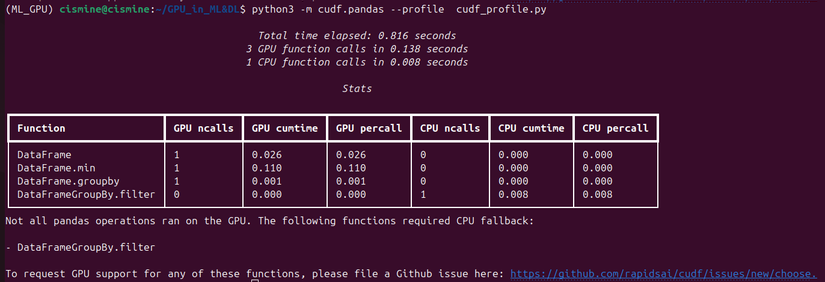
$python3 -m cudf.pandas --line-profile <tên file>.py
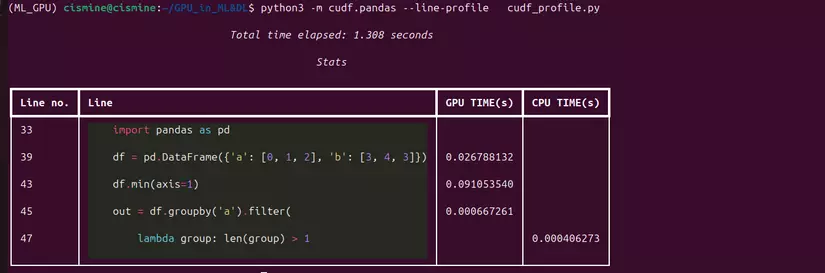
Qua đoạn code demo ta có thể thấy "DataFrameGroupBy.Filter" không hỗ trợ trên GPU nên đã được sử dụng trên CPU 1 cách tự động nên ở bài viết sau mình sẽ hướng dẫn cách tự viết các kernel để hỗ trợ cho GPU để tối ưu 1 cách tối đa
Câu hỏi
Qua các bức ảnh trên tại sao total time không bằng tổng time của CPU và GPU ?