Xin chào anh đã quay trở lại, nếu là lần đầu thì anh em có thể xem từ đầu Series của mình 👉️ tại đây
Tiếp tục hôm nay mình sẽ giới thiệu 1 thành phần trong Apache Kafka mà có thể ít ae biết tới và sử dụng nó là cái vẹo gì thì anh đọc tới hết bài nhé.
Let's go
Như tiêu đề của bài viết thì không gì khác chính là thằng Apache Kafka Connect
Đôi lời giới thiệu về bản thân, à nhầm Kafka Connect
-
Là một công cụ để sử dụng cho việc đồng bộ dữ liệu giữa các Database như: MongoDB, MySQL, SQLServer... ngoài ra cũng có thể dùng cho HDFS và cũng có thể để "ghi" data xuống Elastichsearch .
-
Kafka Connect nó cũng có các khả năng giống như Apache kafka
- Dễ dàng mở rộng (High scalable)
- Độ tin cậy cao (High reliable)
- Dữ liệu truyền tải có độ tin cậy cao (High durable)
- Thông lượng cao (High performance)
- Chịu lỗi cao (High fault tolerance)
- Dễ dàng mở rộng (High scalable)
Tiếp theo ae cùng mình đi vào chi tiết kiến trúc và các thành phần
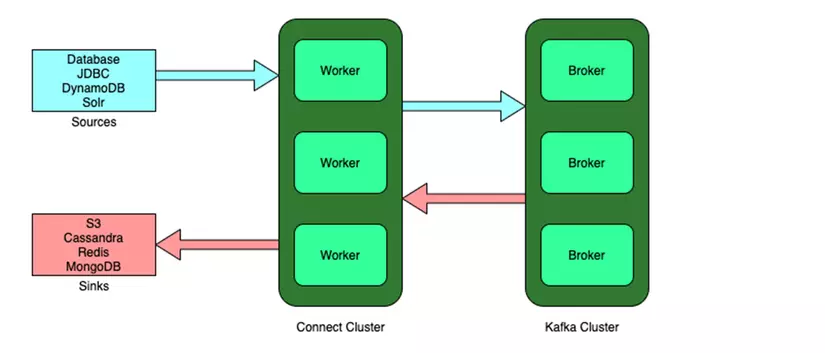
Quay sang trái, à nhầm 😄 từ phải sang trái của bức hình đầu tiên thì mình cũng đã nhắc ở trên rồi Datasource 1 đầu để đọc lên và 1 đầu để ghi xuống
gọi là Source và Sink .
Để ae dễ hiểu thì mình sẽ giải thích lần lượt như sau;
Concept tất cả các thành phần của thằng Kafka connect nó bao gồm:
1. Connector 2. Convertor 3. Task 5. Workers 5. Transforms 6. Dead letter queue
**Connector **
Thành phần này 😂 (nghe có vẻ hơi nhạy cảm nhỉ nhưng mà thôi) có nhiệm vụ là Connect tới Datasource đọc dữ liệu từ Datasource như MySQL là binlog và MongoDB là Oplog ....
- String, Json, Avro, ByteArray, Protobuf
** Lưu ý: ** là Connector và Convert không nằm bên trong hay được hỗ trợ bởi thằng Kafka hay KafkaConnect mà nó được viết dưới dạng Plugin (có thể bằng ngôn ngữ Java) build dưới dạng jar file và khi start Kafka Connect ae cần cấu hình đúng Path nới chưa các file Jar lib.
Connector: ông này giống như là các anh leader giống thôi nhé 😁.
Một số tham số cấu hình 1 Connector submit tới kafka Connect để làm những công việc nêu trên sẽ như sau :
{ "name": "******", "config": { "tasks.max":"3", "connector.class": "com.mongodb.kafka.connect.MongoSourceConnector", "connection.uri": "mongodb://192.168.20.121:27017,192.168.20.122:27017,192.168.20.123:27017", "database": "name", "collection": "answer", "key.converter.schemas.enable": false, "value.converter.schemas.enable": false, "publish.full.document.only":true, "key.converter": "org.apache.kafka.connect.storage.StringConverter", "value.converter": "org.apache.kafka.connect.storage.StringConverter", "topic.creation.enable":"true", "topic.creation.default.replication.factor":"3", "topic.creation.default.partitions":3, "copy.existing":true, "poll.max.batch.size":"1000", "poll.await.time.ms":"5000", "batch.size":0, "change.stream.full.document":"whenAvailable" }
}
Converter
-
Ông này là 1 thành phần quan trọng trong hệ thống Kafka Connect hỗ trợ 1 phần định dạng cụ thể khi ghi hoặc đọc dữ liệu .
-
Tasksử dụng Convertor để chuyển đổi dữ liệu giữa các thành phần trong hệ thống -
Các định dạng convertor có thể được hỗ trợ giữa Kafka và Kafka connect bao gồm:
- StringConverter
- JsonConverter
- JsonSchemaConverter
- ByteArrayConverter
- ProtobufConverter
Để dễ hiểu thì ae nhìn hình minh họa bên dưới như sau:
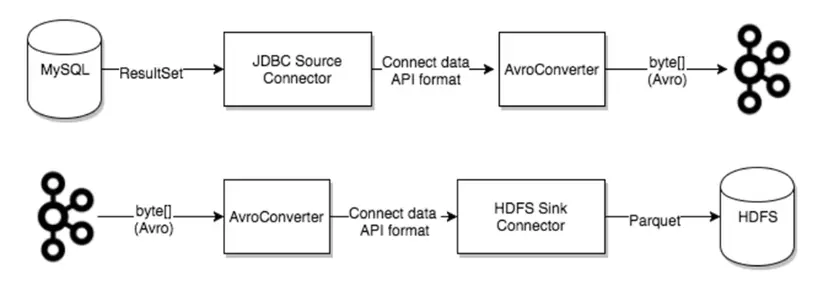
👉️ Khi một connector được tạo ra nó sẽ điều phối các Task xử lý dữ liệu
**Task **
ông này là nhân tố chính xử lý dữ liệu giữa Kafka và các Datasource Sink hình ảnh minh họa như sau:
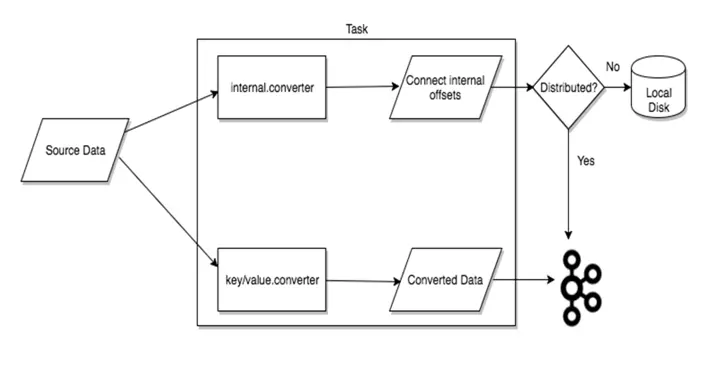
Về chỗ Distributed mình sẽ giải thích ở bên dưới nhé ae 😀.
Rebalancing các Task
- Khi lần đầu tiên connector được khởi tạo và kết nối tới Cluster thì các
Worker(mình sẽ giải thích ngay bên dưới) sẽ Rebalancing 100% các Connect vàTaskcủa connect đến các Worker có cùng 1 số lượngTaskxử lý.
(Các Task sẽ được phân phối đều nhau cho các Worker).
- Khi các Worker Fail over (có 1 task nào đó xử lý convert data bị exception xảy ra .... ) thì các
Taskcũng rebalancing trên các Worker - Khi các Task fail over sẽ ko tự động start lại mà phải restart lại thủ công (việc này có thể thực thi thông qua call API tới Kafa Connect)
Ví dụ:
Lấy trạng thái và restart Task như sau
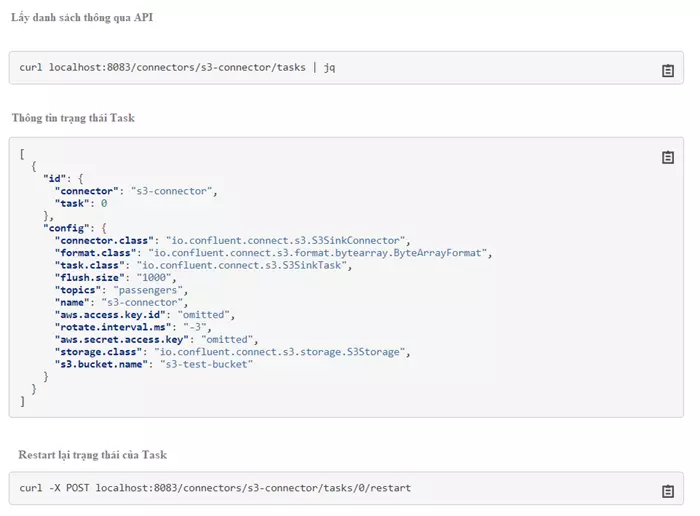
Tiếp theo là tới Worker
-
Connector và Task là các đơn vị xử lý thì thằng Worker chính là
Scheduledthực thi -
Có 2 mode Worker
-
Standalonechế độ cơ bản chỉ có 1 Kafka Connect Server duy nhất đảm nhiệm và thực thi tất cả các Connectors và Task tham số được truyền theo paramameter khi chạy,các bản ghi đọc từ Datasource sẽ được lưu trữ trên file system (Chính vì như vậy mà dữ liệu luôn có tính tin cậy cao) trước khi ghi xuống các Datasource khác .
-
Distributedmình đã nhắc ở phía trên là chế độ cung cấp khả năng có thểmở rộngvàchịu lỗicác Server Kafka Connect run trên cùng 1 cụm Kafka Server và có chung 1 Group id sẽ tạo lên 1 cụm clusterGiao tiếp hay tương tác với các Kafka connect thông qua API. Xử lý: khi đọc log dữ liệu từ các Datasource và được converter thì dữ liệu sẽ được đưa lên kafka Topic theo tên đã được định nghĩa trong tham số của connector.
-
Transforms
-
Trong quá trình đồng bộ giữa 2 Datasource có trong TH ae muốn bỏ bớt 1 vài trường hoặc chuyển đổi kiểu dữ liệu thì có thể sử dụng Transform Transform được sử dụng khi
Sinkxuống Datasource (DB đầu ghi xuống dữ liệu)Ví dụ: với hàm Cast với trường
IDvàScorekhi tạo connector ae set thêm tham số như sau:
"transforms": "Cast", "transforms.Cast.type": "org.apache.kafka.connect.transforms.Cast$Value", "transforms.Cast.spec": "ID:string,score:float64"với đầu vào là :
{"ID": 46920,"score": 4761}thì đầu ra sẽ như sau:
{"ID": "46290","score": 4761.0}Cuối cùng là Dead Letter Queue
-
Khi mà 1 record không hợp lệ xảy ra với nhiều lý do khác nhau
Ví dụ: 1 record Source lên với định dạng JSON nhưng khi Sink lại cấu hình ở định dạng Khác JSON
-
Mặc dù có lỗi xảy ra nhưng Connector vẫn tiếp tục xử lý và gửi record lỗi tới Dead Letter Queue (TH mà trong config connector ae có define Dead Letter Queue )
-
Tiếp theo là khi 1
messagetới DLT Queue sẽ có thông tin header tại đây sẽ có thông tin lý do lỗi tại sao (cũng oke phết nhỉ ).Ví dụ: thông số config :
errors.tolerance: all errors.deadletterqueue.topic.name: <topic-name>
Lời kết :
Cảm ơn ae đã đọc và theo dõi và đọc bài viết của mình, hy vọng nhận được đóng góp ý kiến và ủng hộ nhiều hơn để mình có động lực ra các bài viết tiếp theo nhé ae. 👋👋👋👋👋.
Mời ae cùng đón chờ phần tiếp theo của bài viết nhé!!