Giới thiệu
Khi nhắc tới việc cải thiện hiệu suất của các tác vụ học máy, chắc hẳn các bạn sẽ nghĩ tới 1 cách đơn giản nhất chính là đào tạo nhiều mô hình trên cùng 1 tập dữ liệu, sau đó tính trung bình dự đoán của chúng hoặc chọn ra mô hình có độ chính xác tốt nhất (thông thường là lấy trung bình dự đoán). Tuy nhiên cách này tức là mình sẽ sử dụng toàn bộ các mô hình, chưa nói đến việc các mô hình này khá cồng kềnh và tốn kém trong việc tính toán. Thử nghĩ tới việc áp dụng nó vào thực tế, với số lượng người dùng khổng lồ thì nó sẽ chậm chạp thế nào. Có ai lại đi sử dụng một mô hình điểm danh tự đồng qua các cam mà bắt người dùng phải đứng một chỗ lâu để cho nó phân tích cho xong không =)))
Knowledge Distillation
Vào năm 2015, khi mà khái niệm Transfer Learning đã ra đời từ rất lâu (1972, Stevo Bozinovski – Ante Fulgosi), Geoffrey Hinton đã giới thiệu phương pháp Knowledge distillation – một trong những phương pháp thuộc họ transfer learning. Hinton và các cộng sự của ông đã chỉ ra rằng có thể chắt lọc kiến thức trong một họ mô hình thành công về một mô hình duy nhất kích thước nhỏ nhưng tiết kiệm chi phí tính toán và dễ triển khai trên quy mô lớn hơn trong bài báo mang tựa đề “Distilling the Knowledge in a Neural Network”.
Thuật toán lấy ý tưởng chính từ quá trình học tập ở người: chúng ta học tập kiến thức từ giảng viên – những người có kiến thức thâm sâu, kinh nghiệm nhiều hơn chúng ta – những học sinh còn bỡ ngỡ chưa có nhiều kiến thức. Đối chiếu vào Machine learning, thì mô hình lớn hơn sẽ được coi là Teacher, còn mô hình nhỏ hơn sẽ được coi là Student.
Theo phương pháp này, mô hình Teacher sẽ có thể hướng dẫn song song mô hình Student (mô hình mục tiêu) thông qua pseudo-labels. Hàm mục tiêu của phương pháp này kết hợp giữa Hard Loss và KL divergence loss. Hard loss thông thường là Cross Entropy trong các bài toán phân lớp. Còn KL divergence loss là thành phần được thêm vào nhằm tối thiểu sự khác biệt về phân phối xác suất dự báo giữ student và teacher suggestion dạng pseudo-labels.
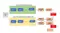
(Nguồn: https://medium.com/analytics-vidhya/knowledge-distillation-in-a-deep-neural-network-c9dd59aff89b)
Teacher Model và Student Model
- Teacher Model: Một mô hình lớn, có thể là tập hợp các mô hình được đào tạo riêng biệt hoặc 1 mô hình lớn duy nhất, được đào tạo với một bộ điều chỉnh rất mạnh.
- Student Model: Mô hình nhỏ hơn, sử dụng kiến thức chắt lọc từ Teacher network. Nó sử dụng một hình thức đào tạo khác, được gọi là “sự chắt lọc”, để chuyển kiến thức đã học từ Teacher Model sang chính mình. Student Model sẽ phù hợp để triển khai hơn là so với Teacher Model bởi nó không tốn kém về mặt tính toán và đem lại độ chính xác tương đương hoặc tốt hơn so với Teacher Model (đã được các bài báo liên quan chứng minh điều này)
Quá trình distillation
Nếu các bạn đọc tới đây, có thể sẽ biết luôn quá trình distillation sẽ gồm 2 bước chính:
- Huấn luyện Teacher model: teacher model được huấn luyện trên tập dữ liệu đã gán nhãn. Bộ dữ liệu này thường có kích thước vừa đủ để Teacher Model học được các đặc trưng tổng quát. Sau khi đã đạt đến một ngưỡng đủ tốt (có thể do các bạn quy ước, ví dụ accuracy > 90%), chúng ta sẽ dùng teacher model để huấn luyện student model.
- Huấn luyện Student model: Quá trình này sẽ dựa trên gợi ý từ teacher model (predict) để cải thiện student. Nếu dùng cách thông thường, student sẽ áp dụng loss function dạng cross-entropy dạng:
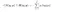
Cross-entropy giúp đo lường sự tương quan giữa phân phối xác suất dự báo p và ground-truth q (q là một one-hot vector). Mục tiêu tối thiểu hoá loss function cũng chính là làm cho phân phối xác suất dự báo và ground-truth giống nhau nhất.
Để củng cố dự báo của student, trong hàm loss function, dự báo từ teacher sẽ được sử dụng để thay thế cho ground-truth. Tức là chúng ta sẽ huấn luyện sao cho phân phối xác suất dự báo của student gần với teacher nhất. Điều này cũng gần giống như khi bạn được giáo viên cung cấp đáp án cho một bài thi trắc nghiệm, bạn sẽ càng giỏi nếu đáp án mà bạn làm sát với đáp án mà giáo viên cung cấp nhất.
Như vậy distillation loss tại quan sát xi sẽ có dạng:
Về cụ thể thực hành bằng python với tensorflow, mời bạn đọc đọc thêm tại đây. Bài viết vô cùng chi tiết từ việc giải thích các hàm loss cũng như việc thực hành cho từng bước.
Ưu điểm của Knowledge Distillation:
- Có thể deploy ở Edge: Student Model kế thừa chất lượng tốt từ Teacher Model, nhưng hiệu quả hơn cho việc suy luận do đọ chính xác là tương đương, thậm chí hơn nhưng lại gọn nhẹ, cần ít tài nguyên tính toán hơn hẳn
- Cải thiện khả nămg tổng quát hóa: Teacher model tạo ra “soft targets” cho quá trình training Student Model. Soft target có entropy cao cung cấp nhiều thông tin hơn. Chứng minh cho thấy soft target có ít phương sai hơn về độ dốc giữa các training case cho phép Student network được đào tạo trên ít dữ liệu hơn nhiều so với Teacher network
So sánh với phương pháp training from scratch
- Đối với các mô hình phức tạp, theo lý thuyết thì không gian tìm kiếm sẽ lớn hơn so với mô hình nhỏ hơn. Tuy nhiên nếu chúng ta coi rằng có thể đạt được sự hội tụ giống nhau (thậm chí tương tự) bằng cách sử dụng một mạng nhỏ hơn, thì không gian hội tụ của Teacher Network nên trùng với không gian nghiệm của Student Network
- Tuy nhiên, chỉ điều kiện đó thôi không đủ để đảm bảo cho sự hội tụ của Student network tại cùng một vị trí. Student network có thể có sự hội tụ rất khác với Teacher network. Nhưng nếu Student network được hướng dẫn để tái tạo hành vi của Teacher Network (Distillation) thì không gian hội tụ của nó được cho là chồng lên không gian hội tụ của Teacher network ban đầu.
Kết luận
Như vậy có thể thấy knowledge distillation là một phương pháp học có ý tưởng khá hay dựa trên việc học tập của con người. Đó là học sinh cần được hướng dẫn từ giáo viên cũng giống như mô hình student nhỏ hơn cần được học từ mô hình teacher to hơn. Xung quanh knowledge distillation còn rất nhiều những lớp mô hình khác có performance tốt hơn chẳng hạn như:
- Không chỉ cho đáp án mà còn dạy cách làm bài: teacher không chỉ dạy student thông qua output mà còn can thiệp vào quá trình học đặc trưng của student trên từng layer.
- Sử dụng trợ lý (teacher assistant) để dạy bổ sung cho student.
- Sử dụng kết hợp thêm attention để củng cố thêm học đặc trưng cho student
Trong khuôn khổ bài viết, mình đã giới thiệu qua về một hướng tiếp cận tương đối hay. Bài viết lấy từ cảm hứng khi một lần lướt dạo FB thấy được. Link bài viết đây nhé ^^