Keras là gì
Keras là một open source cho Neural Network được viết bởi ngôn ngữ Python. Nó là một library được phát triển vào năm 205 bởi Francois Chollet, là một kỹ sư nghiên cứu Deep Learning. Keras có thể sử dụng chung với các thư viện nổi tiếng như Tensorflow, CNTK, Theano. Một số ưu điểm của Keras như:
- Dễ sử dụng, dùng đơn giản hơn Tensor, xây dựng model nhanh.
- Run được trên cả CPU và GPU.
- Hỗ trợ xây dựng CNN , RNN hoặc cả hai.
Với những người mới tiếp cận đến Deep như mình thì mình chọn sử dụng Keras để build model vì nó đơn giản,dễ nắm bắt hơn các thư viện khác. Dưới đây mình xin giới thiệu một chút về API này.

Models
Trong Keras có hỗ trợ 2 cách dựng models là Sequential model và Function API. Với Seqential ta sử dụng như sau:
from keras.models import Sequential
from keras.layers import Dense, MaxPooling2D, Flatten, Convolution2D model= Sequential()
model.add(Convolution2D(32,3,3, input_shape=(64,64,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(output_dim=128,activation='relu'))
model.add(Dense(output_dim=1, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, batch_size = batch_size, epochs = eposhs, verbose =1, validation_data =(x_test, y_test))
Nội dung đoạn code trên như sau:
- Khởi tạo models Sequential ( )
- Tạo Convolutionnal Layers : Conv2D là convolution dùng để lấy feature từ ảnh với các tham số :
- filters : số filter của convolution
- kernel_size : kích thước window search trên ảnh
- strides : số bước nhảy trên ảnh
- activation : chọn activation như linear, softmax, relu, tanh, sigmoid. Đặc điểm mỗi hàm các bạn có thể search thêm để biết cụ thể nó ntn.
- padding : có thể là "valid" hoặc "same". Với same thì có nghĩa là padding =1.
- Pooling Layers: sử dụng để làm giảm param khi train, nhưng vẫn giữ được đặc trưng của ảnh.
- pool_size : kích thước ma trận để lấy max hay average
- Ngoài ra còn có : MaxPooling2D, AvergaPooling1D, 2D ( lấy max , trung bình) với từng size.
- Dense ( ): Layer này cũng như một layer neural network bình thường, với các tham số sau:
- units : số chiều output, như số class sau khi train ( chó , mèo, lợn, gà).
- activation : chọn activation đơn giản với sigmoid thì output có 1 class.
- use_bias : có sử dụng bias hay không (True or False)
- Hàm compile: Ở hàm này chúng ta sử dụng để training models như thuật toán train qua optimizer như Adam, SGD, RMSprop,..
- learning_rate : dạng float , tốc độc học, chọn phù hợp để hàm số hội tụ nhanh.
- Hàm fit ():
- Bao gồm data train, test đưa vào training.
- Batch_size thể hiện số lượng mẫu mà Mini-batch GD sử dụng cho mỗi lần cập nhật trọng số .
- Epoch là số lần duyệt qua hết số lượng mẫu trong tập huấn luyện.
- Giả sử ta có tập huấn luyện gồm 55.000 hình ảnh chọn batch-size là 55 images có nghĩa là mỗi lần cập nhật trọng số, ta dùng 55 images. Lúc đó ta mất 55.000/55 = 1000 iterations (số lần lặp) để duyệt qua hết tập huấn luyện (hoàn thành 1 epochs). Có nghĩa là khi dữ liệu quá lớn, chúng ta không thể đưa cả tập data vào train được, ta phải chia nhỏ data ra thành nhiều batch nhỏ hơn. Ngoài ra ta có thể khai báo như sau :
from keras.models import Model
from keras.layers import Input, Dense input = Input(shape = (64,))
output = Dense(32)(input)
model = Model(input = input, output= output)
Tiền xử lý
train_datagen = ImageDataGenerator( rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) test_datagen = ImageDataGenerator(rescale=1./255)
Trong Keras có đưa ra các funtion xử lý các loại data như:
- Sequence Preprocessing : tiền xử lý chuỗi.
- TimeseriesGenerrator : tạo data cho time series
- pad_sequences : padding các chuỗi có độ dài bằng nhau
- skipgrams : tạo data trong models skip gram, trả về 2 tuple nếu từ xuất hiện cùng nhau, là 1 nếu không có.
- Text Preprocessing : tiền xử lý text
- Tokenizer : tạo token từ documment
- one_hot : tạo data dạng one hot encoding
- text_to_word_seqence : convert text thành sequence ..
- Image Preprocessing : tiền xử lý image
- ImageDataGenerator : tạo thêm data bằng cách scale, rotation ,...để thêm data train
Note
Loss_funtion
- mean_squared_eror: thường dùng trong regression tính theo eculid
- mean_absolute_error : để tính giá trị tuyệt đối
- binary_crossentropy : dùng cho classifier 2 class
- categorical_crossentropy : dùng classifier nhiều class
Metrics
Để đánh giá accuracy của models
- binary_accuracy : dùng cho 2 class , nếu y_true== y_predict thì trả về 1 ngược lại là 0.
- categorical_accuracy : cũng giống như trên nhưng cho nhiều class
Optimizers
Dùng để chọn thuật toán training
- SGD: Stochastic Gradient Descent optimizer
- RMSprop
- Adam
Callbacks
Khi models chúng ta lớn khi training thì gặp lỗi ta muốn lưu lại models để chạy lại thì ta sử dụng callbacks
- ModelsCheckpoint : lưu lại model sau mỗi epoch
- EarlyStopping : stop training khi models training không hiệu quả
- ReducaLROnPlateau : giảm learning mỗi khi metrics không cải thiện
Ví dụ
Chúng ta hãy thử với tập Dataset được cung cấp từ link sau: https://www.kaggle.com/c/dogs-vs-cats
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.optimizers import RMSprop
from keras.layers import Activation, Dropout, Flatten, Dense, GlobalMaxPooling2D, Conv2D, MaxPooling2D
from keras.callbacks import CSVLogger
from livelossplot.keras import PlotLossesCallback
import efficientnet.keras as efn TRAINING_LOGS_FILE = "training_logs.csv"
MODEL_SUMMARY_FILE = "model_summary.txt"
MODEL_FILE = "cats_vs_dogs.h5" path = "home/thangtd/dataset/cat_dog/"
train_data = path + "training"
val_data = path + "val"
test_data = path +"test"
IMAGE_SIZE = 200
IMAGE_WIDTH, IMAGE_HEIGHT = IMAGE_SIZE, IMAGE_SIZE
EPOCHS = 20
BATCH_SIZE = 32
TEST_SIZE = 30 input_shape = (IMAGE_WIDTH, IMAGE_HEIGHT, 3) model = Sequential() model.add(Conv2D(32, 3, 3, border_mode='same', input_shape=input_shape, activation='relu'))
model.add(Conv2D(32, 3, 3, border_mode='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, 3, 3, border_mode='same', activation='relu'))
model.add(Conv2D(64, 3, 3, border_mode='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(128, 3, 3, border_mode='same', activation='relu'))
model.add(Conv2D(128, 3, 3, border_mode='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(256, 3, 3, border_mode='same', activation='relu'))
model.add(Conv2D(256, 3, 3, border_mode='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5)) model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5)) model.add(Dense(1))
model.add(Activation('sigmoid')) model.compile(loss='binary_crossentropy', optimizer=RMSprop(lr=0.0001), metrics=['accuracy']) with open(MODEL_SUMMARY_FILE,"w") as fh: model.summary(print_fn=lambda line: fh.write(line + "\n")) # Data augmentation
training_data_generator = ImageDataGenerator( rescale=1./255, shear_range=0.1, zoom_range=0.1, horizontal_flip=True)
validation_data_generator = ImageDataGenerator(rescale=1./255)
test_data_generator = ImageDataGenerator(rescale=1./255) training_generator = training_data_generator.flow_from_directory( train_data_dir, target_size=(IMAGE_WIDTH, IMAGE_HEIGHT), batch_size=BATCH_SIZE, class_mode="binary")
validation_generator = validation_data_generator.flow_from_directory( val_data_dir, target_size=(IMAGE_WIDTH, IMAGE_HEIGHT), batch_size=BATCH_SIZE, class_mode="binary")
test_generator = test_data_generator.flow_from_directory( test_data_dir, target_size=(IMAGE_WIDTH, IMAGE_HEIGHT), batch_size=1, class_mode="binary", shuffle=False) # Training
model.fit_generator( training_generator, steps_per_epoch=len(training_generator.filenames) // BATCH_SIZE, epochs=EPOCHS, validation_data=validation_generator, validation_steps=len(validation_generator.filenames) // BATCH_SIZE, callbacks=[PlotLossesCallback(), CSVLogger(TRAINING_LOGS_FILE, append=False, separator=";")], verbose=1)
model.save_weights(MODEL_FILE)
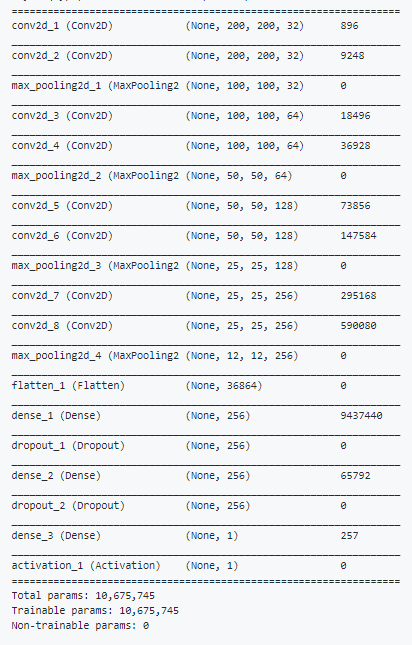
Sử dụng model.summary () để xem ntn :
 Mọi người có thể tự mình build model như bên trên và predict thử xem kết quả thế nào nhé !!!!
Mọi người có thể tự mình build model như bên trên và predict thử xem kết quả thế nào nhé !!!!