Khi xử lí bài toán Machine Learning thì bước đầu tiên không thể thiếu là data analyst và data processing thì ở bài viết này mình sẽ hướng dẫn các bạn cách xử lí 2 vấn đề này trong 1 nốt nhạc
Data analyst và Data processing trong 1 nốt nhạc
Các bước tiêu chuẩn khi xử lí 1 file csv bất kì là:
- Kiểm tra kiểu dữ liệu của các features
- Kiểm tra Missing/ Outlier/ Duplicate values
- Phân tích sâu hơn về data như: stastistics, sự phân bổ của data,...
Chung quy lại là có rất nhiều bước và sẽ mất kha khá thời gian để chúng ta code cũng như phân tích thì YData đã tạo ra thư viện ydata_profiling giúp chúng ta xử lí các công việc này
Cách sử dụng
Bạn có thể cài đặt ydata_profiling bằng câu lệnh:
pip install ydata-profiling Demo
import pandas as pd
from ydata_profiling import ProfileReport df = pd.read_csv('data.csv')
profile = ProfileReport(df, title="Profile csv", explorative=True)
profile.to_file("output.html")
Chỉ đơn giản 2 dòng các bạn đã có file html đầy đủ phân tích thống kê về data của các bạn
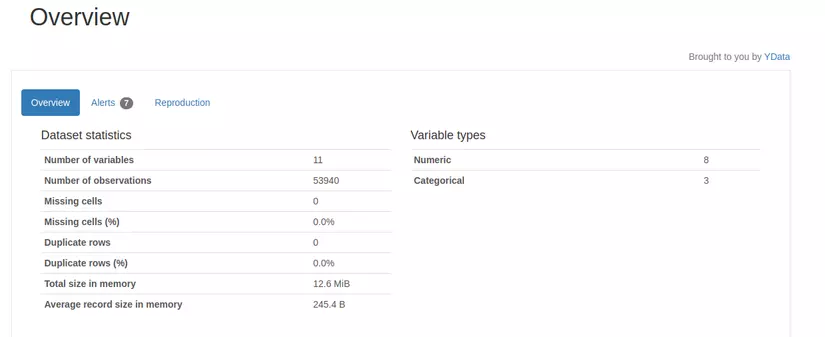
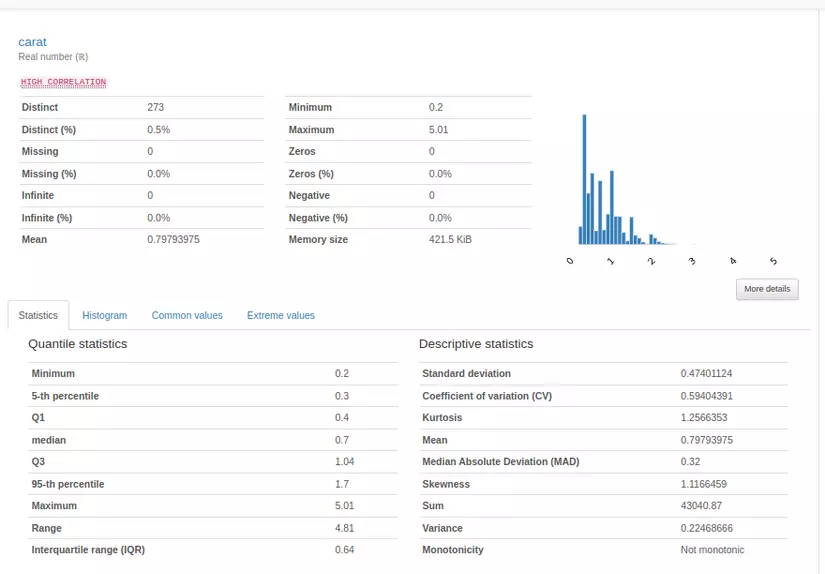
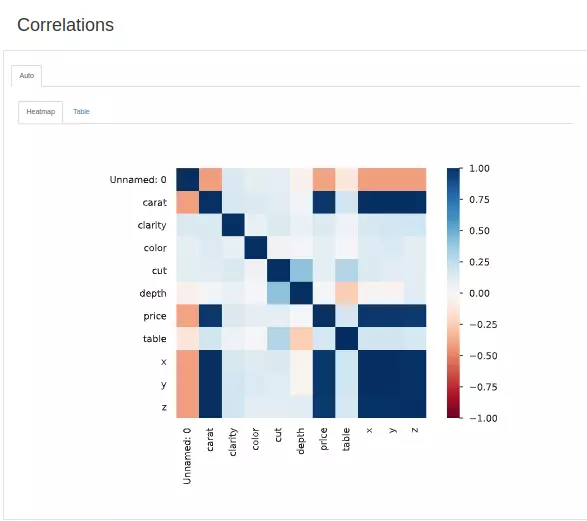
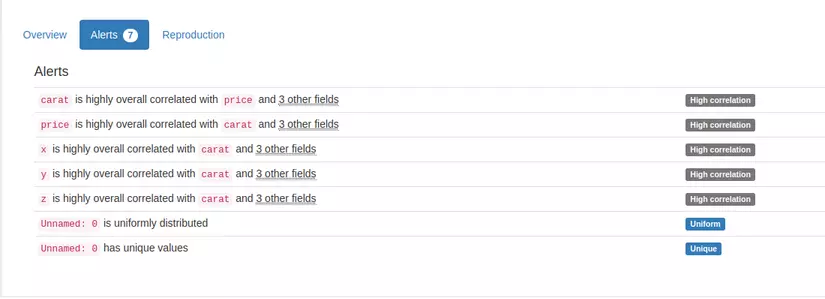
Hi vọng bài viết này sẽ giúp ích cho các bạn