
Trong phần này, chúng ta sẽ đi vào ý tưởng thuần của RL trong trạng thái cơ bản nhất, khi mà state và action space đủ để các values có thể lưu trữ vào trong array hoặc bảng. Trong các dạng như này, thông thường RL sẽ có thể tìm được chính xác action tối ưu trong hầu hết các state.
K-armed bandit problems.
Đặt trường hợp như sau, bạn gặp một trường hợp lặp lại liên tục giữa việc chọn giữa n trường hợp. Sau một lần bạn chọn sẽ được thưởng một điểm bất kì, công việc của bạn là phải lựa chọn các hành động ra sao để tối ưu hóa được điểm của mình sau một chu kì nhất định.
Ví dụ: An có 2 nút bấm, một nút bấm màu đỏ và một nút bấm màu xanh. Với mỗi một lần bấm nút màu đỏ, bạn sẽ nhận được ngẫu nhiên [0, 1, 2] cái kẹo, với mỗi lần bấm nút màu xanh bạn sẽ nhận được ngẫu nhiên [0, 0, 0, 1, 4] cái kẹo. Hãy đưa ra lựa chọn sao cho khi bạn bấm 10 lần sẽ được nhiều kẹo nhất. (trong trường hợp này chúng ta coi như các giá trị ngâu nhiên là không biết.)
Action-Value Methods.
Bây giờ, chúng ta sẽ xem qua một vài phường pháp đơn giản để có thể dự đoán được values của tập hành động (actions) và sử dụng nó để đưa các quyết định cho việc lựa chọn hành động sau này. Trong phần này, chúng ta sẽ xác định true (actual) value của hành động a là q(a), và estimated value trong bước thứ t là Qt(a). Nhận định rằng, giá trị true value của một hành động sẽ là giá trị trung bình nhận được khi lựa chọn một hành động. Một trong những phương pháp phổ thông để xác định giá trị này chính là phương pháp tính giá trị trung bình reward khi một hành động được lựa chọn. Với cách hiểu khác, nếu trong bước thứ t, hành động a được chọn Nt(a) lần cho tới thời gian t, khởi tạo lên một chuỗi R1, R2, …, Rnt(a), thì value sẽ được dự đoán bằng công thức:
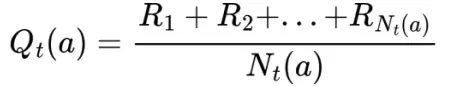
Nếu Nt(a) = 0, thì ta sẽ đặt Qt(a) bằng một giá trị mặc định nào đó, có thể là bằng 0. Với Nt(x) tiếng tới vô cùng, bởi lý thuyết của của đại số, Qt(x) sẽ hội tụ về q(a). Đây được gọi là phương pháp sample-average cho dự đoán action values do mỗi lần đưa ra dự đoán là một lần dự đoán action values, và nó không hoàn toàn cần đến giá trị tốt nhất. Mặc dù vậy thì ta vẫn sử dụng phương pháp đơn giản trên để đưa ra các lựa chọn cho hành động.
Một trong các phương pháp nhất trong việc xây dựng lên cách lựa chọn action là chọn action với giá trị action value là lớn nhất, để lựa chọn hành động trong bước t của các greedy actions, A*t, với mỗi
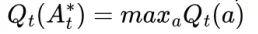
Hành động lựa chọn greedy action này có thể viết dựa dạng: 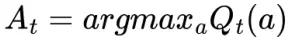
Trong này, ta xác định là argmaxa là value của a tại Qt(a) là tối ưu. Các greedy action được lựa chọn luôn luôn exploits các kiến thức hiện có để có thể tối đa hóa giá trị reward tức thời. Nó sẽ không mất quá nhiều thời gian để có thể lấy được các mẫu thử từ các tập hành động đã làm trước đó để xác định action đó có phải là tốt nhất hay không. Một các tiếp cận đơn giản là nó sẽ đưa ra các hành động greedy hầu hết các lần thử, và chỉ một vài lần nho nhỏ, với một giá trị epsilon thấp sẽ đưa ra các hành động ngẫu nhiên trong các hành động có xác xuất với actions values dự đoán (exploits). Phương pháp này được gọi là near-greedy action selection rule (luật lựa chọn hành động bán tham lam) e-greedy methods. Có một ưu điểm của phương pháp trên là với số lần giới hạn của số lần thử không ngừng tăng lên, mỗi một hành động sẽ được lựa chọn tiến đến vô hạn lần, dẫn đến Nt(a) -> vô cùng với mọi a, và điều này sẽ đảm bảo rằng mọi Qt(a) sẽ hội tụ về q(a).
The 10-armed Testbed.
Để có thể thử nghiệm được tính hiệu quả của greedy và e-greedy action-value methods, Chúng ta sẽ so sánh trên một tập các test problems. Đây là một tập gồm 2000 bài k-armed bandit ngẫu nhiên với k=10. Với mỗi một bài thì action values q*(a), a = 1, …, 10 sẽ được lựa chọn ngẫu nhiên trong một hệ normal (gaussian) distribution với mean 0 và varian 1.
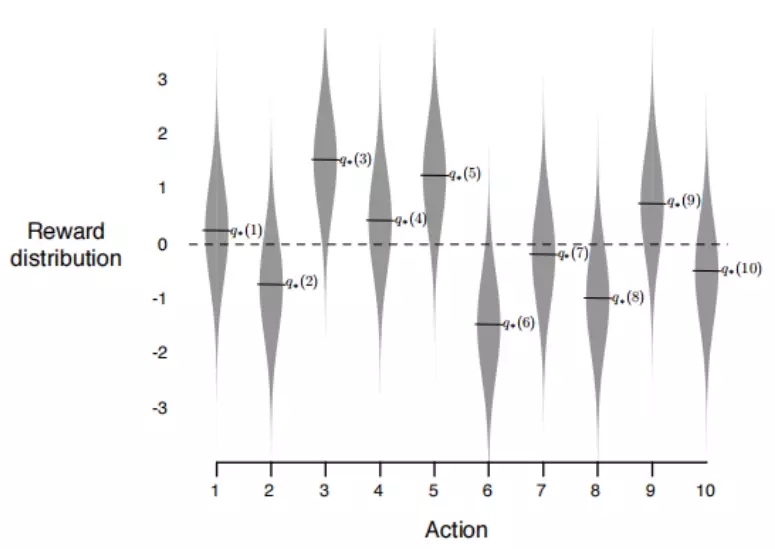
Sau đó, khi mà phương pháp đựa lựa chọn đưa vào để lửa chọn action At tại thời điểm t, giá trị reward thực tế Rt sẽ được lựa chọn ngẫu nhiên bằng bộ normal distribution với mean q*(At) và variance 1. (nhìn vào hình 2.1)
Với mỗi một phương pháp được sử dụng, chúng ta sẽ tính toán performance và behavior trong khi nó liên tục improve trong 1000 time steps của 1 trong những bandit problems, đây được gọi là 1 run (về sau sẽ đổi cách gọi thành episode). Liên tục lặp lại nó trong 2000 run chạy độc lập, chúng ta sẽ đo được average behavior.
Incremental Implementation.
Trong các action-value methods mà chúng ta đã đề cập đến thì ta đều estimate các action values là sample averages của các rewards thu được. Bây giờ, ta sẽ ta sẽ chuyển đổi câu hỏi làm thế nào tính trung bình một cách hiệu quả nhất, trong thực tế là với constant memory và constant per-time-step computation. (nói chung là cái này dễ)

Tracking a Nonstationary Problem.
Với phương pháp tính trung bình mà ta đã đề cập tới bên trên là dành cho các bài toán station bandit, là những bài toán mà xác xuất reward không hề thay đổi theo thời gian. Như chúng ta đã đề cập tới, phương pháp trên hầu như không hiệu quả đổi với vác bài toán bất định hình (Nonstationary). Trong các trường hợp đó, nó sẽ hợp lý hơn nếu ta đánh trọng số vào các reward gần và hiện tại hơn là các reward nhận được trong quá khứ. Một trong những phương pháp làm phổ thông nhất hiện nay là sử dụng một hằng số step-size. Cho ví dụ, trong Incremental update rule cho cập nhật các giá trị trung bình Qn của reward n-1 có thể thay đổi thành
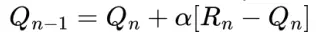
Trong này thì giá trị tham số alpha thuộc (0, 1] là hằng số. Kết quả của Qn+1 sẽ được tính toán bằng trung bình rewards trong quá khứ và giá trị khởi tạo Q1:
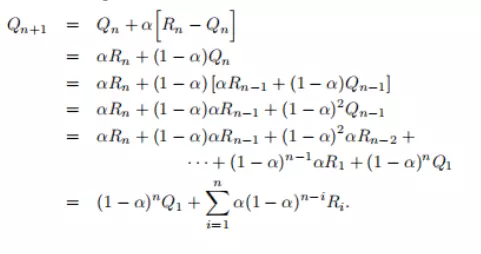
Chúng ta sẽ gọi là weighted average vì tổng của các trọng số là
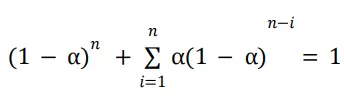
bạn có thể tự kiểm chứng. Lưu ý rằng trọng số, 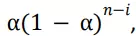
thay đổi Ri phụ thuộc vào đã có bao nhiêu reward trước đó, n - i, như đã quan sát. Với số lượn 1 - alpha là nhỏ hơn 1, và trọng số của Ri giảm dần số lần nhận được rewards. Trong thực tế, giá trị trọng số giảm exponentially dựa vào exponent trong 1 - alpha. (Nếu 1 - alpha = 0, thì thất cả trọng số sẽ được đánh vào reward mới nhất, Rn, bởi vì chúng ta xác nhận rằng 0^0 = 1). Cũng chính vì vậy mà phương pháp này đôi khi được gọi là exponential recency-weighted average.
Đôi khi nó là cần thiết khi mà ta thay đổi tham số step-size với mỗi một step. Hãy đặt
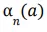
là giá trị step-size được sử dụng để tính toán reward nhận được sau lần thứ n lựa chọn hành động a. Chúng ta sẽ lưu ý, lựa chọn
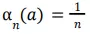
là kết quả trong sample-average method, được xác nhận là hội tụ tới true action values bởi định lý đại số. Điều đáng buồn là sự hội tụ không được đảm bảo với mọi lựa chọn của chuỗi
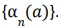
Một kết quả phổ biến trong stochastic approximation theory đưa ra cho chúng ta một điều kiện để đảm bảo sự hội tụ với xác xuất 1:

Điều kiện đầu tiên là cần thiết để xác nhận rằng các steps là đủ lớn để vượt qua được mọi điều kiện khởi tạo hay sự biến động ngẫu nhiên. Điều kiện thứ hai là điều cần để xác nhận rằng các steps sẽ trở nên đủ nhỏ để đảm bảo sự hội tụ.
Lưu ý rằng, cả hai điều kiện hội tụ đều được thoả mãn trong sample-average case
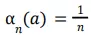
nhưng không phải là dành cho các trường hợp mà step-size là hằng số
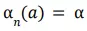
Trong trường hợp này, điều kiện thứ hai không được thỏa mãn, xác nhận rằng việc dự đoán sẽ không vào giờ hoàn toàn hội tụ nhưng sẽ liên tục thay đổi để thỏa mãn với các rewards nhận được gần nhất. Cũng như là đã nói bên trên, điều này là có thể quyết định được ở trong các nonstationary environment, và vấn đề mà effectively nonstationary là điều hết sức phổ biến trong các bài toán reinforcement learning. Đề cập thêm, chuỗi step-size đã thỏa mãn các điều kiện trên thường sẽ hội tụ khá chậm hoặc là cần các phương pháp tunning để có thể nhận được một tốc độ hội tụ đủ tốt. Mặc dù vậy, các chuỗi step-size mà thỏa mãn điều kiện hội tụ thường sẽ được sửu dụng trong các vấn đề về lý thuyết và ít khi được sử dụng trong ứng dụng thực tế hoặc nghiên cứ thực nghiệm.
Đôi lời trước khi kết thúc.
Trước tiên tôi xin lỗi mọi người khi không dịch một vài cụm từ sang tiếng Việt mà để nguyên tiếng Anh, nguyên do là những câu này khi dịch sang tiếng Việt có thể làm mất nghĩa và không truyền tải được đầy đủ thông tin mà đáng nhẽ nó nên mang nên tôi mới đưa ra quyết định như vậy.
Bài viết này tạm thời tới đây thôi, nếu các bạn thực sự muốn tìm hiểu sâu về RL thì có thể ủng hộ bài viết này. thank you all.
refercences.
-
Ảnh trên google