
Cánh fan AI vừa được phen "rụng tim" với siêu phẩm mới nhất của OpenAI - GPT-4o! Em này hứa hẹn sẽ khuấy đảo thế giới ngôn ngữ AI, mang đến những trải nghiệm "chém gió" đỉnh cao mà bạn chưa từng thấy.
Điểm nhấn ở siêu phẩm này chính là khả năng tương tác trực tiếp với ChatGPT, tha hồ "tám chuyện" mà không lo gián đoạn. Thử tưởng tượng xem, bạn có thể thoải mái trò chuyện, hỏi han, hay thậm chí "chỉ đạo" ChatGPT làm đủ mọi thứ, chỉ bằng giọng nói của mình!
Tuy màn demo trực tiếp có "chút xíu" trục trặc, nhưng không thể phủ nhận rằng những gì nhóm OpenAI đạt được quả là phi thường. Khả năng xử lý ngôn ngữ tự nhiên của GPT-4o vượt trội hơn hẳn so với các phiên bản trước, hứa hẹn mang đến những ứng dụng vô cùng rộng rãi trong tương lai.
Và điều "thú vị" hơn nữa là ngay sau khi ra mắt, OpenAI đã tung ra API GPT-4o, mở ra cơ hội cho các nhà phát triển sáng tạo những ứng dụng AI "siêu đỉnh".
Có gì mới ở GPT-4o?
Đi đầu là khái niệm về mô hình Omni , được thiết kế để hiểu và xử lý văn bản, âm thanh và video một cách liền mạch.
Trọng tâm của OpenAI dường như đã chuyển sang hướng dân chủ hóa quyền sử dụng GPT-4 cho đại chúng , giúp mô hình ngôn ngữ cấp độ GPT-4 có thể truy cập được ngay cả với người dùng miễn phí.
OpenAI cũng thông báo rằng GPT-4o bao gồm chất lượng và tốc độ được nâng cao trên hơn 50 ngôn ngữ , hứa hẹn mang lại trải nghiệm AI toàn diện hơn và có thể truy cập toàn cầu với mức giá rẻ hơn.
Họ cũng đề cập rằng thuê bao trả phí sẽ nhận được dung lượng gấp 5 lần so với người dùng không trả phí.
Hơn nữa, họ sẽ phát hành phiên bản ChatGPT dành cho máy tính để bàn để tạo điều kiện thuận lợi cho việc suy luận theo thời gian thực trên các giao diện âm thanh, hình ảnh và văn bản cho đại chúng.
Bài đăng trên blog của OpenAI bao gồm điểm đánh giá của các bộ dữ liệu đã biết, chẳng hạn như MMLU và HumanEval.
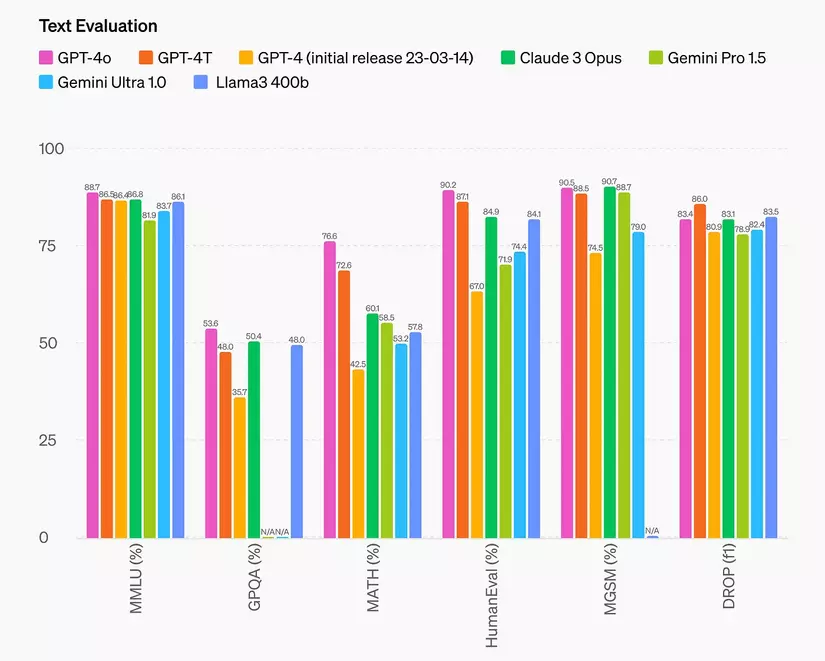
Nhìn vào biểu đồ, hiệu suất của GPT-4o quả là "đỉnh của chóp" trong lĩnh vực này - vừa rẻ, vừa nhanh, ai mà không thích chứ!
Tuy nhiên, "trải nghiệm" của bản thân cho thấy rằng, trong thời gian qua, đã có không ít "lời đồn" về hiệu suất ngôn ngữ "siêu việt" của các mô hình AI trên những tập dữ liệu quen thuộc. Thậm chí, một số mô hình còn được "lợi dụng" bằng cách "học vẹt" dữ liệu mở, dẫn đến kết quả "ảo diệu" trên bảng xếp hạng.
Đánh giá trên dataset "Cây nhà lá vườn"
Vì vậy, để có cái nhìn khách quan hơn, việc đánh giá độc lập hiệu suất của các mô hình này bằng cách sử dụng các tập dữ liệu "ít quen thuộc" hơn là điều vô cùng quan trọng - và đây chính là lúc bộ dữ liệu "cây nhà lá vườn" của mình ra tay!
Bộ dữ liệu này bao gồm 200 câu được phân chia thành 50 chủ đề, trong đó có một số câu được thiết kế "hóc búa" để tăng độ khó cho nhiệm vụ phân loại. Toàn bộ dữ liệu được mình tự tay tạo và gắn nhãn bằng tiếng Anh một cách tỉ mỉ.
Trong bài viết này, mình sẽ hóa thân thành "thám tử ngôn ngữ", mang đến cho bạn bản phân tích độc quyền về khả năng phân loại của các mô hình sau:
- GPT-4o: gpt-4o-2024–05–13
- GPT-4: gpt-4–0613
- GPT-4-Turbo: gpt-4-turbo-2024–04–09
- Gemini 1.5 Pro: gemini-1.5-pro-preview-0409
- Gemini 1.0: gemini-1.0-pro-002
- Palm 2 Unicorn: text-unicorn@001
Nhiệm vụ được giao cho các mô hình ngôn ngữ là ghép từng câu trong tập dữ liệu với đúng chủ đề. Điều này cho phép chúng tôi tính toán điểm chính xác cho mỗi ngôn ngữ và tỷ lệ lỗi của từng mô hình.
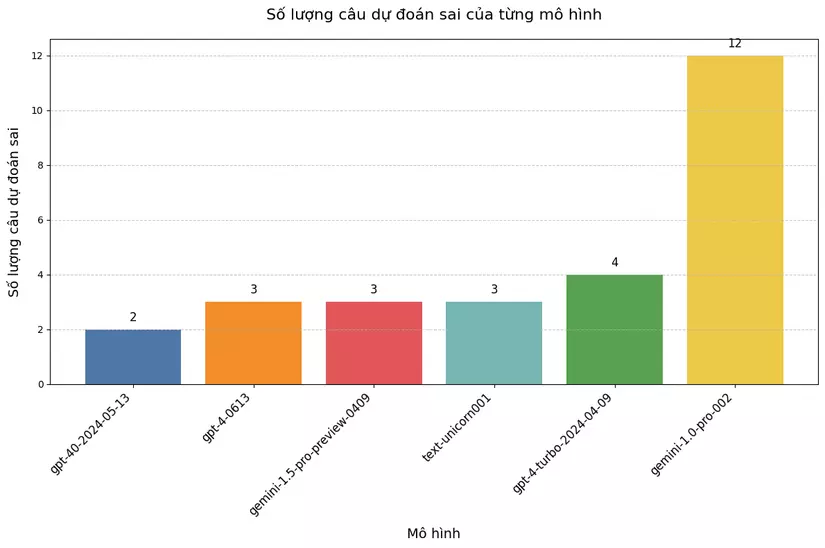
Nhìn vào biểu đồ, ta thấy GPT-4o xuất sắc nhất với chỉ 2 lỗi, bỏ xa các đối thủ còn lại.
Tiếp theo là GPT-4, Gemini 1.5 và Palm 2 Unicorn với chỉ 3 lỗi mỗi mô hình, cho thấy hiệu suất ấn tượng của chúng.
Đáng chú ý, GPT-4 Turbo lại có màn trình diễn "thất vọng" hơn so với đàn em GPT-4-0613, đi ngược lại với những thông tin được OpenAI quảng bá trên trang web mô hình của họ.
Cuối cùng, Gemini 1.0 đang tụt lại phía sau, điều này cũng dễ hiểu bởi nó thuộc phân khúc giá rẻ hơn.
Kết luận🌜️
Phân tích này sử dụng bộ dữ liệu tiếng Anh "cây nhà lá vườn" sẽ vén màn bí mật về khả năng ngôn ngữ "siêu việt" của các AI đình đám nhất hiện nay!
GPT-4o, "ngôi sao sáng" mới nhất từ OpenAI, tỏa sáng rực rỡ với tỷ lệ lỗi thấp nhất, chứng minh thực lực "không phải dạng vừa" như lời đồn!
Tuy nhiên, để có cái nhìn khách quan, cộng đồng AI và người dùng cần "soi" kỹ hơn bằng cách sử dụng nhiều bộ dữ liệu đa dạng, vẽ nên bức tranh toàn cảnh về hiệu quả thực tế của các mô hình, thay vì chỉ dựa vào tiêu chuẩn "đóng hộp".
Lưu ý:
- Phân tích này chỉ tập trung vào hiệu suất phân loại tiếng Anh. Hiệu suất trên các ngôn ngữ khác cần được nghiên cứu thêm.
- Kích thước tập dữ liệu còn hạn chế, có thể ảnh hưởng đến độ chính xác của kết quả.
- Các yếu tố khác như tốc độ xử lý, khả năng thích ứng với dữ liệu mới, v.v. cũng cần được xem xét khi lựa chọn mô hình LLM.
Và đừng quên cho mình một Upvote và một Bookmark nha, thank anh em đã đọc hết bài viết 