Trong hai phần trước, mình đã giới thiệu một chút về Graphs cũng như một số bài toán Machine Learning ở cấp độ Node cho Graphs rồi. Để đổi gió một tí thì hôm nay thực hành xào nấu mấy món khai vị liên quan đến Graphs nhé.
Lưu ý: Mình nghĩ mọi người nên cài môi trường ảo đi, vì cá nhân mình cũng gặp nhiều trường hợp version conflict hay những lỗi khá là củ chuối ngay từ khi cài đặt các thư viện rồi, chứ chưa nói gì đến lỗi code. Vì vậy, mọi người hãy cài đặt môi trường ảo để tránh những cái lỗi lặt vặt khó chịu này nhé. Mình sẽ lấy tên là graph_basic cho dễ nhớ dễ hiểu.
Nhắc lại cho mọi người cùng nhớ nè: Trong VSCode, mở Terminal lên và gõ mấy dòng như này: (mình dùng Conda để tạo cho dễ)
conda create -n graph_basic python=3.9
Cài đặt xong nhớ kích hoạt nhen: conda activate graph_basic
Okay, vô món chính thôi:
1. NetworkX
NetworkX là một Python package được xây dựng để tạo, thao tác và nghiên cứu các kiến trúc Graph từ đơn giản đến phức tạp. Theo mình thấy đây là thư viện dễ hiểu, dễ học, phù hợp với những ai mới tìm hiểu về Graph, cũng như nghiên cứu sâu về Graph trong Deep Learning.
Gì thì gì, trước tiên phải cài đặt đã. Cú pháp cài đặt rất đơn giản:
pip install networkx
Xào nấu thôi.
2. Dùng NetworkX cho các bài toán cơ bản
a. Tạo Graph, thêm Nodes, Edges.
Cú pháp của việc này cũng đơn giản thôi hehe:
# Import package cần thiết
import networkx as nx # Khởi tạo 1 Undirected Graph G:
G = nx.Graph() # Khởi tạo 1 Directed Graph H:
H = nx.DiGraph()
Sau khi đã khởi tạo các Graph rồi thì bây giờ thêm mắm thêm muối để tạo thành một Graph hoàn chỉnh nhé.
# Thêm Node và thêm attribute của node G.add_node(0, feature="nature", label=0)
print("Node 0 attribute is: {}".format(G.nodes[0])) # Thêm nhiều node bằng cách mô tả attribute của các nodes trong 1 dict
# sử dụng lệnh nx.add_nodes_from() G.add_nodes_from([ (1, {"feature": "animals", "label": 1}), (2, {"feature": "forest", "label": 2})
]) #(node, attribute_dict) # In mô tả của các nodes
for node in G.nodes(data=True): print(node) # In ra thông tin số lượng nodes
num_nodes = G.number_of_nodes()
print("G has {} nodes".format(num_nodes))
Khi đó ta được kết quả như này:
Node 0 attribute is: {'feature': 'nature', 'label': 0}
(0, {'feature': 'nature', 'label': 0})
(1, {'feature': 'animals', 'label': 1})
(2, {'feature': 'forest', 'label': 2})
G has 3 nodes
Có Nodes rồi thì thêm mô tả các cạnh vào để hoàn chỉnh cái Graph nào:
# Thêm Edges giữa 2 node:
G.add_edge(0, 1, weight=3)
print("Attribute of edge (0,1) is: {}".format(G.edges[(0,1)])) # Thêm nhiều Edges bằng cách mô tả attribute của các nodes trong 1 dict
# sử dụng lệnh nx.add_edges_from() G.add_edges_from([ (1, 2, {"weight": 2}), (2, 0, {"weight": 2.5})
]) # In mô tả của các Edges
for edge in G.edges(): print(edge) # In số lượng Edges trong Graph
num_edges = G.number_of_edges()
print("G has {} edges".format(num_edges))
Thì kết quả sẽ là....
Attribute of edge (0,1) is: {'weight': 3}
(0, 1)
(1, 2)
(2, 0)
G has 3 edges
Vẽ ra thì sẽ như thế này:
nx.draw(G, with_labels=True)
b. Node Degree, Node Centrality, Clustering Coefficient
Về mặt khái niệm cũng như công thức tính toán thì mọi người có thể xem lại ở 2 phần trước mình đã viết nhé:
Ở đây thì mình sẽ sử dụng NetworkX để minh hoạ các khái niệm này cho dễ hiểu. Trong phần này, mình sẽ lấy một dataset có sẵn trong NetworkX để minh hoạ nhé, đó là Zachary's karate club network. Đây là một Social Graph gồm 34 nodes (chỉ 34 thành viên) của một câu lạc bộ võ Karate. Để minh hoạ cho các khái niệm này thì sẽ tốt hơn nếu lấy một ví dụ của một Graph có nhiều node một xíu, vậy nên mình chọn đây làm ví dụ.
Gọi cái Graph đó thôi nào:
# Gọi Graph G = nx.karate_club_graph()
nx.draw(G, with_labels=True) # In ra Adjacency Matrix của Graph
print(nx.adjacency_matrix(G))
Minh hoạ cái Graph đó nè:
Lấy Node Degree của node có id 16 thử nhé (nhìn vào hình thì ta thấy Node Degree của node này bằng 2):
print(G.degree[16])
Kết quả bằng 2 thật. Mọi người có thể thử.
Khi đó ta thử tìm Average Node Degree, Clustering Coefficient và Node Centrality (cụ thể là Closeness Centrality) của Graph này thử:
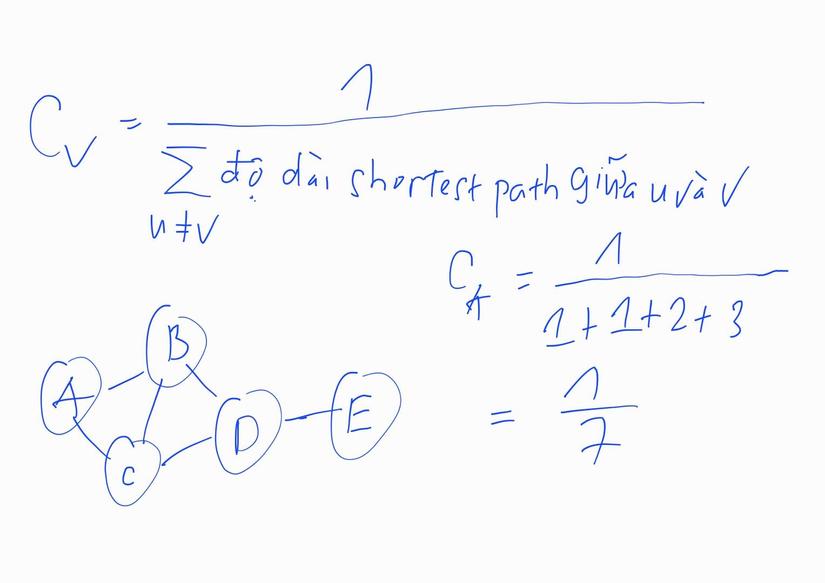
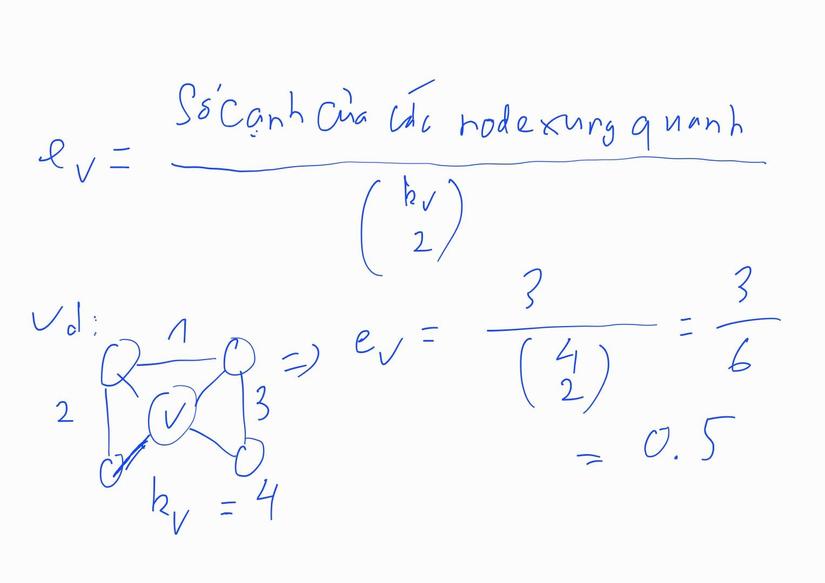
# Tìm Average Degree: num_edges = G.number_of_edges()
num_nodes = G.number_of_nodes()
avg_degree = round(float(2 * num_edges/num_nodes), 2) # Tìm Clustering Coefficient của Graph:
avg_cluster_coef = round(nx.average_clustering(G), 2) # Tìm Closeness Centrality của node có id là 6:
from networkx.algorithms import centrality
closeness_cen = round(centrality.closeness_centrality(G, 6), 2) print("Average degree: {}".format(avg_degree))
print("Clustering Coefficient of Graph is: {}".format(avg_cluster_coef))
print("Closeness Centrality of node with id 6 is: {}".format(closeness_cen))
Kết quả là:
Average degree: 4.59
Clustering Coefficient of Graph is: 0.57
Closeness Centrality of node with id 6 is: 0.38
Xong, vậy là mình đã dùng NetworkX để minh hoạ các bài toán cơ bản của phần Machine Learning trong Graphs rồi.
3. Kết luận
Hôm nay thì mình cũng đã giới thiệu món khai vị trong thực đơn Graphs, cũng như nguyên liệu chính để xào nấu các món Graphs trong Python mà mình hay dùng. Trong các bài tiếp theo thì mình sẽ đề cập thêm, đi sâu và chi tiết hơn vào các bài toán, cũng như giới thiệu thêm các packages để phục vụ việc nghiên cứu Deep Learning trong Graph nhé.
À đây cũng là bài viết đầu tiên của mình viết trong năm mới Quý Mão. Xin chúc tất cả mọi người một năm mới bình an, vạn sự như ý và gặt hái được nhiều thành công cả trong công việc lẫn trong cuộc sống nhé. Chúc anh em, mọi người một năm mới code ít bug và sống chan hoà, vui vẻ với những con bug của mình 🤣
Tài liệu tham khảo: CS224W: Machine Learning with Graphs
Link phần 2: P2. Machine Learning with Graphs