Lời mở đầu
Tiếp nối việc phân tích paper, hôm nay mình sẽ cùng các bạn phân tích 1 paper liên quan dến bài toán Semantic Segmentation và phương pháp Contrastive learning. Đường dẫn bài báo gốc mình để ở đây
Một số khái niệm cơ bản
- Học tự giám sát (Self-supervised learning): Hiểu đơn giản là ngoài việc sử dụng các nhãn (labels) do chính cong người gán nhãn, mô hình sẽ sử dụng thêm 1 lượng lớn các dữ liệu do chính nó gán nhãn cho việc học tập ở các bước và giai đoạn tiếp theo.
- Học tập liên tục (Contrastive learning): Là một kỹ thuật học máy mà mục tiêu là tìm những thứ tương tự và khác nhau trong 1 tập dữ liệu không có nhãn. Bản chất là dạy cho mô hình những điểm nào giống nhau hoặc khác nhau. Một ứng dụng cơ bản là nó có thể sử dụng trên cơ sở dữ liệu hình ảnh để tìm ra các hình ảnh có nét tương đồng
- Pixel-wise: ý nói tính toán trên cấp độ pixel. Ví dụ gán nhãn là không phải gán nhãn trên từng vùng, mà là gán nhãn trên từng pixel
Giới thiệu bài toán
Trong quá khứ, các bào toán phân đoạn ngữ nghĩa (Semantic segmentation) tiếp cận dựa trên Convolution Neural Network (CNN) với bộ dữ liệu tiêu biểu là ImageNet, sau đó sử dụng Pretrained-model này để fine-tuning chúng với một lượng lỡn nhãn cấp độ pixels. Có thể thấy rõ một vài nhược điểm lớn đối với các cách tiếp cận này
- Thời gian để gãn nhãn là vô cũng tốn kém. Ví dụ thời gian trung bình để thực hiện gán nhãn 1 hình ảnh tỏng tập Cityscapes là 90 phút (gán nhãn mức độ pixel)
- Tập ImageNet chỉ phù hợp với nghiên cứu phi thương mại, không phù hợp với các bài toán thực. Việc thu taahjp một tập dữ liệu lớn như ImageNet với từng bài toán là rất tốn kém và mất thời gian
Các mô hình Semantic Segmentation điểm hình bao gồm 1 mạng CNN để trich xuất đặc trưng, sau đó là 1 trình phân loại pixel-wise softmax cùng với hàm loss pixel-wise cross-entropy. Khi thử nghiệm đào tạo mô hình với một lượng lớn ảnh được gãn nhãn cấp độ pixel, hiệu suất mô hình giảm khi số lượng ảnh có nhãn giảm. Điều này minh chứng cho việc CNN được training với cross-entropy loss có thể dễ dàng overfitting với một lượng nhỏ dữ liệu có nhãn, bởi hàm cross-entropy tập trung phân ranh giới giữa các lớp mà bỏ qua các mối quan hệ giữa các pixels.
Để khắc phục điều này, đã có một số bài báo đề xuất sử dụng các hàm loss phụ thuộc vào vùng (region-based loss), có thể kể tới như Region mutual information loss, Affinity field loss.
Tuy nhiên các hàm loss này chỉ mô hình hóa các mối quan hệ giữa các pixel trong 1 vùng lân cận cục bộ. Bởi vậy bài báo đã đề xuất ra hàm loss, tạm gọi là Contrastive loss. Hàm loss này có chức năng khuyến khích những pixels trong cùng 1 lớp thì giống nhau, pixel khác lớp thì khác nhau bất kể vị trí của chúng trên ảnh (Mục tiêu giống Contrastive learning nên gọi là contrastive loss).
Mô hình đề xuất
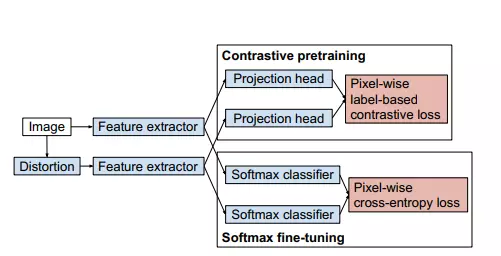
Ý tưởng chính được đề xuất bao gồm:
- Đào tạo trước mô hình trích xuất đặc trưng sử dụng Pixel-wise Label-based contrastive loss (contrastive pretraining)
- Fine-tune lại toàn bộ mạng bao gồm bộ phân loại pixel-wise softmax bằng cách sử dụng CE loss (softmax fine-tuning)
Cụ thể, các bước thực hiện bao gồm:
- Đào tạo mô hình CNN với mục tiêu trích xuất đặc trưng của ảnh đầu vào và ảnh biến dạng của ảnh đó (Distorition, phép biến dạng ở đây có thể là color jittering, …). Các thông số như các layer, các hyper parameters mình thấy trong paper đã nói rất kỹ, để triển khai các bạn có thể xem ở bài báo gốc trong phần 4.Experiments
- Sử dụng Projection head khi đào tạo mô hình, tức là các features được sử dụng trong hàm loss là kết quả đầu ra của Projection head chứ không phải của đầu ra của bộ phận trích xuất. Projection head ở đây bao gồm 3 lớp 1x1 convolution với 256 channels, sau đó là lớp unit-normalization, 2 layer đầu sử dụng ReLU activation
- Sau khi contrastive pretraining, đến công đoạn fine tuning thì thay thế các projection head bằng pixel-wise softmax calssfier và học lại mạng bằng pixel-wise CE loss
- Trong khi quá trinh constrastive pretraining khuyến khích các pixel trong hình ảnh phân cụm theo nhãn của chúng, thì trong Softmax fine-tuning sắp xếp lại các cụm này sao cho chúng nằm ở phía đúng của ranh giới quyết định. Các bạn có thể xem hình ảnh dưới để để thấy rõ sự khác nhau giữa việc sử dụng 2 hàm loss này

Các đóng góp chính
Pixel-wise label-based contrastive loss
Pixel-wise label-based contrastive loss: Extend 3 hàm loss chính:
- Within-image loss
- Cross-image loss
- Batch loss
Một vài chú thích quan trọng
- là ảnh, là phiên bản distorted (biến dạng) của
- : class label của pixel trong ảnh
- : số pixels trong ảnh mà có class label là
- : tổng số pixel trong ảnh
- : unit-normalized feature được trichs xuất từ ảnh tại pixel
- với là temperature parameter.
Within-image loss: mục tiêu là encourages các features của ảnh được phân loại vào từng nhóm theo nhãn tương ứng (Tính toán trong 1 ảnh)
Cross-image loss: exted within-images loss nhờ vào việc sử dụng thêm các positives từ ảnh khác (J). Positive pixels từ ảnh J có thể được coi là harder positives hơn vì chúng đến từ 1 ảnh khác. Không lấy negative từ ảnh khác (qua thử nghiệm thì thấy hiệu suất sụt giảm nếu lấy cả negative)
- Batch loss: Phần này tác giá có thử nghiệm tính toán xử lý tất cả các pixel trong 1 minibatch như 1 “túi” pixel duy nhất để tính toán mất mát, mong đợi kết quả tốt hơn 2 hàm loss trên tuy nhiên kết quả ngược lại
Đề xuất chiến lược đào tạo
- Đầu tiên đạo tạo khối trích xuất đặc trưng sâu với kiến trúc CNN với hàm contrastive loss đề xuất, tất nhiên đầu ra của khối CNN trích xuất sẽ trải qua Projection head rồi mới đưa vào hàm loss
- Sau khi đã đạo tào xong, loại bỏ Projection head đó, thay thế Projecttion head khác (2 khối 2 Project head khác nhau vì 2 mục đích khác nhau), thay thế hàm contrastive loss đề xuất bằng CE loss
- Chú ý rằng có 2 hàm loss được đề xuất: Within-image loss và Cross-image loss. Với Within-image loss, không có sự tương tác giữa các pixel nằm ở ác hình ảnh khác nhau.
- Trong khi quá trinh constrastive pretraining khuyến khích các pixel trong hình ảnh phân cụm theo nhãn của chúng, thì trong Softmax fine-tuning sắp xếp lại các cụm này sao cho chúng nằm ở phía đúng của ranh giới quyết định.
Dataset và Metrics đánh giá
- Dataset sử dụng: Cityscapes (19 classes), PASCAL VOC 2012 (21 classes)
- Metrics được sử dụng: MeanIOU
Kết quả thử nghiệm
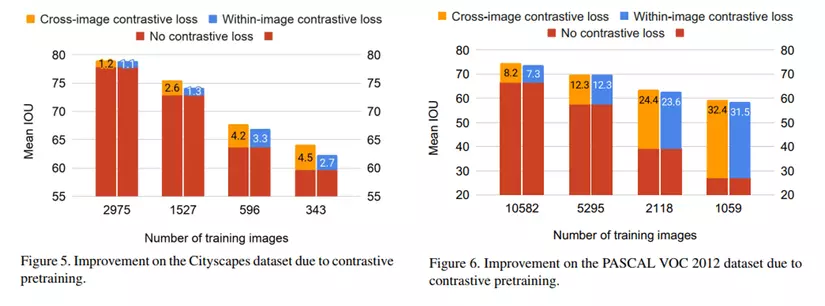
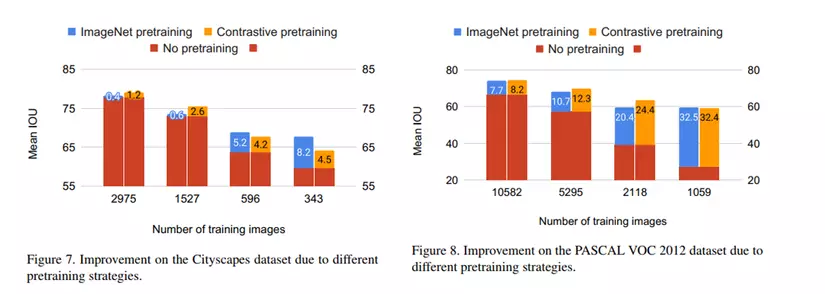
Với việc sử dụng kiểu biểu đồ này, có thể thấy được hiệu quả của việc sử dụng 2 hàm loss đề xuất so với chỉ sử dụng CE loss (HÌnh 5 & 6), cũng như hiệu quả của việc sử dụng Pretraining (hình 7 & 8)
Lời kết
Như vậy, song song với việc nghiên cứu paper này để tìm ra một hướng cải tiến cho bài toán mà mình quan tâm, mình đã cố gắng diễn đạt ý hiểu của mình về paper này cho mọi người cùng tham khảo. Có thể nói bài toán Semantic Segmentation là một bài toán có tính ứng dụng vô cùng cao, có rất nhiều các phương pháp, liên quan đến học liên tiếp, học giám sát, bán giám sát, ….
Hiện tại bài báo này cũng chưa public source code nên trước mắt, mình chỉ chia sẻ về ý tưởng đề xuất của bài báo. Cảm ơn mọi người đã đọc đến những dòng này!