1. Produce Requests
Như ở bài viết này mình đã có đề cập đến tham số cấu hình acks xác định số lượng broker cần phải xác nhận việc đã nhận message trước khi message đó được coi là ghi thành công. Các producer có thể được cấu hình để coi như message là “ghi thành công” khi message được chấp nhận bởi chỉ leader (acks=1), hoặc bởi tất cả các in-sync replicas (acks=all), hoặc ngay khi message được gửi mà không cần chờ broker xác nhận (acks=0).
Khi broker chứa leader replica của một partition nhận được produce request cho partition này, nó sẽ bắt đầu bằng việc thực hiện một số validations:
Người dùng gửi dữ liệu được quyền ghi trên topic không? Cấu hình acks được chỉ định trong yêu cầu có hợp lệ không (chỉ cho phép 0, 1 và “all”)? Nếu acks được đặt thành “all”, có đủ các in-sync replicas để ghi message một cách an toàn không? (Các broker có thể được cấu hình để từ chối message mới nếu số lượng in-sync replicas giảm xuống dưới một giá trị đã cấu hình)
Sau đó, broker sẽ ghi các message mới vào local disk. Trên hệ điều hành Linux, các mesage được ghi vào filesystem cache, và không có đảm bảo về thời điểm chúng được ghi vào đĩa. Kafka không chờ đợi dữ liệu được ghi vào đĩa—nó dựa vào việc sao chép để đảm bảo độ bền vững của message.
Khi message đã được ghi vào leader của partition, broker sẽ kiểm tra cấu hình acks: nếu acks được đặt là 0 hoặc 1, broker sẽ phản hồi ngay lập tức; nếu acks được đặt thành “all”, yêu cầu sẽ được lưu trong một bộ đệm gọi là purgatory cho đến khi leader quan sát thấy các replica follower đã sao chép message, lúc đó phản hồi sẽ được gửi đến client.
2. Fetch Requests
Các broker xử lý các fetch request theo cách rất giống với cách xử lý các produce request. Client gửi yêu cầu, yêu cầu broker gửi các message từ danh sách các topic, partition và offset—hình dung như là “Vui lòng gửi cho tôi các message bắt đầu từ offset 53 trong partition 0 của topic NamDepTrai và các message bắt đầu từ offset 64 trong partition 3 của topic NamDepTrai.” Các client cũng chỉ định, cấu hình giới hạn cho lượng dữ liệu mà broker có thể trả về cho mỗi partition. Giới hạn này quan trọng vì các client cần cấp phát bộ nhớ để chứa phản hồi từ broker. Nếu không có giới hạn này, broker có thể gửi lại các phản hồi lớn đến mức khiến client hết bộ nhớ.
Như chúng ta đã thảo luận trước đó, các yêu cầu phải đến tay các leader của các partition được chỉ định trong yêu cầu, và client sẽ thực hiện các yêu cầu metadata cần thiết để đảm bảo rằng nó đang định tuyến các yêu cầu fetch một cách chính xác. Khi leader nhận được yêu cầu, nó sẽ kiểm tra trước xem yêu cầu có hợp lệ không—offset này có tồn tại cho partition cụ thể này không? Nếu client yêu cầu một message quá cũ đến mức đã bị xóa khỏi partition hoặc một offset chưa tồn tại, broker sẽ phản hồi với lỗi.
Nếu offset tồn tại, broker sẽ đọc các message từ partition cho đến khi đạt giới hạn được cấu hình bởi client trong yêu cầu, và gửi các message đó đến client. Kafka nổi tiếng với việc sử dụng phương pháp zero-copy để gửi message đến các client—điều này có nghĩa là Kafka gửi message từ tệp (hoặc chính xác hơn là từ filesystem cache của Linux) trực tiếp đến network channel mà không cần qua bất kỳ bộ đệm trung gian nào. Điều này khác với hầu hết các cơ sở dữ liệu, nơi dữ liệu được lưu trữ trong bộ nhớ local cache trước khi được gửi đến client. Kỹ thuật này loại bỏ chi phí sao chép byte và quản lý bộ đệm trong bộ nhớ, và mang lại hiệu suất được cải thiện đáng kể.
Ngoài việc đặt giới hạn tối đa về lượng dữ liệu mà broker có thể trả về, client cũng có thể đặt giới hạn tối thiểu về lượng dữ liệu được trả về. Ví dụ, việc đặt giới hạn tối thiểu là 10K là cách mà client yêu cầu broker, "Chỉ trả về kết quả khi có ít nhất 10K byte để gửi cho tôi." Đây là cách tuyệt vời để giảm sử dụng CPU và băng thông mạng khi các client đang đọc từ các topic ít lưu lượng truy cập. Thay vì việc vài mili giây các client gửi yêu cầu đến broker để yêu cầu dữ liệu và nhận được rất ít hoặc không có message nào, các client gửi một yêu cầu, broker chờ đến khi có một lượng dữ liệu đủ lớn, rồi trả dữ liệu đó, và chỉ khi đó client mới yêu cầu thêm (Xem Hình 1). Tổng lượng dữ liệu đọc được là như nhau nhưng với ít lần trao đổi qua lại hơn và do đó giảm thiểu chi phí. Hình 1. Broker trì hoãn phản hồi cho đến khi đủ dữ liệu được tích lũy
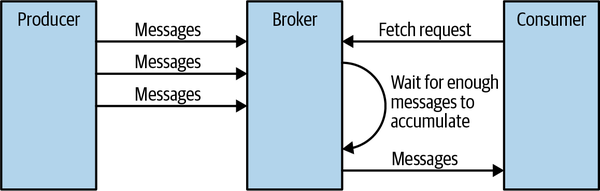
Tất nhiên, chúng ta không muốn các client phải chờ đợi mãi đến khi broker có đủ dữ liệu. Sau một thời gian, việc chỉ lấy dữ liệu hiện có và xử lý nó thay vì chờ đợi thêm dữ liệu là hợp lý. Do đó, các client cũng có thể định nghĩa một thời gian chờ để yêu cầu broker, "Nếu bạn không thu thập được đủ lượng dữ liệu cần gửi trong vòng x mili giây, hãy gửi những gì bạn đã có."
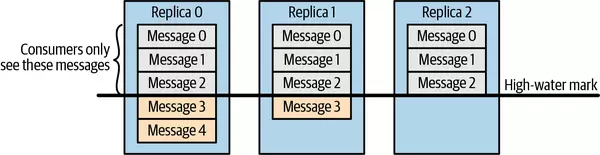
Điều đáng lưu ý là không phải toàn bộ dữ liệu tồn tại trên leader của partition đều có sẵn để các client đọc. Hầu hết các client chỉ có thể đọc các message đã được ghi vào tất cả các in-sync replicas (các replica follower, mặc dù chúng là các consumer, thì không bị ràng buộc điều này—nếu không, việc sao chép dữ liệu sẽ không hoạt động). Chúng ta đã thảo luận rằng leader của partition biết các message nào đã được sao chép đến các replica nào, và cho đến khi một message được ghi vào tất cả các in-sync replicas, nó sẽ không được gửi đến các consumer—việc cố gắng để lấy những message đó sẽ dẫn đến phản hồi rỗng thay vì lỗi.
Lý do cho hành vi này là vì các message chưa được sao chép đến đủ số lượng replica được coi là "không an toàn"—nếu leader bị lỗi và một replica khác thay thế vị trí của nó, các message này sẽ không còn tồn tại trong Kafka. Nếu chúng ta cho phép các client đọc các message chỉ tồn tại trên leader, có thể xảy ra tình trạng không đồng nhất. Ví dụ, nếu một consumer đọc một tin nhắn và sau đó leader bị lỗi và không có broker nào khác chứa message này, message đó sẽ biến mất. Không có consumer nào khác có thể đọc được message này, điều này có thể gây ra sự không nhất quán với consumer đã đọc nó. Thay vào đó, chúng ta chờ cho đến khi tất cả các in-sync replicas nhận được message và chỉ sau đó mới cho phép các consumer đọc message đó, xem hình 2. Hành vi này cũng có nghĩa là nếu việc sao chép giữa các broker chậm vì lý do nào đó, sẽ mất thêm thời gian để các message mới đến tay các consumer (vì chúng ta đang phải chờ message sao chép trước). Sự trì hoãn này được giới hạn bởi tham số replica.lag.time.max.ms—thời gian tối đa mà một replica có thể bị trì hoãn trong việc sao chép các message mới mà vẫn được coi là đồng bộ. Hình 2. Các consumer chỉ thấy các message đã được sao chép thành công đến các in-sync replicas
Trong một số trường hợp, một consumer tiêu thụ message từ một số lượng lớn các partition. Việc gửi danh sách tất cả các phân vùng mà nó quan tâm đến broker với mỗi yêu cầu và yêu cầu broker gửi lại tất cả metadata có thể rất kém hiệu quả—danh sách các partition hiếm khi thay đổi nên metadata của chúng cũng hiếm khi thay đổi, và trong nhiều trường hợp, không có nhiều dữ liệu để trả về. Để giảm thiểu overhead này, Kafka sử dụng fetch session cache. Các consumer có thể cố gắng tạo một session lưu trữ danh sách các partition mà chúng đang tiêu thụ và metadata của chúng. Khi một session được tạo ra, các consumer không cần phải chỉ định tất cả các partition trong mỗi yêu cầu và có thể sử dụng các Incremental fetch requests thay vào đó. Các broker chỉ bao gồm metadata trong phản hồi nếu có bất kỳ thay đổi nào. Session cache có dung lượng hạn chế, và Kafka ưu tiên các replica follower và các consumer với một tập hợp các partition lớn, vì vậy trong một số trường hợp, một session sẽ không được tạo ra hoặc sẽ bị loại bỏ. Trong cả hai trường hợp này, broker sẽ trả về lỗi phù hợp cho client, và consumer sẽ tự động chuyển sang các yêu cầu fetch đầy đủ bao gồm tất cả metadata paritition.
Incremental fetch requests là các yêu cầu lấy dữ liệu từ Kafka mà chỉ yêu cầu các dữ liệu mới hoặc thay đổi kể từ lần yêu cầu trước đó, thay vì yêu cầu toàn bộ dữ liệu từ đầu. Đây là cách để giảm bớt khối lượng dữ liệu cần truyền tải và tối ưu hóa hiệu suất khi lấy dữ liệu từ nhiều partition.
3. Other Requests
Chúng ta vừa thảo luận về các loại yêu cầu phổ biến nhất được các Kafka Client sử dụng: Metadata, Produce và Fetch. Hiện tại, Kafka Protocol xử lý 61 loại yêu cầu khác nhau, và còn nhiều loại khác sẽ được thêm vào. Chỉ riêng các consumer đã sử dụng 15 loại yêu cầu để tạo groups, coordinate consumption và cho phép các nhà phát triển quản lý các consumer group. Cũng có rất nhiều yêu cầu liên quan đến quản lý metadata và bảo mật.
Ngoài ra, cùng một giao thức được sử dụng để giao tiếp giữa các broker Kafka với nhau. Những yêu cầu này là nội bộ và không nên được sử dụng bởi các client. Ví dụ, khi controller thông báo rằng một partition có một leader mới, nó gửi yêu cầu LeaderAndIsr tới leader mới (để nó biết bắt đầu nhận yêu cầu từ client) và tới các follower (để chúng biết theo dõi leader mới).
Giao thức luôn được cập nhật—khi cộng đồng Kafka thêm các khả năng mới cho client, giao thức cũng phát triển theo. Ví dụ, trước đây, các consumer Kafka sử dụng Apache ZooKeeper để theo dõi các offset mà chúng nhận được từ Kafka. Khi một consumer được khởi động, nó có thể kiểm tra ZooKeeper để lấy offset cuối cùng đã đọc từ các partition và biết bắt đầu xử lý từ đâu. Tuy nhiên, vì nhiều lý do, cộng đồng đã quyết định ngừng sử dụng ZooKeeper và lưu trữ các offset trong một topic Kafka đặc biệt. Để thực hiện điều này, các contributors đã phải thêm một số yêu cầu vào giao thức: OffsetCommitRequest, OffsetFetchRequest, và ListOffsetsRequest. Giờ đây, khi một ứng dụng gọi API của client để commit các consumer offset, client không còn ghi vào ZooKeeper nữa mà thay vào đó gửi OffsetCommitRequest đến Kafka.
Việc tạo topic trước đây được thực hiện qua các công cụ dòng lệnh, trực tiếp cập nhật danh sách các topic trong ZooKeeper. Cộng đồng Kafka sau đó đã thêm CreateTopicRequest và các yêu cầu tương tự để quản lý metadata của Kafka. Các ứng dụng Java thực hiện các thao tác metadata này thông qua AdminClient của Kafka. Vì những thao tác này giờ đây đã trở thành một phần của giao thức Kafka, điều này cho phép các client sử dụng các ngôn ngữ không có thư viện ZooKeeper có thể tạo topic bằng cách yêu cầu trực tiếp các Kafka brokers.