Resilient Distributed Datasets (RDDs) là một cấu trúc dữ liệu cơ bản và quan trọng trong Apache Spark, cho phép xử lý dữ liệu phân tán trên các cụm máy tính một cách linh hoạt và hiệu quả. Đây là một phần chính của nền tảng Apache Spark, giúp đơn giản hóa việc xử lý dữ liệu lớn bằng cách tự động xử lý phân tán và chịu sự cố.
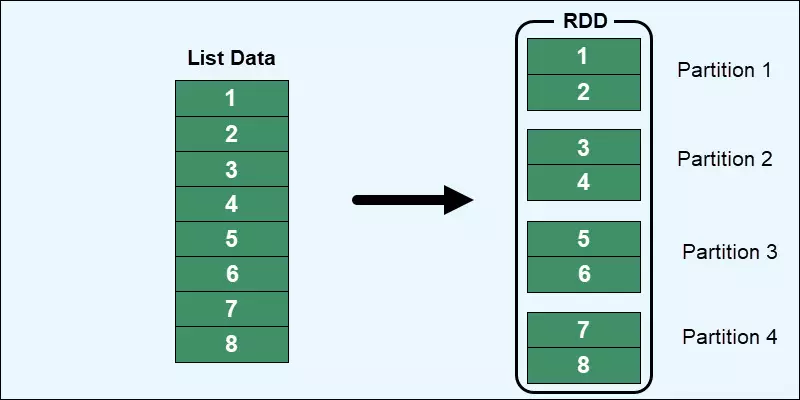
Dưới đây là một số điểm quan trọng cần hiểu về RDDs:
1. Phân tán (Distributed):
RDDs được phân tán trên các nút trong cụm tính toán của Apache Spark. Mỗi RDD được chia thành các phần nhỏ gọi là partitions, mỗi partition có thể được xử lý độc lập trên các nút khác nhau trong cụm. Điều này cho phép Spark tận dụng được sức mạnh tính toán của nhiều máy tính để xử lý dữ liệu một cách song song.
2. Linh hoạt (Resilient):
RDDs có khả năng chịu sự cố tức là nó có thể tự động phục hồi sau khi một phần của dữ liệu hoặc một phần của cụm bị lỗi. Khi một phần của RDDs bị mất do lỗi phần cứng hoặc phần mềm, Spark có thể tái tính toán các partition bị mất từ các dữ liệu gốc và các phần khác của RDD.
3. Khả năng tối ưu hóa (Optimized):
RDDs có thể tối ưu hóa để tận dụng các hoạt động in-memory, giảm thiểu việc truy cập dữ liệu từ đĩa và tối ưu hóa việc chuyển dữ liệu giữa các phần của RDD trên cụm. Điều này giúp tăng tốc độ xử lý dữ liệu của Apache Spark.
4. Khả năng xử lý nhiều loại dữ liệu:
RDDs không giới hạn trong việc xử lý dữ liệu từ nhiều nguồn khác nhau. Chúng có thể xử lý dữ liệu có cấu trúc, bán cấu trúc và không cấu trúc từ các nguồn như hệ thống tệp, cơ sở dữ liệu, hoặc dữ liệu được tạo ra bởi các ứng dụng khác.
5. API linh hoạt:
Apache Spark cung cấp các API cho nhiều ngôn ngữ lập trình như Scala, Java, Python và R để làm việc với RDDs. Điều này giúp cho các nhà phát triển có thể sử dụng RDDs dễ dàng trong môi trường phát triển mà họ thoải mái nhất.
Trong tổng thể, RDDs là một phần quan trọng của Apache Spark, cho phép bạn làm việc với dữ liệu lớn một cách linh hoạt và hiệu quả. Điều này làm cho Spark trở thành một công cụ mạnh mẽ trong việc xử lý dữ liệu lớn và phân tích dữ liệu trong lĩnh vực Big Data.