Mở đầu:
Trong kỷ nguyên số hiện nay, trí tuệ nhân tạo (AI) đang ngày càng phát triển mạnh mẽ, mang đến những đột phá đáng kinh ngạc trong nhiều lĩnh vực. Từ xe tự lái đến trợ lý ảo, AI đang thay đổi cách chúng ta sống và làm việc. Tuy nhiên, để AI có thể hoạt động hiệu quả, nó cần được huấn luyện trên một lượng lớn dữ liệu chất lượng cao.
Thách thức đặt ra là làm sao để thu thập và xử lý dữ liệu một cách hiệu quả, đặc biệt trong bối cảnh dữ liệu ngày càng phức tạp và đa dạng. Các phương pháp thu thập và xử lý dữ liệu truyền thống thường gặp phải những hạn chế như:
- Dựa trên quy tắc: Các công cụ thu thập dữ liệu truyền thống thường dựa trên các quy tắc cố định, dễ bị lỗi khi cấu trúc trang web thay đổi.
- Yêu cầu can thiệp của con người: Quá trình thu thập và xử lý dữ liệu thường đòi hỏi sự can thiệp của con người, tốn thời gian và công sức.
- Khó khăn trong việc xử lý dữ liệu phức tạp: Các công cụ truyền thống gặp khó khăn trong việc xử lý dữ liệu có cấu trúc phức tạp, chẳng hạn như dữ liệu từ các trang web động hoặc dữ liệu đa phương tiện.
Để giải quyết những thách thức này, Scrapegraph-ai ra đời như một giải pháp đột phá, tận dụng sức mạnh của các Mô hình Ngôn ngữ Lớn (LLMs) để tự động hóa việc thu thập và xử lý dữ liệu. Scrapegraph-ai không chỉ giúp thu thập dữ liệu một cách hiệu quả mà còn có khả năng xử lý dữ liệu phức tạp, tạo ra các câu trả lời có cấu trúc và dễ dàng sử dụng cho các hệ thống AI.
Hãy cùng khám phá những ưu điểm vượt trội của Scrapegraph-ai và cách nó có thể giúp bạn giải quyết bài toán thu thập và xử lý dữ liệu cho các hệ thống AI của mình.
Phần 1: Giới thiệu Scrapegraph-ai
Định nghĩa:
Scrapegraph-ai là một thư viện Python mã nguồn mở, được thiết kế để cách mạng hóa các công cụ thu thập dữ liệu. Nó kết hợp sức mạnh của các Mô hình Ngôn ngữ Lớn (LLMs) và các pipeline dựa trên đồ thị để tự động hóa việc thu thập và xử lý dữ liệu từ nhiều nguồn khác nhau, bao gồm trang web, tệp cục bộ, tài liệu PDF, v.v.
Ưu điểm:
Scrapegraph-ai mang đến nhiều ưu điểm vượt trội so với các công cụ thu thập dữ liệu truyền thống:
- Linh hoạt: Scrapegraph-ai sử dụng LLM để thích nghi với các thay đổi trong cấu trúc trang web, giảm thiểu nhu cầu can thiệp của nhà phát triển. Thay vì dựa trên các quy tắc cố định, Scrapegraph-ai có thể hiểu và phân tích nội dung trang web một cách linh hoạt, giúp nó hoạt động hiệu quả ngay cả khi cấu trúc trang web thay đổi.
- Dễ bảo trì: Scrapegraph-ai tự động hóa quá trình thu thập dữ liệu, giúp giảm thiểu công sức bảo trì. Bạn không cần phải liên tục cập nhật các quy tắc hoặc cấu hình khi trang web thay đổi, Scrapegraph-ai sẽ tự động thích nghi và thu thập dữ liệu chính xác.
- Hỗ trợ nhiều LLM: Thư viện hỗ trợ nhiều LLM, bao gồm GPT, Gemini, Groq, Azure, Hugging Face và các mô hình cục bộ có thể chạy trên máy của bạn bằng Ollama. Điều này cho phép bạn lựa chọn mô hình phù hợp nhất với nhu cầu của mình và tận dụng sức mạnh của các LLM tiên tiến nhất.
- Xử lý dữ liệu phức tạp: Scrapegraph-ai có khả năng xử lý dữ liệu có cấu trúc phức tạp, bao gồm dữ liệu từ các trang web động, dữ liệu đa phương tiện, v.v. Nó có thể trích xuất thông tin từ các phần tử HTML phức tạp, phân tích dữ liệu hình ảnh và âm thanh, giúp bạn thu thập được dữ liệu đa dạng và phong phú hơn.
- Tạo câu trả lời có cấu trúc: Scrapegraph-ai có thể tạo ra các câu trả lời có cấu trúc, dễ dàng sử dụng cho các hệ thống AI. Thay vì chỉ thu thập dữ liệu thô, Scrapegraph-ai có thể phân tích dữ liệu và tạo ra các câu trả lời có ý nghĩa, giúp bạn tiết kiệm thời gian và công sức trong việc xử lý dữ liệu.
So sánh với các công cụ thu thập dữ liệu truyền thống:
Các công cụ thu thập dữ liệu truyền thống thường dựa trên các quy tắc cố định, dễ bị lỗi khi cấu trúc trang web thay đổi. Chúng cũng đòi hỏi sự can thiệp của con người để cập nhật các quy tắc và cấu hình, tốn thời gian và công sức.
Scrapegraph-ai vượt trội hơn các công cụ truyền thống nhờ vào khả năng thích nghi với các thay đổi trong cấu trúc trang web, tự động hóa quá trình thu thập dữ liệu và hỗ trợ nhiều LLM. Nó giúp bạn thu thập dữ liệu một cách hiệu quả, chính xác và dễ dàng sử dụng cho các hệ thống AI.
Cách thức hoạt động:
Scrapegraph-ai hoạt động dựa trên các pipeline trên đồ thị (graph-based pipelines). Mỗi pipeline bao gồm một chuỗi các nút (nodes), mỗi nút thực hiện một chức năng cụ thể trong quá trình thu thập và xử lý dữ liệu.
Sơ đồ minh họa kiến trúc cấp cao của ScrapeGraphAI:
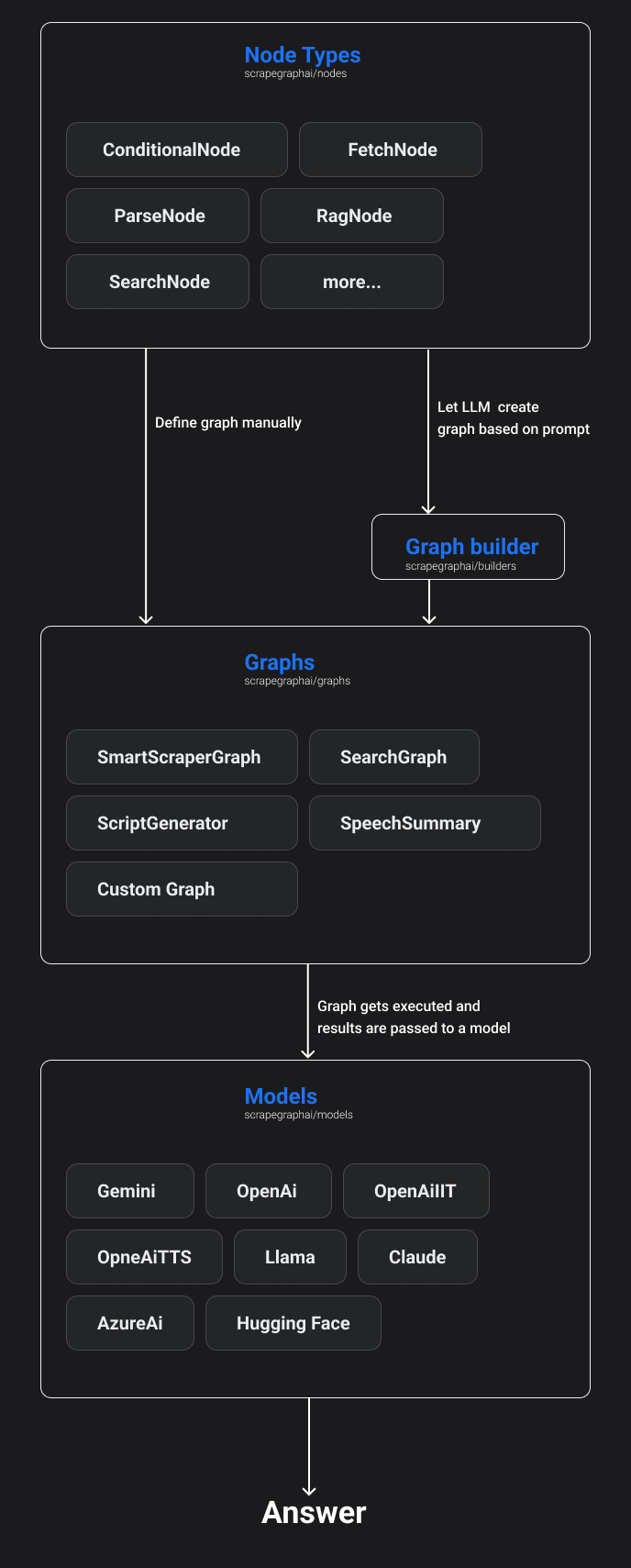
nguồn: scrapegraph-ai.readthedocs.io
Giải thích kiến trúc:
- Nút đồ thị (Nodes): Scrapegraph-ai cung cấp nhiều loại nút đồ thị, mỗi loại thực hiện một chức năng cụ thể:
- FetchNode: Thu thập dữ liệu từ nguồn được chỉ định (ví dụ: trang web, tệp cục bộ).
- ParseNode: Phân tích cú pháp dữ liệu thu thập được (ví dụ: phân tích HTML, XML, JSON).
- RagNode: Sử dụng LLM để trích xuất thông tin từ dữ liệu đã được phân tích cú pháp.
- ConditionalNode: Kiểm tra điều kiện và quyết định luồng dữ liệu tiếp theo.
- SearchNode: Tìm kiếm thông tin trên các công cụ tìm kiếm.
- Và nhiều loại nút khác...
- Xây dựng đồ thị (Graph builder): Scrapegraph-ai cung cấp hai cách để xây dựng đồ thị:
- Định nghĩa đồ thị thủ công: Bạn có thể tự định nghĩa các nút và kết nối chúng theo yêu cầu của mình.
- Tạo đồ thị dựa trên lời nhắc (Prompt-based graph creation): Bạn có thể cung cấp một lời nhắc cho LLM, và LLM sẽ tự động tạo ra đồ thị phù hợp với yêu cầu của bạn.
- Thực thi đồ thị (Graph execution): Sau khi đồ thị được xây dựng, Scrapegraph-ai sẽ thực thi các nút theo thứ tự đã định. Kết quả của mỗi nút sẽ được truyền cho nút tiếp theo trong pipeline.
- Mô hình (Models): Scrapegraph-ai hỗ trợ nhiều LLM, bao gồm GPT, Gemini, Groq, Azure, Hugging Face và các mô hình cục bộ có thể chạy trên máy của bạn bằng Ollama. Bạn có thể lựa chọn mô hình phù hợp nhất với nhu cầu của mình.
- Câu trả lời (Answer): Kết quả cuối cùng của quá trình thu thập và xử lý dữ liệu sẽ được trả về dưới dạng câu trả lời có cấu trúc, dễ dàng sử dụng cho các hệ thống AI.
Ví dụ:
Giả sử bạn muốn thu thập thông tin về các sản phẩm điện thoại thông minh từ một trang web thương mại điện tử. Bạn có thể sử dụng Scrapegraph-ai để xây dựng một pipeline bao gồm các nút sau:
- FetchNode: Thu thập HTML của trang web.
- ParseNode: Phân tích cú pháp HTML để trích xuất thông tin về các sản phẩm (ví dụ: tên sản phẩm, giá, hình ảnh).
- RagNode: Sử dụng LLM để trích xuất thông tin bổ sung về các sản phẩm (ví dụ: đánh giá, thông số kỹ thuật).
- ConditionalNode: Kiểm tra xem thông tin đã đầy đủ chưa. Nếu chưa, nó sẽ chuyển dữ liệu đến nút SearchNode để tìm kiếm thêm thông tin.
- SearchNode: Tìm kiếm thông tin bổ sung trên các công cụ tìm kiếm.
- RagNode: Sử dụng LLM để xử lý thông tin tìm kiếm được và tạo ra câu trả lời có cấu trúc.
Kết quả cuối cùng sẽ là một danh sách các sản phẩm điện thoại thông minh, bao gồm thông tin đầy đủ về mỗi sản phẩm, được định dạng theo cấu trúc dữ liệu dễ dàng sử dụng cho các hệ thống AI.
Phần 2: Tổng quan về đồ thị (graph) và các loại đồ thị hiện có
Định nghĩa:
Trong Scrapegraph-ai, đồ thị (graph) là một cấu trúc dữ liệu mô tả luồng xử lý dữ liệu. Mỗi đồ thị bao gồm một tập hợp các nút (nodes) được kết nối với nhau theo một thứ tự nhất định. Mỗi nút thực hiện một chức năng cụ thể trong quá trình thu thập và xử lý dữ liệu.
Các loại đồ thị:
Scrapegraph-ai cung cấp nhiều loại đồ thị, mỗi loại được thiết kế để giải quyết một bài toán cụ thể:
1. SmartScraperGraph:
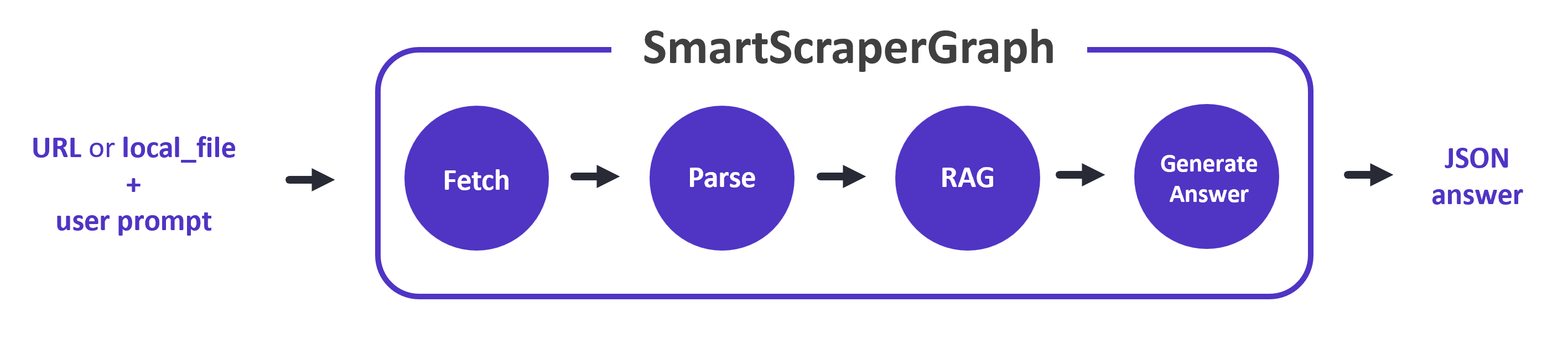 nguồn: scrapegraph-ai.readthedocs.io
nguồn: scrapegraph-ai.readthedocs.io
- Chức năng: Thu thập dữ liệu từ một trang web/local_file dựa trên một lời nhắc của người dùng.
- Cách thức hoạt động:
- Nhận một lời nhắc từ người dùng (ví dụ: "Cho tôi biết thông tin về himmeow the coder.").
- Thu thập dữ liệu từ trang web/local_file được chỉ định.
- Sử dụng LLM để phân tích dữ liệu và trích xuất thông tin phù hợp với lời nhắc.
- Trả về kết quả dưới dạng câu trả lời có cấu trúc.
2. SearchGraph:
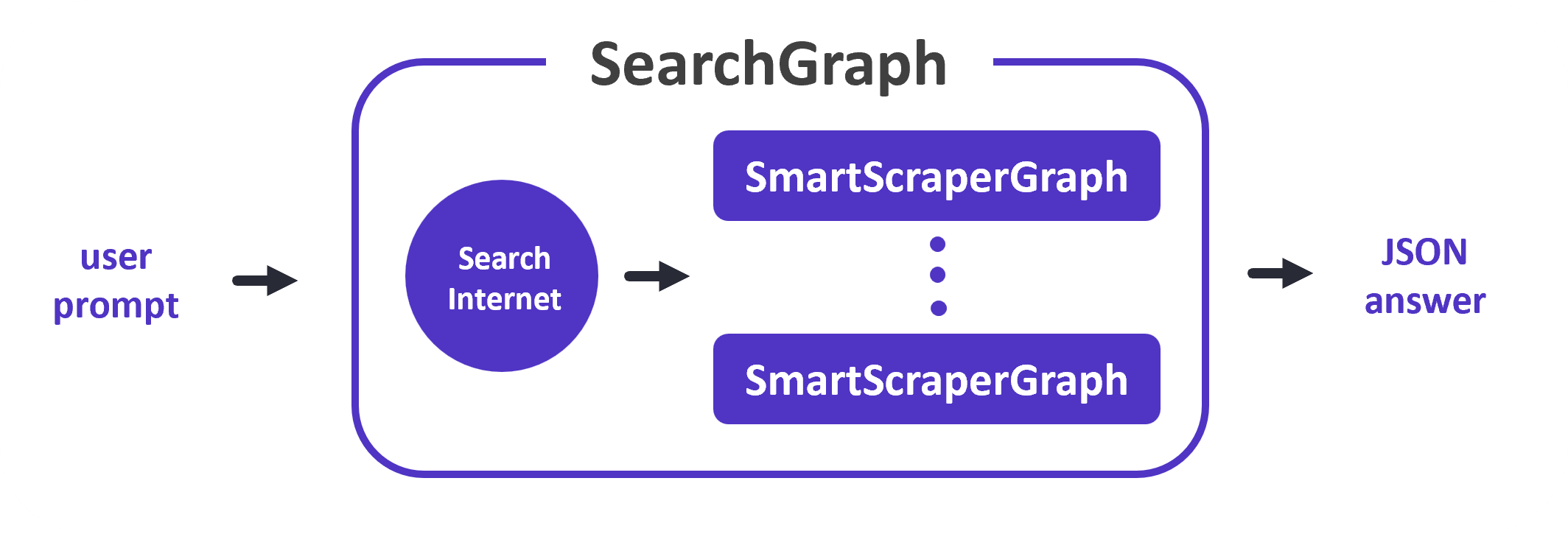 nguồn: scrapegraph-ai.readthedocs.io
nguồn: scrapegraph-ai.readthedocs.io
- Chức năng: Thu thập dữ liệu từ nhiều trang web dựa trên một lời nhắc của người dùng.
- Cách thức hoạt động:
- Nhận một lời nhắc từ người dùng (ví dụ: "Tìm kiếm thông tin về Sun* Inc.").
- Tạo truy vấn tìm kiếm trên các công cụ tìm kiếm.
- Thu thập dữ liệu từ các trang web được tìm kiếm.
- Sử dụng LLM để phân tích dữ liệu và trích xuất thông tin phù hợp với lời nhắc.
- Trả về kết quả dưới dạng câu trả lời có cấu trúc.
3. SpeechGraph:
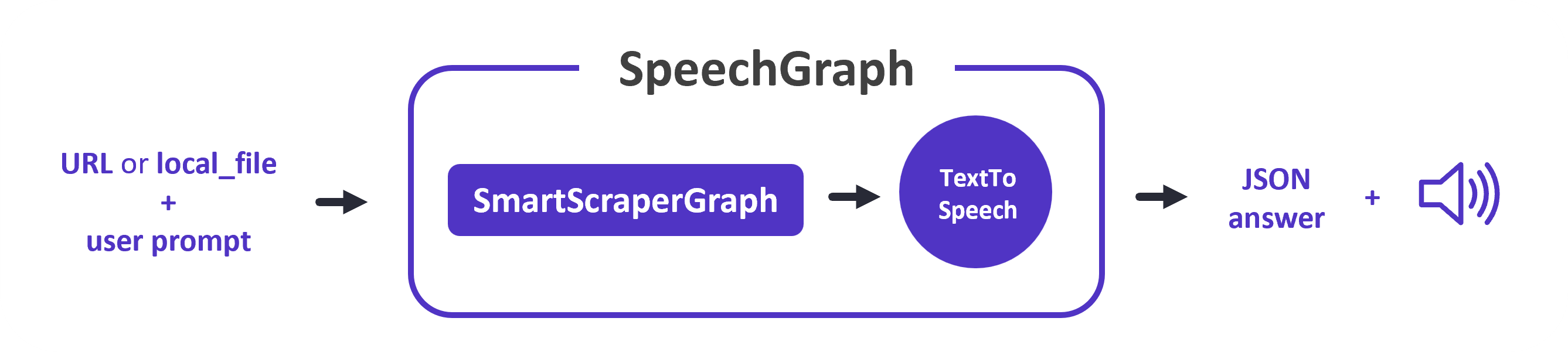 nguồn: scrapegraph-ai.readthedocs.io
nguồn: scrapegraph-ai.readthedocs.io
- Chức năng: Tạo tệp âm thanh từ văn bản thu thập được.
- Cách thức hoạt động:
- Nhận một lời nhắc từ người dùng (ví dụ: "Đọc nội dung bài viết này").
- Thu thập dữ liệu từ trang web hoặc tệp được chỉ định.
- Sử dụng LLM để phân tích dữ liệu và trích xuất thông tin phù hợp với lời nhắc.
- Sử dụng công cụ chuyển văn bản thành giọng nói (Text-to-Speech) để tạo ra tệp âm thanh.
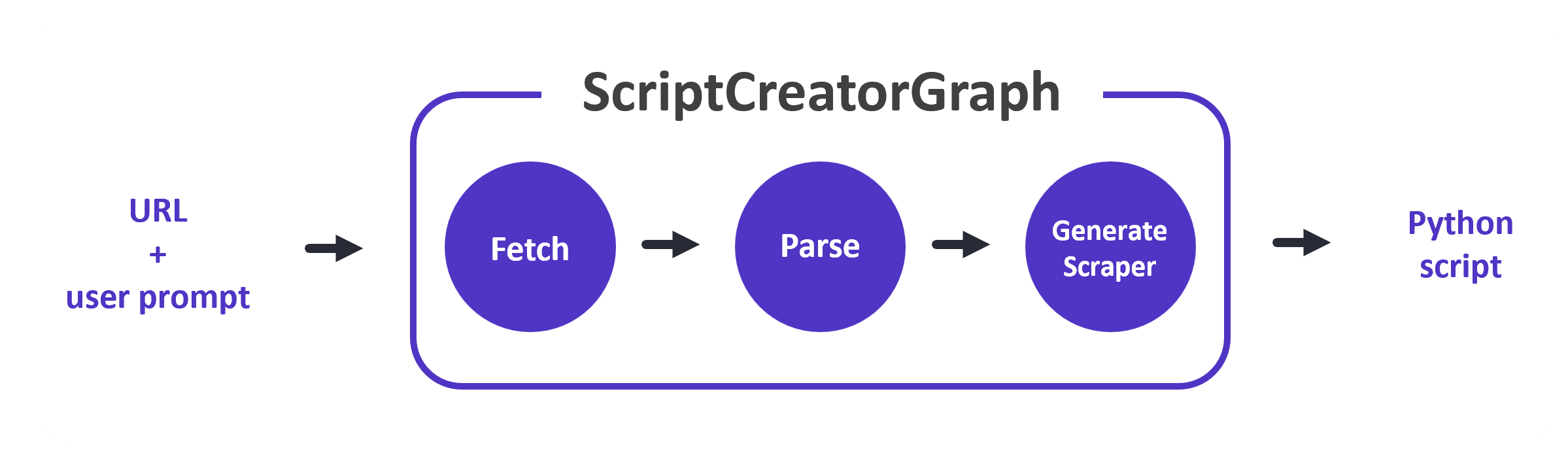
4. ScriptCreatorGraph:
 nguồn: scrapegraph-ai.readthedocs.io
nguồn: scrapegraph-ai.readthedocs.io
- Chức năng: Tạo mã Python để thu thập dữ liệu.
- Cách thức hoạt động:
- Nhận một lời nhắc từ người dùng (ví dụ: "Tạo mã Python để thu thập thông tin về các sản phẩm trên trang web này").
- Thu thập dữ liệu từ trang web được chỉ định.
- Sử dụng LLM để phân tích dữ liệu và tạo ra mã Python phù hợp với yêu cầu của người dùng.
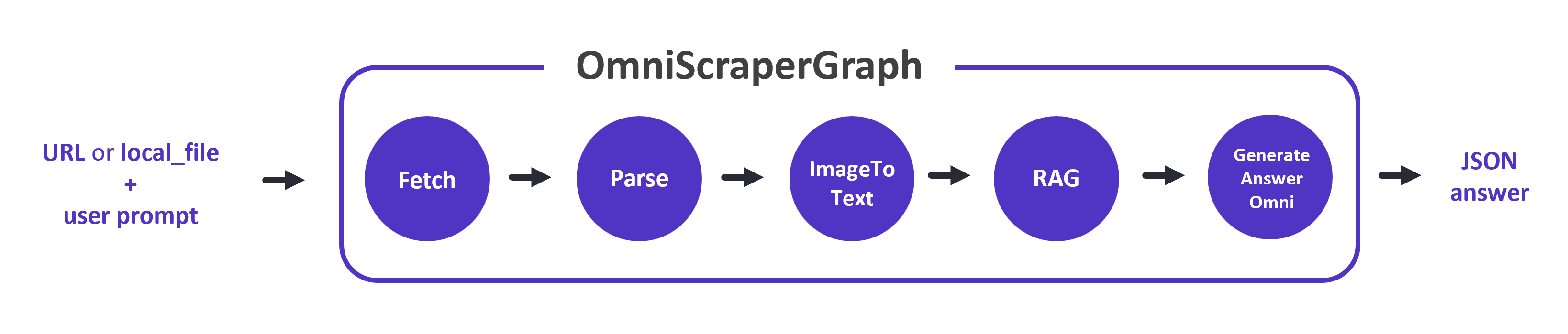
5. OmniScraperGraph:
 nguồn: scrapegraph-ai.readthedocs.io
nguồn: scrapegraph-ai.readthedocs.io
- Chức năng: Thu thập dữ liệu từ hình ảnh và mô tả chúng.
- Cách thức hoạt động:
- Nhận một lời nhắc từ người dùng (ví dụ: "Mô tả hình ảnh này").
- Thu thập dữ liệu từ hình ảnh được chỉ định.
- Sử dụng LLM để phân tích hình ảnh và tạo ra mô tả văn bản.
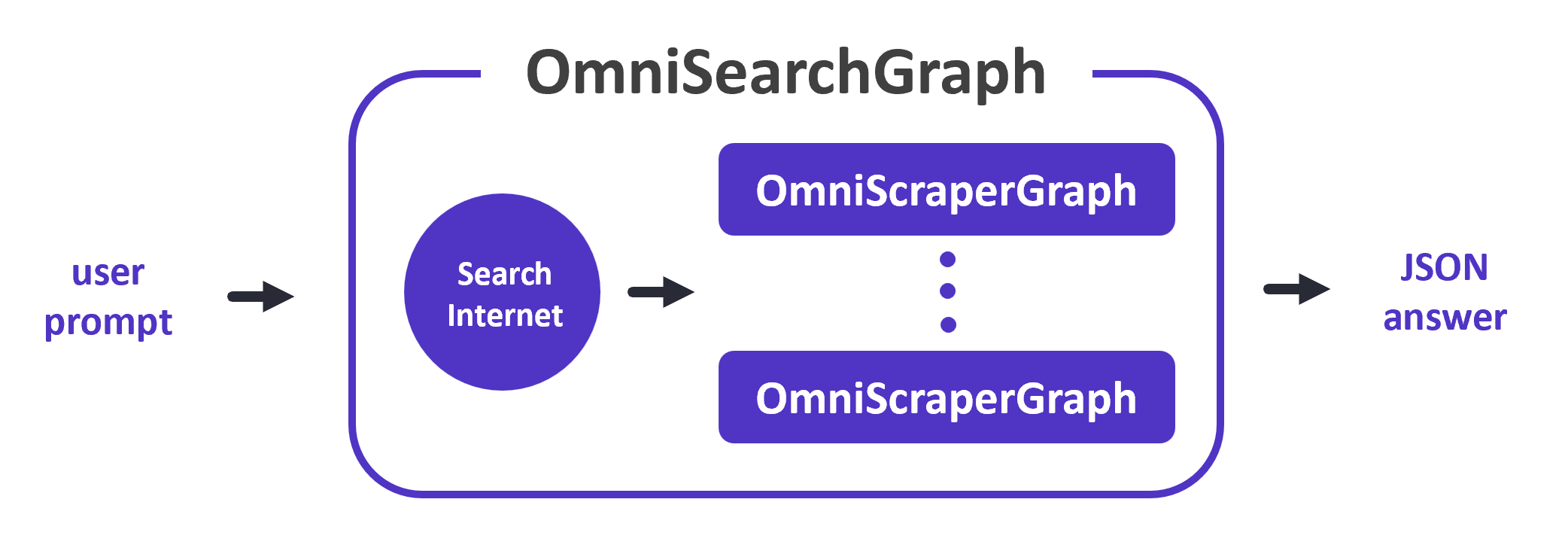
6. OmniSearchGraph:
 nguồn: scrapegraph-ai.readthedocs.io
nguồn: scrapegraph-ai.readthedocs.io
- Chức năng: Tìm kiếm hình ảnh và mô tả chúng.
- Cách thức hoạt động:
- Nhận một lời nhắc từ người dùng (ví dụ: "Tìm kiếm hình ảnh về động vật hoang dã").
- Tạo truy vấn tìm kiếm trên các công cụ tìm kiếm hình ảnh.
- Thu thập dữ liệu từ các hình ảnh được tìm kiếm.
- Sử dụng LLM để phân tích hình ảnh và tạo ra mô tả văn bản.
Scrapegraph-ai cung cấp nhiều loại đồ thị, mỗi loại được thiết kế để giải quyết một bài toán cụ thể trong việc thu thập và xử lý dữ liệu. Bạn có thể lựa chọn loại đồ thị phù hợp nhất với nhu cầu của mình để tự động hóa quá trình thu thập dữ liệu và tạo ra các câu trả lời có cấu trúc, dễ dàng sử dụng cho các hệ thống AI.
Phần 3: Hướng dẫn cài đặt và ví dụ sử dụng
Cài đặt:
Để sử dụng Scrapegraph-ai, bạn cần cài đặt các thành phần sau:
1. Python:
- Scrapegraph-ai yêu cầu Python phiên bản 3.9 trở lên.
- Tải xuống và cài đặt Python từ trang web chính thức: https://www.python.org/downloads/
2. pip:
- pip là trình quản lý gói của Python, được sử dụng để cài đặt các thư viện Python.
- pip thường được cài đặt cùng với Python.
- Kiểm tra xem pip đã được cài đặt chưa bằng cách chạy lệnh sau trong terminal:
pip --version
3. Ollama (tùy chọn):
- Ollama là một nền tảng mã nguồn mở cho phép bạn chạy các mô hình LLM cục bộ trên máy tính của mình.
- Nếu bạn muốn sử dụng các mô hình LLM cục bộ, bạn cần cài đặt Ollama.
- Hướng dẫn cài đặt Ollama: https://ollama.com/
4. Cài đặt Scrapegraph-ai:
- Sau khi cài đặt Python và pip, bạn có thể cài đặt Scrapegraph-ai bằng lệnh sau trong terminal:
pip install scrapegraphai
Lưu ý:
- Nên cài đặt Scrapegraph-ai trong một môi trường ảo (virtual environment) để tránh xung đột với các thư viện khác.
- Hướng dẫn tạo môi trường ảo: https://docs.python.org/3/library/venv.html
Kiểm tra cài đặt:
- Sau khi cài đặt thành công, bạn có thể kiểm tra bằng cách chạy lệnh sau trong terminal:
python -c "import scrapegraphai"
Nếu không có lỗi, bạn đã cài đặt Scrapegraph-ai thành công.
Tiếp theo, chúng ta sẽ cùng khám phá các ví dụ sử dụng Scrapegraph-ai để thu thập và xử lý dữ liệu.
Ví dụ sử dụng:
Sau khi cài đặt thành công Scrapegraph-ai, chúng ta sẽ cùng khám phá hai ví dụ sử dụng thư viện này để thu thập và xử lý dữ liệu từ trang web https://vtv.vn/vtv-news.html của VTV News.
Ví dụ 1: Thu thập dữ liệu cơ bản
Bài toán: Thu thập danh sách các tin tức mới nhất từ trang web VTV News.
Mã ví dụ:
from scrapegraphai.utils import prettify_exec_info
from scrapegraphai.graphs import SmartScraperGraph # Khóa API của Gemini Pro
gemini_key = "GOOGLE_APIKEY" # Cấu hình cho LLM
graph_config = { "llm": { "api_key": gemini_key, "model": "gemini-pro", },
} # Tạo một đối tượng SmartScraperGraph
smart_scraper_graph = SmartScraperGraph( prompt="Hãy liệt kê các tin tức mới nhất", source="https://vtv.vn/vtv-news.html", config=graph_config
) # Thực thi đồ thị và lưu kết quả vào biến result
result = smart_scraper_graph.run()
print(result) # In thông tin về quá trình thực thi đồ thị
graph_exec_info = smart_scraper_graph.get_execution_info()
print(prettify_exec_info(graph_exec_info))
Phân tích code:
- Import các thư viện cần thiết:
prettify_exec_info: Hàm giúp định dạng thông tin về quá trình thực thi đồ thị cho dễ đọc.SmartScraperGraph: Lớp đại diện cho đồ thị SmartScraperGraph.
- Khởi tạo khóa API và cấu hình cho LLM:
gemini_key: Lưu trữ khóa API của Gemini Pro.graph_config: Cấu hình cho LLM, bao gồm khóa API và tên mô hình.
- Tạo đối tượng SmartScraperGraph:
prompt: Lời nhắc cho LLM, yêu cầu LLM liệt kê các tin tức mới nhất.source: Địa chỉ URL của trang web.config: Cấu hình cho LLM.
- Thực thi đồ thị và in kết quả:
smart_scraper_graph.run(): Thực thi đồ thị và trả về kết quả.print(result): In kết quả thu thập được.smart_scraper_graph.get_execution_info(): Lấy thông tin về quá trình thực thi đồ thị.prettify_exec_info(graph_exec_info): Định dạng thông tin về quá trình thực thi đồ thị cho dễ đọc.
Kết quả:
{'tin_moi_nhat': ['Vướng mắc di dời các cơ sở chăn nuôi ra khỏi khu vực không được phép', 'Dịch tả lợn châu Phi bùng phát', 'Lâm Đồng: Công nhận Điểm du lịch “Ga đường sắt Đà Lạt”', ...]}
Phân tích kết quả:
- Kết quả thu thập được là một danh sách các tin tức mới nhất từ trang web VTV News.
- Các tin tức được liệt kê theo thứ tự từ mới nhất đến cũ nhất.
Thông tin về quá trình thực thi đồ thị:
node_name total_tokens prompt_tokens completion_tokens successful_requests total_cost_USD exec_time
0 Fetch 0 0 0 0 0.0 11.461753
1 Parse 0 0 0 0 0.0 0.033072
2 RAG 0 0 0 0 0.0 3.843525
3 GenerateAnswer 0 0 0 1 0.0 8.492593
4 TOTAL RESULT 0 0 0 1 0.0 23.830944
Phân tích thông tin về quá trình thực thi:
- node_name: Tên của mỗi nút trong đồ thị.
- Trong ví dụ này, đồ thị SmartScraperGraph bao gồm các nút Fetch, Parse, RAG và GenerateAnswer.
- Fetch: Nút Fetch đã tải nội dung HTML của trang web
https://vtv.vn/vtv-news.html. - Parse: Nút Parse phân tích cú pháp HTML để xác định các phần tử liên quan đến tin tức.
- RAG: Nút RAG (Retrieval-Augmented Generation) sử dụng LLM để trích xuất thông tin từ các phần tử HTML đã được phân tích cú pháp.
- GenerateAnswer: Nút GenerateAnswer tạo ra câu trả lời cuối cùng dựa trên thông tin được trích xuất bởi RAG.
- Fetch: Nút Fetch đã tải nội dung HTML của trang web
- total_tokens: Tổng số token được sử dụng trong mỗi nút.
- prompt_tokens: Số token trong lời nhắc.
- completion_tokens: Số token trong câu trả lời của LLM.
- successful_requests: Số lượng yêu cầu thành công đến API của LLM.
- total_cost_USD: Tổng chi phí cho việc sử dụng API của LLM (ở đây là 0.0 USD vì đang dùng phiên bản miễn phí của Gemini).
- exec_time: Thời gian thực thi của mỗi nút.
Ví dụ 2: Thu thập và định dạng dữ liệu
Bài toán: Thu thập danh sách các tin tức mới nhất từ trang web VTV News và định dạng dữ liệu theo cấu trúc đã định.
Mã ví dụ:
from typing import List
from pydantic import BaseModel, Field
from scrapegraphai.utils import prettify_exec_info
from scrapegraphai.graphs import SmartScraperGraph # Khóa API của Gemini Pro
gemini_key = "GOOGLE_APIKEY" # Định nghĩa cấu trúc dữ liệu cho tin tức
class News(BaseModel): title: str = Field(description="Tiêu đề của tin tức") public_time: str = Field(description="Thời gian tin tức được đăng tải") description: str = Field(description="Tóm tắt ngắn gọn của tin tức") # Định nghĩa cấu trúc dữ liệu cho danh sách tin tức
class NewsList(BaseModel): news: List[News] # Cấu hình cho LLM
graph_config = { "llm": { "api_key": gemini_key, "model": "gemini-pro", },
} # Tạo một đối tượng SmartScraperGraph
smart_scraper_graph = SmartScraperGraph( prompt="Hãy liệt kê các tin tức mới nhất", source="https://vtv.vn/vtv-news.html", schema=NewsList, # Định dạng dữ liệu đầu ra config=graph_config
) # Thực thi đồ thị và lưu kết quả vào biến result
result = smart_scraper_graph.run()
print(result) # In thông tin về quá trình thực thi đồ thị
graph_exec_info = smart_scraper_graph.get_execution_info()
print(prettify_exec_info(graph_exec_info))
Phân tích code:
- Import các thư viện cần thiết:
List: Kiểu dữ liệu danh sách.BaseModel,Field: Các lớp từ thư viện Pydantic để định nghĩa cấu trúc dữ liệu.prettify_exec_info: Hàm giúp định dạng thông tin về quá trình thực thi đồ thị cho dễ đọc.SmartScraperGraph: Lớp đại diện cho đồ thị SmartScraperGraph.
- Định nghĩa cấu trúc dữ liệu cho tin tức:
News: Lớp mô tả cấu trúc dữ liệu cho một tin tức, bao gồm các trườngtitle,public_time,description.
- Định nghĩa cấu trúc dữ liệu cho danh sách tin tức:
NewsList: Lớp mô tả cấu trúc dữ liệu cho một danh sách tin tức, bao gồm trườngnewslà một danh sách các đối tượngNews.
- Khởi tạo khóa API và cấu hình cho LLM:
gemini_key: Lưu trữ khóa API của Gemini Pro.graph_config: Cấu hình cho LLM, bao gồm khóa API và tên mô hình.
- Tạo đối tượng SmartScraperGraph:
prompt: Lời nhắc cho LLM, yêu cầu LLM liệt kê các tin tức mới nhất.source: Địa chỉ URL của trang web.schema: Cấu trúc dữ liệu đầu ra cho kết quả thu thập được.config: Cấu hình cho LLM.
- Thực thi đồ thị và in kết quả:
smart_scraper_graph.run(): Thực thi đồ thị và trả về kết quả.print(result): In kết quả thu thập được.smart_scraper_graph.get_execution_info(): Lấy thông tin về quá trình thực thi đồ thị.prettify_exec_info(graph_exec_info): Định dạng thông tin về quá trình thực thi đồ thị cho dễ đọc.
Kết quả:
{'news': [{'title': '#### Ra mắt mục Bệnh viện Online - Nơi bác sĩ tư vấn trực tuyến cho độc giả', 'public_time': '28/03/2018 09:55 PM', 'description': 'VTV.vn - Mục Bệnh viện Online thuộc chuyên trang Y tế 24h trên Báo điện tử VTV\nNews sẽ chính thức ra mắt từ tháng 4/2018.'}, {'title': '#### VTV News giành cú đúp tại LHTHTQ lần thứ 37', 'public_time': '17/12/2017 10:52 AM', 'description': 'VTV.vn - Báo điện tử VTV News đã vinh dự giành cú đúp tại LHTHTQ lần thứ 37\nvới hai tác phẩm của phóng viên Trần Đức Long.'}, {'title': '#### 46 thầy giáo ở trường tiểu học Tri Lễ 4 và câu chuyện cổ tích "cõng chữ lên non"', 'public_time': '15/11/2017 06:00 AM', 'description': 'VTV.vn - Giữa thời đại toàn cầu hóa, khi internet gần như ở khắp mọi nơi, thì\nxa xa trên dãy núi đại ngàn Phà Cà Tún, Nghệ An vẫn tồn tại một câu chuyện cổ\ntích giữa đời thường.'},}
Phân tích kết quả:
- Kết quả thu thập được là một danh sách các tin tức mới nhất từ trang web VTV News, được định dạng theo cấu trúc dữ liệu
NewsList. - Mỗi tin tức được mô tả bởi một đối tượng
News, bao gồm các trườngtitle,public_time,description. Thông tin về quá trình thực thi đồ thị:
node_name total_tokens prompt_tokens completion_tokens successful_requests total_cost_USD exec_time
0 Fetch 0 0 0 0 0.0 6.385305
1 Parse 0 0 0 0 0.0 0.069376
2 RAG 0 0 0 0 0.0 2.502607
3 GenerateAnswer 0 0 0 1 0.0 28.340700
4 TOTAL RESULT 0 0 0 1 0.0 37.297989
Phân tích thông tin về quá trình thực thi:
- node_name: Tên của mỗi nút trong đồ thị.
- Trong ví dụ này, đồ thị SmartScraperGraph bao gồm các nút Fetch, Parse, RAG và GenerateAnswer.
- Fetch: Nút Fetch đã tải nội dung HTML của trang web
https://vtv.vn/vtv-news.html. - Parse: Nút Parse phân tích cú pháp HTML để xác định các phần tử liên quan đến tin tức.
- RAG: Nút RAG (Retrieval-Augmented Generation) sử dụng LLM để trích xuất thông tin từ các phần tử HTML đã được phân tích cú pháp.
- GenerateAnswer: Nút GenerateAnswer tạo ra câu trả lời cuối cùng theo cấu trúc dữ liệu
NewsListdựa trên thông tin được trích xuất bởi RAG.
- Fetch: Nút Fetch đã tải nội dung HTML của trang web
- total_tokens: Tổng số token được sử dụng trong mỗi nút.
- prompt_tokens: Số token trong lời nhắc.
- completion_tokens: Số token trong câu trả lời của LLM.
- successful_requests: Số lượng yêu cầu thành công đến API của LLM.
- total_cost_USD: Tổng chi phí cho việc sử dụng API của LLM (ở đây là 0.0 USD vì đang dùng phiên bản miễn phí của Gemini).
- exec_time: Thời gian thực thi của mỗi nút.
Kết luận:
Hai ví dụ trên đã minh họa cách sử dụng Scrapegraph-ai để thu thập và xử lý dữ liệu từ trang web VTV News. Bạn có thể dễ dàng điều chỉnh mã ví dụ để thu thập dữ liệu từ các trang web khác và định dạng dữ liệu theo cấu trúc dữ liệu phù hợp với nhu cầu của mình.
Funfact: Sau khi thu thập cả thời gian public của tin tức thì tôi mới phát hiện ra sự "dừng cập nhật" của vtvnews từ 2022 
Lưu ý:
- Bạn cần thay thế
gemini_keybằng khóa API của Gemini Pro của bạn. - Bạn có thể điều chỉnh lời nhắc và schema để thu thập dữ liệu theo yêu cầu của mình.
- Các ví dụ trên chỉ là những ví dụ đơn giản, Scrapegraph-ai có thể được sử dụng để giải quyết các bài toán phức tạp hơn trong việc thu thập và xử lý dữ liệu.
Kết luận:
Scrapegraph-ai là một công cụ mạnh mẽ, hứa hẹn cách mạng hóa cách chúng ta thu thập và xử lý dữ liệu cho các hệ thống AI. Với khả năng kết hợp LLM và các đường ống dựa trên đồ thị, Scrapegraph-ai mang đến nhiều ưu điểm vượt trội so với các công cụ truyền thống:
- Linh hoạt: Scrapegraph-ai có thể thích nghi với các thay đổi trong cấu trúc trang web, giảm thiểu nhu cầu can thiệp của nhà phát triển.
- Dễ bảo trì: Scrapegraph-ai tự động hóa quá trình thu thập dữ liệu, giúp giảm thiểu công sức bảo trì.
- Hỗ trợ nhiều LLM: Scrapegraph-ai hỗ trợ nhiều LLM, cho phép bạn lựa chọn mô hình phù hợp nhất với nhu cầu của mình.
- Xử lý dữ liệu phức tạp: Scrapegraph-ai có thể xử lý dữ liệu có cấu trúc phức tạp, bao gồm dữ liệu từ các trang web động, dữ liệu đa phương tiện, v.v.
- Tạo câu trả lời có cấu trúc: Scrapegraph-ai có thể tạo ra các câu trả lời có cấu trúc, dễ dàng sử dụng cho các hệ thống AI.
Scrapegraph-ai có tiềm năng ứng dụng rộng rãi trong nhiều lĩnh vực, bao gồm:
- Phát triển các hệ thống AI: Cung cấp dữ liệu chất lượng cao để huấn luyện các mô hình AI.
- Nghiên cứu và phân tích dữ liệu: Thu thập và xử lý dữ liệu từ nhiều nguồn khác nhau để phục vụ cho các nghiên cứu khoa học.
- Tự động hóa các quy trình kinh doanh: Tự động hóa việc thu thập dữ liệu từ các trang web, giúp tối ưu hóa hiệu quả hoạt động kinh doanh.
Những hướng phát triển trong tương lai:
Theo roadmap của Scrapegraph-ai được công bố trên GitHub (https://github.com/VinciGit00/Scrapegraph-ai/blob/main/docs/README.md#scrapgraphai-roadmap), thư viện này sẽ tiếp tục được phát triển với những tính năng mới:
- Hỗ trợ thêm các loại đồ thị: Mở rộng phạm vi ứng dụng của Scrapegraph-ai với các loại đồ thị mới, phù hợp với nhiều bài toán phức tạp hơn.
- Tích hợp với các công cụ AI khác: Cho phép Scrapegraph-ai tương tác với các công cụ AI khác, tạo ra các giải pháp tổng thể hiệu quả hơn.
- Nâng cao khả năng xử lý dữ liệu: Cải thiện khả năng xử lý dữ liệu phức tạp, bao gồm dữ liệu đa phương tiện, dữ liệu có cấu trúc phức tạp, v.v.
- Cải thiện hiệu suất: Tăng tốc độ thực thi và giảm thiểu chi phí sử dụng API của LLM.
Vấn đề liên quan đến việc thu thập và sử dụng dữ liệu:
Việc thu thập và sử dụng dữ liệu cần tuân thủ các nguyên tắc đạo đức và pháp lý. Bạn cần đảm bảo rằng:
- Dữ liệu được thu thập một cách hợp pháp: Không vi phạm quyền riêng tư của người dùng hoặc các quy định về bảo mật thông tin.
- Dữ liệu được sử dụng một cách có trách nhiệm: Không sử dụng dữ liệu cho các mục đích bất hợp pháp hoặc gây hại cho người khác.
- Dữ liệu được bảo mật an toàn: Bảo vệ dữ liệu khỏi bị truy cập trái phép hoặc bị mất mát.
Liên hệ:
Để tìm hiểu thêm về Scrapegraph-ai, bạn có thể tham khảo các tài liệu trên GitHub:
- Trang chủ của Scrapegraph-ai: https://github.com/VinciGit00/Scrapegraph-ai/tree/main
- Mã nguồn của hai ví dụ được cung cấp: https://github.com/Martincrux/Scrapegraph-ai_-1
Nếu bạn có bất kỳ thắc mắc nào hoặc cần liên hệ, vui lòng gửi email đến địa chỉ himmeow.thecoder@gmail.com hoặc tham gia Discord: himmeow the coder 🐾's server.
Chúc bạn thành công trong việc sử dụng Scrapegraph-ai để giải quyết các bài toán thu thập và xử lý dữ liệu cho các hệ thống AI của mình!