1. Giới thiệu
Trong bài viết Scrapegraph-ai #1: Sử dụng sức mạnh của LLMs để giải quyết bài toán thu thập và xử lý dữ liệu cho các hệ thống AI ở kì trước, chúng ta đã tìm hiểu về Scrapegraph-ai, một công cụ mạnh mẽ kết hợp sức mạnh của LLM với khả năng xử lý dữ liệu để giải quyết các bài toán thu thập và xử lý dữ liệu cho các hệ thống AI. Bài viết đã giới thiệu những ứng dụng cơ bản của Scrapegraph-ai trong việc trích xuất thông tin từ các tài liệu.
Quay trở lại các hệ thống RAG cơ bản và kể cả đã được tích hợp phương thức function calling như đã đề cập trong bài viết Function calling: Lời giải cho hệ thống RAG linh hoạt và hiệu quả, trong thực tế thường chỉ giải quyết tốt các bài toán truy vấn về thông tin cụ thể của một đối tượng. Khi gặp bài toán người dùng yêu cầu cung cấp thứ hạng về một tiêu chí nào đấy của đối tượng trong một tập dữ liệu cụ thể, thì việc cung cấp chỉ k văn bản liên quan đến truy vấn trên là không đủ và còn có thể gây ra hiện tượng ảo giác cho mô hình. Ví dụ, khi người dùng hỏi "Ai là người nhỏ tuổi nhất công ty?", hệ thống RAG cơ bản có thể trả về k văn bản chứa thông tin về nhân viên có tuổi nhỏ nhất trong các văn bản được trích xuất, nhưng không thể đảm bảo đó là người nhỏ tuổi nhất trong toàn bộ tập dữ liệu.

Để giải quyết vấn đề này, bài viết này sẽ giới thiệu một giải pháp sử dụng Scrapegraph-ai và function calling để nâng cao khả năng xử lý các bài toán truy vấn phức tạp yêu cầu thông tin về thứ hạng trong hệ thống RAG.
2. Phân tích bài toán
Để minh họa rõ hơn cho vấn đề, chúng ta sẽ lấy ví dụ cụ thể về bài toán quản lý nhân sự của một công ty. Giả sử cơ sở dữ liệu của công ty chứa thông tin về tất cả nhân viên, bao gồm:
- Thông tin cơ bản: Tên, tuổi, chức vụ, quê quán, email, số điện thoại.
- Thông tin bổ sung: Tính cách, sở thích, kinh nghiệm làm việc, trình độ học vấn,...
Yêu cầu của bài toán:
Hệ thống RAG cần có khả năng xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng, ví dụ:
-
Truy vấn về thứ hạng:
- "Ai là 3 người lớn tuổi nhất trong công ty?" (Yêu cầu sắp xếp danh sách nhân viên theo tuổi giảm dần và lấy 3 người đầu tiên)
- "Danh sách 5 nhân viên trẻ nhất có chức vụ là Nhân viên?" (Yêu cầu lọc nhân viên theo chức vụ "Nhân viên", sau đó sắp xếp theo tuổi tăng dần và lấy 5 người đầu tiên)
-
Truy vấn về liệt kê toàn bộ:
- "Danh sách tất cả nhân viên có chức vụ là Nhân viên?" (Yêu cầu lọc nhân viên theo chức vụ "Nhân viên" và liệt kê tất cả)
- "Liệt kê những người có quê quán ở Quảng Bình?" (Yêu cầu lọc nhân viên theo quê quán "Quảng Bình" và liệt kê tất cả)
Điểm yếu của hệ thống RAG cơ bản khi giải quyết bài toán này:
-
Không thể cung cấp thông tin về thứ hạng: Hệ thống RAG cơ bản thường dựa trên kỹ thuật
similarity search, trả vềkvăn bản liên quan nhất đến truy vấn. Điều này dẫn đến việc không thể đảm bảo danh sách được sắp xếp theo thứ hạng mong muốn. Ví dụ, khi người dùng hỏi "Ai là 3 người lớn tuổi nhất trong công ty?", hệ thống RAG cơ bản chỉ có thể trả vềkvăn bản có chứa thông tin về nhân viên có tuổi lớn nhất trong các văn bản được trích xuất, nhưng không thể đảm bảo đó là 3 người lớn tuổi nhất trong toàn bộ cơ sở dữ liệu. -
Có thể gây ra hiện tượng ảo giác: Khi người dùng yêu cầu liệt kê toàn bộ nhân viên thỏa mãn một tiêu chí nhất định, hệ thống RAG cơ bản chỉ có thể trích xuất
kvăn bản, dẫn đến việc mô hình có thể bị ảo giác và cho rằng danh sách đó đã chứa đủ toàn bộ đối tượng.
Ví dụ: Khi người dùng hỏi "Danh sách tất cả nhân viên có chức vụ là Nhân viên?", hệ thống RAG cơ bản có thể chỉ trích xuất k văn bản chứa thông tin về nhân viên có chức vụ là Nhân viên, nhưng không thể đảm bảo rằng danh sách đó đã chứa đủ tất cả nhân viên có chức vụ là Nhân viên trong toàn bộ cơ sở dữ liệu.
Để giải quyết các điểm yếu này, chúng ta cần một giải pháp hiệu quả hơn, có khả năng xử lý các truy vấn phức tạp yêu cầu thông tin về thứ hạng và liệt kê toàn bộ đối tượng thỏa mãn một tiêu chí nhất định.
Lưu ý:
- Bài toán quản lý nhân sự chỉ là một ví dụ minh họa. Giải pháp được đề xuất trong bài viết có thể được áp dụng cho các bài toán khác yêu cầu xử lý thông tin về thứ hạng và liệt kê đối tượng trong các lĩnh vực như quản lý tài chính, phân tích thị trường, dịch vụ khách hàng,...
3. Giải pháp
Để giải quyết các điểm yếu của hệ thống RAG cơ bản trong việc xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng, chúng ta sẽ sử dụng kết hợp Scrapegraph-ai và function calling.
3.1. Giới thiệu giải pháp sử dụng Scrapegraph-ai và function calling
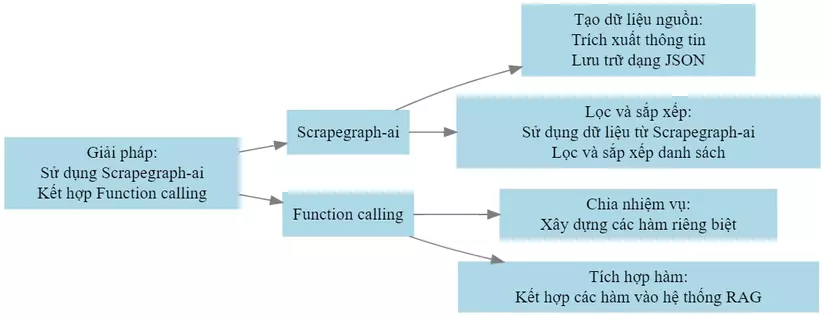
-
Scrapegraph-ai: Công cụ này được giới thiệu trong bài viết Scrapegraph-ai #1: Sử dụng sức mạnh của LLMs để giải quyết bài toán thu thập và xử lý dữ liệu cho các hệ thống AI sẽ giúp chúng ta trích xuất thông tin từ các tài liệu và tạo ra một cơ sở dữ liệu có cấu trúc về nhân viên.
-
Function calling: Như đã đề cập trong bài viết Quy trình xây dựng hệ thống RAG tích hợp Function Calling (with source code), function calling cho phép chúng ta chia nhỏ các nhiệm vụ phức tạp thành các hàm nhỏ hơn, giúp hệ thống RAG linh hoạt và hiệu quả hơn trong việc xử lý các truy vấn phức tạp.
3.2. Chia việc truy xuất dữ liệu thành 3 hướng
Chúng ta sẽ chia việc truy xuất dữ liệu thành 3 hướng, tương ứng với 3 hàm:
-
Hàm truy xuất tài liệu liên quan khi biết rõ một trong các thông tin của đối tượng (sử dụng semilarity search):
- Hàm này sẽ được sử dụng khi người dùng cung cấp thông tin cụ thể về một nhân viên, ví dụ như tên, email, số điện thoại,...
- Hàm sẽ tìm kiếm các tài liệu liên quan đến thông tin đã cho bằng kỹ thuật
similarity searchdựa trên vector embedding. - Kết quả trả về sẽ là một danh sách các tài liệu có chứa thông tin liên quan đến đối tượng được tìm kiếm.
-
Hàm đóng vai trò là bộ lọc thực hiện các yêu cầu trích xuất đối tượng thỏa mãn các tiêu chí nhất định (sử dụng Scrapegraph-ai):
- Hàm này sẽ được sử dụng để lọc danh sách nhân viên dựa trên các tiêu chí được đưa ra bởi người dùng, ví dụ như tuổi, chức vụ, quê quán,...
- Hàm sẽ sử dụng Scrapegraph-ai để trích xuất thông tin từ các tài liệu và tạo ra một cơ sở dữ liệu có cấu trúc về nhân viên.
- Sau đó, hàm sẽ lọc danh sách nhân viên dựa trên các tiêu chí được chỉ định và trả về danh sách nhân viên thỏa mãn yêu cầu.
-
Hàm tìm kiếm các đối tượng dựa trên các tiêu chí đặc trưng (sử dụng semilarity search):
- Hàm này sẽ được sử dụng khi người dùng cung cấp các tiêu chí đặc trưng để tìm kiếm nhân viên, ví dụ như sở thích, tính cách,...
- Hàm sẽ tìm kiếm các tài liệu liên quan đến các tiêu chí đặc trưng bằng kỹ thuật
similarity searchdựa trên vector embedding. - Kết quả trả về sẽ là một danh sách các tài liệu có chứa thông tin liên quan đến các tiêu chí đặc trưng được tìm kiếm.
Việc chia việc truy xuất dữ liệu thành 3 hướng sẽ giúp hệ thống RAG xử lý các truy vấn phức tạp một cách hiệu quả hơn, đảm bảo tính chính xác và tránh hiện tượng ảo giác.
Lưu ý:
- Các hàm được đề xuất có thể được mở rộng và tùy chỉnh để phù hợp với các yêu cầu cụ thể của bài toán.
- Việc lựa chọn hàm phù hợp với từng loại truy vấn sẽ được thực hiện bởi hệ thống RAG dựa trên phân tích ngữ cảnh của truy vấn.
Trong phần tiếp theo, chúng ta sẽ đi sâu vào chi tiết cách thức hoạt động của mỗi hàm và cách kết hợp chúng để xây dựng hệ thống RAG có khả năng xử lý các truy vấn phức tạp về thứ hạng và liệt kê đối tượng.
3.3.1. Hàm truy xuất tài liệu liên quan khi biết rõ một trong các thông tin của đối tượng (sử dụng semilarity search)
- Tên hàm:
search_employee_info_by_name - Công dụng: Hàm này sẽ được sử dụng khi người dùng cung cấp thông tin cụ thể về một nhân viên, ví dụ như tên, email, số điện thoại,...
- Cách thức hoạt động: Hàm này sử dụng kỹ thuật
similarity searchdựa trên vector embedding, tương tự như cách thức được trình bày trong các bài viết trước của tôi về hệ thống RAG và function calling. Bạn có thể tham khảo thêm về cách thức hoạt động củasimilarity searchtrong bài viết Quy trình xây dựng hệ thống RAG tích hợp Function Calling (with source code).
3.3.2. Hàm đóng vai trò là bộ lọc thực hiện các yêu cầu trích xuất đối tượng thỏa mãn các tiêu chí nhất định (sử dụng Scrapegraph-ai)
-
Tên hàm:
search_employee_by_rules -
Công dụng: Hàm này là cốt lõi của giải pháp, giúp xử lý các truy vấn phức tạp về thứ hạng và liệt kê đối tượng. Hàm này sẽ được sử dụng để lọc danh sách nhân viên dựa trên các tiêu chí được đưa ra bởi người dùng, ví dụ như tuổi, chức vụ, quê quán,...
-
Cách thức hoạt động:
-
Tạo dữ liệu nguồn bằng Scrapegraph-ai:
-
Trích xuất thông tin từ các tài liệu: Chúng ta sẽ sử dụng Scrapegraph-ai để trích xuất thông tin từ các tài liệu (ví dụ: file PDF, file Word,...) và tạo ra một cơ sở dữ liệu có cấu trúc về nhân viên.
-
Lưu trữ dữ liệu dưới dạng file JSON: Dữ liệu nguồn cho Scrapegraph-ai sẽ được lưu trữ dưới dạng file JSON, mỗi đối tượng trong file JSON là một nhân viên với các thông tin cơ bản như tên, tuổi, chức vụ, quê quán,...
-
Code ví dụ:
from typing import List from pydantic import BaseModel, Field from scrapegraphai.utils import prettify_exec_info import PyPDF2 from scrapegraphai.graphs import PDFScraperGraph import json # API Key của Gemini Pro gemini_key = "..." # Tạo source file_path = "employee_info_1.pdf" # Mở file PDF with open(file_path, 'rb') as pdf_file: pdf_reader = PyPDF2.PdfReader(pdf_file) # Khởi tạo biến sources sources = "" # Duyệt qua từng trang và nối nội dung vào sources for page_num in range(len(pdf_reader.pages)): page = pdf_reader.pages[page_num] page_text = page.extract_text() sources += page_text- Đoạn code trên sử dụng thư viện
PyPDF2để đọc nội dung của file PDF và lưu trữ vào biếnsources.
# Định nghĩa cấu trúc dữ liệu cho lời nhận xét class Employee(BaseModel): name: str = Field(description="Tên của thành viên") age: str = Field(description="Tuổi của thành viên") role: str = Field(description="Chức vụ của thành viên. Các giá trị hợp lệ bao gồm: 'Giám đốc', 'Thư ký' và 'Nhân viên'") hometown: str = Field(description="Quê quán của thành viên (chỉ ghi tên, không ghi đơn vị, ví dụ: 'Quảng Bình', 'Hà Nội'") # Định nghĩa cấu trúc dữ liệu cho danh sách nhận xét class Employees(BaseModel): employees: List[Employee]- Code định nghĩa cấu trúc dữ liệu cho mỗi nhân viên (
Employee) và danh sách nhân viên (Employees) bằng thư việnpydantic.
# Cấu hình cho LLM graph_config = { "llm": { "api_key":gemini_key, "model": "gemini-pro", }, } # Tạo một đối tượng SmartScraperGraph smart_scraper_graph = PDFScraperGraph( prompt="Hãy liệt kê toàn bộ thành viên của công ty này", source=sources, schema=Employees, # Định dạng dữ liệu đầu ra config=graph_config ) # Thực thi đồ thị và lưu kết quả vào biến result result = smart_scraper_graph.run() print(result) # Lưu kết quả vào file JSON result = Employees(**result) with open('employee_info.json', 'w', encoding='utf-8') as f: json.dump(result.dict(), f, indent=4, ensure_ascii=False)Kết quả:
{ "employees": [ { "name": "Himmeow", "age": "35", "role": "Giám đốc", "hometown": "Thành phố Hà Nội" }, { "name": "Trần Thị Bình", "age": "28", "role": "Thư ký", "hometown": "Thành phố Hồ Chí Minh" },... ] }- Code tạo một đối tượng
PDFScraperGraphcủa Scrapegraph-ai, với prompt là "Hãy liệt kê toàn bộ thành viên của công ty này", nguồn dữ liệu làsourcesvà schema làEmployees. - Code thực thi đồ thị Scrapegraph-ai và lưu kết quả vào file JSON
employee_info.json.
- Đoạn code trên sử dụng thư viện
-
-
Tạo phương thức lọc và sắp xếp:
-
Lọc danh sách nhân viên: Hàm sẽ lọc danh sách nhân viên dựa trên các tiêu chí được chỉ định bởi người dùng, ví dụ như tuổi, chức vụ, quê quán,...
-
Sắp xếp danh sách nhân viên: Hàm cũng có thể sắp xếp danh sách nhân viên theo thứ hạng dựa trên các tiêu chí được chỉ định bởi người dùng, ví dụ như sắp xếp theo tuổi tăng dần, giảm dần, sắp xếp theo chức vụ, ...
-
Code ví dụ:
def search_employee_by_rules(role: str = 'pass', age: str = 'pass', hometown: str= 'pass', sort_by: str= 'pass', sort_rule: str= 'pass', choose_range: str= 'pass') -> str: """ Sử dụng các bộ lọc để cung cấp danh sách và thông tin cơ bản của những người có đặc điểm giống với bạn đang tìm kiếm. Args: role: Danh sách chức vụ hợp lệ mà bạn cần lọc. Các chức vụ hợp lệ bao gồm (Giám đốc, Thư ký, Nhân viên). Đặt role = "pass" nếu bạn không cần sử dụng bộ lọc này. Ví dụ: - "Giám đốc; Nhân viên". age: Danh sách các độ tuổi hợp lệ mà bạn cần lọc. Đặt age = "pass" nếu bạn không cần sử dụng bộ lọc này. Ví dụ: - "18; 19; 20"... Returns: Chuỗi JSON chứa danh sách những người phù hợp với yêu cầu của bạn. """ json_file_path ="employee_info.json" with open(json_file_path, 'r', encoding='utf-8') as f: employees = json.load(f)["employees"] # Xử lý role if role != "pass": roles = [r.strip() for r in role.split(";")] employees = [e for e in employees if e["role"] in roles] # Xử lý age ... # Xử lý hometown ... # Xử lý sort_by ... # Xử lý choose_range ... # Trả về danh sách nhân viên sau khi đã được lọc dưới dạng json return json.dumps({"employees": employees}, ensure_ascii=False, indent=4) -
Giải thích code:
- Hàm
search_employee_by_rulesnhận các tham số đầu vào làrole,age,hometown,sort_by,sort_rulevàchoose_range. - Hàm đọc dữ liệu từ file JSON
employee_info.json. - Hàm thực hiện lọc danh sách nhân viên dựa trên các tiêu chí
role,age,hometown. - Hàm sắp xếp danh sách nhân viên theo thứ hạng dựa trên tiêu chí
sort_byvàsort_rule. - Hàm trả về danh sách nhân viên thỏa mãn yêu cầu sau khi đã được lọc và sắp xếp.
- Hàm
-
-
Trả về kết quả: Hàm sẽ trả về danh sách nhân viên thỏa mãn yêu cầu sau khi đã được lọc và sắp xếp.
-
Lưu ý:
- Hàm
search_employee_by_ruleslà một giải pháp mới, giúp xử lý các truy vấn phức tạp về thứ hạng và liệt kê đối tượng một cách hiệu quả. - Việc tạo file JSON làm dữ liệu nguồn cho Scrapegraph-ai là bước quan trọng giúp hệ thống RAG có thể xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng.
3.3.3. Hàm tìm kiếm các đối tượng dựa trên các tiêu chí đặc trưng (sử dụng semilarity search)
- Tên hàm:
search_employee_by_info - Công dụng: Hàm này sẽ được sử dụng khi người dùng cung cấp các tiêu chí đặc trưng để tìm kiếm nhân viên, ví dụ như sở thích, tính cách,...
- Cách thức hoạt động: Hàm này cũng sử dụng kỹ thuật
similarity searchdựa trên vector embedding, tương tự như hàmsearch_employee_info_by_name. Bạn có thể tham khảo thêm về cách thức hoạt động củasimilarity searchtrong bài viết Quy trình xây dựng hệ thống RAG tích hợp Function Calling (with source code).
Lưu ý:
- Việc kết hợp 3 hàm sẽ giúp hệ thống RAG xử lý các truy vấn phức tạp một cách linh hoạt và hiệu quả.
- Bạn có thể tham khảo thêm về cách thức hoạt động của Scrapegraph-ai trong bài viết Scrapegraph-ai #1: Sử dụng sức mạnh của LLMs để giải quyết bài toán thu thập và xử lý dữ liệu cho các hệ thống AI.
3.4. Cách xây dựng và triển khai hệ thống với function calling

Để xây dựng và triển khai hệ thống RAG với function calling, chúng ta sẽ sử dụng thư viện langchain kết hợp với GoogleGenerativeAI. Quy trình xây dựng hệ thống RAG với function calling đã được trình bày chi tiết trong bài viết Quy trình xây dựng hệ thống RAG tích hợp Function Calling (with source code). Trong phần này, chúng ta sẽ tập trung vào việc tích hợp 3 hàm đã được định nghĩa ở trên vào hệ thống RAG.
1. Khởi tạo môi trường:
- Cài đặt các thư viện cần thiết:
langchain,langchain_google_genai,google.generativeaivà các thư viện khác liên quan đến xử lý dữ liệu và vector embedding. - Cấu hình API key cho Google Generative AI.
2. Xây dựng các hàm:
- Định nghĩa 3 hàm
search_employee_info_by_name,search_employee_by_rulesvàsearch_employee_by_infonhư đã trình bày ở phần 3.3.
3. Tích hợp các hàm vào hệ thống RAG:
- Tạo một danh sách các hàm
toolsđể sử dụng trong hệ thống RAG. - Tạo một dictionary
available_toolsánh xạ tên hàm với hàm tương ứng. - Khởi tạo model Google Generative AI với tên model và danh sách công cụ.
- Cấu hình system message để hướng dẫn chatbot sử dụng các công cụ một cách chính xác.
4. Triển khai hệ thống RAG:
- Tạo một vòng lặp chính để nhận input từ người dùng và trả về phản hồi.
- Kiểm tra xem input của người dùng có chứa yêu cầu gọi hàm hay không.
- Nếu có, lấy hàm tương ứng từ
available_toolsvà gọi hàm với các tham số được chỉ định. - Lưu trữ kết quả trả về từ hàm vào dictionary
responses. - Gửi phản hồi mới (bao gồm kết quả từ các hàm) cho chatbot.
- In ra phản hồi cuối cùng từ chatbot.
Code ví dụ:
import google.generativeai as genai
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS import os, json, re
from typing import Union # ... (code của 3 hàm search_employee_info_by_name, search_employee_by_rules, search_employee_by_info) # Danh sách các hàm (công cụ) có sẵn cho chatbot
tools = [search_employee_info_by_name, search_employee_by_rules, search_employee_by_info] # Tạo dictionary ánh xạ tên hàm với hàm tương ứng
available_tools = { "search_employee_info_by_name": search_employee_info_by_name, "search_employee_by_rules": search_employee_by_rules, "search_employee_by_info": search_employee_by_info
} # Khởi tạo model Google Generative AI với tên model và danh sách công cụ
model = genai.GenerativeModel(model_name="gemini-1.5-flash", tools=tools, system_instruction="""Bạn là một trợ lý ảo thông minh, làm nhiệm vụ quản lý nhân sự cho một công ty. Bạn có khả năng truy xuất thông tin từ cơ sở dữ liệu để trả lời câu hỏi của người dùng một cách chính xác và hiệu quả... """) # Tạo chatbot với system message để cấu hình chatbot history=[] chat = model.start_chat(history=history) # Vòng lặp chính để nhận input từ người dùng và trả về phản hồi
while True: user_input = input("User: ") # Kiểm tra điều kiện thoát if user_input.lower() in ["thoát", "exit", "quit"]: break # Gửi tin nhắn của người dùng cho chatbot và nhận phản hồi response = chat.send_message(user_input) while True: # Tạo dictionary để lưu trữ kết quả từ các hàm responses = {} # Xử lý từng phần của phản hồi từ chatbot for part in response.parts: # Kiểm tra xem phần phản hồi có chứa yêu cầu gọi hàm hay không if fn := part.function_call: ... # Nếu có kết quả từ các hàm if responses: # Tạo danh sách các phần phản hồi mới, bao gồm kết quả từ các hàm response_parts = [ genai.protos.Part(function_response=genai.protos.FunctionResponse(name=fn, response={"result": val})) for fn, val in responses.items() ] # Gửi phản hồi mới (bao gồm kết quả từ các hàm) cho chatbot response = chat.send_message(response_parts) else: break # In ra phản hồi cuối cùng từ chatbot print("Chatbot:", response.text)
Giải thích code:
- Đoạn code
tools = [search_employee_info_by_name, search_employee_by_rules, search_employee_by_info]tạo một danh sách các hàmtoolsđể sử dụng trong hệ thống RAG. - Đoạn code
available_tools = {"search_employee_info_by_name": search_employee_info_by_name, "search_employee_by_rules": search_employee_by_rules, "search_employee_by_info": search_employee_by_info}tạo một dictionaryavailable_toolsánh xạ tên hàm với hàm tương ứng. - Đoạn code
model = genai.GenerativeModel(model_name="gemini-1.5-flash", tools=tools, system_instruction="...")khởi tạo model Google Generative AI với tên model làgemini-1.5-flash, danh sách công cụ làtoolsvà system message làsystem_instruction. - Vòng lặp chính nhận input từ người dùng, kiểm tra xem input có chứa yêu cầu gọi hàm hay không, và gọi hàm tương ứng nếu có.
Lưu ý:
- Bạn có thể tham khảo thêm về cách thức hoạt động của
langchainvàGoogleGenerativeAItrong các tài liệu chính thức của thư viện. - Việc cấu hình system message là rất quan trọng để hướng dẫn chatbot sử dụng các công cụ một cách chính xác và hiệu quả.
Bằng cách sử dụng Scrapegraph-ai và function calling, hệ thống RAG của bạn sẽ có khả năng xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng, đồng thời đảm bảo tính chính xác và tránh hiện tượng ảo giác.
4. Thực nghiệm và đánh giá
Để đánh giá hiệu quả của giải pháp sử dụng Scrapegraph-ai và function calling trong việc xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng, chúng ta sẽ tiến hành thực nghiệm với một số test case.
4.1. Test case cho hệ thống RAG cơ bản
Hệ thống RAG cơ bản thường chỉ sử dụng kỹ thuật similarity search để trả về k văn bản liên quan nhất đến truy vấn. Điều này dẫn đến việc không thể xử lý hiệu quả các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng.
Test case có thể thực hiện:
- User: himmeow là ai?
- Chatbot: Himmeow là Giám Đốc của công ty. Số điện thoại liên lạc của anh ấy là 0123456789 và email là himmeow.thecoder@gmail.com.
- User: ai là thư ký của công ty?
- Chatbot: Thư ký của công ty là Trần Thị Bình.
Test case bị lỗi hoặc ảo giác:
- User: ai là người nhỏ tuổi nhất công ty bạn?
- Chatbot: Chị Lữ Thị Hạ 27 tuổi, quản trị thành phố Đan Nẵng, là người nhỏ tuổi nhất công ty. (bị ảo giác vì trong
ktài liệu trả về thì Hạ có tuổi bé nhất)
- Chatbot: Chị Lữ Thị Hạ 27 tuổi, quản trị thành phố Đan Nẵng, là người nhỏ tuổi nhất công ty. (bị ảo giác vì trong
- User: danh sách người có chức vụ nhân viên, quê ở hà nội?
- Chatbot: Hiện tại tôi không có thông tin về nhân viên nào quê ở Hà Nội. (không giải quyết được)
Phân tích:
- Các test case trên cho thấy hệ thống RAG cơ bản chỉ có thể xử lý các truy vấn đơn giản, yêu cầu thông tin cụ thể về một đối tượng.
- Khi gặp các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng, hệ thống RAG cơ bản gặp khó khăn trong việc xử lý và có thể dẫn đến hiện tượng ảo giác.
4.2. Test case cho mô hình đề xuất
Mô hình đề xuất sử dụng Scrapegraph-ai và function calling để giải quyết các vấn đề của hệ thống RAG cơ bản.
Test case cho thấy mô hình đề xuất đã giải quyết được bài toán:
- User: ai là người bé tuổi nhất công ty bạn?
- Mô hình: Sử dụng hàm
search_employee_by_rulesvới đầu vào (choose_range=1; 1, sort_by=age, sort_rule=ascending) - Chatbot: Người bé tuổi nhất là Vũ Thị Hoa.
- Mô hình: Sử dụng hàm
- User: danh sách người có chức vụ nhân viên, quê ở hà nội?
- Mô hình: Sử dụng hàm
search_employee_by_rulesvới đầu vào (hometown=Thành phố Hà Nội, role=Nhân viên) - Chatbot: Danh sách người có chức vụ nhân viên, quê ở Hà Nội gồm: Nguyễn Thị Lan, Đỗ Văn Đức, Vũ Thị Hương, Trần Văn Nam.
- Mô hình: Sử dụng hàm
- User: cho tôi thông tin về người lớn tuổi thứ 7 công ty bạn?
- Mô hình: Sử dụng hàm
search_employee_by_rulesvới đầu vào (choose_range=7; 7, sort_by=age, sort_rule=decrease) sau đấy sử dụng hàmsearch_employee_info_by_name(name = 'Trần Thị Bình') - Chatbot: Người lớn tuổi thứ 7 trong công ty là Trần Thị Bình, 28 tuổi, hiện đang giữ chức vụ Thư ký và quê ở Thành phố Hồ Chí Minh.
- Mô hình: Sử dụng hàm
Phân tích:
- Các test case trên cho thấy mô hình đề xuất đã giải quyết được các vấn đề của hệ thống RAG cơ bản.
- Mô hình có thể xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng một cách chính xác.
- Mô hình hoạt động hiệu quả với phương thức function calling khi biết sử dụng phối hợp các hàm để giải quyết vấn đề.
4.3. Phân tích và so sánh kết quả
Để đánh giá hiệu quả của mô hình đề xuất so với hệ thống RAG cơ bản, chúng ta sẽ phân tích kết quả của các test case đã thực hiện. Bảng sau so sánh kết quả của hai mô hình:
| Test case | Hệ thống RAG cơ bản | Mô hình đề xuất | Phân tích |
|---|---|---|---|
| Ai là người nhỏ tuổi nhất công ty bạn? | Bị ảo giác: Trả về thông tin về người có tuổi nhỏ nhất trong k tài liệu được trích xuất, không phải người nhỏ tuổi nhất trong toàn bộ cơ sở dữ liệu. |
Trả về kết quả chính xác: Sử dụng hàm search_employee_by_rules với đầu vào (choose_range=1; 1, sort_by=age, sort_rule=ascending) để tìm người có tuổi nhỏ nhất trong toàn bộ cơ sở dữ liệu. |
Mô hình đề xuất đã giải quyết được vấn đề ảo giác bằng cách sử dụng hàm search_employee_by_rules để lọc và sắp xếp toàn bộ danh sách nhân viên theo tuổi. |
| Danh sách người có chức vụ nhân viên, quê ở hà nội? | Không giải quyết được: Hệ thống chỉ trích xuất k tài liệu, không thể đảm bảo đã chứa đủ thông tin về tất cả nhân viên có chức vụ nhân viên và quê ở Hà Nội. |
Trả về danh sách chính xác: Sử dụng hàm search_employee_by_rules với đầu vào (hometown=Thành phố Hà Nội, role=Nhân viên) để lọc và liệt kê tất cả nhân viên có chức vụ nhân viên và quê ở Hà Nội. |
Mô hình đề xuất đã giải quyết được vấn đề liệt kê toàn bộ đối tượng bằng cách sử dụng hàm search_employee_by_rules để lọc và liệt kê tất cả nhân viên thỏa mãn các tiêu chí. |
| Cho tôi thông tin về người lớn tuổi thứ 7 công ty bạn? | Không giải quyết được: Hệ thống không có khả năng xử lý các truy vấn liên quan đến thứ hạng. | Trả về thông tin chính xác: Sử dụng hàm search_employee_by_rules với đầu vào (choose_range=7; 7, sort_by=age, sort_rule=decrease) để tìm người lớn tuổi thứ 7, sau đó sử dụng hàm search_employee_info_by_name để lấy thông tin chi tiết về người đó. |
Mô hình đề xuất đã giải quyết được vấn đề truy vấn về thứ hạng bằng cách sử dụng hàm search_employee_by_rules để lọc và sắp xếp danh sách nhân viên theo tuổi, sau đó sử dụng hàm search_employee_info_by_name để lấy thông tin chi tiết về người được tìm kiếm. |
Kết luận:
- Mô hình đề xuất đã giải quyết được các hạn chế của hệ thống RAG cơ bản trong việc xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng.
- Mô hình đề xuất đã cải thiện đáng kể khả năng xử lý các truy vấn phức tạp, đảm bảo tính chính xác và tránh hiện tượng ảo giác.
- Việc sử dụng function calling và Scrapegraph-ai đã giúp mô hình trở nên linh hoạt và hiệu quả hơn trong việc xử lý các yêu cầu đa dạng của người dùng.
4.4. Đánh giá hiệu quả
Ưu điểm:
- Khả năng xử lý truy vấn phức tạp: Mô hình có thể xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng, giải quyết được hạn chế của hệ thống RAG cơ bản.
- Tăng tính chính xác: Mô hình giảm thiểu hiện tượng ảo giác, trả về kết quả chính xác hơn.
- Linh hoạt: Mô hình có thể xử lý các yêu cầu đa dạng của người dùng thông qua việc sử dụng phối hợp các hàm.
Hạn chế:
- Dựa vào chất lượng dữ liệu nguồn: Hiệu quả của mô hình phụ thuộc vào chất lượng của dữ liệu nguồn được trích xuất bởi Scrapegraph-ai.
- Thiết kế và cấu hình: Việc thiết kế các hàm và cấu hình system message cho chatbot cần có kỹ năng chuyên môn.
5. Kết luận
Bài viết này đã giới thiệu một giải pháp sử dụng Scrapegraph-ai và function calling để nâng cao khả năng xử lý các bài toán truy vấn phức tạp yêu cầu thông tin về thứ hạng trong hệ thống RAG. Giải pháp này được chia thành 3 hàm: hàm truy xuất tài liệu liên quan, hàm lọc và sắp xếp đối tượng, và hàm tìm kiếm đối tượng dựa trên các tiêu chí đặc trưng. Việc chia nhỏ nhiệm vụ thành các hàm riêng biệt giúp hệ thống RAG linh hoạt và hiệu quả hơn trong việc xử lý các truy vấn phức tạp, đồng thời đảm bảo tính chính xác và tránh hiện tượng ảo giác.
Thực nghiệm với các test case đã chứng minh hiệu quả của giải pháp. Mô hình đề xuất đã giải quyết được các vấn đề của hệ thống RAG cơ bản trong việc xử lý các truy vấn phức tạp liên quan đến thứ hạng và liệt kê đối tượng.
Tuy nhiên, giải pháp này cũng có một số hạn chế. Việc chia nhỏ hàm bắt buộc sử dụng function calling, dẫn đến chi phí (số token cho mỗi truy vấn) sẽ tăng khi độ phức tạp của bài toán và số lượng function tăng lên. Điều này có thể ảnh hưởng đến hiệu quả của hệ thống.
Trong bài viết tiếp theo, tôi sẽ giới thiệu cách xây dựng hệ thống multi-agents để giải quyết vấn đề này. Hệ thống multi-agents sẽ cho phép chúng ta chia nhỏ nhiệm vụ phức tạp thành nhiều agent nhỏ hơn, mỗi agent sẽ chuyên trách một phần nhiệm vụ. Cách tiếp cận này sẽ đánh đổi một phần tốc độ hệ thống để đạt được hiệu quả xử lý cao hơn.
Hy vọng bài viết này đã cung cấp cho bạn những kiến thức hữu ích về cách sử dụng Scrapegraph-ai và function calling để nâng cao khả năng xử lý các bài toán truy vấn phức tạp trong hệ thống RAG. Hãy theo dõi bài viết tiếp theo để tìm hiểu thêm về hệ thống multi-agents và cách ứng dụng nó vào các hệ thống AI.
Liên hệ
Mã nguồn của ví dụ được cung cấp: github.com/Martincrux/RAG_function_calling
Nếu bạn có bất kỳ thắc mắc nào hoặc cần liên hệ, vui lòng gửi email đến địa chỉ himmeow.thecoder@gmail.com hoặc tham gia Discord: himmeow the coder 🐾's server.
Chúc bạn thành công trong việc sử dụng mô hình để giải quyết các bài toán cụ thể trong hệ thống RAG của mình!